

采用双塔BERT模型对文本字符和label进行编码
描述
这是一篇来自于 ACL 2022 的文章,总体思想就是在 meta-learning 的基础上,采用双塔 BERT 模型分别来对文本字符和对应的label进行编码,并且将二者进行 Dot Product(点乘)得到的输出做一个分类的事情。文章总体也不复杂,涉及到的公式也很少,比较容易理解作者的思路。对于采用序列标注的方式做 NER 是个不错的思路。

1、模型
1.1 架构
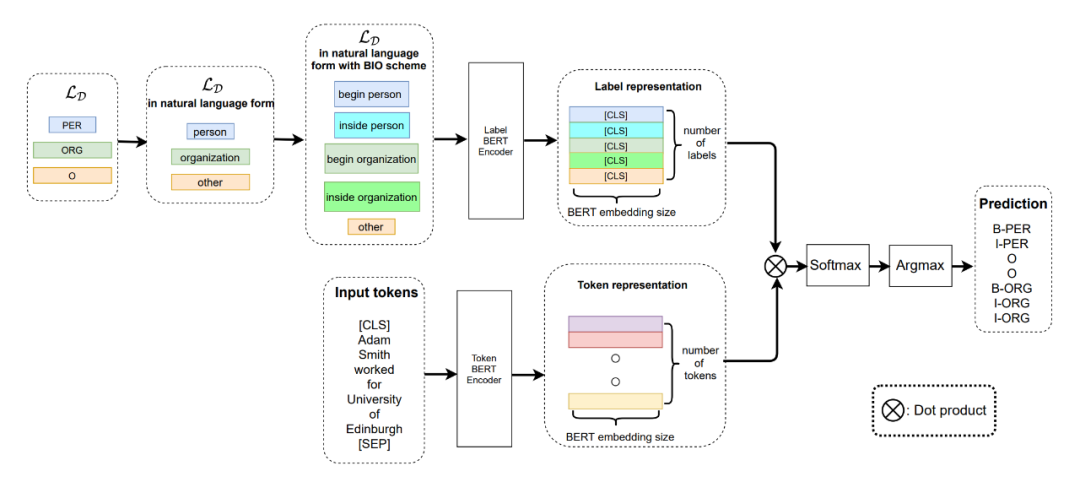
▲图1.模型整体构架
从上图中可以清楚的看到,作者采用了双塔 BERT 来分别对文本的 Token 和每个 Token 对应的 label 进行编码。这里作者采用这种方法的思路也很简单,因为是 Few-shot 任务,没有足够的数据量,所以作者认为每个 Token 的 label 可以为 Token 提供额外的语义信息。 作者的 Meta-Learning 采用的是 metric-based 方法,直观一点理解就是首先计算每个样本 Token 的向量表征,然后与计算得到的 label 表征计算相似度,这里从图上的 Dot Product 可以直观的体现出来。然后对得到的相似度矩阵 ([batch_size,sequence_length,embed_dim]) 进行 softmax 归一化,通过 argmax 函数取最后一维中值最大的 index,并且对应相应的标签列表,得到当前 Token 对应的标签。
1.2 Detail
此外,作者在对标签进行表征时,也对每个标签进行了相应的处理,总体分为以下三步: 1. 将词语的简写标签转为自然语言形式,例如 PER--》person,ORG--》organization,LOC--》local 等等; 2. 将标注标签起始、中间的标记转为自然语言形式,例如以 BIO 形式进行标记的就可以转为 begin、inside、other 等等,其他标注形式的类似。 3. 按前两步的方法转换后进行组合,例如 B-PER--》begin person,I-PER--》inside person。 由于进行的是 Few-shot NER 任务,所以作者在多个 source datasets 上面训练模型,然后他们在多个 unseen few shot target datasets 上面验证经过 fine-tuning 和不经过 fine-tuning 的模型的效果。 在进行 Token 编码时,对应每个 通过 BERT 模型可以得到其对应的向量 ,如下所示:
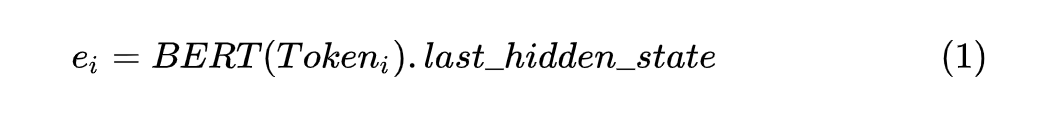
这里需要注意的是 BERT 模型的输出取 last_hidden_state 作为对应 Token 的向量。 对标签进行编码时,对标签集合中的所有标签进行对应编码,每个完整的 label 得到的编码取 部分作为其编码向量,并且将所有的 label 编码组成一个向量集合 ,最后计算每个 与 的点积,形式如下:
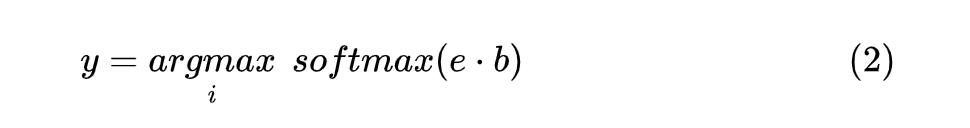
由于这里使用了 label 编码表征的方式,相比于其他的 NER 方法,在模型遇到新的数据和 label 时,不需要再初始一个新的顶层分类器,以此达到 Few-shot 的目的。
1.3 Label Transfer
在文章中作者还罗列了实验数据集的标签转换表,部分如下所示:
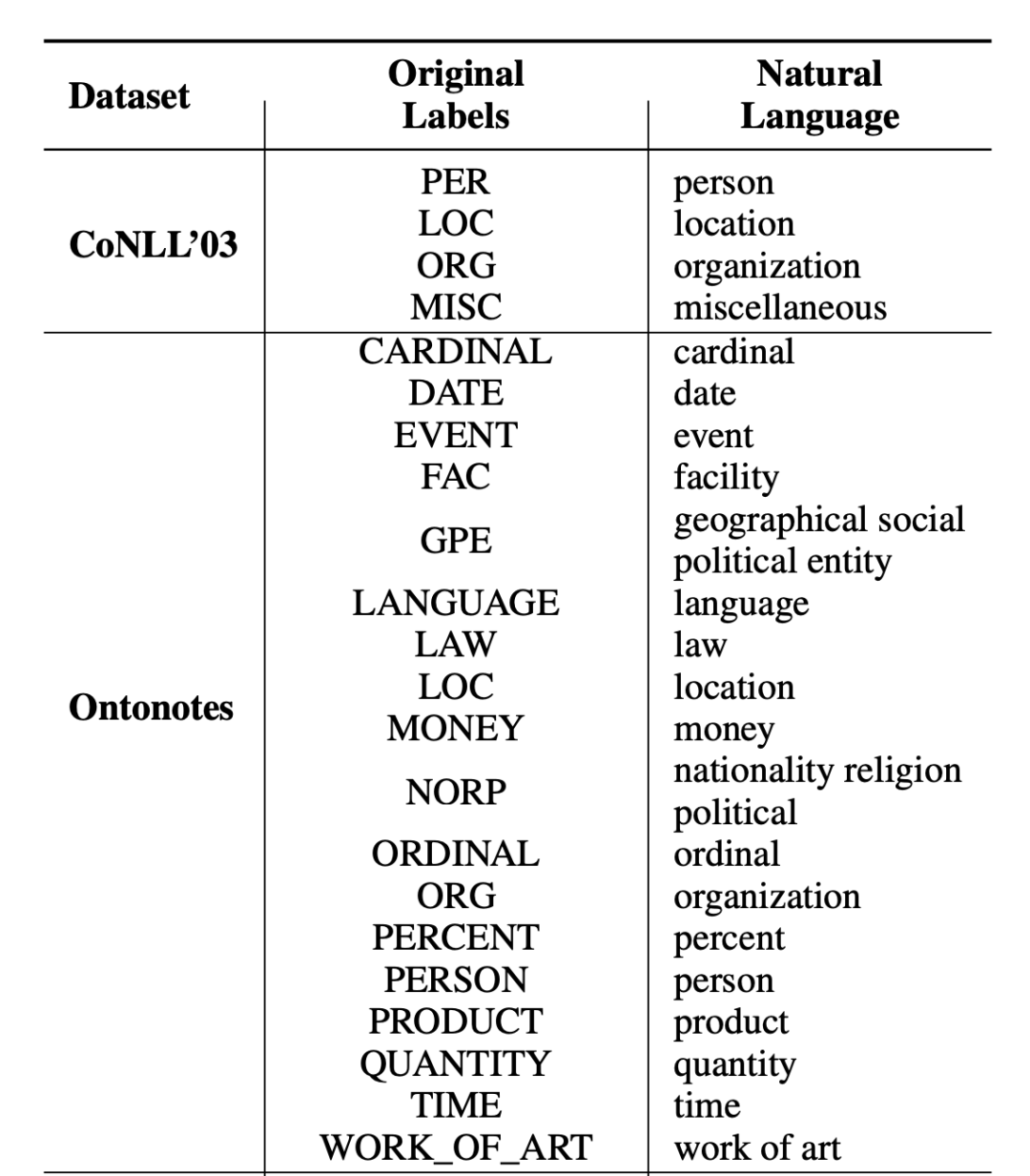
▲图2. 实验数据集Label Transfer
1.4 Support Set Sampling Algorithm
采样伪代码如下所示:

▲图3. 采样伪代码
2、实验结果
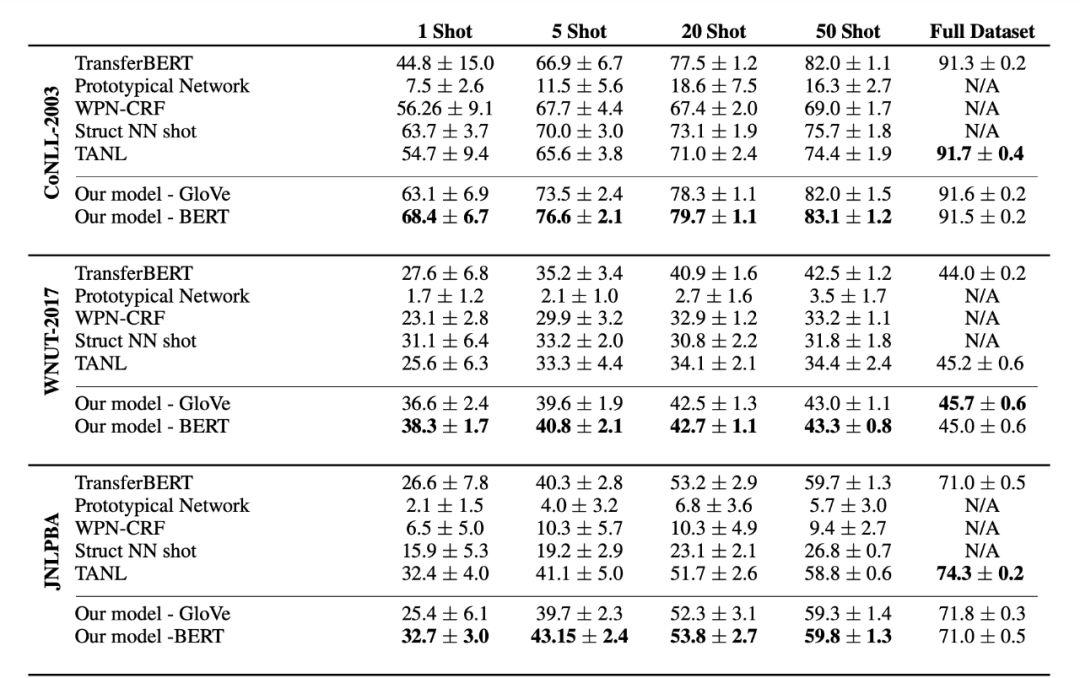
▲图4. 部分实验结果
从实验结果上看,可以明显的感受到这种方法在 Few-shot 时还是有不错的效果的,在 1-50 shot 时模型的效果都优于其他模型,表明了 label 语义的有效性;但在全量数据下,这种方法就打了一些折扣了,表明了数据量越大,模型对于 label 语义的依赖越小。这里笔者还有一点想法就是在全量数据下,这种方式的标签语义引入可能会对原本的文本语义发生微小偏移,当然,这种说法在 Few-shot 下也是成立的,只不过 Few-shot 下的偏移是一个正向的偏移,能够增强模型的泛化能力,全量数据下的偏移就有点溢出来的感觉。 双塔 BERT 代码实现(没有采用 metric-based 方法):
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2022/5/23 13:49
# @Author : SinGaln
import torch
import torch.nn as nn
from transformers import BertModel, BertPreTrainedModel
class SinusoidalPositionEmbedding(nn.Module):
"""定义Sin-Cos位置Embedding
"""
def __init__(
self, output_dim, merge_mode='add'):
super(SinusoidalPositionEmbedding, self).__init__()
self.output_dim = output_dim
self.merge_mode = merge_mode
def forward(self, inputs):
input_shape = inputs.shape
batch_size, seq_len = input_shape[0], input_shape[1]
position_ids = torch.arange(seq_len, dtype=torch.float)[None]
indices = torch.arange(self.output_dim // 2, dtype=torch.float)
indices = torch.pow(10000.0, -2 * indices / self.output_dim)
embeddings = torch.einsum('bn,d->bnd', position_ids, indices)
embeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1)
embeddings = embeddings.repeat((batch_size, *([1] * len(embeddings.shape))))
embeddings = torch.reshape(embeddings, (batch_size, seq_len, self.output_dim))
if self.merge_mode == 'add':
return inputs + embeddings.to(inputs.device)
elif self.merge_mode == 'mul':
return inputs * (embeddings + 1.0).to(inputs.device)
elif self.merge_mode == 'zero':
return embeddings.to(inputs.device)
class DoubleTownNER(BertPreTrainedModel):
def __init__(self, config, num_labels, position=False):
super(DoubleTownNER, self).__init__(config)
self.position = position
self.num_labels = num_labels
self.bert = BertModel(config=config)
self.fc = nn.Linear(config.hidden_size, self.num_labels)
if self.position:
self.sinposembed = SinusoidalPositionEmbedding(config.hidden_size, "add")
def forward(self, sequence_input_ids, sequence_attention_mask, sequence_token_type_ids, label_input_ids,
label_attention_mask, label_token_type_ids):
# 获取文本和标签的encode
# [batch_size, sequence_length, embed_dim]
sequence_outputs = self.bert(input_ids=sequence_input_ids, attention_mask=sequence_attention_mask,
token_type_ids=sequence_token_type_ids).last_hidden_state
# [batch_size, embed_dim]
label_outputs = self.bert(input_ids=label_input_ids, attention_mask=label_attention_mask,
token_type_ids=label_token_type_ids).pooler_output
label_outputs = label_outputs.unsqueeze(1)
# 位置向量
if self.position:
sequence_outputs = self.sinposembed(sequence_outputs)
# Dot 交互
interactive_output = sequence_outputs * label_outputs
# full-connection
outputs = self.fc(interactive_output)
return outputs
if __name__=="__main__":
pretrain_path = "../bert_model"
from transformers import BertConfig
token_input_ids = torch.randint(1, 100, (32, 128))
token_attention_mask = torch.ones_like(token_input_ids)
token_token_type_ids = torch.zeros_like(token_input_ids)
label_input_ids = torch.randint(1, 10, (1, 10))
label_attention_mask = torch.ones_like(label_input_ids)
label_token_type_ids = torch.zeros_like(label_input_ids)
config = BertConfig.from_pretrained(pretrain_path)
model = DoubleTownNER.from_pretrained(pretrain_path, config=config, num_labels=10, position=True)
outs = model(sequence_input_ids=token_input_ids, sequence_attention_mask=token_attention_mask, sequence_token_type_ids=token_token_type_ids, label_input_ids=label_input_ids,
label_attention_mask=label_attention_mask, label_token_type_ids=label_token_type_ids)
print(outs, outs.size())
审核编辑:郭婷
-
导gerber时,TOP SILK和BOT SILK层文本字符不显示2016-08-03 7009
-
并非所有字符都显示在文本字段或标签中2019-02-12 1196
-
css的文本字体概念2019-05-22 1189
-
labview采用TCP传输数据时转化字符串的编码格式是哪种?2019-08-22 5678
-
【Altium小课专题 第111篇】原理图上如何添加字符标注和文本框?2021-07-16 10959
-
LabVIEW编程更改字符串控件的文本字体颜色或大小2022-04-16 8154
-
如何优雅地使用bert处理长文本2020-12-26 9776
-
结合BERT模型的中文文本分类算法2021-03-11 1791
-
基于BP神经网络分类器的垃圾文本过滤模型2021-03-27 1390
-
一种基于BERT模型的社交电商文本分类算法2021-04-13 1360
-
基于BERT+Bo-LSTM+Attention的病历短文分类模型2021-04-26 1897
-
如何使用BERT模型进行抽取式摘要2022-03-12 5989
-
快速了解文本语义相似度领域的研究脉络和进展2022-08-16 1864
-
C++字符编码转换的基本方法2022-09-20 2598
-
如何在文本字段中使用上标、下标及变量2024-11-12 1457
全部0条评论

快来发表一下你的评论吧 !
