

分享一个使用BPF事件捕获rootkit的案例
描述
如今,云原生平台越来越多的使用了基于eBPF的安全探测技术。这项技术通过创建安全的Hook钩子探针来监测内部函数和获取重要数据,从而支持对应用程序的运行时做监测和分析。Tracee是用于Linux的运行时安全和取证的开源项目,它基于eBPF实现,所以在安全监测方面效果更加优化。
在本文中,我们将探索控制eBPF事件的方法,并研究一个使用BPF事件捕获rootkit的案例。Rootkit是一种存在于内核中复杂类型的恶意漏洞攻击,并将介绍Tracee用于检测Syscall 钩子的新特性,它实现了在内核中使用eBPF事件的独特方式。
eBPF: 不只是用来跟踪
eBPF是一种Linux内核技术,它允许在不更改内核源代码或添加新模块的前提下,在Linux内核中运行沙盒程序。因此,eBPF可以支持安全的Hook到事件上,而不会造成内核崩溃的风险。
具体来说,eBPF程序使用内核机制(如kprobes、kretprobes、Linux安全模块(LSM) Hooks、uprobes和traceponits)来创建和设置钩子,并加以验证代码不会使内核崩溃。eBPF有一个Verifier验证器,其目标是确保eBPF程序安全运行(而不是通过加载内核模块来与内核交互,如果操作不当,会导致系统崩溃)。
攻击者为何喜欢Hook内核函数?
目前使用rootkit的复杂攻击往往是针对内核空间,这是因为攻击者试图避免被安全防御方案,以及监控用户空间事件或分析基本系统日志的取证工具检所测到。此外,在内核空间中嵌入恶意软件也会使得安全研究员和响应团队更难找到它。恶意软件越接近于底层,检测起来就越困难。
下面,我们将看看TNT团队的例子,并查看他们是如何利用Diamorphine 这个rootkit,以及Tracee如何检测到它。
内核中的函数操作
攻击者为了自身利益最大化,会寻找内核级别的目标函数。常用的一种方法是函数钩子,旨在通过操纵内核中的函数来隐藏恶意活动。这样做的原因是内核函数执行的是来自用户空间的任务。如果它们被破坏,攻击者即可控制所有用户空间程序的行为。
当攻击者试图Hook系统调用(syscall)函数时,这就是函数钩子的一个很好示例。这些高级内核函数用于执行来自用户空间的任务,Hook住它们主要目的是隐藏恶意行为。例如,攻击者将getdents系统调用Hook起来,以隐藏用于列出文件命令(如ps、top和ls)的恶意文件和进程。
通常,通过读取系统调用表并获取系统调用函数的地址来Hook他们。一旦获得系统调用函数地址,攻击者将保存原始地址,并试图用包含恶意代码的新函数覆盖它。
攻击者如何Hook内核函数?
现在,让我们研究一下攻击者如何在真实环境下的网络攻击中劫持内核函数。
为了Hook内核函数,必须首先获得想要钩住的对象访问权。例如,它可以是保存所有系统调用函数地址的系统调用表。然后,保存函数的原始地址并覆盖它。在某些情况下,由于当前位置的内存权限,还需要获取CPU中控制寄存器的权限。
接下来是TNT团队使用Diamorphine隐藏加密的活动,这作为他们攻击的一部分可以很好的解释这样的方法:
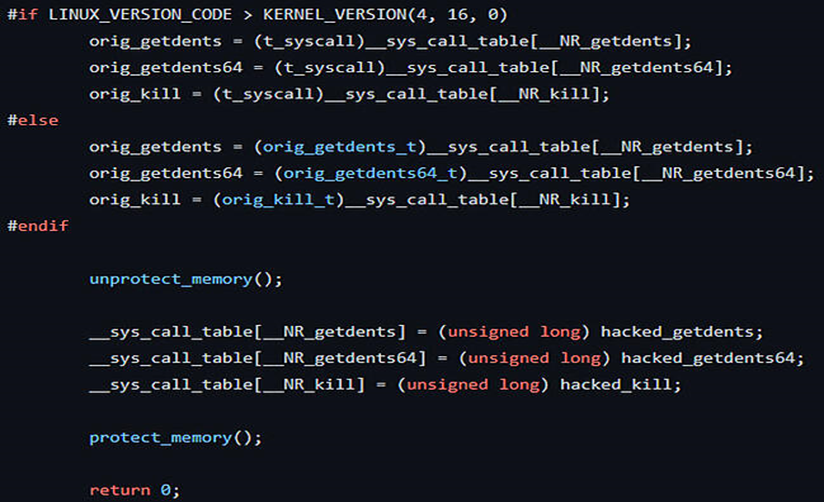
使用内存边界技术检测Syscall钩子
现在我们已经确定了攻击者的动机以及他们如何修改内核行为,问题是,我们该如何检测这种活动? 明确的目标是找到一种方法,以区分内核中的原始内部函数(或与核心内核关联的syscall)和新的内核模块代码(或换句话说,被攻击后的函数)。
我们可以通过内核的core_text边界检测来实现这一点。内核中的内存被分为几个部分。其中一个是core_text段,它保存内核中的原始函数。此部分注册在特定的内存映射区域中,该区域不受更改或操作的影响。此外,如果我们加载一个新的内核模块--也就是说,编写一个新函数或覆盖原始函数——这个新函数将写入另一个专门为新函数保留的内存区域。可以在下面的虚拟内存映射中看到这一点。注意,分配给原始内核代码的地址范围(文本部分,又名“核心内核文本”)和分配给新内核模块的地址范围是不同的。
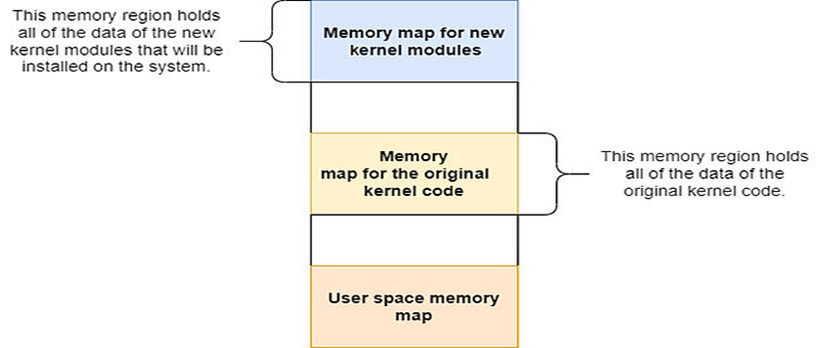
因此,当前的目标是获取一个系统调用地址,然后将其与内核core_text边界进行比较,正如我们所看到的,core_text边界表示原始内核源的范围。
使用Tracee检测Syscall钩子
现在,我们已经了解了恶意软件如何以及为什么以内核函数为目标,以及如何检测被钩住的内核函数,接下需要知道如何使用eBPF来提取函数的地址。使用Tracee可以确定函数是否被钩住,即使钩子是在Tracee执行之前放置的。
首先创建一个在用户空间中触发的BPF程序,并在内核空间中捕获相应BPF事件。如果内核程序需要来自用户空间的信息,可以通过BPF映射来进行传递。
例如在Tracee中创建一个事件,该事件将从系统调用表中获取系统调用地址,接下来确认系统调用是否被内核模块钩住了。如果它被钩住了,继续将创建一个派生事件(由内核另一个事件而创建的事件),它将提示系统调用钩住的情况,如下:
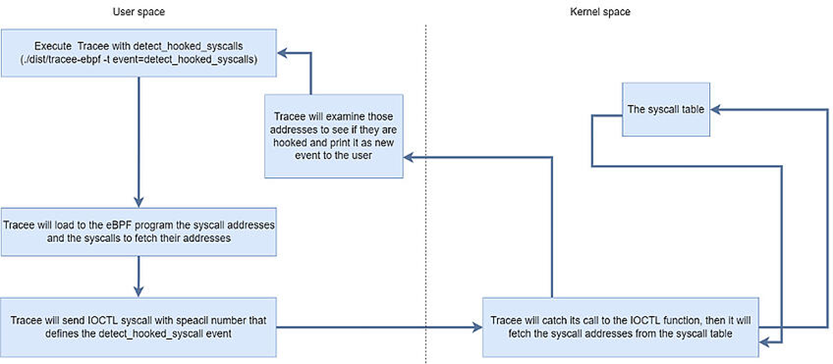
先使用libbpfgo的helper来获取系统调用表地址,并将其添加到事件内核符号依赖项中。
注意,detect_hooked_sycalls事件是派生事件。这意味着在我们接收到系统调用的地址并检查它们之后,我们将创建一个新的detect_hooked_sycalls事件。
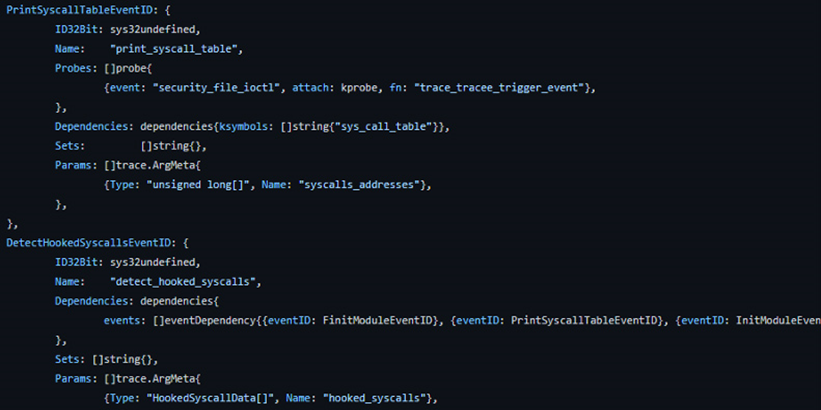
然后,我们将它与系统调用号一起传递,以便使用BPFMap检查内核空间。
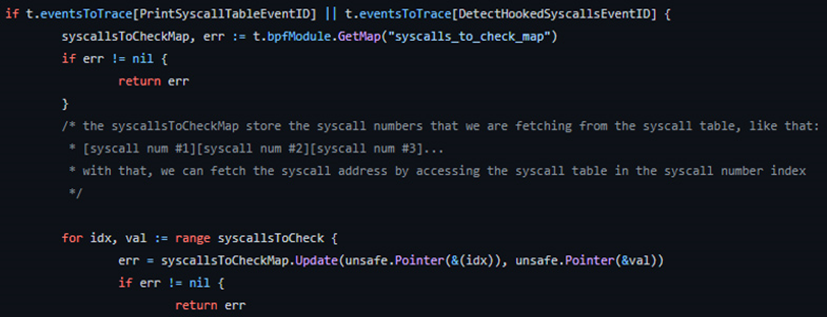
为了检查内核空间中的那些系统调用,基于security_file_ioctl上的kprobe创建一个事件,它是ioctl系统调用的一个内部函数。这样我们就可以通过使用用户空间的特定参数触发系统调用来控制程序流,接下来用一个特定的命令触发ioctl:
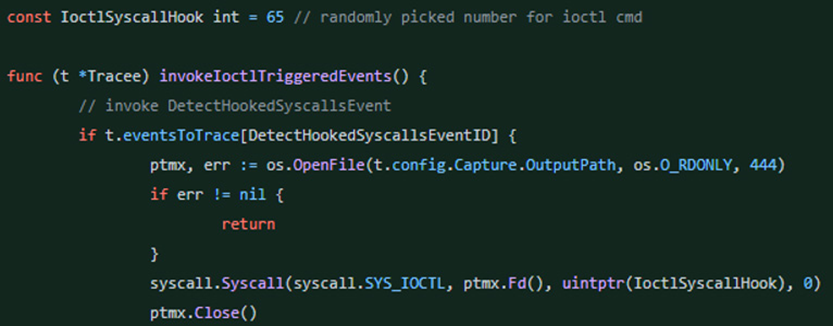
此时,在内核空间中开始检查ioctl命令是否相同,以及调用该系统调用的进程是否为Tracee。这样就可以验证只有当用户要求Tracee检查时才会发生检测的需求。
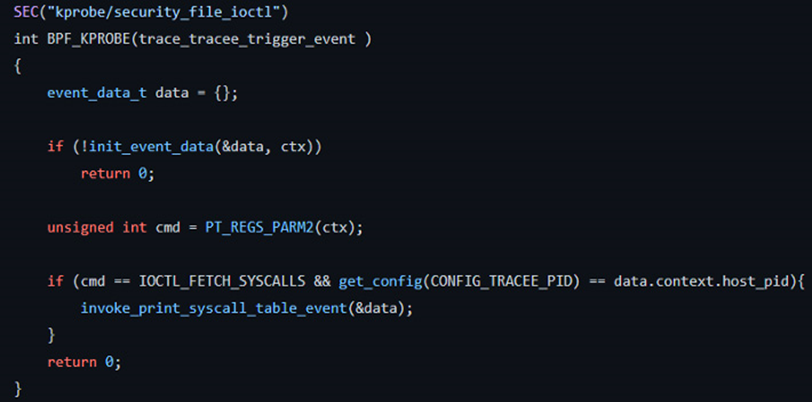
检测代码很简单,遍历系统调用映射,通过使用READ_KERN()来获取系统调用表的地址如下:
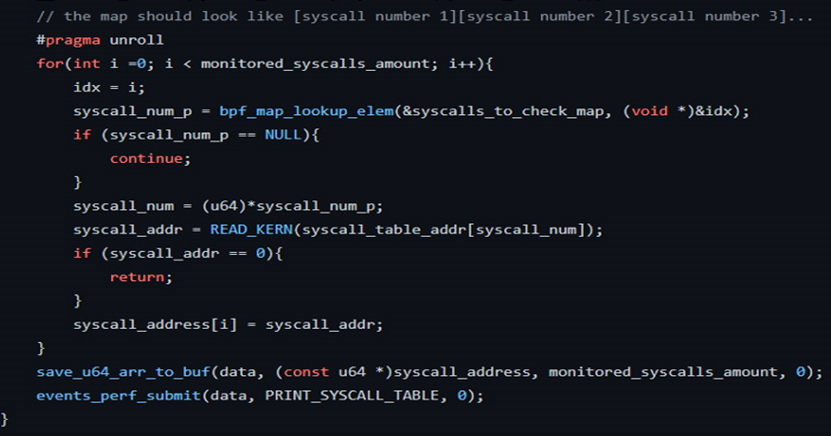
然后在用户空间中,我们将这些地址与libbpfgo helpers进行比较:
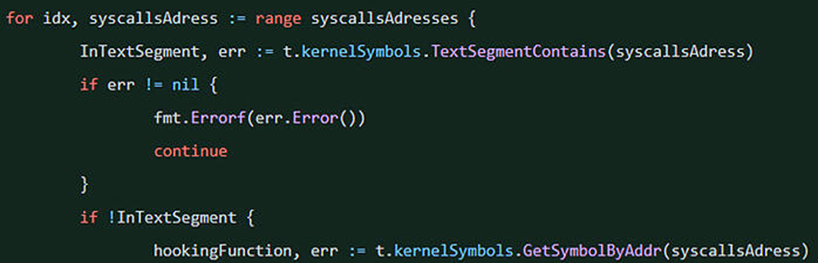
狩猎时间: 用eBPF检测Diamorphine rootkit
现在,开始运行Tracee,来看看它将如何检测出Diamorphine rootkit。
使用insmod函数加载Diamorphine (.ko)的内核对象文件。目标是看看Tracee的探测结果。通常,在加载一个内核模块的情况下启动Tracee,如果选择了detect_hooked_sycall事件,Tracee将发送一个hooked_sycalls事件,以确保系统没有被破坏:

Tracee检测到getdents和getdents64这些挂起的系统调用。TNT团队使用它们来隐藏大量加密活动导致的CPU负载过高,以及通常用于从用户空间发送命令来杀死进程的kill函数。在这种情况下,rootkit使用kill -63作为用户空间和内核空间之间的通信通道。同样,如果再次运行Diamorphine和Tracee使用json输出,参数将显示Diamorphine的恶意钩子:
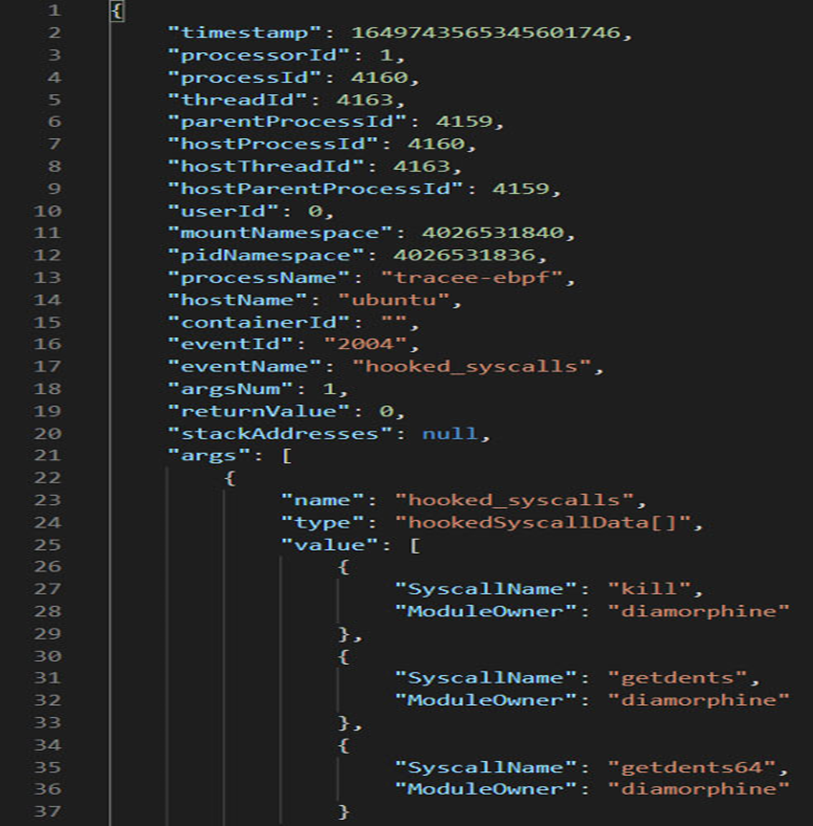
如果运行Tracee-rules,我们可以看到detect_hooked_sycall事件的新签名:

结论
现代攻击者的目标是包括内核层的操作系统各个层级,此外,由于开源项目(如Diamorphine)的流行,攻击性网络工具变得越来越容易获得。因此,安全研究员需要提高自身的防御能力知识,开发出合适的检测方法。
审核编辑:刘清
-
BPF-A580+带通滤波器产品介绍2019-09-24 919
-
一篇文章搞懂BPF的内部逻辑2022-07-07 5838
-
Kylin系统的内核级Rootkit防护2009-04-10 818
-
Rootkit是什么2018-11-07 8903
-
保证BPF程序安全的BPF验证器介绍2021-05-03 2860
-
如何使用BPF对Linux内核进行实时跟踪2021-06-30 3287
-
BPF系统调用与Tracing类型的BPF程序2022-03-14 5103
-
BPF ring buffer解决的问题及背后的设计2022-05-17 3658
-
BPF编程的环境搭建方法2022-10-14 3185
-
BPF为内核编程提供了一个新的参考模型2022-10-19 2070
-
防御Rootkit攻击并避免恶意恶意软件2023-04-24 2976
-
Linux内核革命性技术之BPF的前世今生2023-07-26 2836
-
如何利用ebpf检测rootkit项目取证呢?2023-08-01 1434
-
内核观测技术BPF详解2023-11-10 3778
-
一个通道如何捕获PWM的频率和占空比?2023-12-30 5628
全部0条评论

快来发表一下你的评论吧 !
