

如何在 MCU 上快速部署 TinyML
电子说
描述
您对人工智能 (AI) 和机器学习 (ML) 感到好奇吗?您想知道如何在您已经使用过的微控制器上使用它吗?在本文中,我们向您介绍了微控制器上的机器学习。该主题也称为微型机器学习 (TinyML)。准备好在石头、纸、剪刀上输给 ESP-EYE。您将了解数据收集和处理、如何设计和训练 AI 以及如何使其在 MCU 上运行。这个示例为您提供了从头到尾完成您自己的 TinyML 项目所需的一切。
我为什么要关心 TinyML?
您肯定听说过 DeepMind 和 OpenAI 等科技公司。他们凭借专家和 GPU 能力在 ML 领域占据主导地位。为了给人一种规模感,最好的人工智能,比如谷歌翻译使用的人工智能,需要几个月的训练。他们并行使用数百个高性能 GPU。TinyML 通过变小来扭转局面。由于内存限制,大型 AI 模型不适合微控制器。下图显示了硬件要求之间的差异。
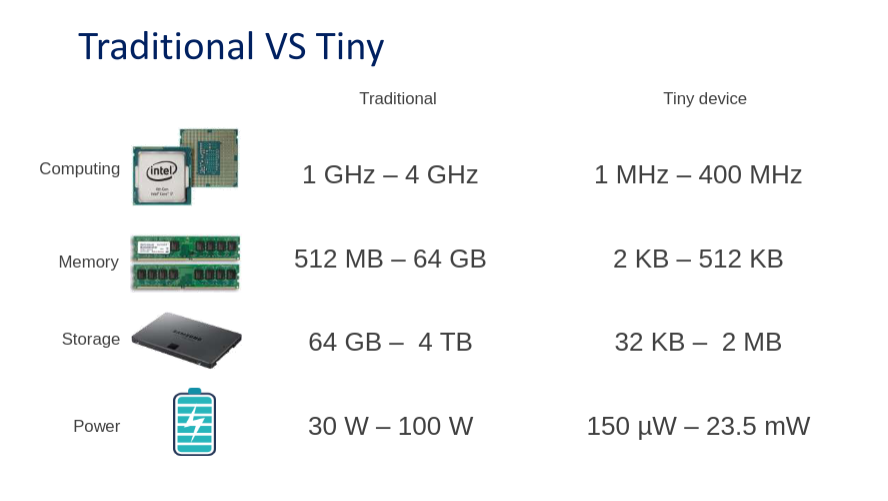
与在云端使用 AI 服务相比,MCU 上的机器学习有哪些优势?我们发现了七个主要优势。
成本
微控制器的购买和运行都很便宜。
环保
在微控制器上运行 AI 消耗的能量很少。
一体化
微控制器很容易集成到现有环境中,例如生产线。
隐私和安全
数据可以在本地、在设备上处理。数据不必通过互联网发送。
快速原型制作
TinyML 使您能够在短时间内开发概念验证解决方案。
自主可靠
即使没有基础设施,微型设备也可以在任何地方使用。
即时的
数据在微控制器上进行处理,没有延迟。唯一的限制是 MCU 的处理速度。
剪刀石头布
你有没有在石头、纸、剪刀上输给人工智能?或者你想通过击败人工智能来给你的朋友留下深刻印象?您将使用 TinyML 与 ESP-EYE 板对战。要使这样的项目成为可能,您需要学习五个步骤。以下部分提供了必要步骤的高级概述。如果您想仔细查看,请参阅我们项目存储库中的文档。它解释了漂亮的细节。
收集资料
收集数据是机器学习的关键部分。为了让事情运行起来,你需要拍摄你的手形成石头、纸、剪刀手势的图像。图片越独特越好。AI 将了解到您的手可以处于不同的角度、位置或光线变化。数据集包含记录的图像和每个图像的标签。这被称为监督学习。
最好使用与训练 AI 相同的传感器和环境来运行您的 AI。这将确保模型熟悉传入的数据。例如,考虑由于制造差异,温度传感器在相同温度下具有不同的电压输出。就我们而言,这意味着使用 ESP-EYE 相机在统一的背景上记录图像是理想的选择。在部署期间,人工智能将在类似的背景下工作得最好。您还可以使用网络摄像头记录图像,但可能会牺牲一些准确性。由于 MCU 容量有限,我们记录和处理 96×96 像素的灰度图像。
收集数据后,将数据拆分为训练集和测试集非常重要。我们这样做是为了看看我们的模型如何识别它以前从未见过的手势图像。该模型自然会在训练期间已经看到的图像上表现良好。

以下是一些示例图像。如果您现在不想收集数据,可以在这里下载我们现成的数据集。
预处理数据
识别数据中的模式不仅对人类来说很困难。为了让 AI 模型更容易做到这一点,通常依赖于预处理算法。在我们的数据集中,我们使用 ESP-EYE 和网络摄像头记录图像。由于 ESP-EYE 可以捕获 96×96 分辨率的灰度图像,因此我们不需要在这里进行太多进一步的处理。但是,我们需要将网络摄像头图像缩小并裁剪为 96×96 像素,并将它们从 RGB 转换为灰度格式。最后,我们对所有图像进行归一化。下面,您将看到我们处理的中间步骤。
 设计模型
设计模型
设计一个模型是相当棘手的!详细的处理超出了本文的范围。我们将描述模型的基本组件以及我们如何设计我们的模型。在引擎盖下,我们的 AI 依赖于神经网络。您可以将神经网络视为神经元的集合,有点像我们的大脑。这就是为什么在僵尸末日的情况下,人工智能也会被僵尸吃掉。
当网络中的所有神经元相互连接时,这称为全连接或密集。这可以被认为是最基本的神经网络类型。由于我们希望我们的 AI 能够从图像中识别手势,因此我们使用了一些更先进且更适合图像的东西,即卷积神经网络 (CNN)。卷积降低了图像的维度,提取了重要的模式并保留了像素之间的局部关系。为了设计一个模型,我们使用了TensorFlow 库,它提供了现成的神经网络组件,称为层,这使得创建神经网络变得容易!
创建模型意味着堆叠层。它们的正确组合对于开发稳健且高精度的模型至关重要。下图显示了我们正在使用的不同层。Conv2D表示卷积层。批标准化layer 对上一层的输出应用一种归一化形式。然后我们将数据输入激活层,这会引入非线性并过滤掉不重要的数据点。接下来,最大池化类似于卷积减小图像的大小。这个层块重复了几次;合适的量是由经验和实验决定的。之后,我们使用扁平化层将二维图像缩减为一维数组。最后,该阵列紧密连接到三个神经元,它们分别代表石头、纸和剪刀等类别。
def make_model_simple_cnn (INPUT_IMG_SHAPE, num_classes= 3 ): 输入= keras.Input(形状=INPUT_IMG_SHAPE) x = 输入 x = layers.Rescaling( 1.0 / 255 )(x) x = layers.Conv2D( 16 , 3 , strides= 3 , padding= "same" )(x) x = layers.BatchNormalization()(x) x = layers.Activation( “relu” )(x) x = 层数.MaxPooling2D()(x) x = layers.Conv2D( 32 , 3 , strides= 2 , padding= "same" , activation= "relu" )(x) x = 层数.MaxPooling2D()(x) x = layers.Conv2D( 64 , 3 , padding= "same" , activation= "relu" )(x) x = 层数.MaxPooling2D()(x) x = 层.Flatten()(x) x = 层数.Dropout( 0.5 )(x) output = layers.Dense(units=num_classes, activation= "softmax" )(x) return keras.Model(inputs, outputs)
训练模型
一旦我们设计了一个模型,我们就可以训练它了。最初,人工智能模型会做出随机预测。预测是与标签相关的概率,在我们的例子中是石头、纸或剪刀。我们的 AI 告诉我们它将图像视为每个标签的可能性有多大。因为人工智能在一开始就在猜测标签,所以它经常会弄错标签。将预测标签与真实标签进行比较后进行训练。预测错误会导致网络中神经元之间的更新。这种学习形式称为梯度下降。因为我们在 TensorFlow 中构建了模型,所以训练就像一、二、三一样简单。下面,您会看到训练期间产生的输出——准确度(训练集)和验证准确度(测试集)越高越好!
时期1 / 6 480 / 480 [===============================] - 17秒34毫秒/步 - 损失:0.4738 - 准确度:0.6579 - val_loss:0.3744 - val_accuracy:0.8718 Epoch 2 / 6 216 / 480 [============>....... ] - ETA:7秒 - 损失:0.2753 - 准确度:0.8436
在训练期间,可能会出现多个问题。最常见的问题是过拟合。当模型一遍又一遍地暴露在相同的例子中时,它会开始记住训练数据,而不是学习底层模式。当然,您从学校记得理解比记忆更好!在某些时候,训练数据的准确率可能会继续上升,而测试集的准确率则不会。这是过度拟合的明确指标。
转换模型
经过训练,我们得到一个 TensorFlow 格式的 AI 模型。由于 ESP-EYE 无法解释这种格式,我们将模型更改为微处理器可读格式。我们从转换为 TfLite 模型开始。TfLite 是一种更紧凑的 TensorFlow 格式,它使用量化导致模型尺寸减小。TfLite 常用于世界各地的边缘设备,例如智能手机或平板电脑。最后一步是将 TfLite 模型转换为 C 数组,因为微控制器无法直接解释 TfLite。
部署模型
现在我们可以将模型部署到微处理器上。我们唯一需要做的就是将新的 C 数组放入预期的文件中。替换 C 数组的内容,不要忘记替换文件末尾的数组长度变量。我们提供了一个脚本来简化此操作。就是这样!
嵌入式环境
让我们回顾一下 MCU 上发生的事情。在设置过程中,解释器被配置为我们图像的形状。
//初始化解释器
静态tflite::MicroInterpreter static_interpreter (
模型、解析器、tensor_arena、kTensorArenaSize、error_reporter);
解释器 = &static_interpreter;
模型输入=解释器->输入(0);
模型输出=解释器->输出(0);
// 断言真实输入与期望输入匹配
if ((model_input->dims->size != 4) || // 形状 (1, 96, 96, 1) 的张量具有昏暗 4
(model_input->dims->data[ 0] != 1) || // 每批 1 个 img
(model_input->dims->data[1] != 96) || // 96 x 像素
(model_input->dims->data[2] != 96 ) || // 96 y 像素
(model_input->dims->data[3] != 1) || // 1 通道(灰度)
(model_input->type != kTfLiteFloat32)) { // 单个数据的类型点,这里是一个像素
error_reporter->Report( "Bad input tensor parameters in model\n" );
返回;
}
设置完成后,捕获的图像被发送到模型,在模型中进行手势预测。
// 从摄像头读取图像到一维数组
uint8_t img[dim1*dim2*dim3]
if (kTfLiteOk != GetImage(error_reporter, dim1, dim2, dim3, img)) {
TF_LITE_REPORT_ERROR(error_reporter, "图像捕获失败。" );
}
// 将图像写入模型
std :: vector < uint8_t > img_vec(img, img + dim1*dim2*dim3);
std ::向量< float_t > img_float(img_vec.begin(), img_vec.end());
标准::copy(img_float.begin(), img_float.end(), model_input->data.f);
// 应用推理
TfLiteStatus invoke_status = 解释器->Invoke();
}
然后模型返回每个手势的概率。由于概率数组只是一系列介于 0 和 1 之间的值,因此需要进行一些解释。我们认为识别出的手势是概率最高的手势。现在我们通过将识别的手势与 AI 的动作进行比较来处理解释,并确定谁赢得了回合。你没有机会了!
// 每个类的概率 浮动纸=模型输出->数据.f[0]; 浮动岩石 = model_output->data.f[1]; 浮动剪刀 = model_output->data.f[2];
下面的可爱图表说明了 MCU 上的步骤。出于我们的目的,不需要对微控制器进行预处理。
点击查看完整大小的图片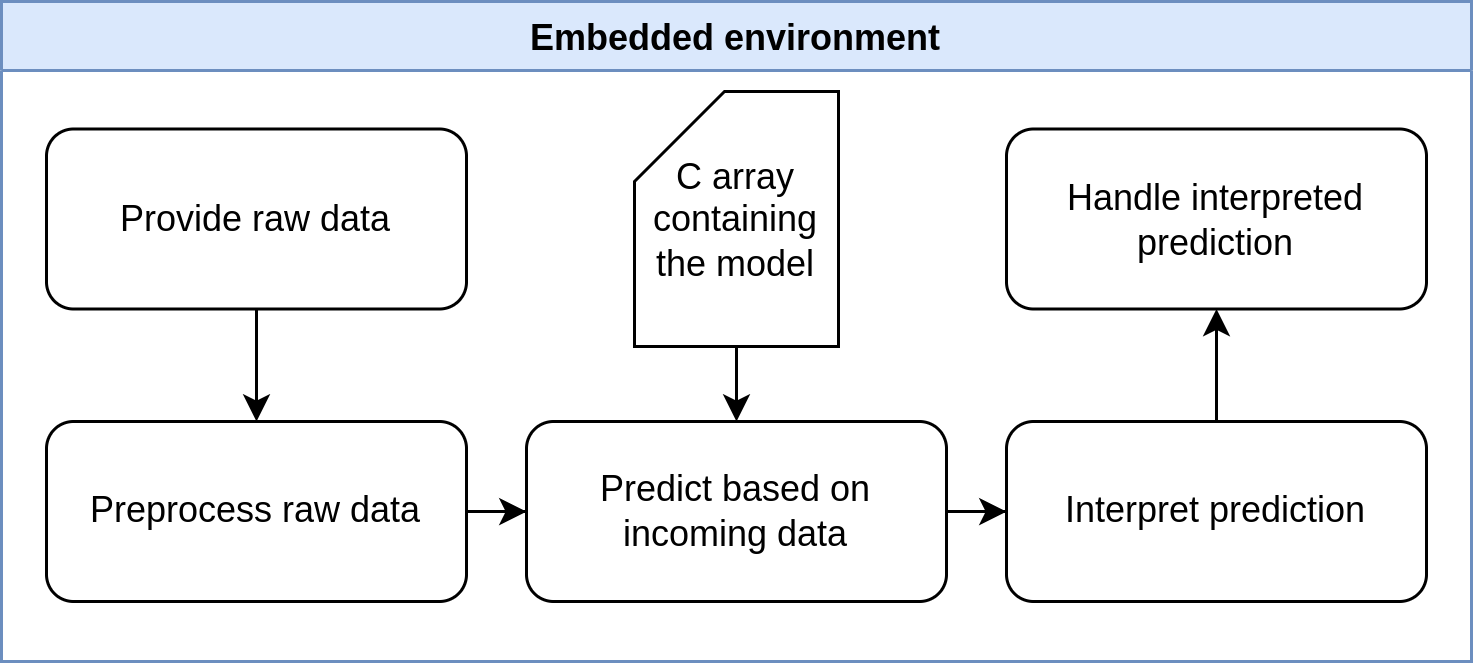
展开示例
来个挑战怎么样?人生的新目标?想要给老朋友留下深刻印象或寻找新朋友?通过添加蜥蜴和史波克,将石头、纸、剪刀提升到一个新的水平。你的 AI 朋友将是一项更接近世界统治的技能。好吧,首先你应该看看我们的石头、纸、剪刀存储库,并能够复制上述步骤。自述文件将帮助您了解详细信息。下图向您展示了游戏的运作方式。您需要添加两个额外的手势和一些新的输赢条件。
点击查看完整大小的图片
开始你自己的项目
如果您喜欢这篇文章并想开始自己的项目,我们会为您提供一个模板项目,它使用与我们的石头、纸、剪刀项目相同的简单管道。您可以在此处找到模板。不要犹豫,通过社交媒体向我们展示您的项目。我们很想看看你能创造什么!
您可以在这里和那里找到有关 TinyML 的更多信息。Pete Warden 的书是一个很好的资源。
审核编辑 黄昊宇
-
如何在DRA821U上使用Linux实现快速引导2024-09-03 428
-
如何在AT32F系列MCU上使用FreeRTOS2023-10-24 660
-
如何在基于Cortex-M7的MCU上通过XC32编译器使用TCM2023-09-20 726
-
如何在KV260上快速体验Vitsi AI图像分类示例程序2023-09-12 4010
-
如何在FTDI FT2232H上使用快速串行模式2023-06-19 1660
-
TinyML:ESP32 CAM和TFT上的实时图像分类2023-02-08 1457
-
MCU上的TinyML变速箱故障预测开源分享2022-10-27 1051
-
利用TinyML在MCU上实现AI/ML推论工作2022-09-20 3103
-
如何在MCU上进行实际的部署2022-08-11 2742
-
什么是TinyML?微型机器学习2022-04-12 12313
-
如何在esp8266 Node MCU的硬件上部署LVGL2021-12-08 2615
-
如何在嵌入式系统或快速原型构建板上实现即交即用式部署?2021-11-22 1521
-
如何在云平台上实现应用的快速部署?2020-10-13 5644
全部0条评论

快来发表一下你的评论吧 !
