

生成式摘要的经典模型
描述
写在前面
在一文详解生成式文本摘要经典论文Pointer-Generator中我们介绍了生成式摘要的经典模型,今天我们来分享一篇带风格的标题生成的经典工作。

以往的标题模型产生的都是平实性标题,即简单语言描述的事实性标题。但是,实际上我们可能更需要有记忆点的爆款标题来增加点击量/曝光率。因此,衍生出了一个新任务——带有风格的标题生成,即 Stylistic Headline Generation,简称 SHG 。
本篇文章将介绍 TitleStylist 模型,该模型是针对 SHG 任务提出的,它可以生成相关、通顺且具有风格的标题,其中风格主要包括三种:幽默、浪漫、标题党。
论文名称:《Hooks in the Headline: Learning to Generate Headlines with Controlled Styles》
论文链接:https://arxiv.org/abs/2004.01980v1
代码地址:https://github.com/jind11/TitleStylist
1. 问题定义
首先假设我们有两类数据和:是由文章-标题对组成的数据;是由具有某种特定风格的句子组成的数据。
我们用来表示数据,其中表示文章,表示标题。此外,我们用来表示数据。需要注意的是,中的句子可以是书本中的句子,不一定是标题。
假设我们有、、。那么,SHG 任务目的是从中学习,也就是从分布、中学习出条件分布。
2. 核心思想
TitleStylist 模型整体上是一个 Transformer 结构,分为Encoder(编码器)和Decoder (解码器)。TitleStylist 利用多任务学习,同时进行两个任务:
标题生成:有监督任务;在数据S上,根据文章原文生成相应标题。
带有风格的文本重构:无监督或自监督;在数据上,输入为扰乱后的句子,生成原句。
标题生成与带有风格的文本重构两个任务的数据集和模型都是独立的。为了生成带有风格的标题,TitleStylist 通过参数共享将二者融合。
3. 模型细节
3.1 序列到序列模型架构(Seq2Seq Model Architecture)
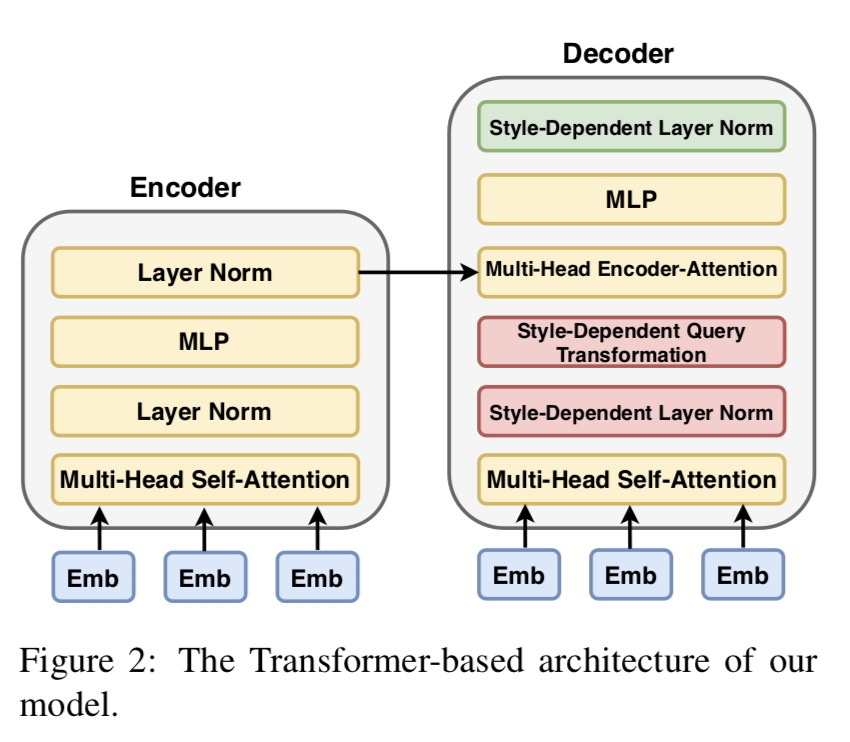
如上图,TitleStylist 采用了 Transformer 架构的 seq2seq 模型,它包含编码器和解码器。为了提高生成的标题的质量,TitleStylist 使用 MASS 模型来初始化模型参数。
3.2 多任务学习
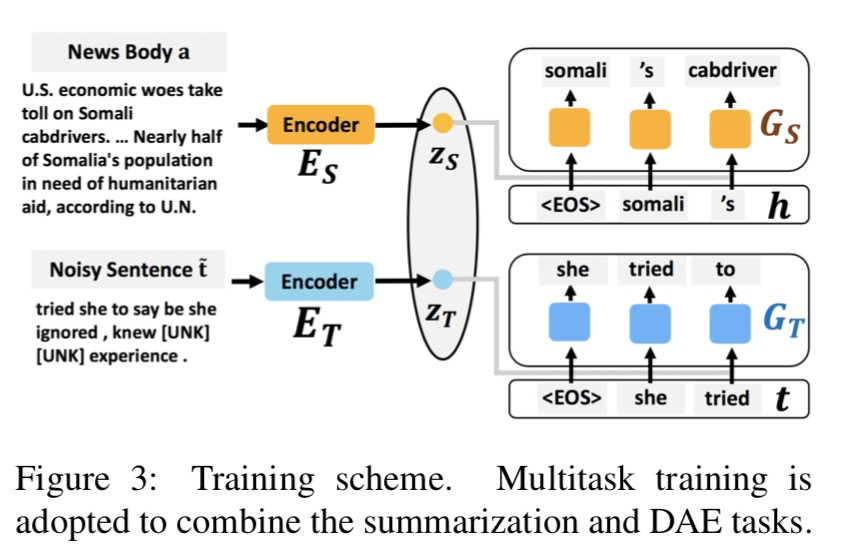
为了分离文本的风格和内容,模型引入 多任务学习 框架。在这里主要包含两个任务:标题生成 及 DAE (Denoising Autoencoder)。根据论文描述,我们在这里将 DAE 称为带风格的文本重构。
有监督的标题生成
在标题生成任务中,首先我们输入文章原文,然后经过编码器获得向量表征;接着,再利用解码器生成标题。
换句话说,在标题生成任务中,我们是利用编码器和解码器学习条件分布。我们设是编码器的待优化参数,是解码器的待优化参数,那么标题生成任务的损失函数如下:
其中是单向语言模型,即:
这里代表句子的长度。
无监督/自监督的风格文本重构
在文本重构任务中,对于句子,我们通过随机删除或者遮盖某些词,或者改变文本中词的顺序可以获得破坏版本的句子。将作为模型输入,经过编码器获得中间表征,再经过解码器进行还原获得。这个任务的目的是在还原句子时使模型学到风格化句子的能力。
同样我们设是编码器的待优化参数,是解码器的待优化参数,那么文本重构任务的损失函数如下:
联合学习
最终,多任务学习会最小化将两部分的损失函数之和:
3.3 如何生存带有特定风格的相关标题
到目前为止,大家可能会有所疑问:两个任务除了损失函数是一同优化外再没有看到其他任何关联, 那么 TitleStylist 怎么可能学到问题部分定义的终极目标,毕竟我们只有来自分布、的数据,并没有来自分布的数据。
实际上,TitleStylist 通过设计参数共享策略,让两个任务的编码器及解码器存在某种关联,最终以此来建模。那么如何进行参数共享呢?
最简单的,可以直接共享所有参数(与共享,与共享)。这样模型等于同时学了标题生成与带风格的文本重构两个任务。其中标题生成的任务让模型学到了如何生成与文章内容相关的标题;带风格的文本重构则让模型学到了如何在还原文本时保留文本具有的风格。在两个任务的相互加持下,模型就可以生成和文章相关的又具有特定风格的标题。
好了,我们就想到这里。接下来看看 TitleStylist 究竟是怎么做的。
3.4 参数共享
刚才我们所说的直接共享所有参数的方式存在一个问题,就是模型并没有真正地显式地区分开文本内容与文本风格,那么模型就是又学了中的事实性风格,又学了中的特定风格(比如幽默、浪漫或标题党)。
TitleStylist 为了更好地区分开文本内容与文本风格,显式地学习数据中所包含的风格,选择让编码器共享所有参数,解码器共享部分参数。个人认为编码器端之所以完全共享参数,是想在编码时尽可能保留原文信息。
如上图所示,解码器端的参数主要被分成两部分:黄色部分表示不依赖风格的参数,是共享的;剩余依赖风格的参数,不共享。
具体地,存在于 Layer Normalization 及 Decoder Attention,即 层归一化及 解码器注意力 两部分:
(1) 带风格的层归一化(Style Layer Normalization)
带风格的层归一化 这个部分是借鉴 图像风格迁移 的思想。其中分别是的的均值和标准方差,是模型需要学习的与风格相关的参数。
(2) 带风格的解码器注意力(Style-Guided Encoder Attention)
TitleStylist 认为两个任务的解码器端在逐个生成下一个词时的注意力机制应该有所不同。在这里,TitleStylist 主要是设置了不同的 ,以此生成不同的 从而形成不同的注意力模式。
这里代表风格,对 标题生成 而言其实可以算作事实性风格;对 文本重构 而言,可能是幽默、浪漫或标题党风格。
TitleStylist 结合完全共享参数的编码器与部分参数共享的解码器来实现其目标模型,最终可以生成带有特定风格的又与原文内容相关的标题。
总结
好了,带风格的标题生成论文《Hooks in the Headline: Learning to Generate Headlines with Controlled Styles》的内容就到这里了。在本篇文章中,我们就论文思想与论文所提出的模型的结构设计进行了介绍。论文实验部分小喵没有细看,大家感兴趣的话可以下载原文并结合源码进行学习。
审核编辑 :李倩
-
基于图集成模型的自动摘要生产方法2021-03-22 1054
-
融合文本分类和摘要的多任务学习摘要模型2021-04-27 1629
-
基于条件生成式对抗网络的面部表情迁移模型2021-05-13 1108
-
基于语义感知的中文短文本摘要生成技术2021-05-28 981
-
如何使用BERT模型进行抽取式摘要2022-03-12 5989
-
摘要模型理解或捕获输入文本的要点2022-11-01 1886
-
SOTA生成式模型:9大类别21个模型合集2023-02-23 1850
-
LLM在生成摘要方面效果到底如何?2023-09-21 1215
-
联想携手京东,紧扣大模型和生成式AI技术2024-04-12 1672
-
生成式 AI 进入模型驱动时代2024-04-13 1392
-
生成式AI与神经网络模型的区别和联系2024-07-02 2775
-
经典卷积网络模型介绍2024-07-11 2772
-
声智完成多项生成式算法和大模型服务备案2024-07-23 1517
-
NVIDIA推出全新生成式AI模型Fugatto2024-11-27 1527
-
生成式人工智能模型的安全可信评测2025-01-22 2009
全部0条评论

快来发表一下你的评论吧 !
