

FPGA程序中内存的实现方式
可编程逻辑
描述
Xilinx zynq系列FPGA实现神经网络评估
本篇目录
1. 内存占用
1.1 FPGA程序中内存的实现方式
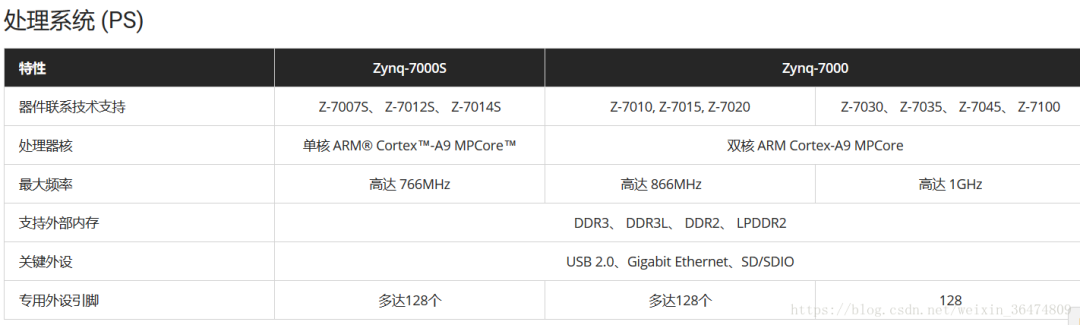
1.2 Zynq的BRAM内存大小
1.3 一个卷积操作占用的内存
2. PipeCNN可实现性
PipeCNN论文解析:用OpenCL实现FPGA上的大型卷积网络加速
2.1 已实现的PipeCNN资源消耗
3. 实现大型神经网络的方法
4. Virtex-7高端FPGA概览、7系列FPGA相关文档
正文
0 Zynq7000系列概览
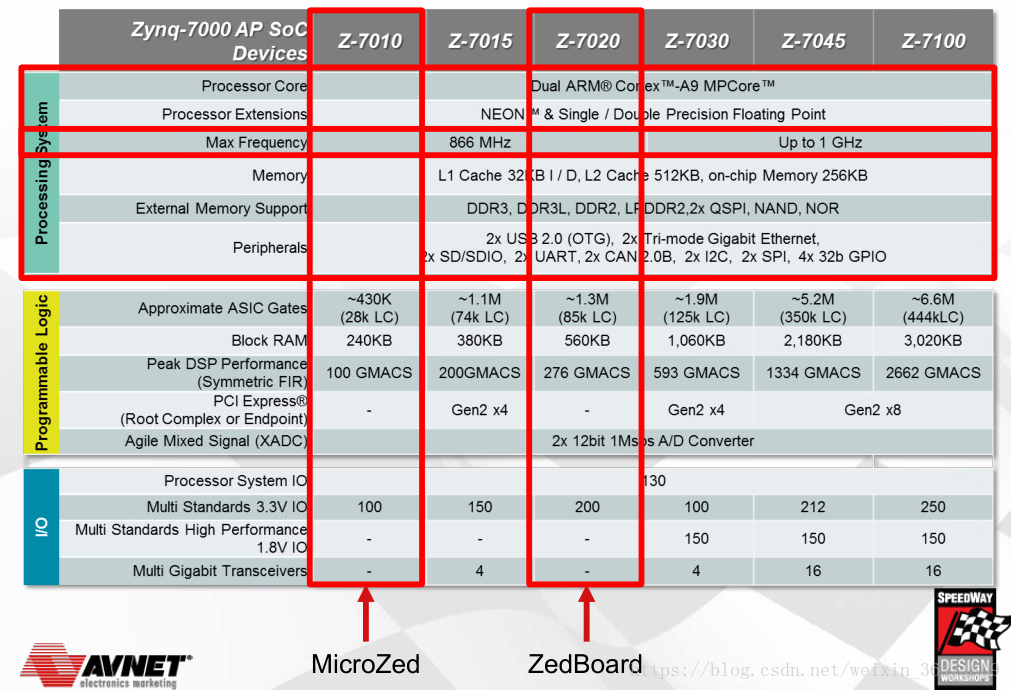
1 内存占用
1.1 FPGA程序中内存的实现方式
参阅xilinx文档UG998

FPGA并没有像软件那样用已有的cache,FPGA的HLS编译器会在FPGA中创建一个快速的memory architecture以最好的适应算法中的数据样式(data layout)。因此FPGA可以有相互独立的不同大小的内部存储空间,例如寄存器,移位寄存器,FIFOs和BRAMs。
寄存器:最快的内存结构,集成在在运算单元之中,获取不需要额外的时延。
移位寄存器:可以被当作一个数据序列,每一个数据可以在不同的运算之中被重复使用。将其中所有数据移动到相邻的存储设备中只需要一个时钟周期。
FIFO:只有一个输入和输出的数据序列,通常被用于循环或循环函数,细节会被HLS编译器处理。
BRAM:集成在FPGA fabric模块中的RAM,每个xilinx的FPGA中集成有多个这样的BRAM。可以被当作有以下特性的cache:1.不支持像处理器cache中那样的缓存一致性(cache coherency,collision),不支持处理器中的一些逻辑类型。2.只在设备有电时保持内存。3.不同的BRAM块可以同时传输数据。
1.2 Zynq的BRAM内存大小
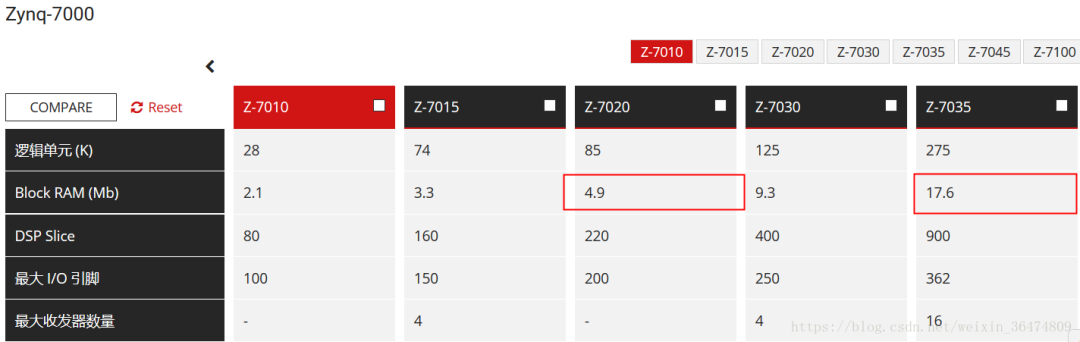
zynq 7z020的BRAM为4.9Mb,7z035的BRAM为17.6Mb(2.2MB)
1.3 一个卷积操作占用的内存
例如,我们实现的卷积函数,输入27×600,卷积核16×27,输出16×600,数据类型为float。
//convolution operation for (i = 0; i < 16; i++) { for (j = 0; j < 600; j++) { result = 0; for (k = 0; k < 27; k++) { temp = weights[i*27+k] * buf_in[k*600+j]; result += temp; } buf_out[i*600+j] = result; } }
在HLS中生成的IPcore占用硬件资源为:
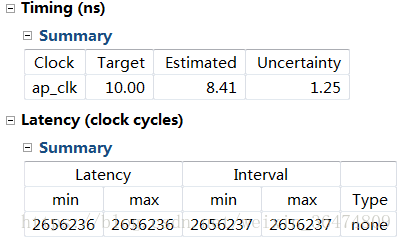
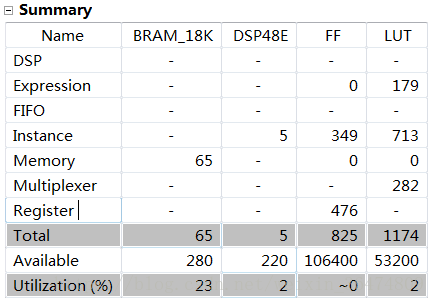
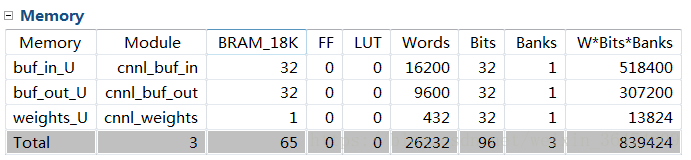
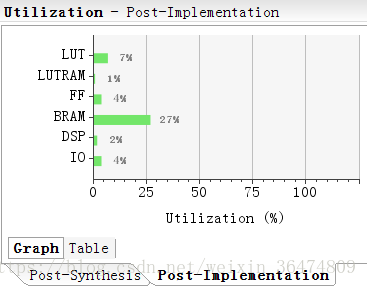
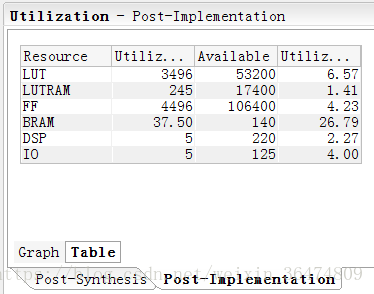
在vivado中搭建好系统,占用的资源为:
2 PipeCNN可实现性
PipeCNN是一个基于OpenCL的FPGA实现大型卷积网络的加速器。
PipeCNN解析文档:
PipeCNN论文解析:用OpenCL实现FPGA上的大型卷积网络加速
github地址:https://github.com/doonny/PipeCNN#how-to-use
2.1 已实现的PipeCNN资源消耗
对于Altera FPGA,运用 Intel's OpenCL SDK v16.1 toolset.
对于Xilinx FPGAs, the SDAccel development environment v2017.2 can be used.

Xilinx's KCU1500 (XCKU115 FPGA)(已经有xilin的板子实现过pipeCNN,但是型号比zynq高很多)
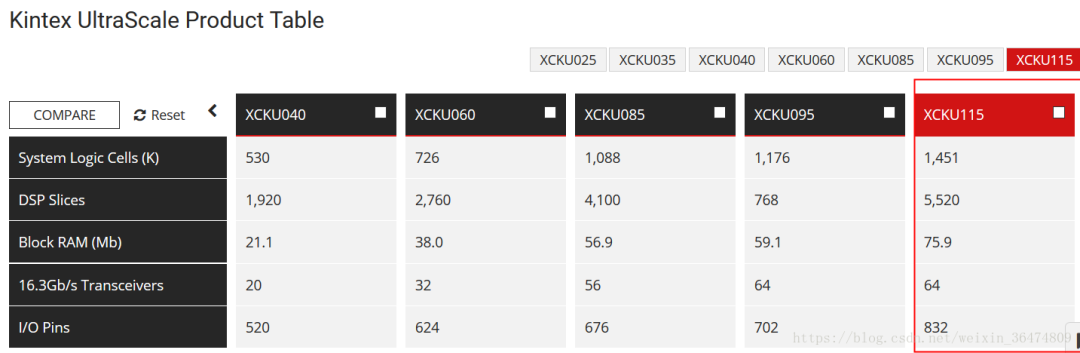
硬件资源可以被三个宏调控,device/hw_param.cl. Change the following macros
VEC_SIZE
LANE_NUM
CONV_GP_SIZE_X
消耗资源为:
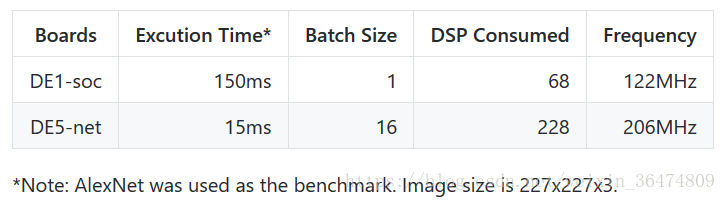
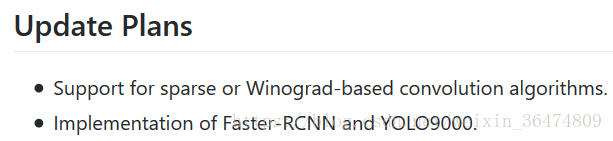
3 实现大型神经网络的方法
方案一:压缩模型到<2.2MB,可实现在BRAM中
优点:1.速度快 2.实现方便
缺点:1.模型压缩难度 2.难以实现大型网络
方案二:用FPGA调用DDR
优点:1.速度中等 2.可实现大型网络
缺点:调用DDR有难度,开发周期长
方案三:用片上单片机调用DDR(插入SD卡)分包传入IPcore运算
优点:可实现大型网络
缺点:速度较慢
4 Virtex-7高端FPGA概览
Virtex-7为高端FPGA,比Zynq高了一个档次。
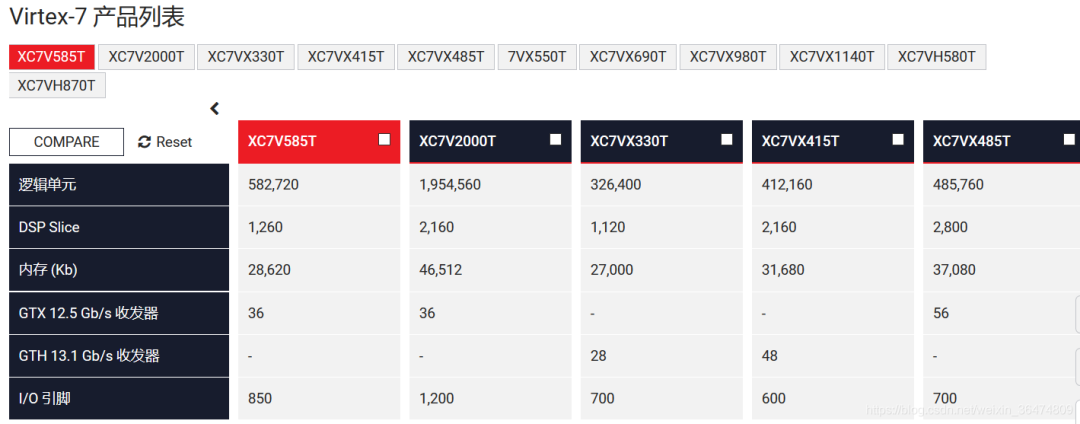
7系列FPGA相关文档:

原文标题:Xilinx Zynq系列FPGA实现神经网络中相关资源评估
文章出处:【微信公众号:FPGA技术江湖】欢迎添加关注!文章转载请注明出处。
-
C语言程序设计中动态内存分配如何实现2023-09-28 2453
-
怎么将数据加载到FPGA的内存中2019-05-06 4408
-
嵌入式系统中FPGA 的被动串行配置方式2009-04-15 600
-
FPGA对DDRSDRAM内存条的控制2010-06-29 3233
-
在FPGA上实现CRC算法的程序2016-06-07 1181
-
FPGA的程序下载方式详细资料概述2018-10-31 1978
-
浅谈内存分配方式 避免内存浪费问题2019-03-03 1887
-
单片机的程序在内存和FLASH中应该如何进行空间分配2019-09-18 1649
-
7 eries FPGAs SPI MultiBoot实现方式2020-12-11 2730
-
使用FPGA实现电子琴设计的程序与仿真资料免费下载2021-01-18 1344
-
如何用OpenCL实现FPGA上的大型卷积网络加速?2021-04-19 3656
-
程序员眼里的内存(中)2023-02-24 1231
-
FPGA复位电路的实现方式2023-05-25 4920
-
程序内存分区中的堆与栈2023-11-11 1880
-
malloc 申请内存的两种方式2023-11-13 4509
全部0条评论

快来发表一下你的评论吧 !
