

如何从notebook实验过渡到云中部署
描述
当您开始研究一个新的机器学习问题时,我猜您首先会使用的环境便是 notebook。也许您喜欢在本地环境中运行 Jupyter、使用 Kaggle Kernel,或者我个人比较喜欢使用的 Colab。有了这些工具,创建并进行机器学习实验变得越来越便利。尽管在 notebooks 中进行实验时一切顺利,但在您将实验提升到生产环境时,很容易碰壁。突然间,您的关注点不再只是追求准确度上的高分。
如果您有长时间运行的作业,如进行分布式训练或是托管一个在线预测模型,这时该怎么办?亦或您的用例需要有关安全性和数据隐私的更细粒度的权限,您的数据在使用期间会是怎样的?您将如何处理代码更改,或者如何随着时间推移监控模型的表现?
要打造生产级应用或训练大型模型,您需要额外的工具来帮您实现扩缩,而不仅仅是在 notebook 中编写代码。使用云服务提供商可以帮助解决这个问题,但这一过程可能会让人感到有点望而生畏。如果浏览一下 Google Cloud 产品的完整列表,您可能完全不知道该从何入手。
因此,为了让您的旅程更轻松,我将向您介绍从实验性 notebook 代码到云中部署模型的快速路径。
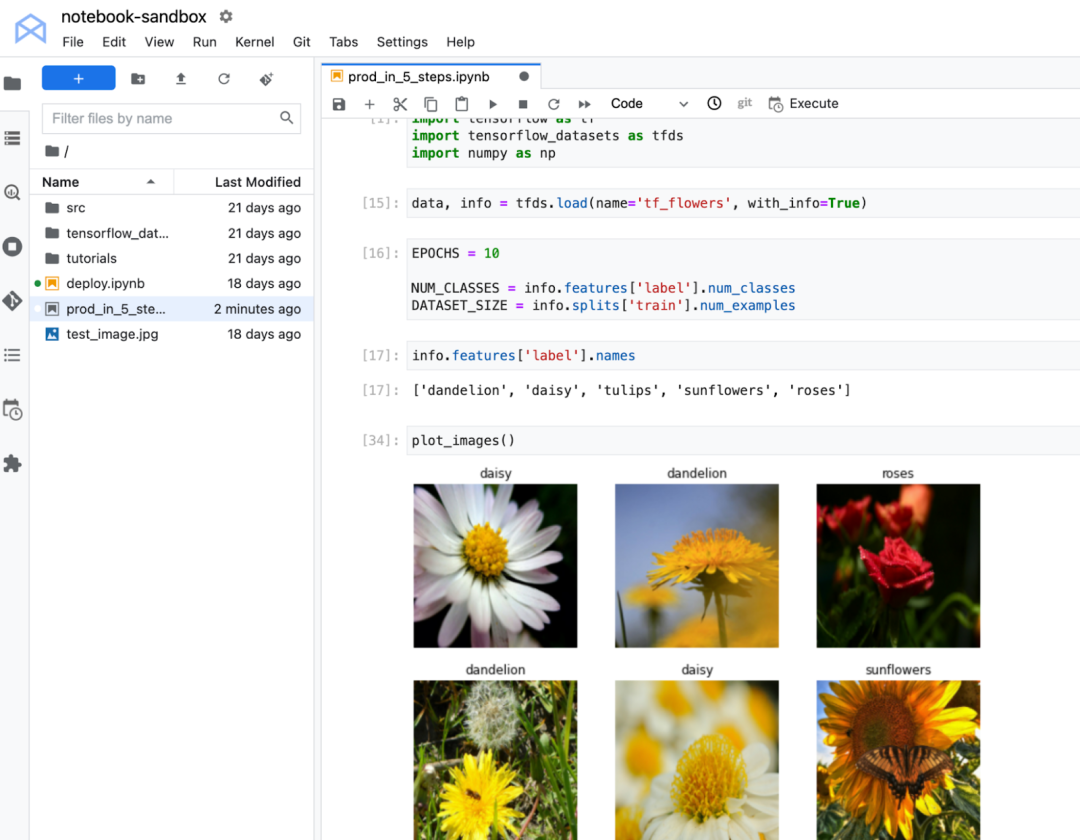
您可以在此处获取本示例中使用的代码。此 notebook 在 TF Flowers 数据集上训练了一个图像分类模型。您将看到如何在云中部署该模型,并通过 REST 端点获取对新花卉图像的预测。
请注意,为了遵循此教程进行实验,您需要有一个启用计费功能的 Google Cloud 项目。如果您以前从未使用过 Google Cloud,可以按照此处的说明设置一个项目,并免费获得 300 美元赠金以进行实验。
以下是您需要采取的 5 个步骤:
1. 创建一个 Vertex AI Workbench 代管式 notebook
2. 上传 .ipynb 文件
3. 启动 notebook 执行
4. 部署模型
5. 获取预测
创建一个 Vertex AI Workbench 代管 notebook
要训练和部署该模型,您将使用 Google Cloud 的代管式机器学习平台 Vertex AI。Vertex AI 包含许多不同的产品,可以在 ML 工作流的整个生命周期中为您提供帮助。今天,您将使用其中的一些产品,让我们先从代管式 notebook 产品 Workbench 开始。
在 Cloud Console 的“Vertex AI”部分下,选择“Workbench”。请注意,如果这是您首次在项目中使用 Vertex AI,系统将提示您启用 Vertex API 和 Notebooks API。因此,请务必点击界面中的按钮来执行此操作。
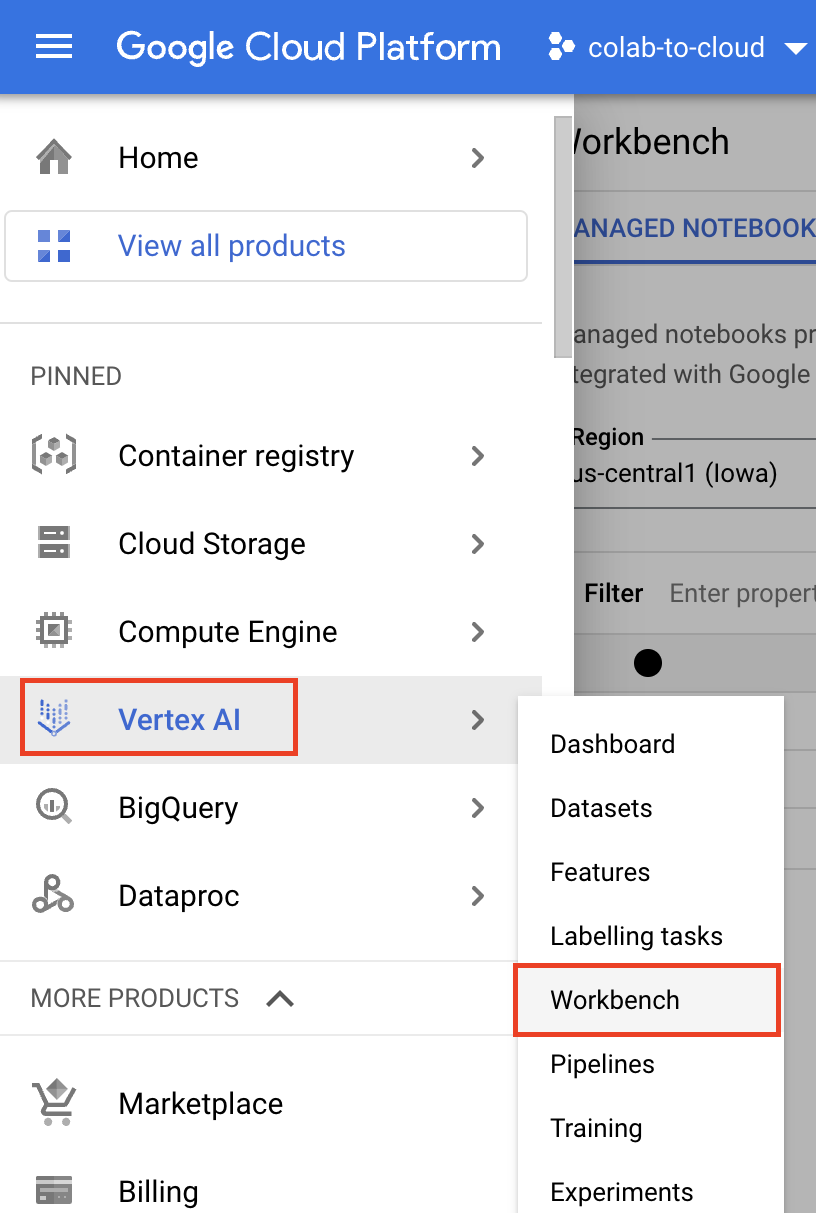
接下来,选择“MANAGED NOTEBOOKS”,然后选择“NEW NOTEBOOK”。
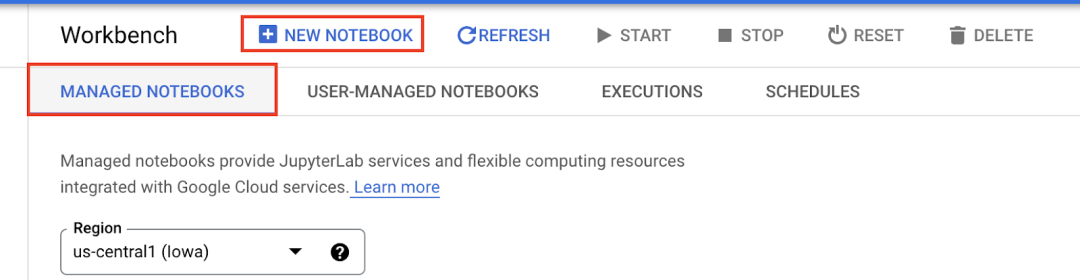
在“Advanced Settings”下,您可以通过指定机器类型和位置、添加 GPU、提供自定义容器以及启用终端访问来自定义 notebook。目前,请保留默认设置,只需为 notebook 命名即可。然后点击“CREATE”。
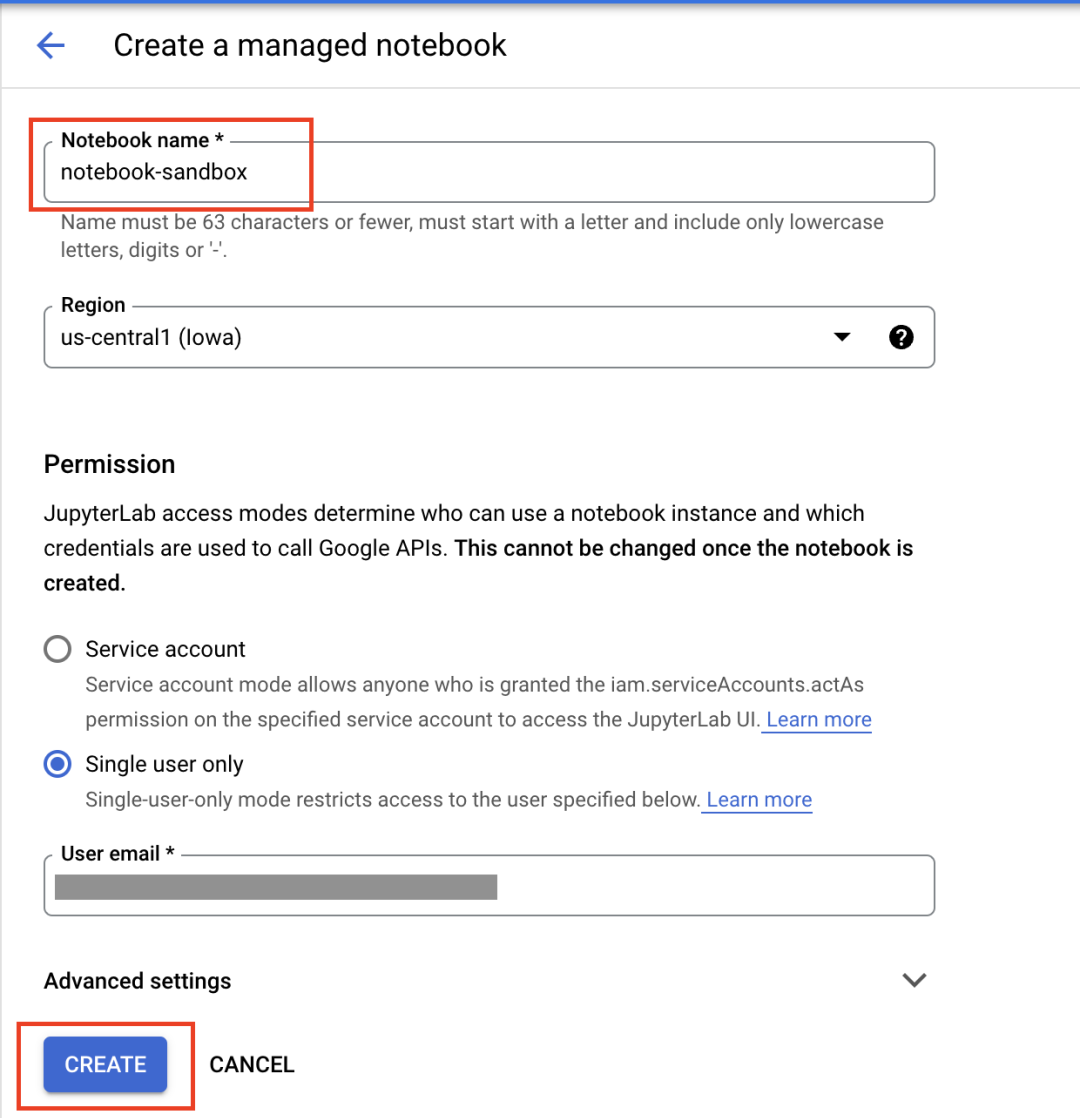
当 OPEN JUPYTERLAB 文本变为蓝色时,表示您的 notebook 已准备就绪。首次打开 notebook 时,系统会提示您进行身份验证,您可以按照界面中的步骤操作。

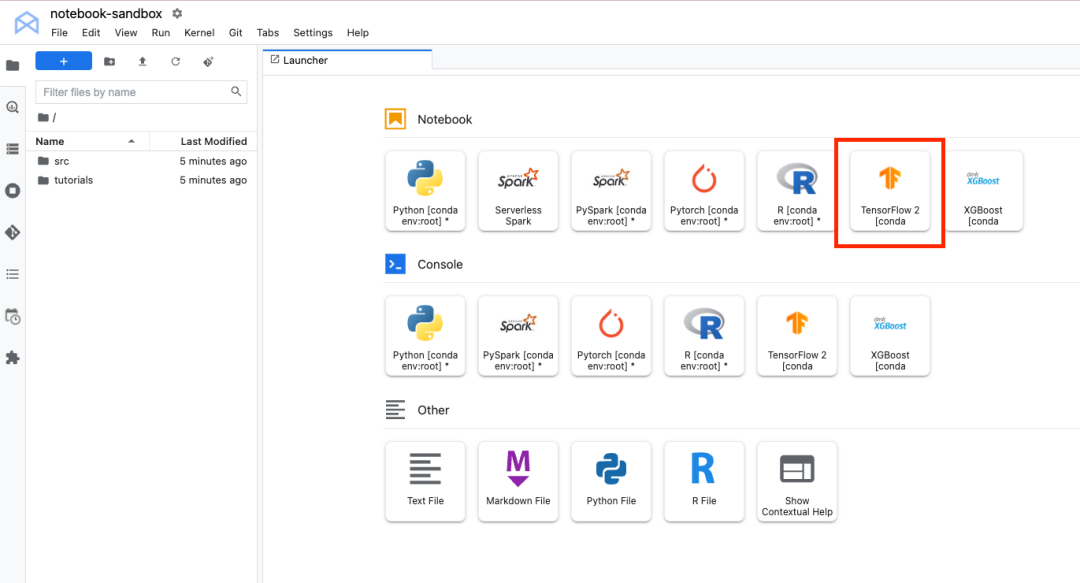
打开 JupyterLab 实例后,您会看到几种不同的 notebook 选项。Vertex AI Workbench 提供了不同的内核(TensorFlow、R、XGBoost 等),这些内核是预安装了通用数据科学库的代管式环境。如果您需要向内核中添加其他库,和在 Colab 中一样,您可以在 notebook 单元中使用 pip install。

第 1 步已完成!您已经创建了代管式 JupyterLab 环境。
上传 .ipynb 文件
现在,将 TensorFlow 代码放入 Google Cloud 中。如果您一直在使用不同的环境(Colab、本地等),则可以将任何需要的代码工件上传到您的 Vertex AI Workbench 代管式 notebook,甚至可以与 GitHub 集成。在未来,您可以直接在 Workbench 中完成所有的开发工作,但现在让我们假设您一直在使用 Colab。
Colab notebooks 可以导出为 .ipynb 文件。
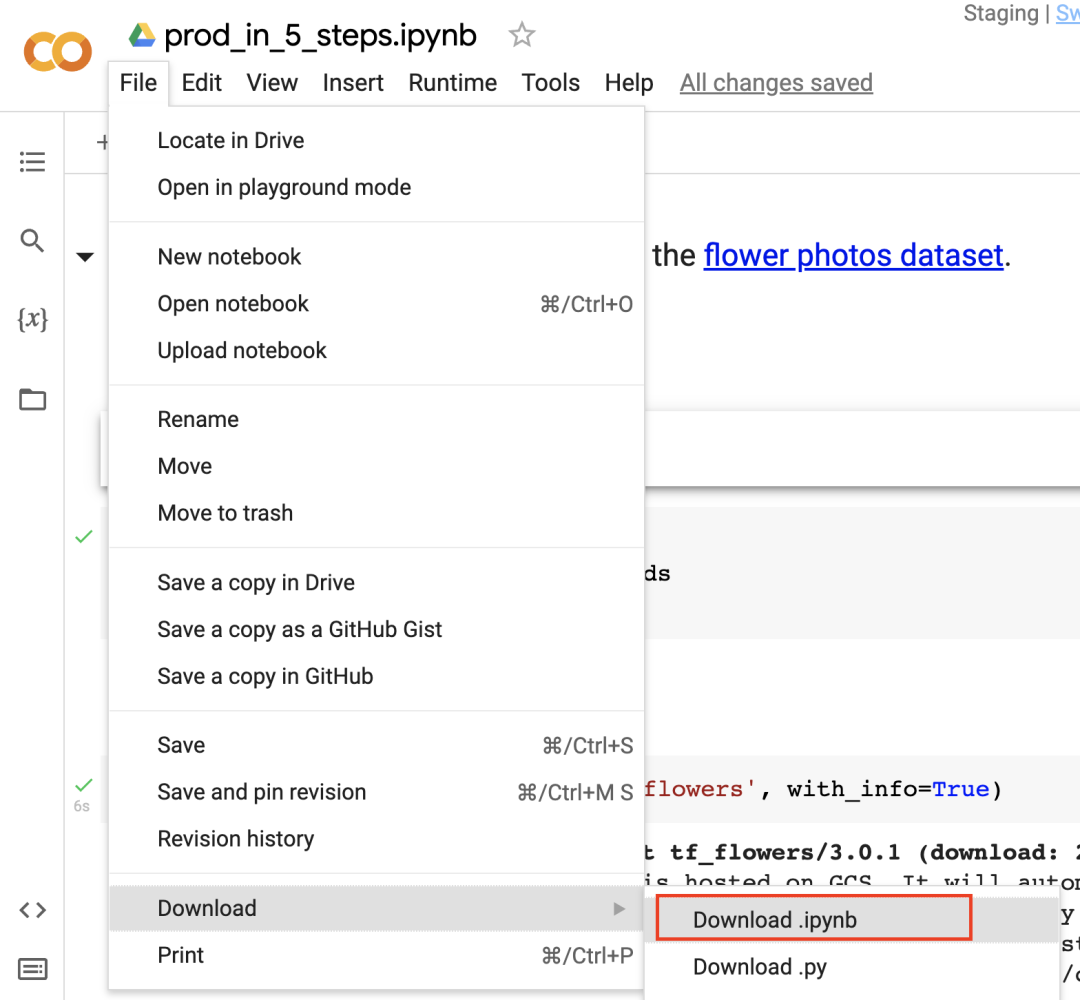
您可以点击“上传文件”图标,将文件上传到 Workbench。
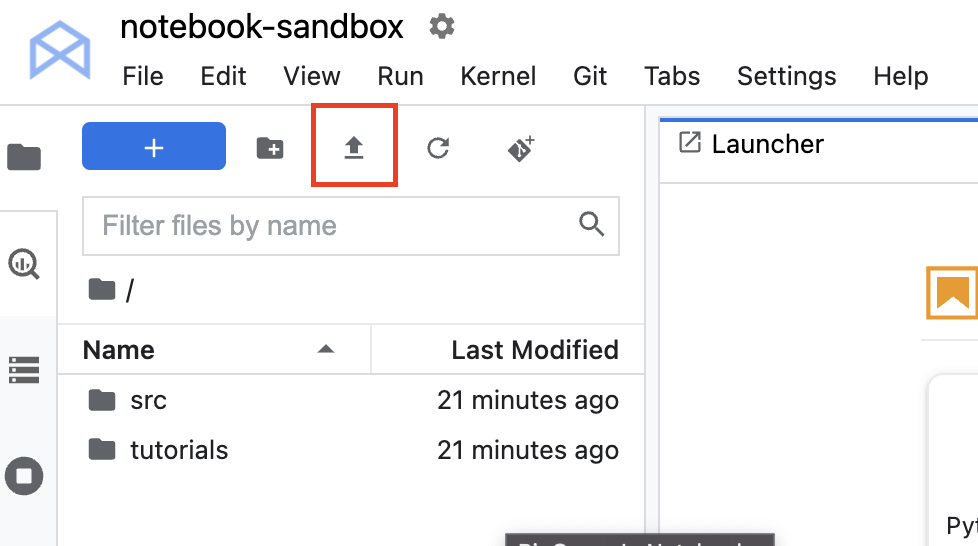
当您在 Workbench 中打开此 notebook 时,系统会提示您选择内核,即 notebook 的运行环境。有几种不同的内核可供选择,但由于此代码示例使用 TensorFlow,因此需要选择 TensorFlow 2 内核。
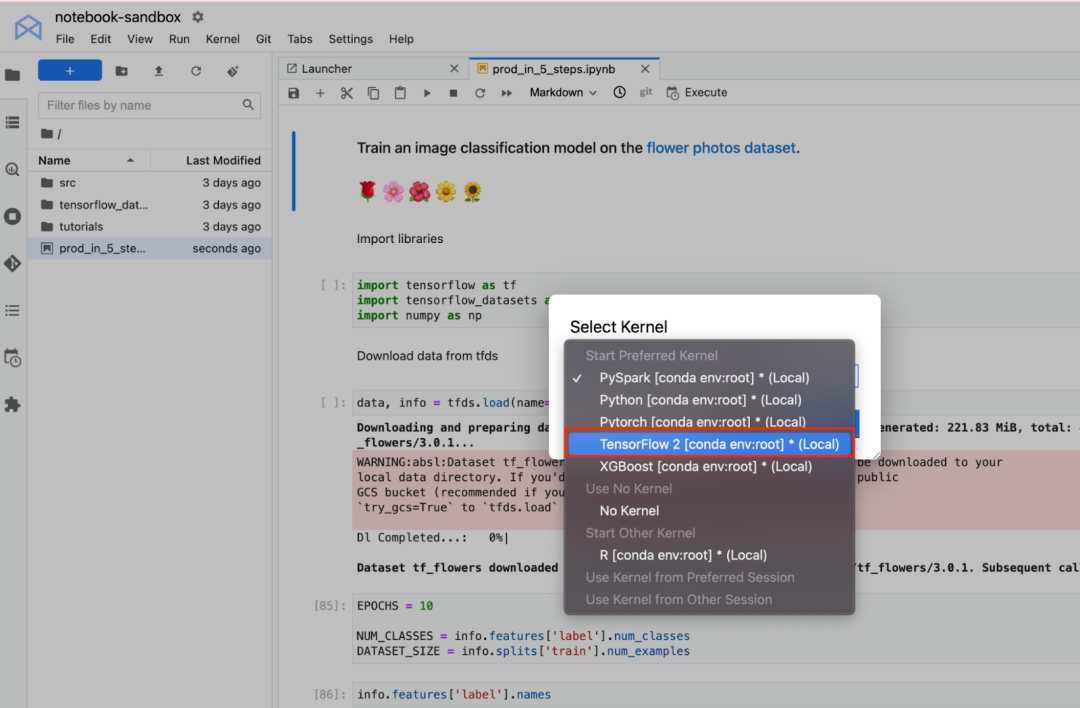
选择内核后,在 notebook 中执行的任何单元都将在此代管式 TensorFlow 环境中运行。例如,如果执行导入单元,则可以导入 TensorFlow、TensorFlow Datasets 和 NumPy。这是因为所有这些库都包含在 Vertex AI Workbench TensorFlow 2 内核中。当然,由于 XGBoost 内核中没有安装 TensorFlow,如果您尝试在该内核中执行相同的 notebook 单元,则会看到一条错误消息。
启动 notebook 执行
虽然我们可以手动运行其余的 notebook 单元,但对于需要长时间训练的模型而言,notebook 并不总是最方便的选择。如果使用 ML 构建应用,通常来说您需要对模型进行多次训练。随着时间的推移,您会想要重新训练模型,以确保其保持实时更新,并不断产生有价值的结果。
如果您要开始处理一个新的机器学习问题,手动执行 notebook 单元可能是不错的选择。但是,如果您想要大规模进行自动化实验,或者为生产应用重新训练模型,代管式 ML 训练选项将大大简化您的工作。
启动训练作业最快的方法是使用 notebook 执行功能,该功能将在 Vertex AI 代管式训练服务上逐个运行 notebook 单元。
notebook 执行功能
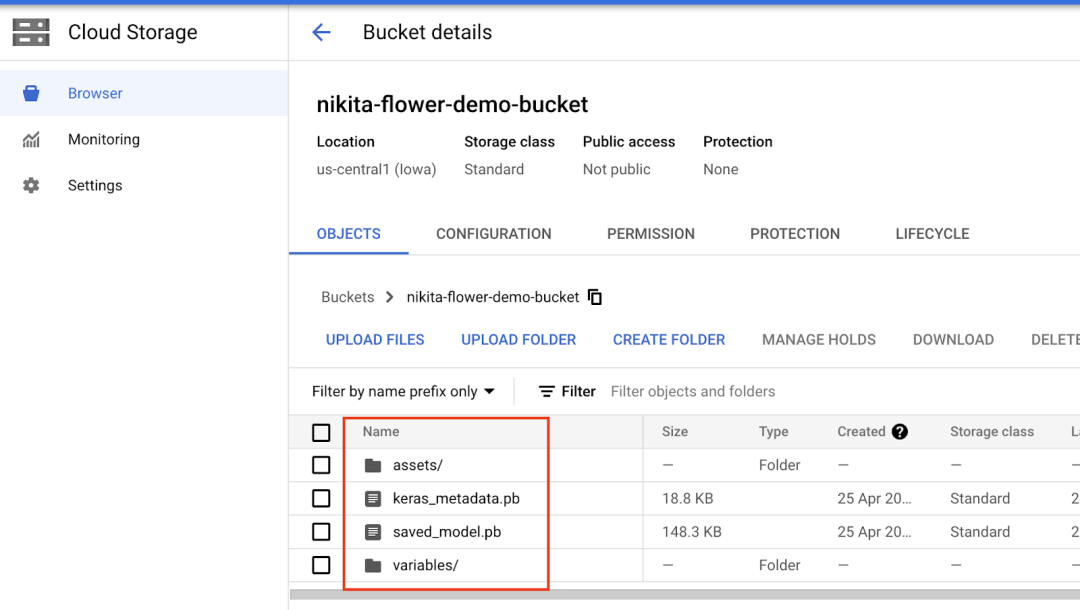
启动训练作业后,它将在作业完成后您无法访问的机器上运行。因此,您不希望将 TensorFlow 模型工件保存到本地路径。您想要将其保存到 Google Cloud 的对象存储空间 Cloud Storage 中,以便您可在其中存储图像、csv 文件、txt 文件和保存的模型工件。几乎包括任何类型的内容。
Cloud Storage 涉及“存储分区”的概念,它用于存放数据。您可以通过界面创建存储分区。Cloud Storage 中存储的所有内容都必须包含在存储分区中。在存储分区中,您可以创建文件夹来组织数据。
通过界面创建存储分区
Cloud Storage 中的每个文件都有一个路径,就像本地文件系统上的文件一样,只是 Cloud Storage 路径始终以 gs:// 开头
您需要更新训练代码,以便将内容保存到 Cloud Storage 存储分区而非本地路径中。
例如,在这里,我从 model.save('model_ouput"). 更新了 notebook 的最后一个单元,将工件保存到我在项目中创建的名为 nikita-flower-demo-bucket 的存储分区中,而不是保存到本地。

现在,我们可以启动执行了。
选择“Execute”按钮,为您的执行命名,然后添加 GPU。在“环境”下方,选择 TensorFlow 2.7 GPU 映像。该容器预安装了 TensorFlow 和许多其他数据科学库。
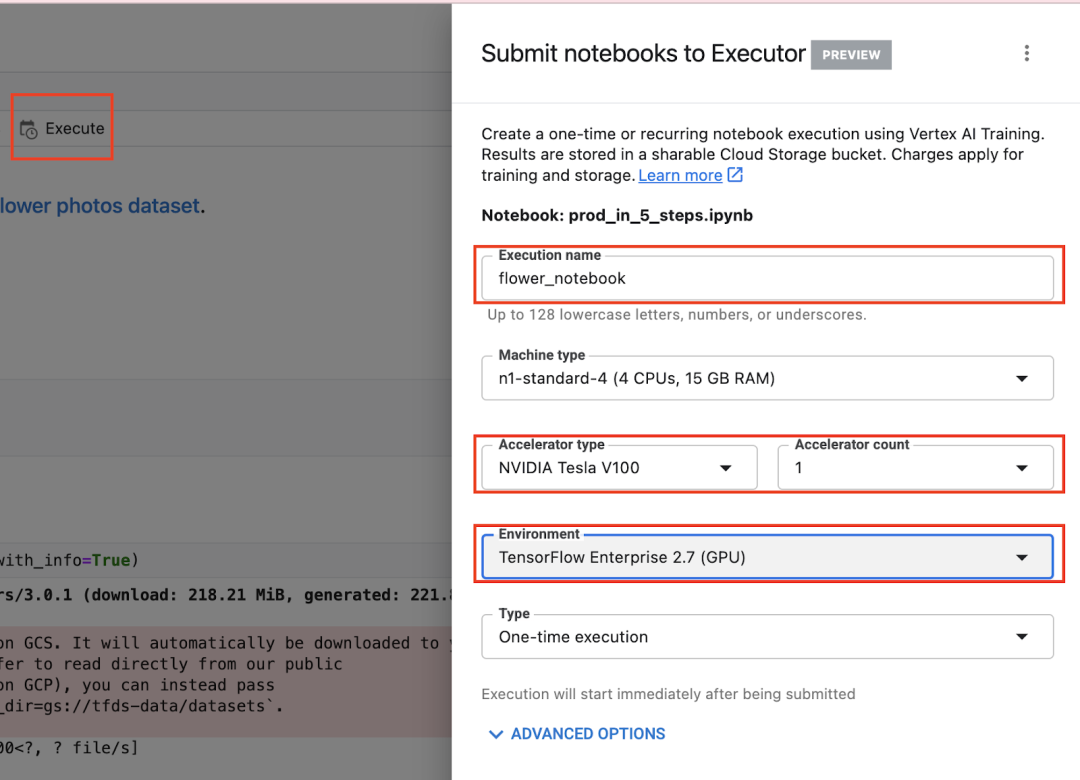
然后,点击“SUBMIT”。
您可以在“EXECUTIONS”标签页中跟踪训练作业的状态。作业完成后,您可以在“VIEW RESULT”下查看 notebook 和每个单元的输出,它们存储在 GCS 存储分区中。这意味着,您始终可以将模型运行与执行的代码关联在一起。
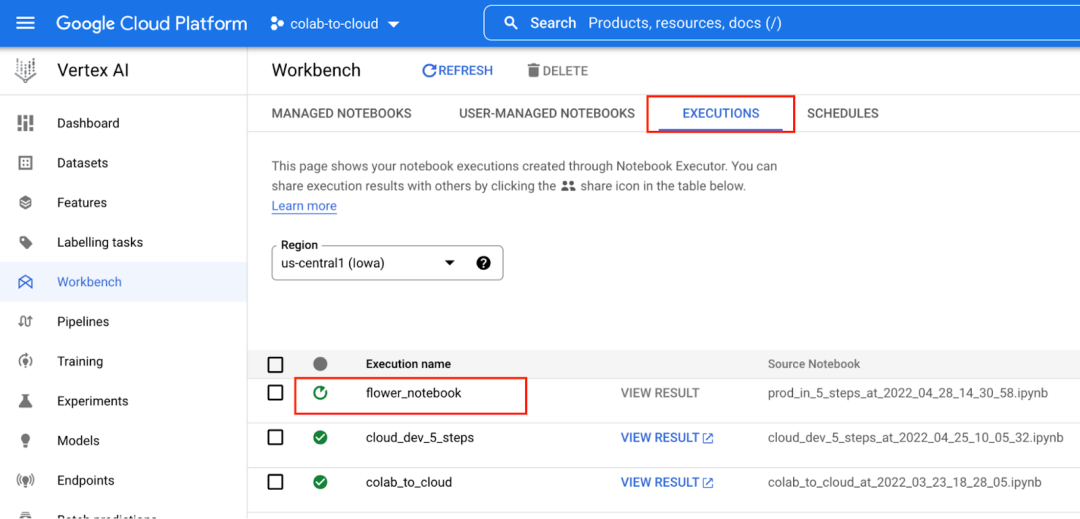
训练完成后,您将能够在存储分区中看到 TensorFlow 保存的模型工件。
部署到端点
现在,您已经了解到如何在 Google Cloud 上快速启动无服务器训练作业。但 ML 不仅仅只是用于训练。如果我们不使用模型来实际完成一些任务,那么所有这些工作有什么意义呢?
就像训练一样,我们可以通过调用 model.predict 直接从 notebook 执行预测。但是,如果我们想要获取对大量数据的预测,或在运行中获取低延迟预测,则需要比 notebook 更强大的工具。
让我们回到 Vertex AI Workbench 代管式 notebook。您可以将下面的代码粘贴到一个单元中,该单元会使用 Vertex AI Python SDK 将您刚刚训练的模型部署到 Vertex AI Prediction 服务。将模型部署到端点会将保存的模型工件与物理资源相关联,从而确保低延迟预测。
首先,导入 Vertex AI Python SDK。
Vertex AI Python SDK
然后,将您的模型上传到 Vertex AI Model Registry。您需要为模型命名,并提供一个用于传送的容器映像,这是将用于运行您的预测的环境。Vertex AI 提供了用于传送的预构建容器,在本例中,我们使用的是 TensorFlow 2.8 映像。
Vertex AI Model Registry
预构建容器
您还需要将 artifact_uri 替换为存储保存的模型工件的存储分区路径。对我来说,该路径是“nikita-flower-demo-bucket”。您还需要将 project 替换为您的项目 ID。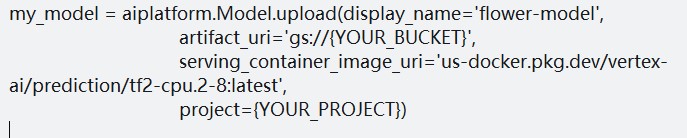
然后,将模型部署到端点。我目前使用的是默认值,但如果您想详细了解流量分配和自动扩缩,请务必查看相关文档。请注意,如果您的用例不需要低延迟预测,则无需将模型部署到端点,而是可以使用批量预测功能。
流量分配
自动扩缩
批量预测功能

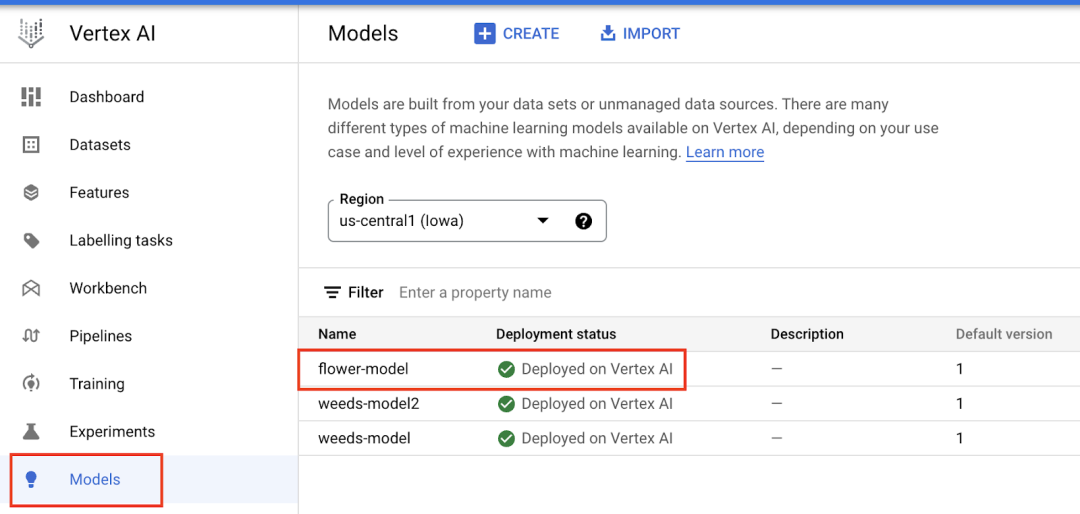
部署完成后,您可以在控制台中看到您的模型和端点。
获取预测
现在,该模型已部署到端点,您可以像使用任何其他 REST 端点一样使用它。也就是说,您可以将模型集成到下游应用中并获取预测。
现在,我们直接在 Workbench 中测试该模型。
首先,打开一个新的 TensorFlow notebook。
在此 notebook 中,导入 Vertex AI Python SDK。

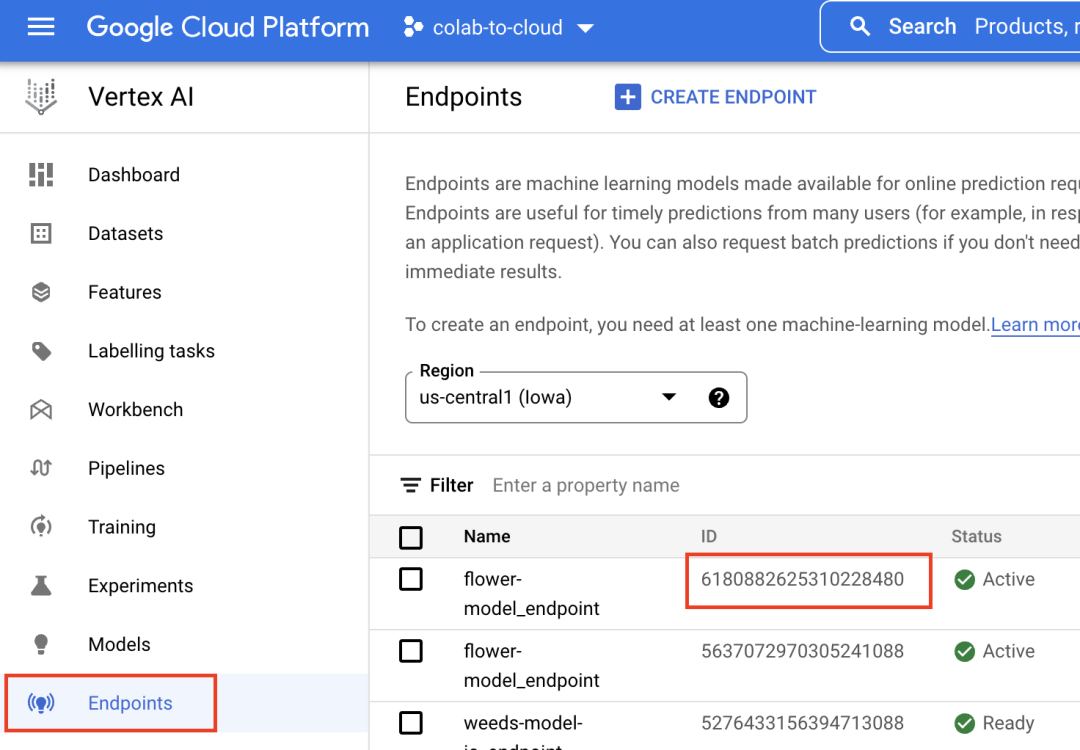
然后,创建端点,替换 project_number 和 endpoit_id。

您可以在 Cloud Console 的“Endpoints”部分找到端点 ID。
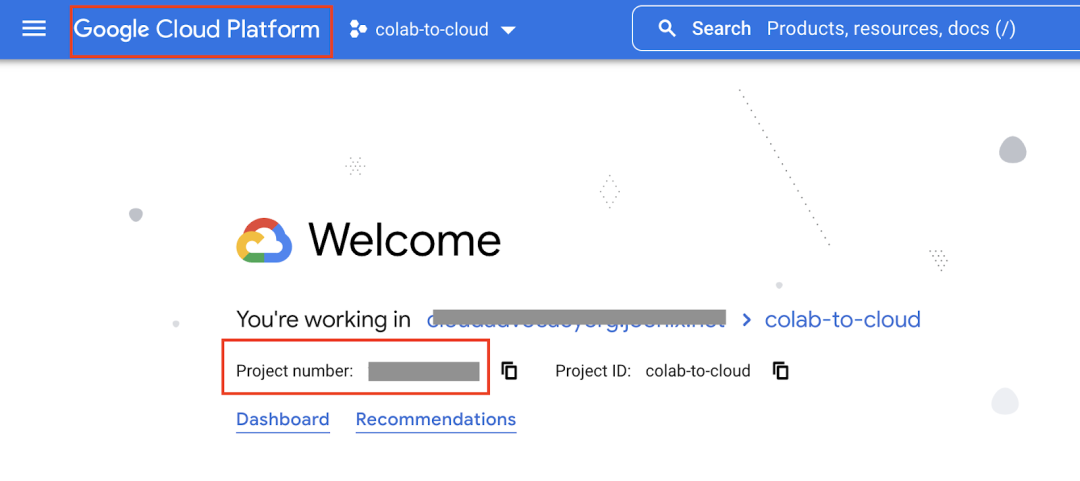
您可以在控制台首页找到项目编号。注意,该编号与项目 ID 不同。
当您向在线预测服务器发送请求时,HTTP 服务器会接收该请求。HTTP 服务器会从 HTTP 请求内容正文中提取预测请求。提取的预测请求会被转发到传送函数。在线预测的基本格式是数据实例列表。此类列表可以是普通的值列表,也可以是 JSON 对象成员,具体取决于您如何在训练应用中配置输入。
为了测试端点,我首先将一张花卉图像上传到 Workbench 实例。
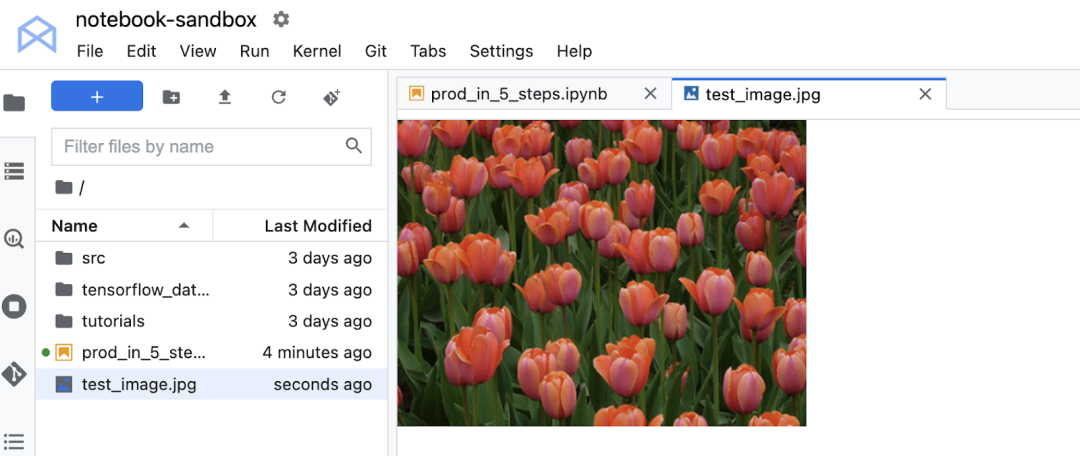
下面的代码使用 PIL 打开图像并调整其大小,然后将其转换为 NumPy 数组。

接下来,我们将 NumPy 数据转换为 float32 类型和列表。我们将其转换为列表,是由于 NumPy 数据不支持 JSON 序列化,因此我们不能在请求的正文中发送这些数据。请注意,不需要将数据扩缩 255,因为该步骤已通过 tf.keras.layers.Rescaling(1./255). 包含在我们的模型架构中。为了避免调整图像的大小,可以将 tf.keras.layers.Resizing 添加到模型中,而不是将其作为 tf.data 流水线的一部分。

然后,调用 predict

所得到的结果是模型的输出,这是一个包含 5 个单元的 softmax 层。看起来索引 2 的类(郁金香)得分最高。

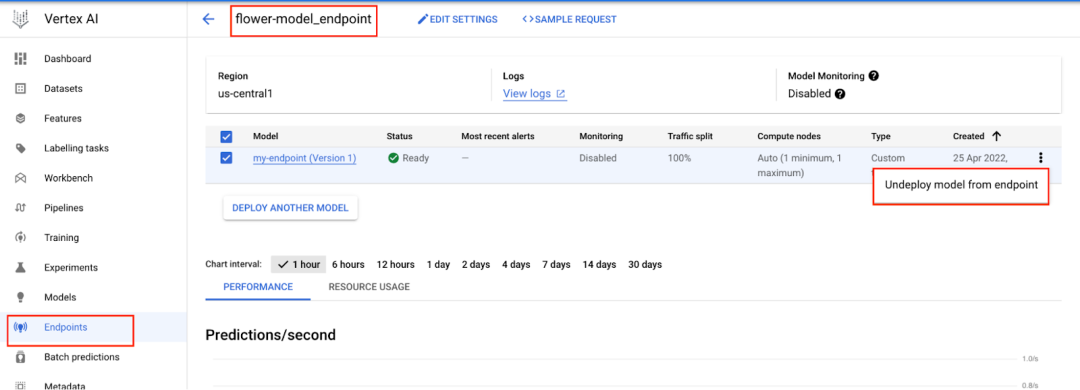
提示:为了节省成本,如果您不打算使用端点,请务必取消部署端点!要取消部署,转到控制台的“Endpoints”部分,选择端点,然后选择“Undeploy model form endpoint”选项。如果需要,您可以随时在未来重新部署。
在更加实际的例子中,您可能希望直接将图像发送到端点,而不是先将其加载到 NumPy 中。如果您想查看相关示例,可以参阅此 notebook 。
开始您的探索吧!
现在您已了解到如何从 notebook 实验过渡到云中部署。有了这一框架,您可以开始思考如何使用 notebooks 和 Vertex AI 构建新的 ML 应用啦。
审核编辑:刘清
-
ICC AVR 过渡到 AVR STUDIO2011-07-27 3121
-
标题51单片机过渡到ARM2013-05-12 1567
-
告诉你如何从51单片机快速过渡到AVR单片机2013-10-06 3963
-
8510网络分析仪过渡到PNA工程服务2019-08-05 1189
-
将系统软件从GPIB过渡到LAN/LXI2019-10-16 2363
-
把指针操作过渡到寄存器的使用2021-08-24 879
-
如何从学习51单片机过渡到STM32单片机2021-09-18 1432
-
在嵌入式环境中部署环境的相关资料分享2021-10-27 826
-
如何从51单片机过渡到STM32呢2021-12-20 12218
-
安捷伦LTE测试解决方案助用户从3G过渡到4G2009-12-29 863
-
从ADXL202过渡到ADXL213或ADXL2032011-11-28 1471
-
研究显示企业完整上云普及率仅13%,42%在云中部署应用程序和项目2020-10-15 1813
-
AN-0989: 从ADXL202过渡到ADXL213或ADXL2032021-03-21 883
-
从裸机调度过渡到RTOS的7个小技巧2022-11-29 1856
-
EE-130:从ADSP-21xx快速过渡到ADSP-219x2025-01-14 460
全部0条评论

快来发表一下你的评论吧 !
