

开发嵌入式神经网络的现实
电子说
描述
关于将人工智能用于越来越智能的车辆的文章已经很多。但是,您如何将在服务器场上开发的神经网络 (NN) 压缩到量产汽车中资源受限的嵌入式硬件中呢?本文探讨了我们应该如何授权汽车生产 AI 研发工程师在将 NN 从原型到生产的整个过程中改进 NN,而不是像今天过早地将 NN 移交给嵌入式软件团队的过程。
“如果我们要充分利用嵌入式硬件资源,我们需要让生产 AI 团队在软件移植过程中利用他们对 NN 的知识”(来源:Marton Feher,SVP 硬件工程,AImotive)
嵌入式人工智能:嵌入式软件——但不是我们所知道的
对于任何注定要在批量生产中部署的嵌入式软件,一旦完成并验证了其核心功能的实现,就会在代码中投入大量精力。这个优化阶段是关于最小化所需的内存、CPU 和其他资源,以便尽可能多地保留软件功能,同时将执行它所需的资源减少到绝对最低限度。
这种从基于实验室的算法创建嵌入式软件的过程使生产工程师能够将软件功能成本工程化为可量产的形式,与用于开发它的海量计算数据中心相比,所需的芯片和硬件更便宜、功能更差。但是,它通常需要从一开始就冻结功能,只进行代码修改以改进算法本身的执行方式。对于大多数软件来说,这很好:确实,它可以使用严格的验证方法来确保嵌入过程保留所需的所有功能。
然而,当嵌入基于 NN 的 AI 算法时,这可能是一个主要问题。为什么?因为从一开始就冻结功能,您正在删除可以优化执行的主要方法之一。
问题是什么?
有两种根本不同的方法可以解决将复杂的 NN 从实验室中不受约束、资源丰富的 NN 训练环境移植到受严格约束的嵌入式硬件平台的任务:
优化执行NN的代码
优化神经网络本身
当嵌入式软件工程师发现性能问题,例如内存带宽瓶颈或底层嵌入式硬件平台利用率低下时,传统的嵌入式软件技术会鼓励您深入挖掘底层代码并找出问题所在。
这反映在当今可用于嵌入式MCU和DSP的许多先进而复杂的工具中。它们使您能够了解软件中正在发生的事情的最低水平,并识别和改进软件本身的执行——希望不会改变其功能。
对于神经网络来说,优化与传统的嵌入式软件完全不同——至少如果你想用可用的硬件资源实现尽可能最佳的结果。对于神经网络,通过改变拓扑神经网络本身(神经网络的各个层如何连接,以及每个层做什么)和使用更新的约束和输入重新训练来实现改进。这是因为功能不是由神经网络“软件”定义的,而是在训练期间应用的目标和约束,以创建定义神经网络最终行为的权重。
因此,在执行神经网络的嵌入过程时,需要冻结神经网络的目标性能,而不是如何实现它。如果您从嵌入过程开始就约束神经网络拓扑,那么您就是在删除生产工程师需要的提高性能的工具。
这意味着您需要新的不同工具来完成将NNs从实验室移植到嵌入式平台的任务。低级软件工程师无法完成这项工作——你需要人工智能工程师根据工具提供的性能信息来调整神经网络及其训练。这是新的:当研发工程师将经过培训的神经网络交给生产工程师时,他们再也不能说“工作完成了”!
不同的方法
通过采用将 AI 研发工程师置于嵌入式软件移植任务中心的开发工作流程,任何芯片都可以实现卓越的结果。使用以层为中心的分析,辅以从编译改进的卷积神经网络 (CNN) 到查看目标神经处理器单元 (NPU) 的准确性能结果的几分钟内快速周转,开发人员可以使用相同的底层硬件实现 100% 或更多的增益. 这是因为修改 CNN 本身,而不是只修改用于执行相同 CNN 的代码,为 AI 工程师提供了更大的灵活性来识别和实施性能改进。
在开发我们的 aiWare NPU 时,AImotive 使用了我们自己的 AI 工程师将移植过程移植到具有广泛 NPU 功能的多个不同芯片的经验。我们希望找到更好的方法来帮助我们自己的 AI 工程师完成这项任务,因此在开发我们对 aiWare NPU 本身和支持它的 aiWare Studio 工具的要求时,我们确定了我们在过去的:
高度确定性的 NPU 架构,使时序非常可预测
准确的基于层(不是基于时序或低级代码)的性能估计,以便任何 AI 研发工程师都可以看到更改其训练标准(例如添加或更改使用的场景,或修改目标 KPI)的影响; / 或 NN 拓扑快速
准确的离线性能估计,以便在第一个硬件可用之前执行所有 NN 优化(因为第一个原型总是稀缺的!)
点击查看完整大小的图片
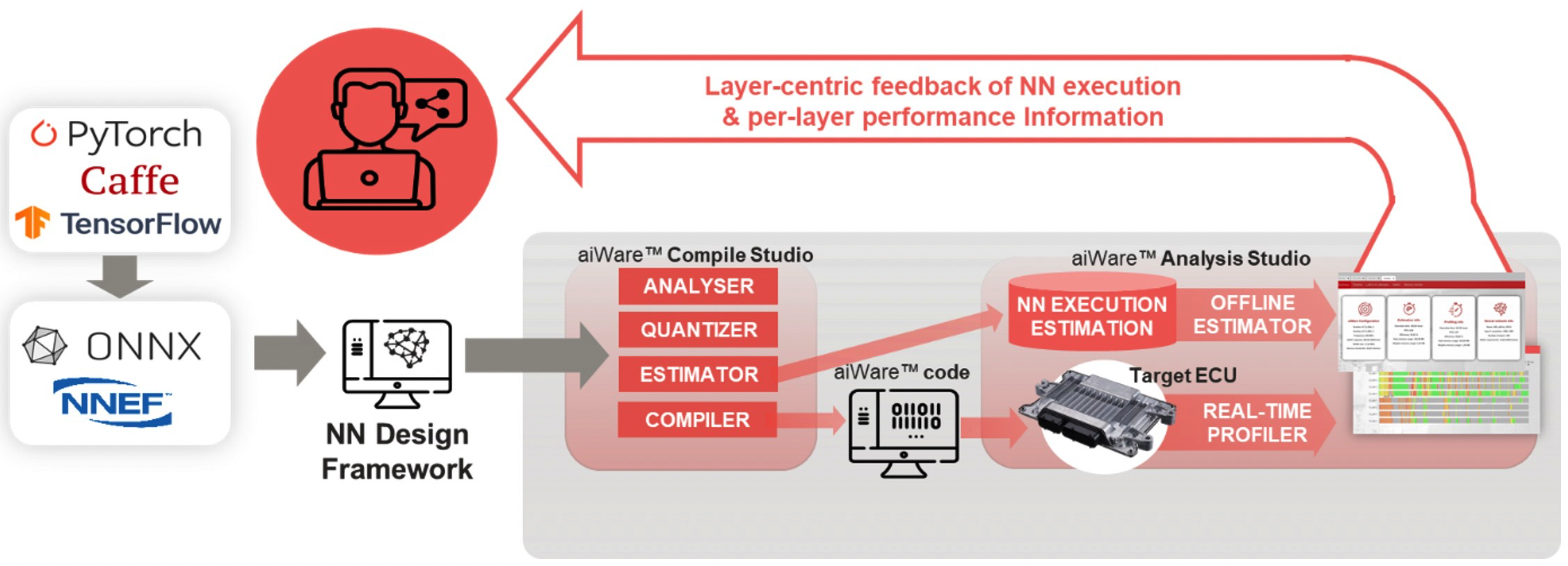
图 1:aiWare Studio 使用户能够优化他们的 NN,而不是用于执行它们的代码。这为 AI 设计人员提供了更大的灵活性,可以更快地实现出色的结果。(来源:AImotive)
结果是一组工具使 AI 研发工程师能够在实验室环境中对目标硬件进行几乎所有优化,并在最终目标硬件的 5% 范围内展示性能——这一切都在任何人看到硬件之前完成。
最终检查
当然,在芯片和硬件原型可用时测量最终硬件至关重要。这种开发环境中实时硬件分析功能的可用性使工程师能够访问由此类工具支持的 NPU 内的一系列深度嵌入式硬件寄存器和计数器。虽然芯片开销很小(因为许多 NPU 主要由内存而非逻辑控制),但这些功能可以在执行期间实现前所未有的、非侵入式的实时性能测量。然后可以将其用于直接与离线性能估计器结果进行比较,以确认准确性。
点击查看完整大小的图片
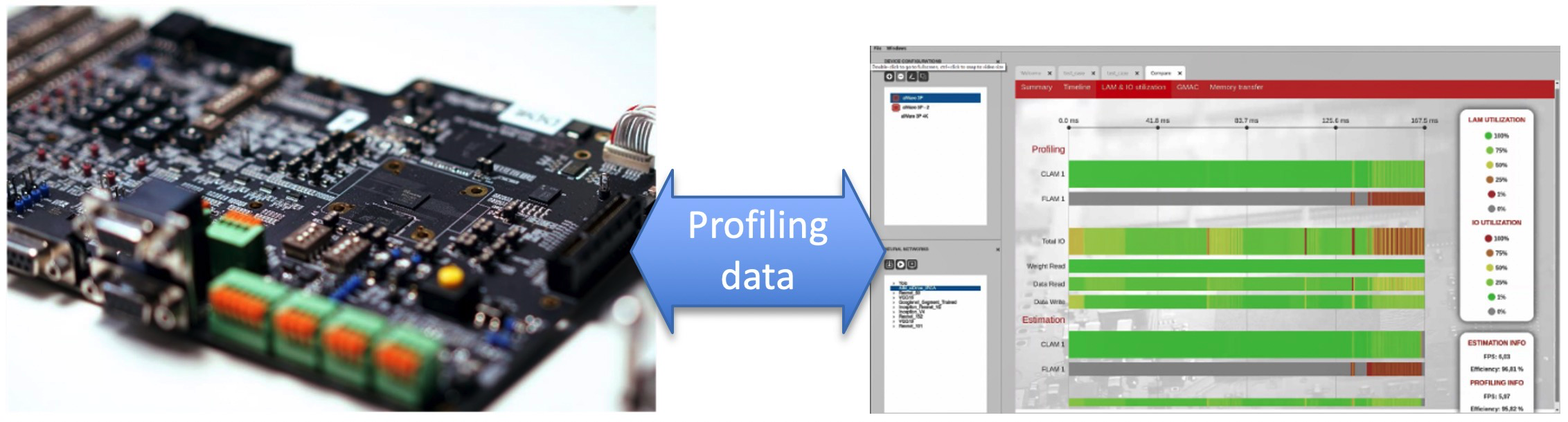
图 2:使用嵌入式寄存器和计数器,aiWare Studio 可以准确测量最终芯片性能,与离线估计结果相比,通常在 1%-5% 以内。(来源:AImotive 和 Nextchip Co. Ltd)
结论
这种新方法为汽车行业提供了一种新的、更好的方式来开发、优化和在生产车辆中部署人工智能。使用协同 NPU 硬件和工具,人工智能工程师可以为汽车应用设计、实施和优化更好的 CNN。
审核编辑 黄昊宇
-
卷积神经网络一维卷积的处理过程2021-12-23 2150
-
轻量化神经网络的相关资料下载2021-12-14 2149
-
嵌入式中的人工神经网络的相关资料分享2021-11-09 1517
-
嵌入式中的人工神经网络2021-11-04 912
-
开发嵌入式神经网络的现实2021-11-03 613
-
针对Arm嵌入式设备优化的神经网络推理引擎2021-01-15 2366
-
基于深度神经网络的激光雷达物体识别系统及其嵌入式平台部署2021-01-04 2000
-
嵌入式神经网络有哪些挑战2020-06-30 3412
-
嵌入式神经网络加速器的市场需求将持续增加2019-11-22 1451
-
Facebook的神经网络新研究将助力嵌入式设备的发展2019-11-18 1053
-
以AI神经网络为导向的嵌入式系统市场迎来爆发期2019-11-14 1173
-
怎么设计ARM与神经网络处理器的通信方案?2019-09-20 2817
-
Facebook神经网络新研究将造福嵌入式设备2019-08-07 1180
-
神经网络解决方案让自动驾驶成为现实2017-12-21 8977
全部0条评论

快来发表一下你的评论吧 !
