

采用HBEns的轨迹预测模型设计
描述
摘要:轨迹预测是自动驾驶系统中不可或缺的一环,对帮助理解车体周围环境和其它人、车的意图有着至关重要的作用。在2022年Waymo自动驾驶数据集挑战赛上,地平线使用了HBEns模型框架,基于“在单模型的输出上使用模型聚合”的二阶段思路,大幅提升了总体轨迹预测精度,同时给予了较高的模型设计自由性。
简介
给定一份道路地图和周围所有可观测的物体的历史轨迹,轨迹预测模型的任务是将目标物体的未来轨迹预测出来。现阶段的轨迹预测模型根据输入编码类型的不同可以分成基于栅格(raster-based)、基于矢量(vector-based)和基于图(graph-based)这三大类。基于栅格的模型一般通过卷积神经网络(CNN)编码信息;另两种则侧重于使用transformer结构或其他图算法进行地图、物体的编码。从工程角度而言,两者各有优劣:CNN已被广泛应用多年,硬件加速成熟,但和近几年才发展起来的transformer相比存在地图输入尺寸受限、预测精度低等问题。综合考虑,HBEns建立在“基础模型(base models)+模型聚合(model ensemble)”的思想上(图1)。对于模型聚合来说,前面的基础模型即相当于一个黑盒,从而赋予模型设计很大的自由性。
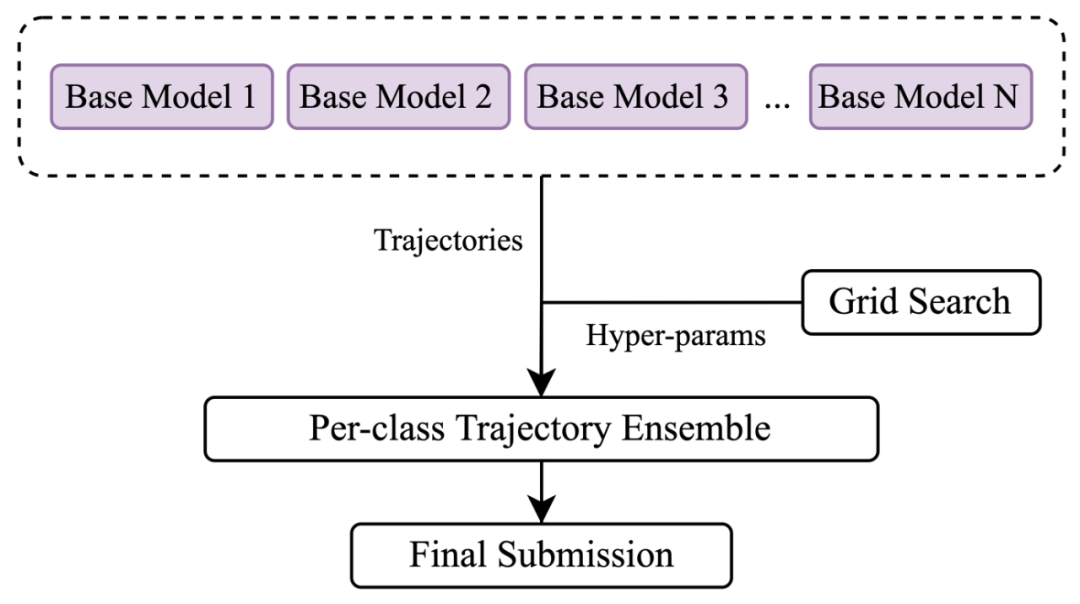
图1 HBEns流程图。多个基础模型的结果通过分类别的轨迹聚合实现最后输出,轨迹聚合的参数通过网格调参实现。
方法
基础模型沿用了HOME和MultiPath++的设计,并在此基础上增加了新特性。对于自行车、行人等运动速度较慢的物体,基于栅格的HOME模型性能优异;对运动较快的汽车,基于矢量输入的MultiPath++则更胜一筹。
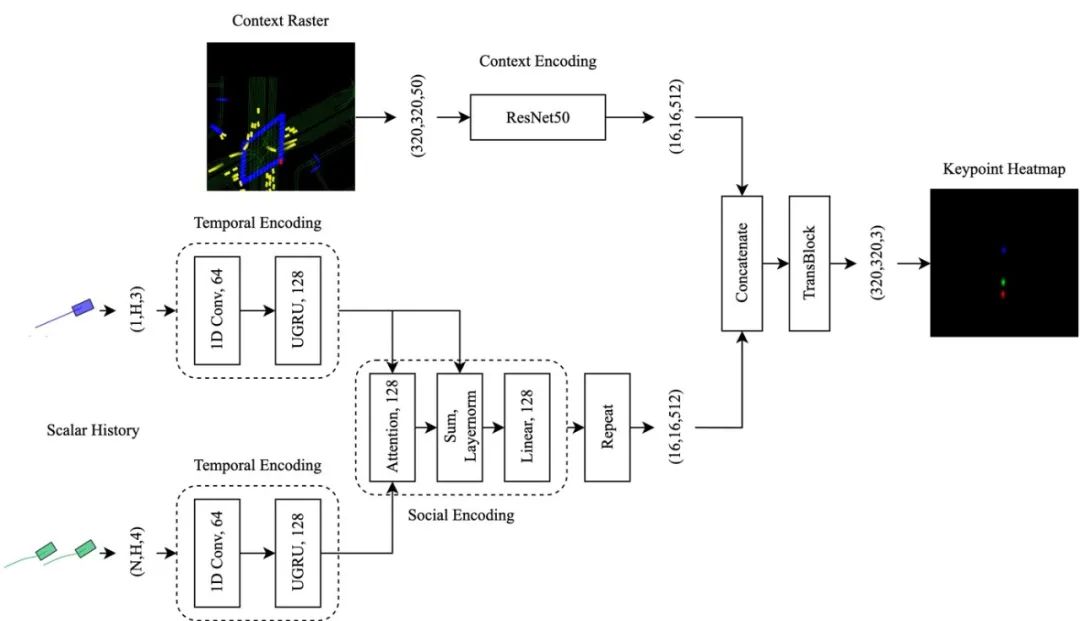
图2 基于HOME模型的第一阶段结构 HOME模型是一个二阶段模型,其一阶段结构见图2。自车轨迹、周围物体轨迹和地图信息分三路分别完成编码,目标物体信息和周围物体信息还会进行一次attention操作来增强信息互动。原始的HOME输出的是物体最后所在位置的热力点图,HBEns则采用了3/5/8s共三个点的位置生成热力图,来加强监督过程。 第二阶段(图3)采用了轻量级的CNN和源自MultiPath++的多语境门控机制(multi-context gating, MCG)来解决原始HOME无法较好处理低清热力图的问题。MCG模块的功能类似于attention,目的是将3/5/8s的信息融合编码进目标物体的轨迹信息中。
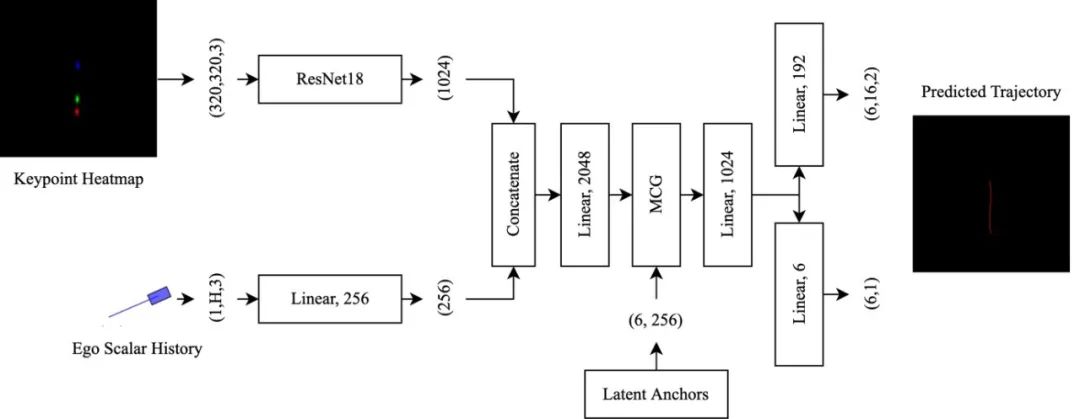
图3 CNN+MCG门控机制实现第二阶段从热力图到轨迹的输出 针对MultiPath++模型,两种不同的输入表示被采用:1)选取距离目标物体最近的256个地图标记(包括中心线、路沿、车道线等);2)仅选取128个距离目标物体最近的车道中心线标记。选取的过程采用了广度优先搜索(BFS)算法。每个标记额外拥有一个0-1矢量来注记它的其他特性(如是否位于斑马线、减速带内)。模型结构上,在不损失精度的前提下,采用GRU模块替换了MultiPath++原有的LSTM模块。
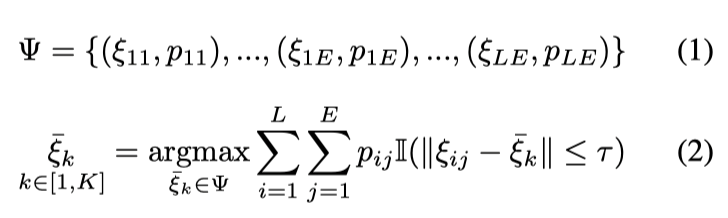
图4 基于贪婪策略的轨迹选择。每根轨迹由坐标点ξ和置信度p描述。每一轮迭代中,在给定距离阈值τ条件下,贪婪策略优先选择阈值范围内所有轨迹的置信度总和最高的轨迹作为中心轨迹。阈值内的其他轨迹在下一轮不参与选取。 HBEns对MultiPath++中的模型聚合(model ensemble)进行了一定的改进并实验了一些新的想法。执行模型聚合之前,首先利用一个聚类算法从所有输入的轨迹中选取K根作为“中心轨迹”。聚类算法可以通过贪婪策略(greedy)或非极大值抑制(NMS)来实现。贪婪策略倾向于选择周围轨迹较为集中的作为中心(图4),而NMS则着眼于每根轨迹的置信度,每次选择置信度最高的轨迹,并将周围的一定范围内的其他轨迹抑制。完成中心选择后,采用最大期望算法(EM)进行迭代,完成轨迹的最终迭代更新。
实验结果
模型聚合的步骤存在多种可调参数,因此网格调参可以帮助搜索到最优的参数配置。对于自行车和行人等行动方向更扩散的物体,NMS在聚合中的效果更优;车辆则一般沿着既定的车道线行驶,因此贪婪策略的中心点选择效果更好。表1综合了网格调参后每个类别的最优参数配置。表2的实验结果证明,模型聚合对提升单个模型的预测准确度有着显著的帮助。

表1 针对每个类别的网格搜参结果
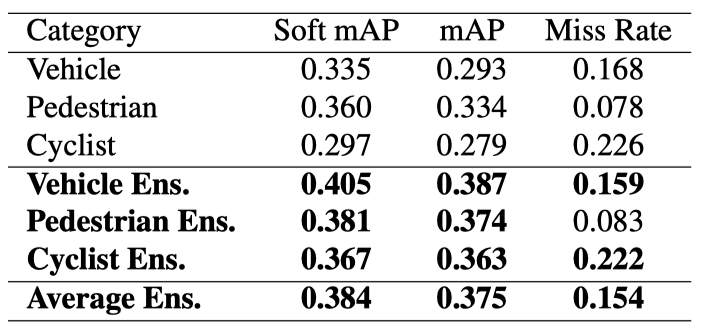
表2 验证集上模型聚合前后的mAP指标变化
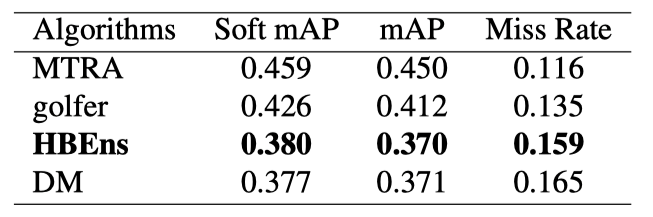
表3 测试集上HBEns排名
可视化结果
下图是HBEns结果的可视化。其中蓝色代表实车轨迹,青色代表模型预测轨迹,黑色代表道路中心线轨迹,红色为路沿,黄色为斑马线区域。模型共输出6条可能的轨迹及其置信度,来预测物体未来的前进方向。
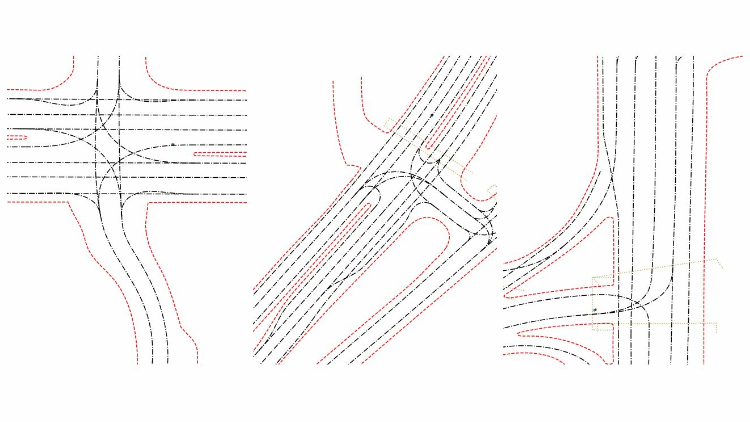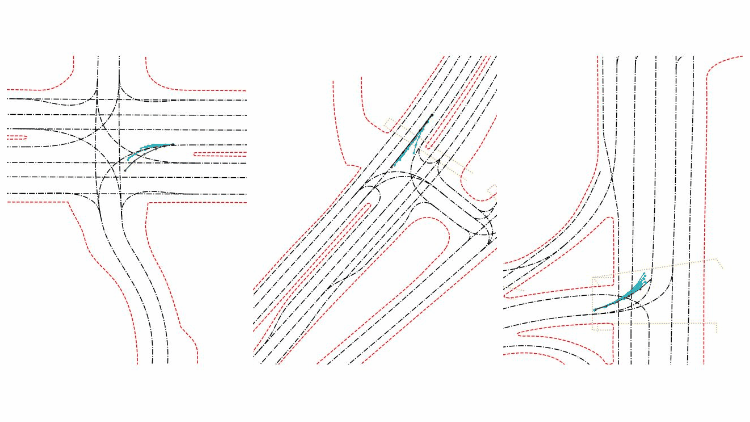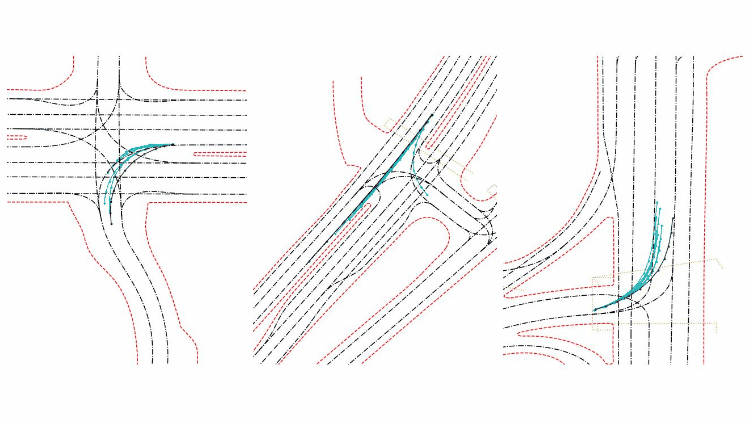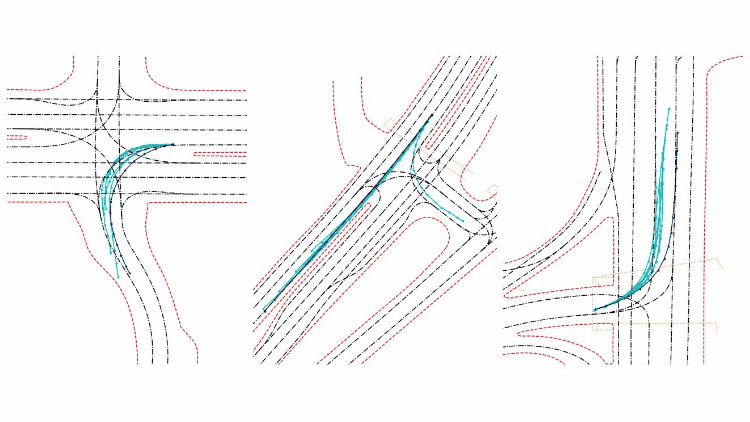
总结
HBEns模型框架采用了“基础模型+模型聚合”的思路,使得模型拥有较大的设计空间,可针对不同的类型、数据集做出优化。基于EM算法的模型聚合作为后处理步骤,显著提高了仅使用单模型进行预测的精度。
审核编辑:汤梓红
-
电磁轨迹预测分析系统软件全面解析2025-04-12 1221
-
电磁轨迹预测分析软件2024-07-16 1536
-
电磁轨迹预测分析系统2024-06-25 1296
-
蘑菇车联论文入选IEEE 轨迹预测模型可提高轨迹预测的泛化能力2023-10-13 2190
-
软件集成和轨迹预测开源分享2023-02-09 874
-
模型预测控制介绍2021-08-18 2777
-
船舶自动识别系统轨迹序列预测模型2021-05-07 1142
-
如何使用注意力机制进行行人轨迹预测生成模型的详细资料说明2019-04-04 1738
-
如何使用Adaboost Markov模型进行移动用户位置预测方法的详细资料说明2019-03-28 1214
-
基于迭代网格划分和熵的稀疏轨迹预测算法2017-12-29 1140
-
基于移动模式匹配的目标轨迹预测算法2017-12-27 973
-
前缀投影技术的大规模轨迹预测模型2017-12-25 1836
-
基于加权灰色GM模型的动态轨迹预测算法2017-12-19 645
-
基于Web行为轨迹的防御模型2017-12-07 1053
全部0条评论

快来发表一下你的评论吧 !
