

在没有机器学习技能的情况下实施预测性维护
电子说
描述
如今,工程师们越来越意识到,预测性维护现在几乎是人工智能 (AI) 技术的专有领域,他们首先需要学习机器学习 (ML) 和神经网络技能来实现此类应用程序。MathWorks 高级产品营销经理 Aditya Baru 表示,工程师仍然可以部署预测性维护,而无需学习新的 AI 和 ML 技能。
在最近与EDN的一次谈话中,Baru 概述了实施预测性维护的四个基本步骤,并补充说每个步骤都有专门的工具可用。
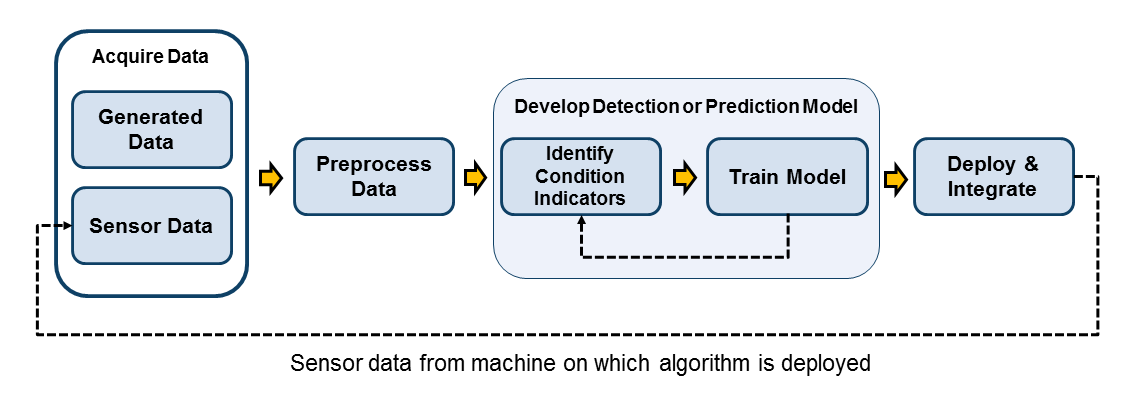
图 1. 基本的预测性维护工作流程包括四个基本步骤。
1.数据处理
对于不是数据科学家或没有机器学习背景的工程师来说,查看由传感器和工业设备(如风力涡轮机、发电机、泵和电机)生成的大量数据并不容易。工程师处理的数据主要是原始数据;它又脏又脏。
勘探作业中的喷气发动机或油泵每天可以轻松创建 1TB 的数据;现在想象一下在 TB 的数据中寻找故障条件。那么,工程师能做什么呢?“工程师可以查看大量传入的数据,找出原始数据中是否有任何变化,识别任何系统退化,并确定系统出现异常行为的原因,”Baru 说。
例如,在石油勘探泵中,工程师可以查看原始数据的一件事是对持续旋转的泵进行光谱分析。因此,他们可以识别故障出现的频率。“虽然工程师已经了解这台机器,但他们现在要做的是确定最有效的方法。”
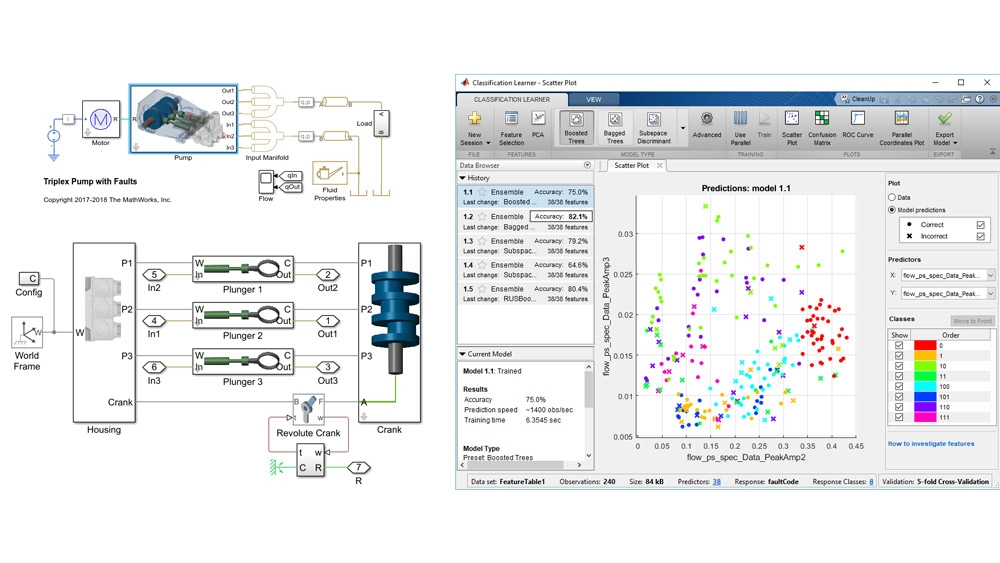
图 2. 工程师可以通过跟踪电机摩擦的变化来检测泵中的泄漏和堵塞。
这将我们带到第二个基本步骤,条件指标,一种数据缩减方法。
2.状态指标
如果工程师有 100 个时间序列数据样本,他应该设法将其减少到一个数字,而这个数字必须捕获这 100 个样本中的所有相关信息。“我们的想法是你获取一个巨大的数据集并将其减少为更少的特征。”
Baru 提到了最近的一个项目,在该项目中,MathWorks 与戴姆勒梅赛德斯合作开发了一个异常检测应用程序,该应用程序分析大量时间序列数据并确定生产线是否存在异常情况。在这里,MathWorks 工具将大量数据减少为一组较小的特征(例如模式和时间延迟),从而将数据处理减少了 250 倍。
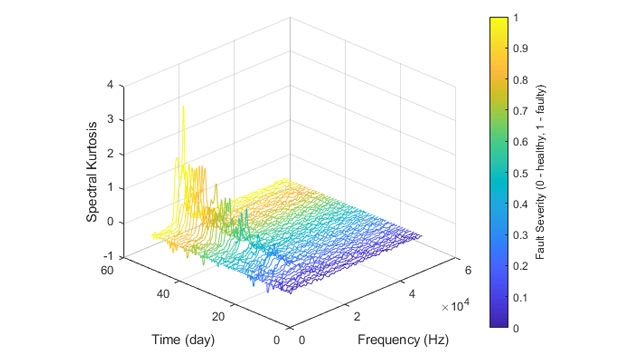
图 3. 工程师可以从原始传感器数据中提取特征,并使用基于时间和频率的技术创建条件指标。资料来源:数学工作
现在工程师正在研究较少数量的条件指标,他们可以根据这些条件指标构建预测模型。
3.预测模型
使用代表整个大型数据集并捕获独特信息的小得多的数据集,工程师可以使用合适的工具来创建预测学习模型,而无需学习 AI 和 ML 技能集。
各种模型(例如时间序列模型、统计模型和基于概率的模型)同样适用于构建预测模型。“有很多用于构建预测模型的传统工程技术,”Baru 说。
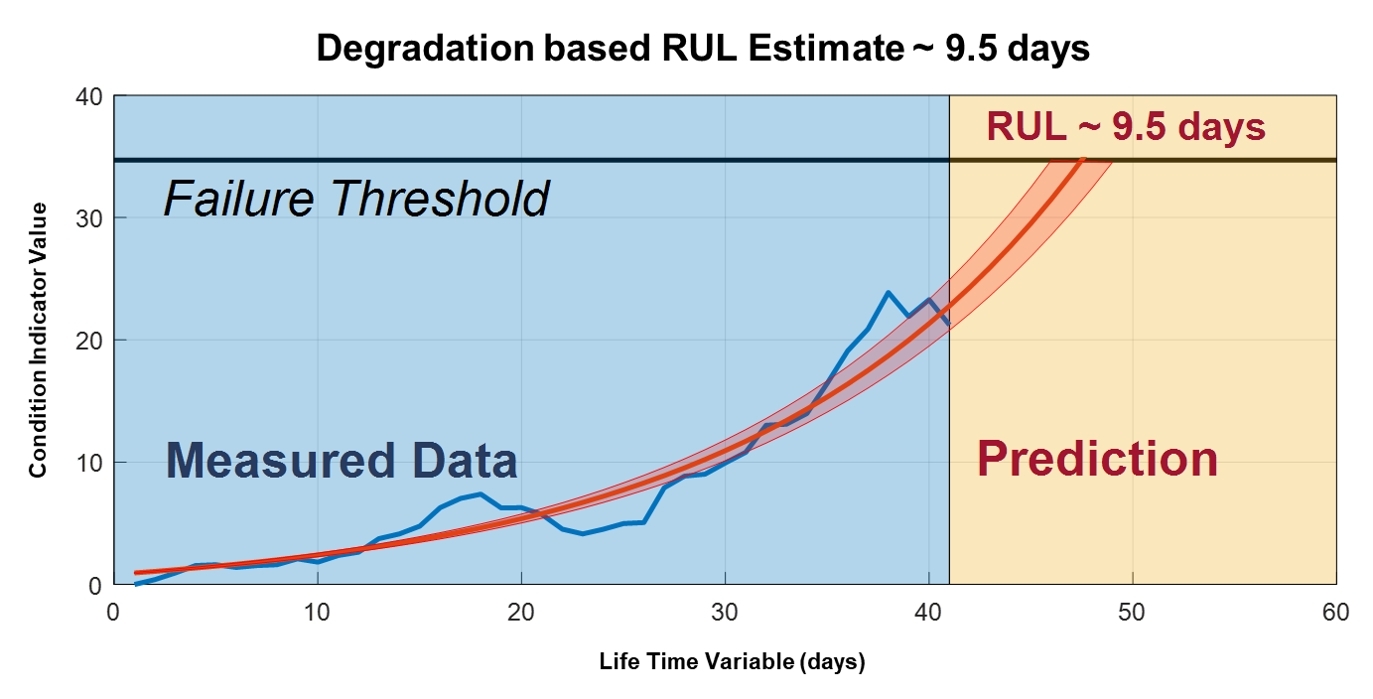
图 4. Predictive Maintenance Toolbox使工程师能够估计剩余使用寿命 (RUL) 并提供与预测相关的置信区间。资料来源:MathWorks
工程师还可以将工具重新用于稍微不同的应用程序。Baru 提到了 Safran,这是一家航空航天公司,它使用信号调理技术来预测系统何时可能出现故障。这项工作是在MATLAB中完成的,这是一个用于算法开发、数据分析、可视化和数值计算的编程环境。
4.算法部署
第四步可能是最重要的:在生产环境中为预测模型部署算法。工程师可以通过多种方式部署算法。这包括本地嵌入机器的预测模型、作为本地服务器在本地运行的小型计算机,或者在连接可行时将数据流式传输到云服务。
在这个四步工作流程中实施的预测性维护允许工程师部署维护服务,以保证机器在 90% 的时间内保持运行。并且可以使用工具来有效地管理所有这四个基本步骤。
审核编辑:郭婷
-
传感器在工业 4.0 预测性维护中的应用2022-04-21 8409
-
[转]物联网和机器学习究竟有哪些真实应用价值?2017-04-19 12814
-
什么是机器学习? 机器学习基础入门2022-06-21 3077
-
没有仿真器的情况下如何开发AVR2017-09-21 960
-
在没有网络和WIFI的情况下用手机无线投屏到电视2019-09-13 43584
-
如何成功实施和管理物联网预测性维护计划2019-09-25 1374
-
如何实施物联网预测性维护解决方案2020-03-17 2071
-
预测性维护该如何实施?2021-11-09 2487
-
什么是状态监测,“预测性维护”该如何实施2021-11-29 2217
-
如何在边缘使用机器学习提高生产线质量2022-05-31 1595
-
如何避免实施预测性维护时面临的三个常见障碍2022-07-06 1671
-
在没有GPS的情况下跟踪我的汽车行程2022-11-14 705
-
如何在没有Arduino情况下制作机器人2022-12-05 600
-
使用振动对旋转机器进行预测性维护2023-06-20 713
-
在没有人机界面的情况下,应如何配置设备?2023-11-03 1526
全部0条评论

快来发表一下你的评论吧 !
