

Python编程语言开源库NUMPY的工作原理及优势
描述
NumPy 是一个免费的开源 Python 库,用于 n 维数组(也称为张量)处理和数值计算。
什么是 NUMPY?
NumPy 是一个免费的 Python 编程语言开源库,它功能强大、已经过充分优化,并增加了对大型多维数组(也称为矩阵或张量)的支持。NumPy 还提供了一系列高级数学函数,可与这些数组结合使用。其中包括基本的线性代数、随机模拟、傅立叶变换、三角运算和统计运算。
NumPy 代表 “numerical Python”,基于早期的 Numeric 和 Numarray 库构建而成,旨在为 Python 提供快速的数字计算。如今,NumPy 贡献者众多,并得到了 NumFOCUS 的赞助。
作为科学计算的核心库,NumPy 是 Pandas、Scikit-learn 和 SciPy 等库的基础。它广泛应用于在大型数组上执行优化的数学运算。
选择 NUMPY 的原因及其工作原理
多维数组是 NumPy 库的中心数据结构,通常代表值的网格。NumPy 的 ndarray 是一个同构的 n 维数组对象,描述了类似类型的元素或项的集合。在这些 ndarrays 中,每个项都包含大小相同的内存块,且每个内存块都采用同一识别方式。这能够高效、快速、轻松地处理科学计算的数据。
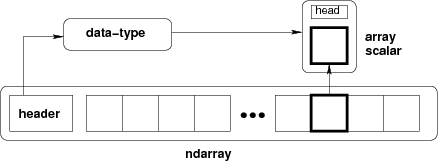
NumPy 数组运算速度比 Python Lists 要快,因为 NumPy 数组是类似数据类型的编译,并且在内存中密集打包。相比之下,Python Lists 可以具有不同的数据类型,在系统执行计算时会增加对这些数据类型的限制。
| NumPy 的优势
NumPy 具有以下重要优势和特性:
NumPy 的 ndarray 计算概念是 Python 和 PyData 科学生态系统的核心。
NumPy 为高度优化的 C 函数提供了 Python 前端,可提供简单的 Python 接口,并实现编译代码的速度。
NumPy 强大的 N 维数组对象可与各种库集成。
与使用 Python 的内置列表相比,NumPy 数组可以更高效地使用大型数据集来执行高级数学运算,且使用的代码更少。对于大小和速度至关重要的科学计算序列而言,这一点至关重要。
NUMPY 的重要意义
NumPy 让数据科学家更易于使用 Python 并提供了 C 级优化,有助于快速创建高效代码,进行探索数据分析和模型构建。如今,要想在科学计算领域取得成功,对算法进行快速原型设计必不可少,而这二者的实现对此至关重要。因此,可以使用 NumPy 在 Python 中实现多维数据通信。
利用 PYTHON 进行 GPU 加速计算
在架构方面,CPU 仅由几个具有大缓存内存的核心组成,一次只可以处理几个软件线程。相比之下,GPU 由数百个核心组成,可以同时处理数千个线程。

NumPy 已成为在 Python 中实现多维数据通信的实际方法。然而,对于多核 GPU,这种实施并非最佳。因此,对于较新的针对 GPU 优化的库实施 Numpy 数组或与 Numpy 数组进行互操作。
NVIDIA CUDA 是 NVIDIA 专为 GPU 通用计算开发的并行计算平台和编程模型。CUDA 数组接口是描述 GPU 数组(张量)的标准格式,允许在不同的库之间共享 GPU 数组,而无需复制或转换数据。CUDA 数组由 Numba、CuPy、MXNet 和 PyTorch 提供支持。
CuPy 是一个利用 GPU 库在 NVIDIA GPU 上实施 NumPy CUDA 数组的库。
Numba 是一个 Python 编译器,可以编译 Python 代码,以在支持 CUDA 的 GPU 上执行。Numba 直接支持 NumPy 数组。
Apache MXNet 是一个灵活高效的深度学习库。可以使用它的 NDArray 将模型的输入和输出表示和操作为多维数组。NDArray 类似于 NumPy 的 ndarray,但它们可以在 GPU 上运行,以加速计算。
PyTorch 是一种开源深度学习框架,以出色的灵活性和易用性著称。Pytorch Tensors 与 NumPy 的 ndarray 类似,但它们可以在 GPU 上运行,加速计算。
NVIDIA GPU 加速的端到端数据科学
基于 CUDA-X AI 创建的 NVIDIA RAPIDS 开源软件库套件使您完全能够在 GPU 上执行端到端数据科学和分析流程。此套件依靠 NVIDIA CUDA 基元进行低级别计算优化,但通过用户友好型 Python 接口实现了 GPU 并行化和高带宽显存速度。
借助 RAPIDS GPU DataFrame,数据可以通过一个类似 Pandas 的接口加载到 GPU 上,然后用于各种连接的机器学习和图形分析算法,而无需离开 GPU。这种级别的互操作性是通过 Apache Arrow 这样的库实现的。仅需一行代码,即可从 NumPy 数组、Pandas DataFrame 和 PyArrow 表格创建 GPU 数据框。其他项目可以使用数组接口交换 CUDA 数据。这可加速端到端流程(从数据准备到机器学习,再到深度学习)。
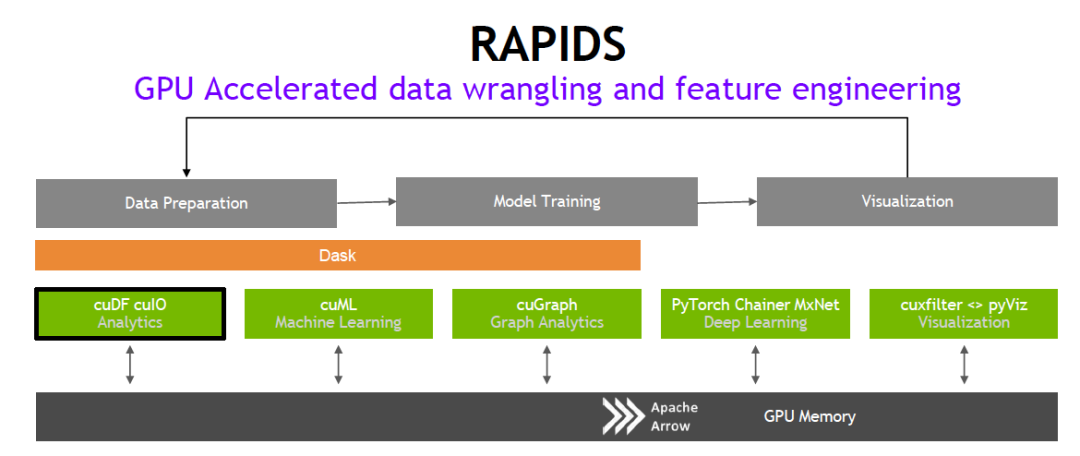
RAPIDS 支持在许多热门数据科学库之间共享设备内存。这样可将数据保留在 GPU 上,并省去了来回复制主机内存的高昂成本。
-
python第三方库有哪些2023-11-29 3369
-
Python编程语言属于什么语言2023-11-22 3524
-
什么是NumPy?选择NUMPY的原因及其工作原理是什么2022-07-15 5132
-
详解Python中的Pandas和Numpy库2022-05-25 4412
-
Python和R语言都适合进行数据分析2020-03-25 3660
-
不得不知的6大Python编程的优势2018-06-28 2745
-
Python语言在人工智能中的功能及优势2018-05-22 12460
-
python和别的语言比所具备的优势2018-04-13 3433
-
数据分析必备的NumPy技巧(Python)2018-03-05 6712
-
Python编程语言可以应用在哪些方面?2018-02-05 4761
-
基于python的numpy深度解析2018-01-24 6116
-
python和matlab哪个好?2017-11-20 43921
-
Python中NumPy扩展包简介及案例详解2017-11-15 6618
全部0条评论

快来发表一下你的评论吧 !
