

深入剖析高性能内存回收技术
存储技术
描述
众所周知,内存是操作系统的一项重要资源,直接影响系统性能。而在应用蓬勃发展的今天,系统中运行的应用越来越多,这让内存资源变得越来越紧张。在此背景下,方舟JS运行时在内存回收方面发力,推出了高性能内存回收技术——HPP GC(High Performance Partial Garbage Collection)。本文我们将从GC的基础入手,由浅入深地为大家介绍HPP GC。
一、什么是GC?
GC(全称Garbage Collection),字面意思是垃圾回收。在计算机领域,GC就是找到内存中的垃圾,释放和回收内存空间。目前主流编程语言实现的GC算法主要分为两大类:引用计数和对象追踪(即Tracing GC)。
1. 引用计数
我们通过一个示例来了解什么是引用计数:当一个对象A被另一个对象B指向时,A引用计数+1;反之当该指向断开时,A引用计数-1。当A引用计数为0时,回收对象A。
● 优点:
引用计数算法设计简单,并且内存回收及时,在对象成为垃圾的第一时间就会被回收,所以没有单独的暂停业务代码(Stop The World,STW)阶段。
● 缺点:
在对对象操作的过程中额外插入了计数环节,增加了内存分配和内存赋值的开销,对程序性能必然会有影响。最致命的一点是存在循环引用问题。
function main() {var parent = {};var child = {};parent.child = child;child.parent = parent;}
(左右滑动,查看更多)
比如以上代码中,对象parent被另一个对象child持有,对象parent引用计数加1,同时child也被parent持有,对象child引用计数也加1,这就是循环引用。一直到main函数结束后,对象parent和child依然无法释放,导致内存泄漏。
2. 对象追踪
为了方便大家理解对象追踪算法,我们通过一个图来进行介绍:如图1所示,从根对象开始遍历对象以及对象的域,所有可达的对象打上标记(黑色),即为活对象,剩下的不可达对象(白色)即为垃圾。
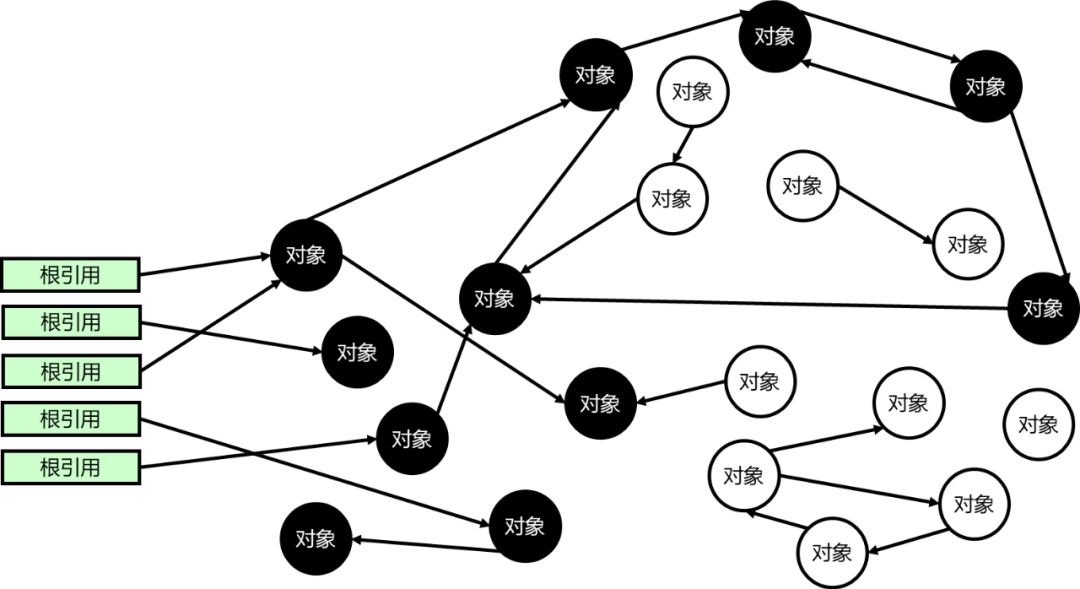
图1 对象追踪
● 优点:
对象追踪算法可以解决循环引用的问题,且对内存的分配和赋值没有额外的开销。
● 缺点:
和引用计数算法相反,对象追踪算法较为复杂,且有短暂的STW阶段。此外,回收会有延迟,导致比较多的浮动垃圾。
引用计数和对象追踪算法各有优劣,但考虑到引用计数存在循环引用的致命性能问题,方舟JS运行时选择基于对象追踪(即Tracing GC)算法来设计自己的GC算法。
二、Tracing GC介绍
在介绍HPP GC之前,我们先来了解一下Tracing GC。从前面的介绍可知,Tracing GC算法通过遍历对象图标记出垃圾。而根据垃圾回收方式的不同,Tracing GC可以分为三种基本类型:标记-清扫回收、标记-复制回收、标记-整理回收。
1. 标记-清扫回收
此算法的回收方式是:完成对象图遍历后,将不可达对象内容擦除,并放入一个空闲队列,用于下次对象的再分配。该种回收方式不需要搬移对象,所以回收效率非常高。但由于回收的对象内存地址不一定连续,所以该回收方式最大的缺点是会导致内存空间碎片化,降低内存分配效率,极端情况下甚至会出现还有大量内存的情况下分配不出一个比较大的对象的情况。

图2 标记-清扫回收
(注:灰色块表示可达对象的内存空间,白色块表示不可达对象的内存空间。)
2. 标记-复制回收
此算法的回收方式是:在对象图的遍历过程中,将找到的可达对象直接复制到一个全新的内存空间中。遍历完成后,一次将旧的内存空间全部回收。显然,这种方式可以解决内存碎片的问题,且通过一次遍历便完成整个GC过程,效率较高。但同时在极端情况下,这种回收方式需要预留一半的内存空间,以确保所有活的对象能被拷贝,空间利用率较低。
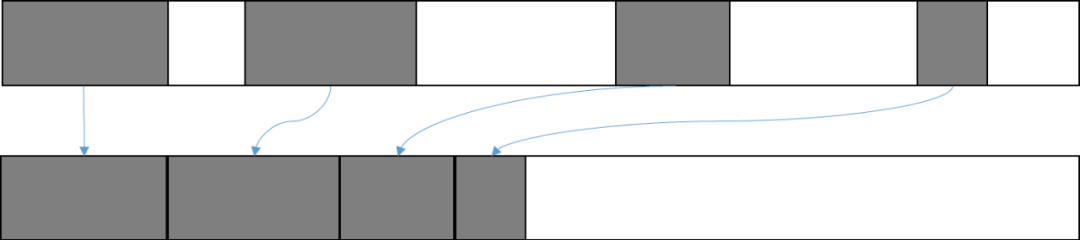
图3 标记-复制回收
3. 标记-整理回收
此算法的回收方式是:完成对象图遍历后,将可达对象(红色)往本区域(或指定区域)的头部空闲位置复制,然后将已经完成复制的对象回收整理到空闲队列中。这种回收方式既解决了“标记-清扫回收”引入的大量内存空间碎片的问题,又不需要像“标记-复制回收”那样浪费一半的内存空间,但是性能上开销比“标记-复制回收”稍大一些。
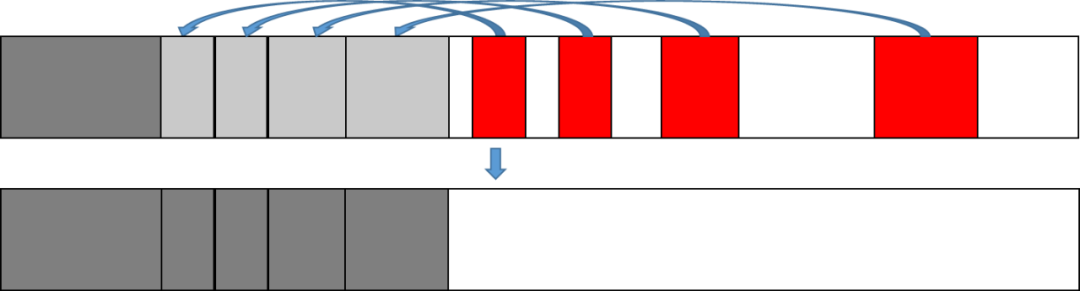
图4 标记-整理回收
综上所述,Tracing GC的三种基本类型各有优缺点,那么方舟JS运行时的HPP GC是基于哪种类型实现的呢?
HPP GC同时实现了这三种Tracing GC算法!没想到吧?HPP GC综合了这三种算法的优点,且支持根据不同对象区域、采取不同的回收方式。下面就为大家详细解析HPP GC。
三、HPP GC详解
前面我们提到了,HPP GC支持根据不同对象区域,采取不同的回收方式。这是基于分代模型和混合算法来实现的。另外,为了实现HPP GC(High Performance Partial Garbage Collection)中的“High Performance”(高性能),HPP GC对GC流程做了大量优化。所以下面我们就从分代模型、混合算法和GC流程优化三个方面来为大家介绍HPP GC。
1. 分代模型
方舟JS运行时采用传统的分代模型,将对象进行分类。考虑到大多数新分配的对象都会在一次GC之后被回收,而大多数经过多次GC之后依然存活的对象会继续存活,方舟JS运行时将对象划分为年轻代对象和老年代对象,并将对象分配到不同的空间。如图5所示,方舟JS运行时将新分配的对象直接分配到年轻代(Young Generation)的From空间。经过一次GC后依然存活的对象,会进入To空间。而经过再次GC后依然存活的对象,会被复制到老年代(Old Generation)。
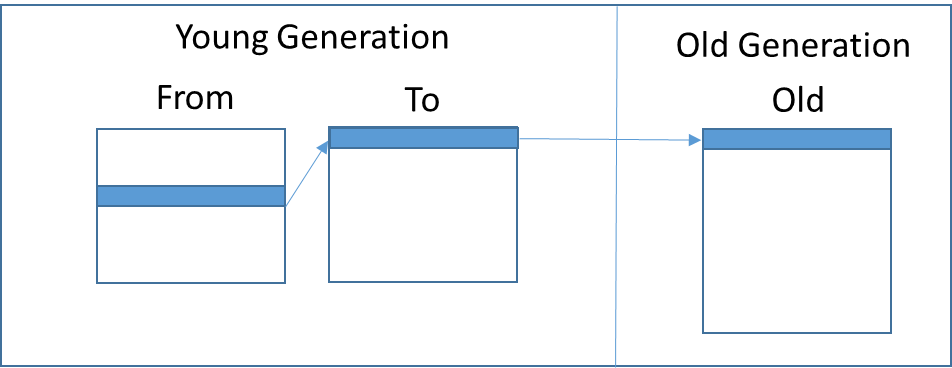
图5 分代模型
2. 混合算法
通过前面的介绍,我们已经知道:HPP GC同时实现了“标记-清扫回收”、“标记-复制回收”和“标记-整理回收”这三种Tracing GC算法。也就是说,HPP GC是一种“部分复制+部分整理+部分清扫”的混合算法,支持根据年轻代对象和老年代对象的不同特点,分别采取不同的回收方式。(1) 部分复制
考虑到年轻代对象生命周期较短,回收较为频繁,且年轻代对象大小有限的特点,方舟JS运行时对年轻代对象采用“标记-复制回收”算法。(2) 部分整理+部分清扫
方舟JS运行时根据老年代对象的特点,引入启发式Collection Set(简称CSet)选择算法。此选择算法的基本原理是:在标记阶段对每个区域的存活对象进行大小统计,然后在回收阶段优先选出存活对象少、回收代价小的区域进行对象整理回收,再对剩下的区域进行清扫回收。具体的回收策略如下:
(a) 根据设定的区域存活对象大小阈值,将满足条件的区域纳入初步的CSet队列,并根据存活率进行从低到高的排序。
(注:存活率=存活对象大小/区域大小)
(b) 根据设定的释放区域个数阈值,选出最终的CSet队列,进行整理回收。
(c) 对未被选入CSet队列的区域进行清扫回收。
由上可知,启发式CSet选择算法同时兼顾了 “标记-整理回收”和“标记-清扫回收”这两种算法的优点,既避免了内存碎片问题,也兼顾了性能。
3. GC流程优化
在内存回收时,虽然释放和回收了内存空间,让系统有了更多可用的内存资源,但内存回收过程本身需要暂停应用业务代码执行,影响用户使用应用的体验。回收内存时,如何尽可能的减小对应用性能的影响呢?为此,我们在HPP GC流程中引入了大量的并发和并行优化,以减少对应用性能的影响。如图6所示,HPP GC流程中采用了并发+并行标记(Marking)、并发+并行清扫(Sweep)、并行复制/整理(Evacuation)、并行回改(Update)和并发清理(Clear)。
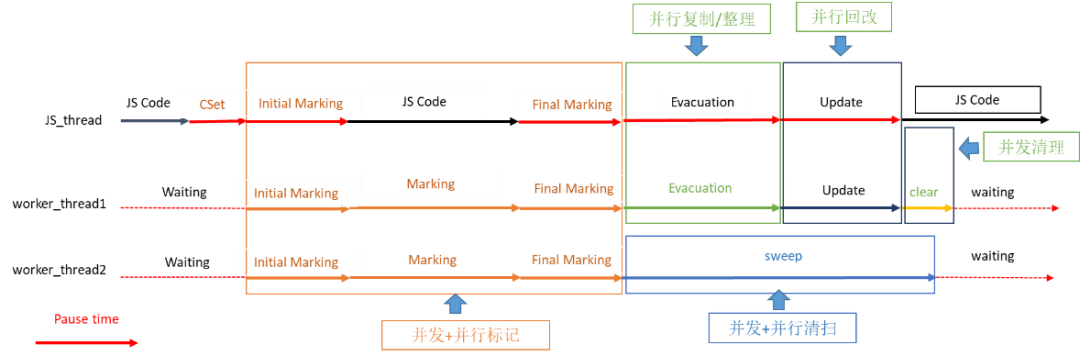
图6 HPP GC流程
(1) 并发+并行标记
在JS线程执行业务代码的同时,另外启动线程执行标记,即为“并发标记”。如果另外启动多个线程执行标记,即为“并发+并行标记”。 在并发+并行标记过程中,为确保标记的正确性和高性能,HPP GC采取了两项优化措施:措施一:在新增引用关系时增加标记屏障(Marking Barrier),以确保标记结果的正确性。
并发标记过程中,JS线程有可能会更改对象之间的引用关系,从而导致对象标记结果出错。如图7所示,在marking线程完成对象1的标记、准备标记对象2的过程中,JS线程更改了对象3的引用关系。那么marking线程完成对象2的标记后,对象3不会被标记,回收器会判定对象3为垃圾,进行回收。此后,如果JS线程读取对象1的字段,将会发生不可预知的错误。
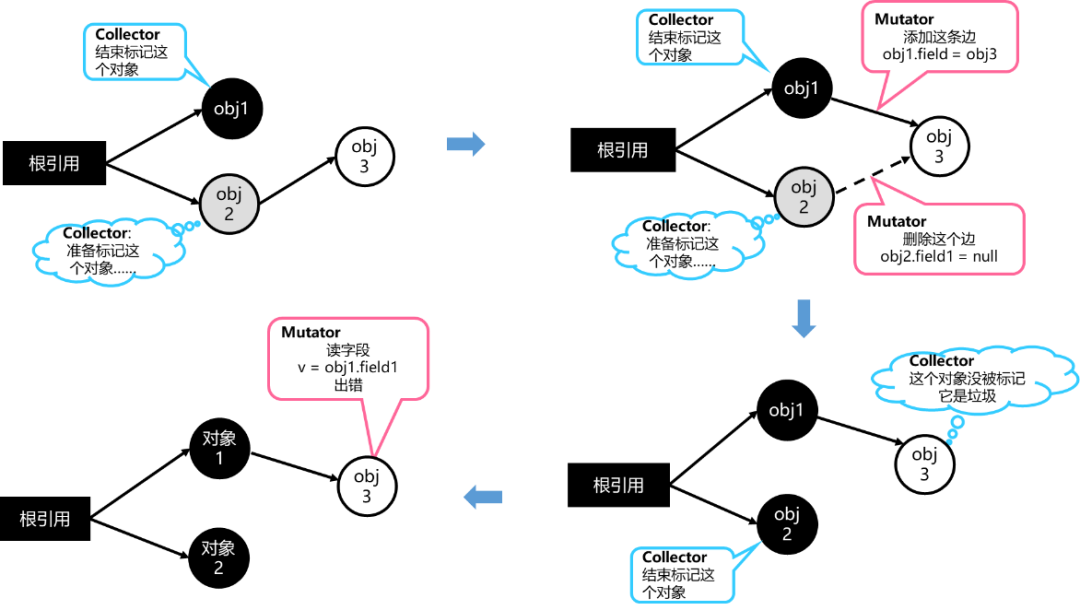
图7 对象标记出错
为确保标记结果的正确性,HPP GC在新增引用关系时增加标记屏障。如图8所示,在marking线程完成对象1的标记、准备标记对象2的过程中,JS线程更改了对象3的引用关系。此时,JS线程会将对象3加入等待标记队列,等marking线程完成对象2的标记后,继续对象3的标记,从而确保对象3不会被回收。
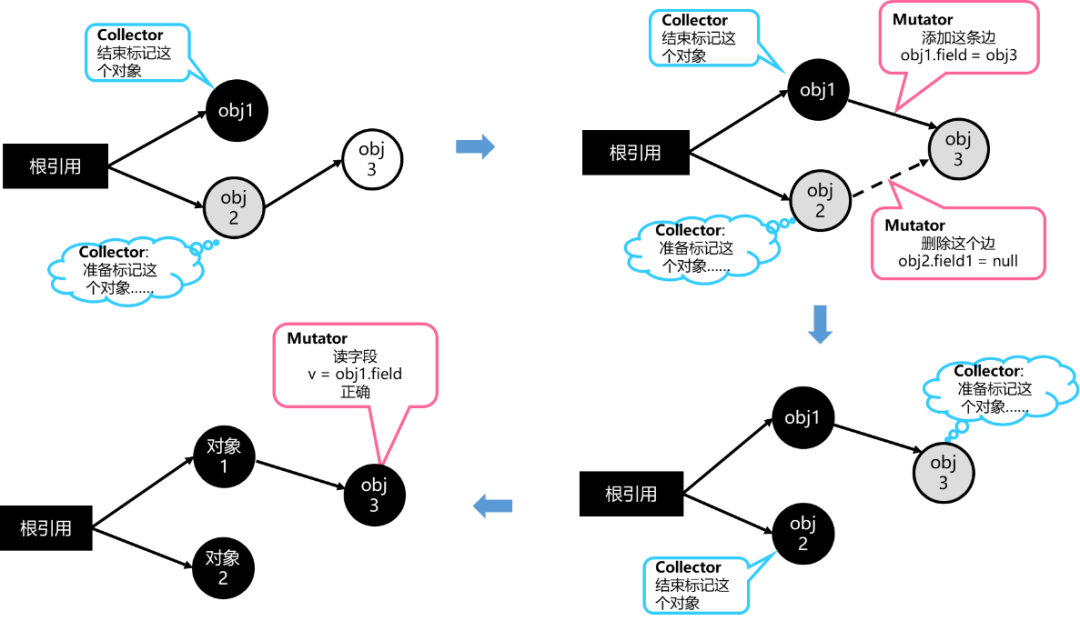
图8 增加标记屏障
措施二:在共享全局工作队列的基础上,增加了本地工作队列(Local Work List),以提高读取对象的性能。
如图9所示,并行标记时,每个Marking线程都要执行以下操作:从全局工作队列(Global Work List)获取一个对象,然后设置标记位,最后遍历该对象的每个域,将子对象放入全局工作队列中。考虑到线程之间读取数据安全,必须在每个对象的Push/Pop操作时增加原子化或者锁,这对对象的读取性能有较大的影响。
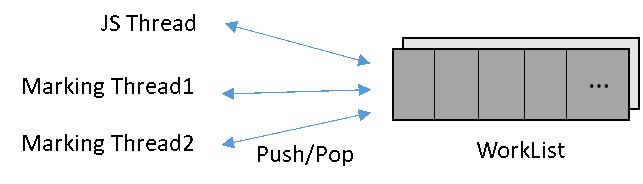
图9 全局工作队列
为提高读取对象的性能,HPP GC增加了本地工作队列。每个线程持有一个独立的本地工作队列,优先从本地工作队列获取/放入对象。当本地工作队列满时,将本地工作队列的部分队列一次发布到全局工作队列中;当本地工作队列空时,一次从全局工作队列获取若干对象到本地工作队列。这样,只有从全局工作队列发布/获取对象那一次需要增加原子化或者锁,兼顾了多线程的并发效率和任务均衡,大大提高了并发标记的效率。
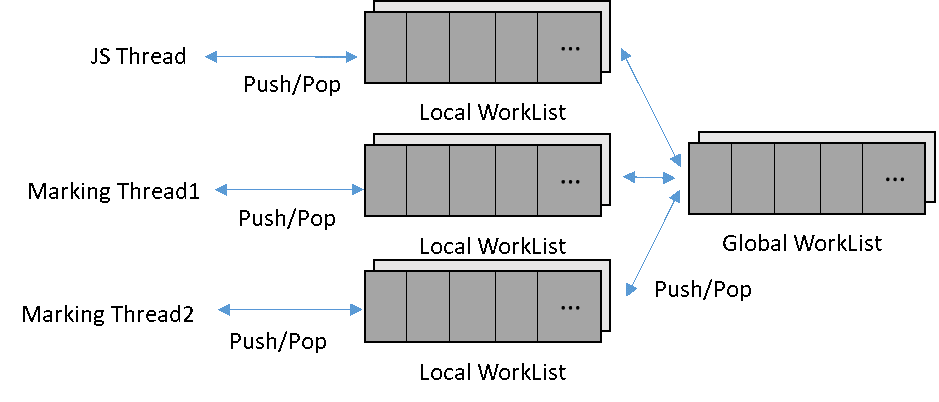
图10 增加本地工作队列
(2) 并发+并行清扫
在JS线程执行业务代码的同时,另外启动线程执行清扫,即为“并发清扫”。如果另外启动多个线程执行清扫,即为“并发+并行清扫”。在并发+并行清扫过程中,HPP GC采取增加区域空闲队列(Region Free List)的优化措施,用于提高多线程并发清扫的效率。
并发+并行清扫过程中,Sweeping线程发现不可达对象后,需要将对象放入全局的空闲队列,同时JS线程执行的业务代码可能需要从空闲队列分配对象。为了确保数据安全,这个过程需要增加原子化或者锁,但会影响到分配和清扫的效率。
为了提升效率,HPP GC增加区域空闲队列。将所有需要清扫的内存按内存地址分成若干个区域,每个区域拥有独立的空闲队列,且每个区域同时只有一个线程进行清扫。在并发清扫过程中,Sweeping线程会首先将不可达对象放入本区域的空闲队列。当JS线程需要从空闲队列分配对象时,先获取已经完成清扫的区域,再将这些区域的空闲队列发布到全局空闲队列中,用于对象分配,如图11所示。由于发布的任务由JS线程单独完成,所以整个并行清扫的过程都不需要加锁,大大提高了并发+并行清扫的效率。
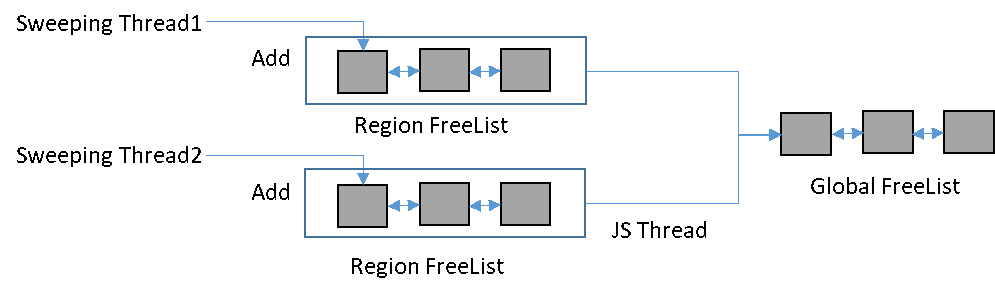
图11 增加区域空闲队列
(3) 并行复制/整理
在JS线程暂停业务代码(STW)对可达对象进行复制/整理时,另外启动多个线程一起进行复制/整理,即为“并行复制/整理”。和并发+并行清扫相似,并行复制/整理的瓶颈点在于多个线程同时从全局空闲队列/全局线性分配器分配对象时,需要增加原子化或者锁。为了提高多线程分配性能,在并行复制/整理过程中引入了TLAB Allocator。TLAB英文全称为Thread Local Allocation Buffer。顾名思义,TLAB Allocator就是每个线程拥有一个独立的本地分配器,该分配器会从全局内存分配器一次分配一块较大的内存,然后在线程内部再分配。这样只需从全局分配器分配时保证多线程安全,即可完成高性能且安全的并行复制/整理功能。(4) 并行回改
在GC完成标记和复制/整理后,需要将可达对象中指向旧对象地址的域改成新对象地址,这个过程就是“地址回改”,如图12所示。为了提升地址回改的效率,HPP GC引入了“并行回改”,同时启动多个线程进行地址回改,每个线程负责其中一块内存区域对象地址的回改。
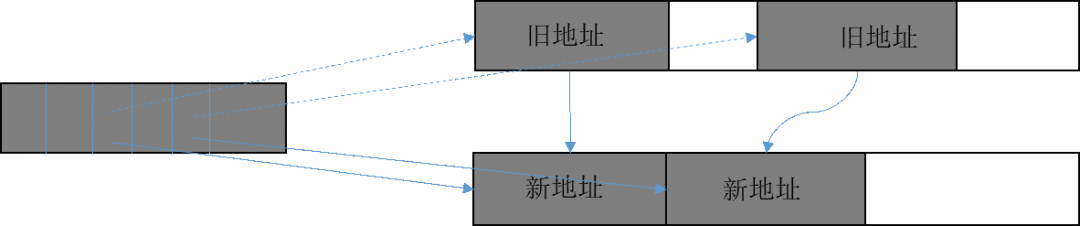
图12 地址回改
(5) 并发清理
在GC复制/整理结束后,JS线程将不再读写遍历出来的不可达对象和已经完成复制的可达对象,因此需要清理和回收对应的物理内存。为了减少STW时间,HPP GC引入“并发清理”,另外启动一个工作线程进行并发的物理内存回收,这样JS线程就可以继续执行业务代码。四、结束语
本期就为大家介绍到这里了,最后我们总结一下:● HPP GC基于分代模型将对象分为年轻代和老年代对象。
● HPP GC基于Tracing GC的三种基本类型,实现了“部分复制+部分整理+部分清扫”的混合算法,从而实现根据不同对象区域、采取不同的回收方式。
● HPP GC通过在GC流程中引入了大量的并发和并行优化,实现高性能。
HPP GC仍有很大的探索空间,我们还将继续努力,为大家提供更高性能的内存回收能力!
-
2GB/4GB 244-Pin DDR2 VLP Mini-RDIMM:高性能内存模块的技术剖析2026-06-06 238
-
探索ADVANTECH AQD - SD3L4GN16 - SG:高性能DDR3内存模块的技术剖析2026-05-13 412
-
探索ADVANTECH AQD-D3L4GR16-SG:高性能DDR3L内存模块的技术剖析2026-05-12 228
-
深入剖析AD1938:高性能音频编解码器的技术奥秘2026-04-18 323
-
深入剖析UC3D:高性能32位AVR®微控制器的技术魅力2026-04-06 1348
-
深入剖析LM4549B:高性能音频编解码器的技术指南2026-02-03 571
-
深入解析AFE7953:高性能多通道收发器的技术剖析与应用前景2026-01-26 649
-
深入剖析CC1354R10:高性能多频段无线MCU的卓越之选2025-12-22 1134
-
AMD UltraScale架构:高性能FPGA与SoC的技术剖析2025-12-15 907
-
解密方舟的高性能内存回收技术——HPP GC2022-07-20 3119
-
分享高性能Android应用开发超清版PDF2018-08-13 7337
-
最深入最经典的电容剖析2012-08-02 13260
全部0条评论

快来发表一下你的评论吧 !
