

NN模型在金融风控场景中的应用
描述
IEEE x ATEC
IEEE x ATEC科技思享会是由专业技术学会IEEE与前沿科技探索社区ATEC联合主办的技术沙龙。邀请行业专家学者分享前沿探索和技术实践,助力数字化发展。
在社会数字化进程中,随着网络化、智能化服务的不断深入,伴随服务衍生出的各类风险不容忽视。本期分享会的主题是《网络欺诈的风险与对抗》。五位嘉宾将从不同的技术领域和观察视角,围绕网络欺诈场景下的风险及对抗技术展开分享。
以下是庄福振研究员的演讲,《NN模型在金融风控场景中的应用》。
《NN模型在金融风控场景中的应用》
很高兴能来参加IEEE x ATEC科技思享会。我今天分享的题目是《NN模型在金融风控场景中的应用》。我今天的演讲内容主要分成三个部分:背景,研究工作,我们的一点总结。
众所周知,在过去十几年中,第三方在线支付市场发展迅速。同时,与在线交易相关的犯罪活动也大大增加,并且这种交易欺诈行为严重威胁了在线支付行业。2016年,互联网犯罪投诉中心就收到了近380万投诉,导致超过13亿的财务损失。在线交易欺诈中,最常见的是账户被盗以及卡被盗。账户被盗指的是未经授权的账户操作或欺诈者在控制了某人的付款账户后进行的交易,通常由于凭证泄露造成的。卡被盗表示某人卡的相关信息,例如卡号、账单信息等已被欺诈者获取并用于未经授权的一些收费。
下面我分享一下我们和蚂蚁集团联合做的一些研究工作。主要有三个工作,一个是基于神经层级分解机的用户事件序列分析(SIGIR 2020),第二个是基于双重重要性感知分解机的欺诈检测 (AAAI 2021),第三个是我们在可解释方面提出的利用层级可解释网络建模用户行为序列的跨领域欺诈检测 (WWW 2020)。
一、基于神经层级分解机的用户事件序列分析
首先是基于神经层级分解机的用户事件序列分析。在支付业务中,每个人都从注册系统、登录系统,再到把自己选择的商品放入购物车,最后做交易或者付款。根据用户的账户动态,我们可以判定下次付款到底是不是一个欺诈行为。用户的账户动态有丰富的数据序列信息可供利用。单纯只关注特征组合的工作或者单纯关注序列信息的工作,都只能从单独的角度去建模用户事件序列行为,每个事件仅通过简单的嵌入、拼接或者全连接,而难以获得更好的事件表示。我们希望设立一个层次化的模型同时结合这两方面进行建模,从而对欺诈检测进行分析。

右图有两个案例,一个是我们在豆瓣上看了电影(如图1),同样也是一个用户行为序列,这里面最大的一个贡献是怎么去做这个事件的表示。我们刚才看到,每个事件实际上都包含了很多的特征。

如图2所示,一个事件的特征包含X1到Xn这么多个特征。我们在用户的事件序列里,包括e1到eT的T个事件,每个事件在场景里面有56个特征,包括50个类别型特征和6个数字型特征。事件内部的特征之间的组合实际上更具判别性地来判定、预测欺诈检验。例如在1分钟之内进行的跨国交易,我们就很容易判断这是一笔盗卡行为。我们希望用FM模型去建模这种特征组合关系。FM是一种在嵌入空间中自动进行二阶特征组合的模型。看一下(图2)事件的表示:vi跟vj是两个特征的向量化的空间的表示,它是两两特征之间的一个组合,Xi跟Xj实际上是一个权重的表示。最后我们会得到一个事件的表示,从特征的交互得到一个特征的事件表示。

当这个事件表示完后,我们希望得到一个比较好的序列表示,即我们对这个序列进行提取一个比较好的特征表示。每个用户序列实际上包含多个事件,两个事件组合发生,对欺诈行为检测更具有判别性。同样的,我们也希望去考虑事件之间的序列的影响。比如说我们先做A事件再做B事件,可能会导致欺诈的可能性变大。我们希望我们的模型能够去建模这种序列的影响。从刚才的角度出发,事件组合的建模,我们用S来表示,同样也是因子分解机去做的。不同事件两两组合,qi和qj也是它的一个权重。对于序列影响,我们从两方面去考虑,一是从事件自身的重要性去考虑,它有一个自注意力机制来表示就是Sself;还有一个是我们用RNN网络来去建模事件的历史序列行为信息,也就是双向的LSTM去建模。最后,我们可得出这个序列是由三部分组成:事件的组合;事件的自注意力机制;事件本身具有的一个特征。把三者组合在一起得到整体的序列表示。
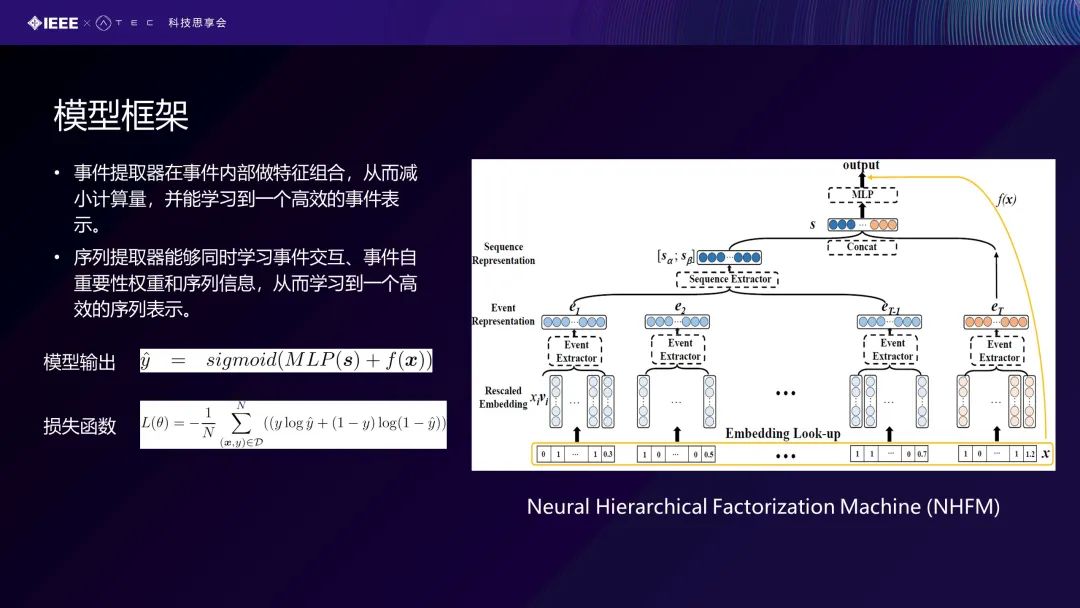
右边这张图是我们提出的一个框架,也叫做神经层级分解机。从底部开始,是有事件的特征。我们对哪个事件特征进行编码后,就可以去做这个事件的表示,学习做这个序列的提取。提取后,我们可以看到模型做一个多层感知机的输出。我们同样可以在这个Feature上面去做一个线性的分类。最终我们把这两部分当成一个Sigmoid的一个参数,得到0到1之间的输出,我们最终的一个优化函数其实是一个交叉熵的损失函数,N是对所有有标记的数据进行学习。这是我们的模型的一个框架。

在这个实验中,我们利用工业界里面的一个真实的数据集。例如LAZADA这样一个东南亚的电商平台,我们从这个平台上面拿到了三个国家的数据集。这个数据集正例是欺诈行为,负例是正常的交易行为,可以看到正常交易行为和异常的欺诈行为,相差非常大、类别非常不平衡。我们的公开数据集上、电影上的数据集也做了一个实验。在基准的算法比较上,我们采用了比较先进的一些算法,比如W&D(Wide & deep)宽度和深度,还有NFM、DeepFM、xDeepFM,以及M3利用混合模型同时学习序列的长短期依赖的模型。
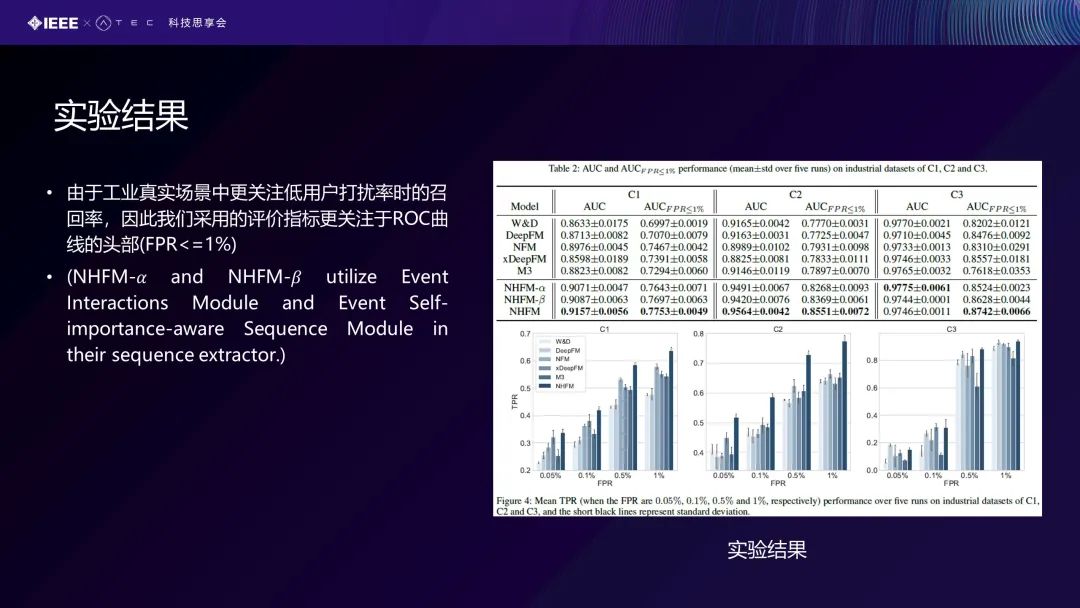
我们的评价指标是采用真实工业场景里面比较关注的低用户打扰率时的召回率,即我们在给出结果时,我们希望对前面头部的百分之多少的用户打电话告诉他们这可能是一个欺诈行为。例如打1000个电话,这1000个应该都是有欺诈行为,即这个比例应该是越高越好的,因此我们采用的评价指标更关注于ROC曲线的头部(FPR<=1%) 。这里面有一个消融的
审核编辑 :李倩
-
中软国际金融AI能力获权威报告认可2026-04-14 492
-
商汤科技与海通证券携手发布金融行业首个多模态全栈式大模型2024-05-06 1124
-
华为云盘古大模型通过金融大模型标准符合性验证2024-03-05 1788
-
金融行业迎来大模型时代,存算基建成决胜关键2023-09-25 977
-
PyTorch中nn.Conv2d与nn.ConvTranspose2d函数的用法2023-01-11 7352
-
游戏AI代理的设计方式以及生成的神经网络 (NN) 模型的外观解析2022-08-15 2391
-
使用Streamline分析在Linux上运行的Arm NN机器学习应用程序2022-08-11 3007
-
人工智能在金融风控领域的应用: 声纹反欺诈2020-03-21 1796
-
区块链软件开发公司谈区块链在供应链金融场景中的应用2018-11-21 2944
-
汽车金融风控的黑科技—超级GPS2018-09-17 453
-
智信通:如何破除汽车金融风控行业困境?2018-08-16 495
-
风电功率爬坡气象场景分类模型2018-03-21 1145
-
松下NN-5508 NN-5558 NN-6508 NN-72009-02-13 1457
全部0条评论

快来发表一下你的评论吧 !
