

单个CNN就能够在多个数据集上实现SOTA
描述
在 VGG、U-Net、TCN 网络中... CNN 虽然功能强大,但必须针对特定问题、数据类型、长度和分辨率进行定制,才能发挥其作用。我们不禁会问,可以设计出一个在所有这些网络中都运行良好的单一 CNN 吗? 本文中,来自阿姆斯特丹自由大学、阿姆斯特丹大学、斯坦福大学的研究者提出了 CCNN,单个 CNN 就能够在多个数据集(例如 LRA)上实现 SOTA !

- 论文地址:https://arxiv.org/pdf/2206.03398.pdf
- 代码地址:https://github.com/david-knigge/ccnn
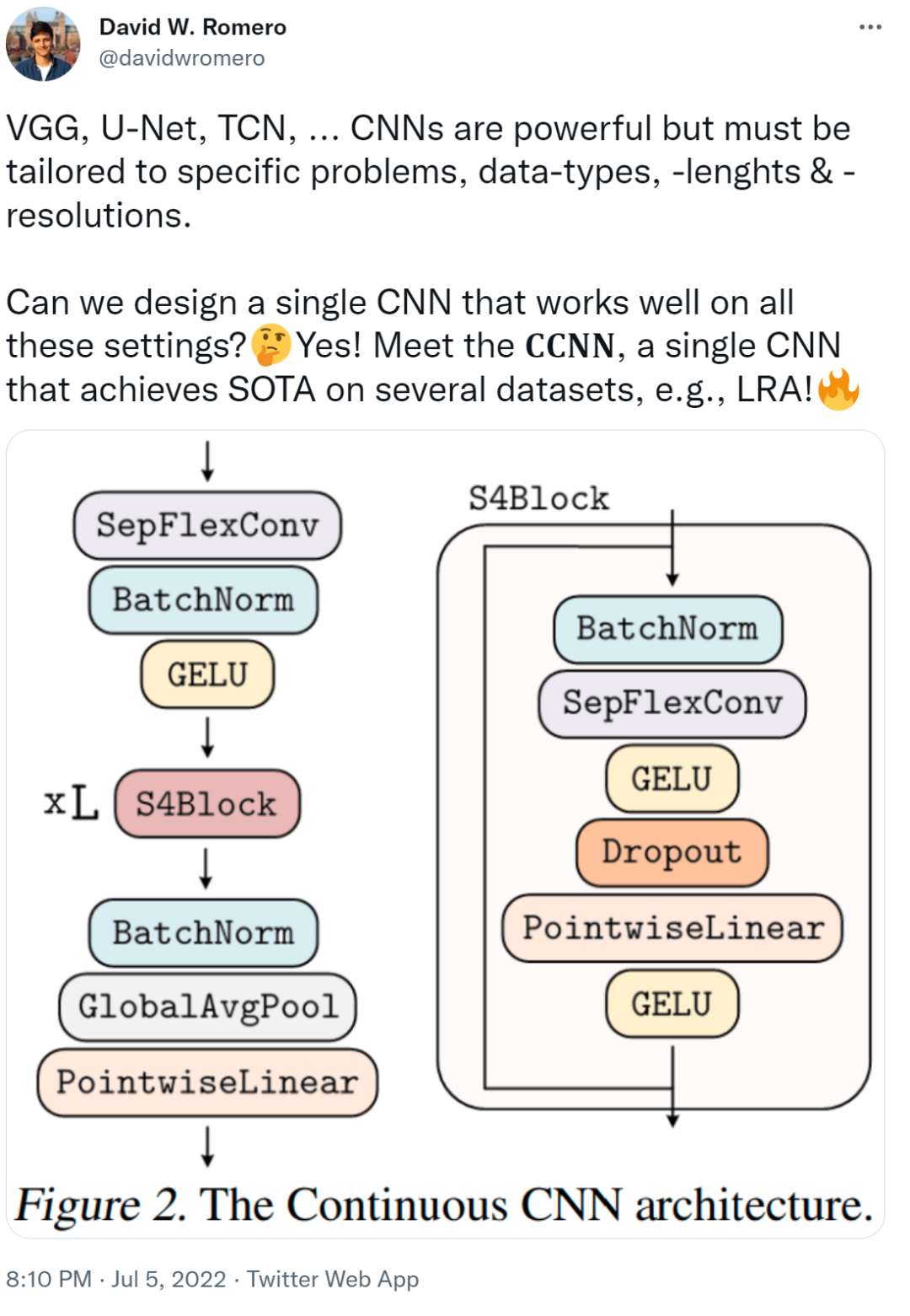
- 该研究提出 Continuous CNN(CCNN):一个简单、通用的 CNN,可以跨数据分辨率和维度使用,而不需要结构修改。CCNN 在序列 (1D)、视觉 (2D) 任务、以及不规则采样数据和测试时间分辨率变化的任务上超过 SOTA;
- 该研究对现有的 CCNN 方法提供了几种改进,使它们能够匹配当前 SOTA 方法,例如 S4。主要改进包括核生成器网络的初始化、卷积层修改以及 CNN 的整体结构。
 作为核生成器网络,同时将卷积核参数化为连续函数。该网络将坐标
作为核生成器网络,同时将卷积核参数化为连续函数。该网络将坐标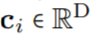 映射到该位置的卷积核值:
映射到该位置的卷积核值: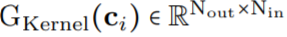 (图 1a)。通过将 K 个坐标
(图 1a)。通过将 K 个坐标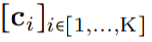 的向量通过 G_Kernel,可以构造一个大小相等的卷积核 K,即
的向量通过 G_Kernel,可以构造一个大小相等的卷积核 K,即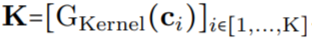 。随后,在输入信号
。随后,在输入信号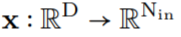 和生成的卷积核
和生成的卷积核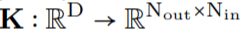 之间进行卷积运算,以构造输出特征表示
之间进行卷积运算,以构造输出特征表示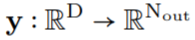 ,即
,即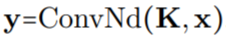 。
。
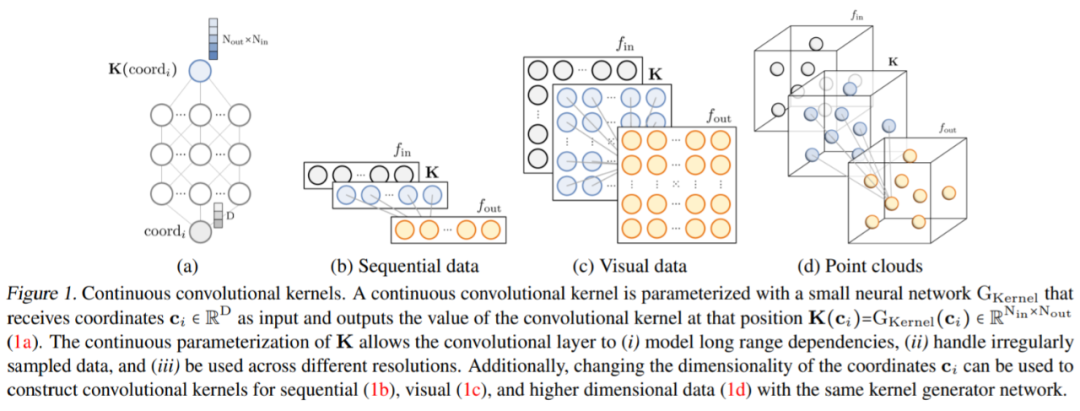
任意数据维度的一般操作。通过改变输入坐标 c_i 的维数 D,核生成器网络 G_Kernel 可用于构造任意维数的卷积核。因此可以使用相同的操作来处理序列 D=1、视觉 D=2 和更高维数据 D≥3。 不同输入分辨率的等效响应。如果输入信号 x 有分辨率变化,例如最初在 8KHz 观察到的音频现在在 16KHz 观察到,则与离散卷积核进行卷积以产生不同的响应,因为核将在每个分辨率下覆盖不同的输入子集。另一方面,连续核是分辨率无关的,因此无论输入的分辨率如何,它都能够识别输入。 当以不同的分辨率(例如更高的分辨率)呈现输入时,通过核生成器网络传递更精细的坐标网格就足够了,以便以相应的分辨率构造相同的核。对于以分辨率 r (1) 和 r (2) 采样的信号 x 和连续卷积核 K,两种分辨率下的卷积大约等于与分辨率变化成比例的因子:
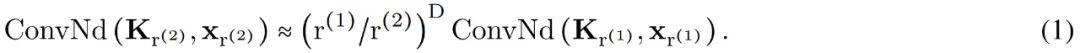
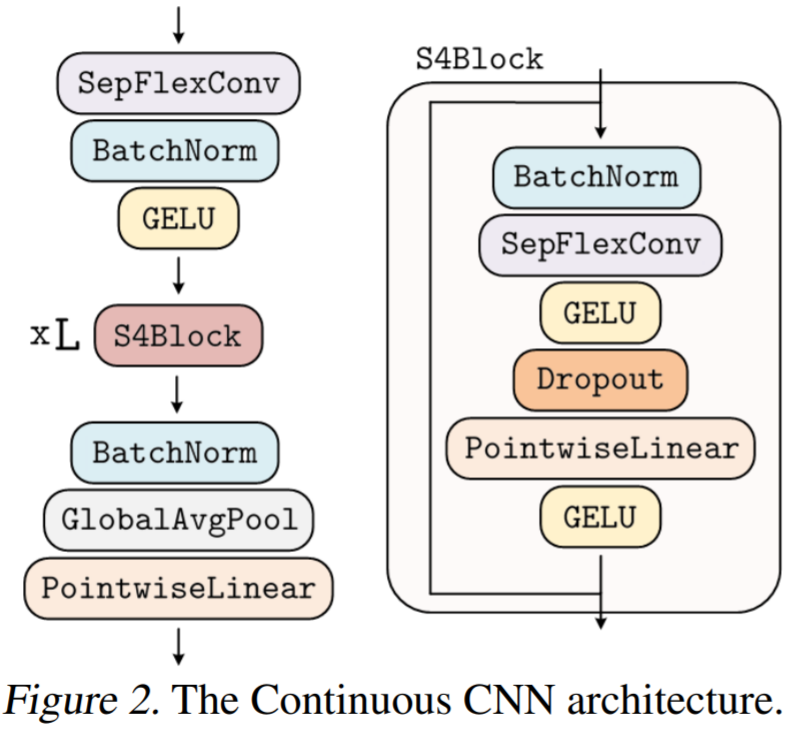
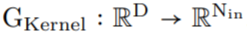 生成的核计算的,之后是从 N_in 到 N_out 进行逐点卷积。这种变化允许构建更广泛的 CCNN—— 从 30 到 110 个隐藏通道,而不会增加网络参数或计算复杂度。
生成的核计算的,之后是从 N_in 到 N_out 进行逐点卷积。这种变化允许构建更广泛的 CCNN—— 从 30 到 110 个隐藏通道,而不会增加网络参数或计算复杂度。正确初始化核生成器网络 G_Kernel。该研究观察到,在以前的研究中核生成器网络没有正确初始化。在初始化前,人们希望卷积层的输入和输出的方差保持相等,以避免梯度爆炸和消失,即 Var (x)=Var (y)。因此,卷积核被初始化为具有方差 Var (K)=gain^2 /(in channels ⋅ kernel size) 的形式,其增益取决于所使用的非线性。 然而,神经网络的初始化使输入的 unitary 方差保留在输出。因此,当用作核生成器网络时,标准初始化方法导致核具有 unitary 方差,即 Var (K)=1。结果,使用神经网络作为核生成器网络的 CNN 经历了与通道⋅内核大小成比例的特征表示方差的逐层增长。例如,研究者观察到 CKCNNs 和 FlexNets 在初始化时的 logits 大约为 1e^19。这是不可取的,这可能导致训练不稳定和需要低学习率。 为了解决这个问题,该研究要求 G_Kernel 输出方差等于 gain^2 /(in_channels⋅kernel_size)而不是 1。他们通过、
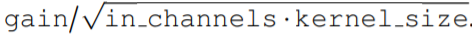 重新加权核生成器网络的最后一层。因此,核生成器网络输出的方差遵循传统卷积核的初始化,而 CCNN 的 logits 在初始化时呈现单一方差。
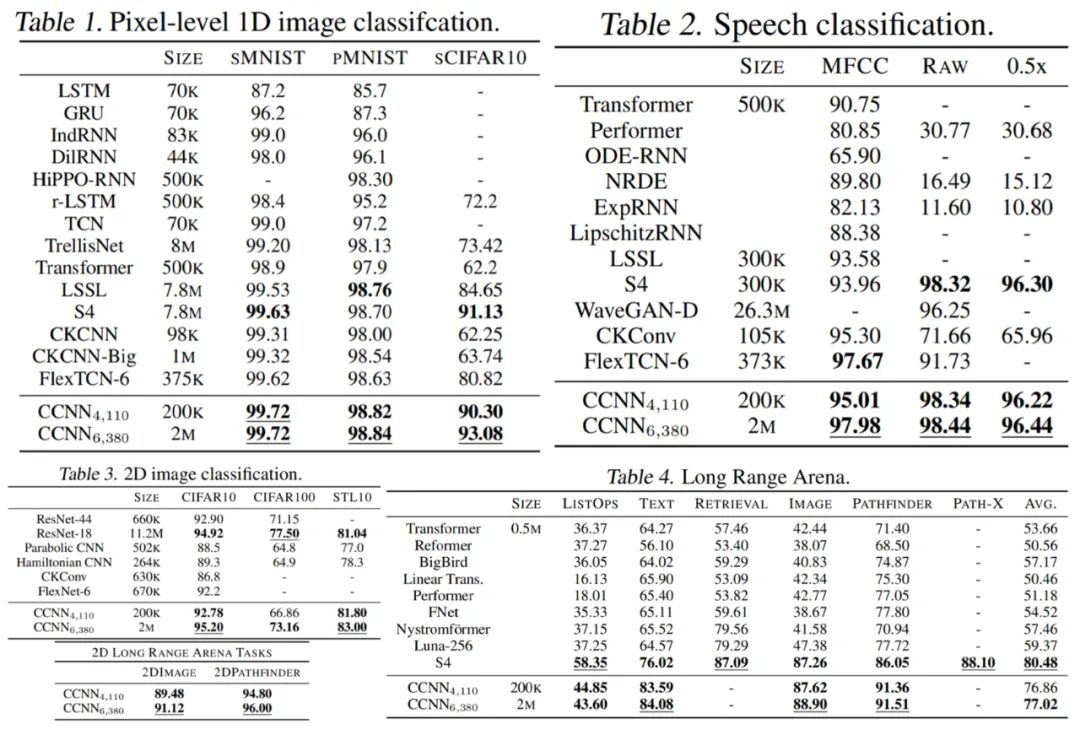
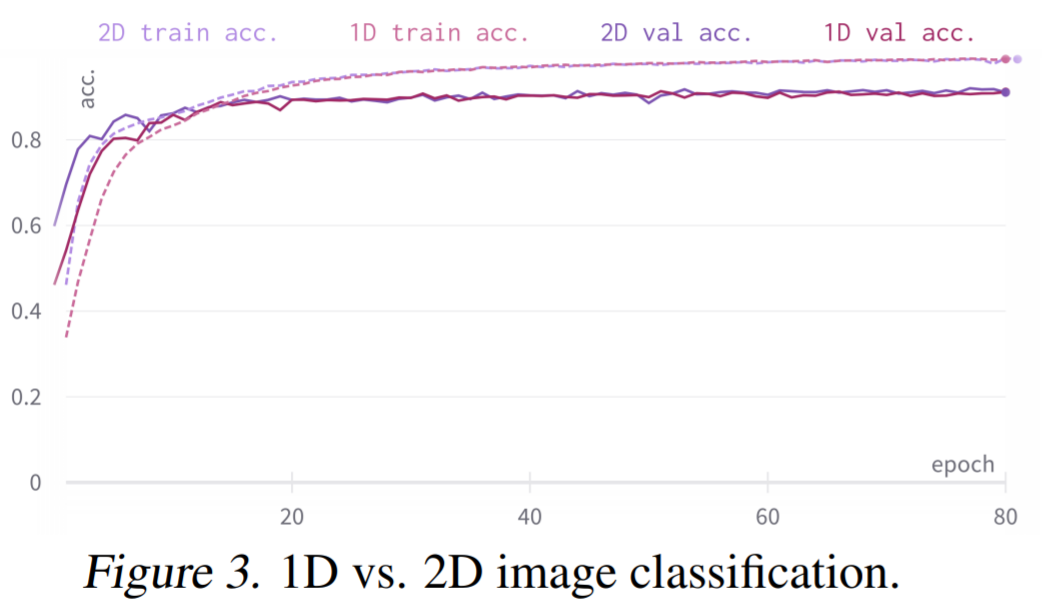
重新加权核生成器网络的最后一层。因此,核生成器网络输出的方差遵循传统卷积核的初始化,而 CCNN 的 logits 在初始化时呈现单一方差。实验结果 如下表 1-4 所示,CCNN 模型在所有任务中都表现良好。 首先是 1D 图像分类 CCNN 在多个连续基准上获得 SOTA,例如 Long Range Arena、语音识别、1D 图像分类,所有这些都在单一架构中实现的。CCNN 通常比其他方法模型更小架构更简单。 然后是 2D 图像分类:通过单一架构,CCNN 可以匹配并超越更深的 CNN。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
CNN在多个领域中的应用2024-07-08 3995
-
什么是SIMT和SIMD?SIMT和SMID在硬件实现上主要的区别有哪些2023-12-07 6007
-
python如何输入多个数据2023-11-23 6913
-
人工智能SOTA什么意思2023-08-22 27345
-
C语言的函数如何返回多个数据2023-07-25 1548
-
华为诺亚提出新型Prompting (PHP),GPT-4拿下最难数学推理数据集新SOTA2023-05-15 2023
-
介绍单个数据项的读取事务的过程2023-05-11 1414
-
为什么传统CNN在纹理分类数据集上的效果不好?2022-09-23 1575
-
SOTA的定义是什么?常规的实现方式有哪些2022-02-14 1444
-
Vector实现在单个ECU硬件上运行多个不同配置ECU系统2022-01-05 3540
-
通过引入实例 scale-uniform 采样策略与 crop-aware 边框回归损失实现 SOTA 性能2021-02-15 2297
-
TF之CNN:CNN实现mnist数据集预测2018-12-19 3132
-
能在单个安装上在PNAX上安装多个CalPods吗2018-11-16 1218
-
利用ADO实现对多个数据库的访问2009-09-10 686
全部0条评论

快来发表一下你的评论吧 !
