

近存处理器存内处理芯片设计方案
处理器/DSP
描述
首先,我们来了解一下什么是近存处理器。下图展示了几种主要的近存和存内处理芯片设计方案的基本概念。
- Traditional:传统的处理器系统,运算和存储是2个不同的die,通过片外走线连接。
- 2D CIM:存储和运算在同一个die中,混合分布。
- 2D PNM:存储和运算在同一个die中,分成两个独立的部分。
- 2.5D PNM:存储和运算在2个不同的die上,通过interposer连接。
- 3D HB-PNM:存储和运算2个die脸对脸通过铜-铜互连(本论文的方案)。
- 3D TSV-PNM:存储和运算stack的方式通过TSV连接。
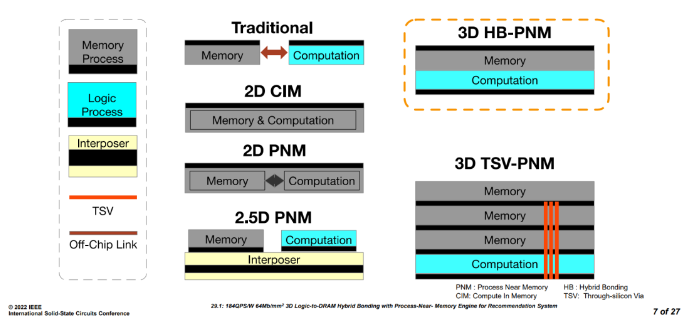
Figure1 近存存内处理器结构介绍[1]
推荐系统工作流程
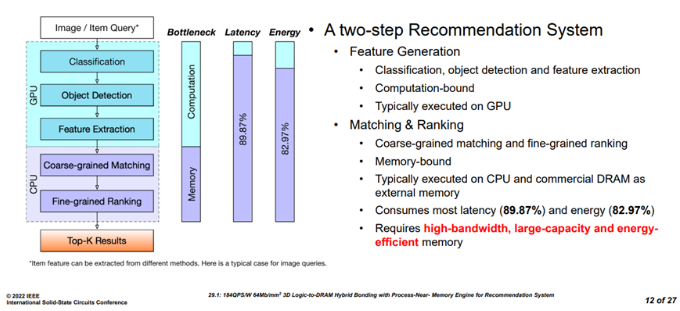
Figure2 推荐系统任务流程[1]
推荐系统的工作流程主要包含特征生成和召回排序两个阶段。其中,特征生成主要在GPU上运行,具体的任务包括分类,目标检测,特征提取,通常是运算密集型任务。而召回排序包括粗粒度召回和细粒度排序两个阶段,占据了整个推荐任务89.7%的延迟和82.97%的能量消耗,因此,该阶段需要大容量,高带宽,低能耗的存储系统。
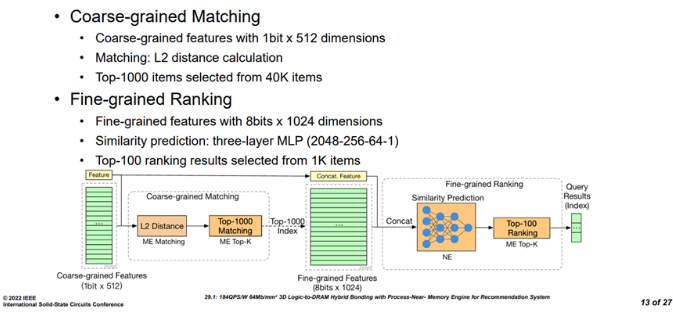
Figure3 召回和精排任务流程[1] 在该芯片设计面对的推荐任务中,粗粒度召回包含L2 distance和Top-k两个阶段,输入为1个1bitx512维度的特征,首先进入ME(matching engine)单元进行L2距离计算,然后从40k的项目中选出排名靠前的1000个子项,得到一个8bits x 1024的特征,这些特征和之前的特征连接合并,进入细力度排序阶段。细力度排序包括相似度预测和top-k两个阶段,相似度预测由一个三层的MLP进行操作(2048-256-64-1),主要利用NE(neural engine)进行,最后MLP的输出会再次返回ME进行top-k操作, 从之前的1000个子项中选择100个子项,然后返回查询结果。
近存处理器架构
整体架构
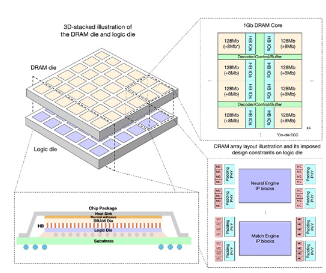
Figure4 3D stack芯片整体结构[1] 整体逻辑die wafer和DRAM die wafer通过脸对脸对贴,铜-铜互连,逻辑和DRAM die 有同样的大小,都是25.24 x 23.86 mm2,DRAM 由6x6个同等大小的block组成,每个block是4x4 mm2,有1Gb的容量大小。这1Gbit的DRAM 有8个bank,支持ECC, 每个bank有128 bits的IO。每个逻辑block都可以访问自己对应的DRAM block,此外,也可以通过片上总线访问其它的DRAM block。每4个DRAM block的大小是64mm2,DRAM die工作在150Mhz,1.1V, 功耗为300mW/1Gb,36个DRAM总的带宽为1.38TB/s。
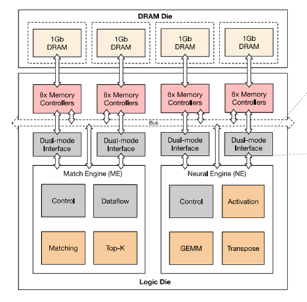
Figure5 近存处理器的整体架构[1]
每4个DRAM block对应一套处理引擎,即ME(
match
engine)和NE(neural engine)。其中match engine中主要有top-k和matching 2个DSA处理模块,而neuralengine中由activation函数处理,GEMM运算和transpose操作等引擎构成。NE的大小为5.9mm,ME的大小为7.02mm,逻辑die工作在300Mhz 1.2V,功耗为977mW。ME和NE分别连接了2个dual-mode interface,每个dual-mode interface和8个memory controller连接。这8个MC可以同时给ME提供数据或者只有其中一个MC给ME提供数据。
Matching engine
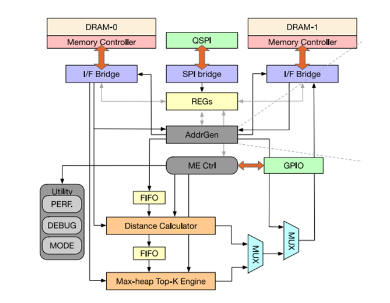
Figure6 matching engine微架构[1]
如前面介绍所说,matching 引擎负责召回阶段的top-k和L2 距离计算以及精排阶段的top-k,因此,该模块最主要的功能模块就是distance calculator和max-heap top-k engine。
地址生成器
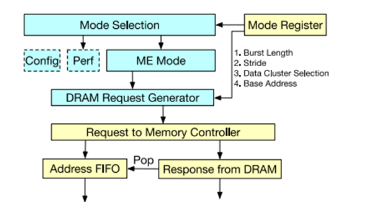
Figure7 地址生成逻辑[1]
地址生成器的主要功能是生成DRAM的访存请求,其地址生成可以通过寄存器配置,包括不同的brust length和stride,数据cluster、基地址等。
距离计算逻辑
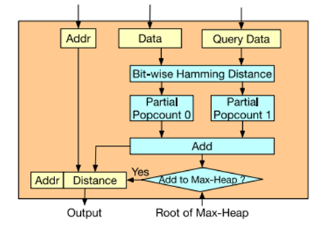
Figure8 距离计算[1] Bit-wise的汉明距离计算比较简单,为查询值和DRAM中的数据值进行按bit异或操作,异或后得到的值里面1的个数即汉明距离。
Top-K引擎
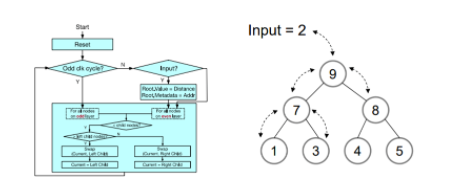
Figure9 max-heap硬件模块[1]
Top-k引擎又称排序引擎,基本逻辑结构为一个2叉树的max-heap硬件模块,其中由1000个节点组成,对应召回阶段最短的1000距离值。堆栈模块每2个周期从顶部即root节点输入一个汉明距离数据。当奇数cycle时,对奇数层的节点进行操作,偶数cycle时,对偶数层的节点进行操作。每个node由node 索引和距离值构成,通过不断的比较和交换当前节点和子节点的值,得到最终的top-1000的结果。同时,由于Top-K引擎只有处理速度的一半,在输入端有一个比较逻辑用于初步过滤数据,因为栈顶总是当前大顶堆中最大的数据,当最新的计算距离小于当前堆顶的值才能替换当前root节点进入堆区域。Max-heap堆排序top-k算法规则如下:
- 当reset时,所有node的distance都设置成max值。
-
当父节点大于所有子节点的值时,不操作,否则进行下面的操作:
- 当前节点小于左子节点,则交换当前节点和左子节点的值。
- 当前节点大于左子节点,则交换当前节点和右子节点的值。
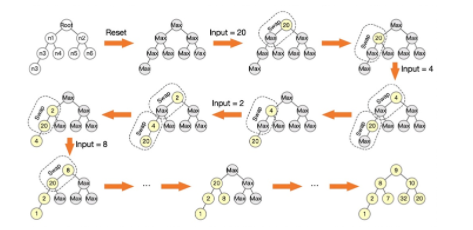
Figure10 max-heap算法举例说明[1]
不难看出,该算法排序按经过若干次迭代操作后,最终拿到了我们想要的从树底层左边最小开始的top-1000树形排列结果。
Neural engine
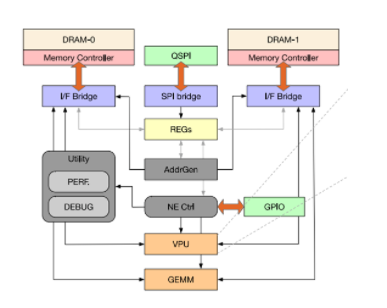
Figure11 Neural引擎[1]
Neural engine更像是一个传统NN processor的方案,包含了VPU(vector process unit)和GEMM(general engine for matrix and multiply)。其中vector引擎包含了一个基于LUT的激活函数处理模块,支持硬件GeLU和Exponential函数运算,另外vector还有一个转置模块,使用2D register file实现,使用乒乓的方式进行16x16的矩阵转置,支持行写入列写出。
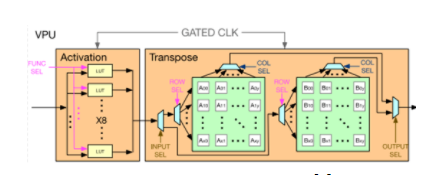
Figure12 vector process unit[1]
GEMM模块在传统NN处理器中用于计算矩阵乘法,这里主要用于MLP的运算流程。运算部分包含了32x32 int8的systolic array和int32的部分积累加器,分别有两个输入和一个输出FIFO用于数据流水,使用weight station的策略,通过顶层的GEMM controller控制。运行在300Mhz时,总的算力为600Gops。
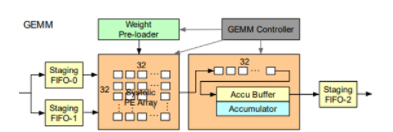
Figure13 GEMM[1]
实验对比
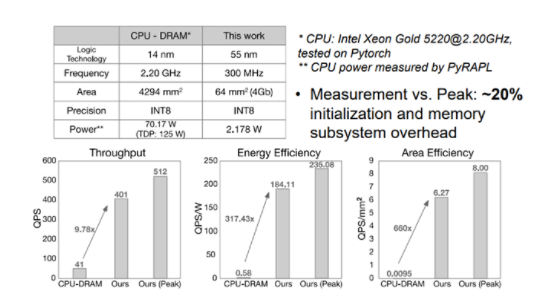
Figure14 性能功耗表现(vs CPU-DRAM)[1] 文章首先和CPU+DRAM组成的系统相比,该近存处理系统有9.7 倍的吞吐率QPS优势,317倍的能效优势QPS/W,660倍的面积优势QPS/mm2。
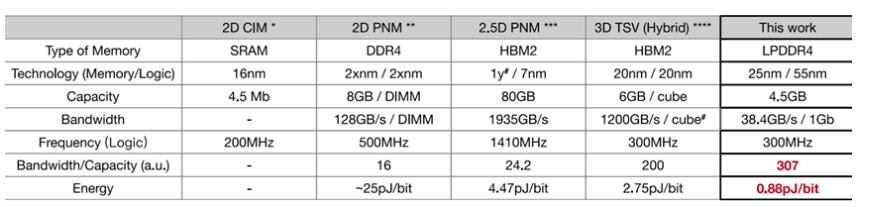
Figure15 性能功耗表现 vs CIM/PNM[1] 同时,文章还和最好的CIM/PNM处理器进行了对比,该设计在单位容量带宽上,单位带宽能耗上也保持很大的优势。
总结
PNM和CIM架构可以很大程度上提高内存受限的应用的性能和功耗表现,本设计中的3D逻辑-DRAM Hybird bonding chip有以下几个特点:
- 使用3D Hybrid bonding技术,为整个系统提供了具有高带宽和能效的存储系统。
- 使用了高吞吐率的流处理加速设计来进行粗召回和精排系统优化操作。
- 该设计达到了2.4GB/s/mm带宽密度,0.87pJ/bit的能耗指标。
- 对于传统的CPU+DRAM系统,该设计有300倍的能效提升和10倍的性能提升。
参考文献
[1] Austin Derrow-Pinion, Jennifer She, David Wong, et al. ETA Predictionwith Graph Neural Networks in Google Maps. 2021
[1] 184QPS/W 64Mb/mm2 3D Logic-to-DRAM Hybrid Bonding with Process-Near-Memory Engine for Recommendation System DiminNiu, Shuangchen Li, Yuhao Wang, Wei Han, Zhe Zhang,Yijin Guan, Tianchan Guan, FeiSun, Fei Xue, Lide Duan, Yuanwei Fang, Hongzhong Zheng, Xiping Jiang, SongWang, Fengguo Zuo, Yubing Wang, Bing Yu, Qiwei Ren, Yuan Xie
-
如何读取PSoC处理器的非易失性锁存器?2019-08-15 1089
-
基于TMS320C6701信号处理器的高性能信号处理模块的设计方案2021-04-02 2504
-
求一种嵌入式PLC微处理器的设计方案2021-05-06 1898
-
分享一款不错的通用微处理器与DSP的接口设计方案2021-06-08 2217
-
基于DSP处理器的光纤高温测量仪的设计方案2010-01-08 1477
-
基于ARM处理器的车载GPS系统设计方案2010-03-23 1464
-
可重构密码流处理器片外流访存系统的设计2017-01-07 760
-
基于I2C总线的处理器的联网设计方案2017-01-26 966
-
苹果又惹上官司 iPhone用户表示A系列处理器存漏洞2018-01-16 1358
-
常用锁存器芯片有哪些_锁存器的作用介绍2018-01-31 84654
-
特斯拉的下一代AI芯片:存算一体2023-03-09 3657
全部0条评论

快来发表一下你的评论吧 !
