

一文解析人工智能之CV领域内的无监督学习
人工智能
描述
导读
本文主要介绍了CV领域内的无监督学习,内容主要包括Moco、Simclr、BYOL、SimSiam、SwAV、MAE、IPT,详细介绍了这些经典工作的亮点,并附有自己实际工作中复现的心得体会,希望能够帮助大家更深刻的了解无监督学习
前言
由于工作原因搞了相当一段时间的无监督学习,包括cv单模态的无监督,以及多模态的无监督学习,这里将自己重点关注的论文介绍一下,并且会附上自己在实验过程中的一点心得体会。这篇文章主要介绍图像(CV)领域内的无监督学习。
无监督学习的概念其实很早就有了,从最初的auto-encoder,到对图像进行不同的预处理然后进行预测的无监督学习(比如旋转后预测旋转角度、mask一部分进行复原),以及到如今对比学习(simclr、moco)、特征重构(byol,simsiam)、像素重构MAE、甚至low-level的无监督预训练(IPT),可以说图像的无监督学习获得了长足的发展,而且无监督的效果已经在逐步逼近有监督的效果。
当然,截止到目前我仍然不认为无监督学习的效果能打败有监督学习,但是在大量没有标注的数据上进行无监督训练,然后再在自己的特定任务上的少量标注数据上进行finetune,那效果确实是会好很多的,但是如果是大量的无监督训练的数据也是有标注的情况,那么效果肯定不如直接有监督训练,而且经过自己的实验,即便是先无监督再有监督、有监督无监督一起训练也不会有太大收益,所以说目前为止还是数据为王。
但是目前无论是单模态(CV、NLP)还是多模态下,都会有超大规模的预训练数据甚至能到亿级别,在这种数据量下预训练出来的模型当然会很好,但是收集整理如此量数据以及在亿级别训练数据上进行训练都是极其消耗资源的,一般的研究员都是load开源的模型参数再进一步pretrain或者finetune。
对比学习
最初做无监督的想法很简单,类似auto-encoder,重构像素、或者对图像做一些变换(比如旋转)然后进行预测,但是如此做并没有得到特别好的效果。自己个人感觉对比学习(simclr和moco)的出现算是无监督学习的一次质的飞跃,而且这些经典论文的一些思路以及结论,对其他工作都有借鉴意义,自己有关的实验也会一一介绍。
先简单介绍下对比学习的概念。我们的输入图像 ,经过两种不同的预处理(变换)之后可以得到两张图像 和 ,那么经过特征提取器(encoder)之后两者的特征应该是比较相近的。但是如果直接最大化两张图像特征的距离,模型很容易陷入坍塌,即特征都映射成固定特征,那么loss为0。因此对比学习引入负样本的概念,对于来自同一张图像的特征,其特征距离尽可能近,而来自不同图像的特征,其特征距离要尽可能远,用学术上的话说就是最小化正样本距离,最大化负样本距离,也就是对比学习的损失函数。
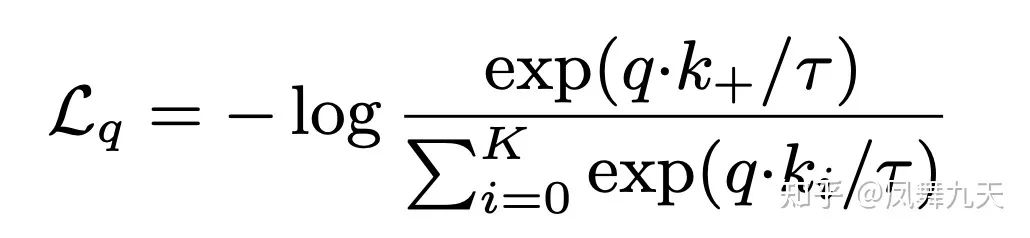
这里对损失函数简单解释下,对比学习的输入是对每一张图像进行两种不同的变换,经过特征提取之后会得到两种特征,对任意特征 来说,总会有一个特征 是其正样本(同一张原始图像的两种不同的数据增强得到的特征),而一个batch中的其他图像提取到的特征就是负样本。从原理上来说(其实是各种论文的实验结果),提高对比学习的效果就是提供足够大的batch size、研究更加有效的不同预处理方式(使得经过变换后的两张图像既能保留图像最本质的信息,又尽可能不一致)以及增加模型(encoder)表达能力。下面重点讲一下对比学习领域内Moco和Simclr两个最具代表性以及影响力的文章。
MoCo: Momentum Contrast for Unsupervised Visual Representation Learning
首先是Moco,Moco研究的重点是如何增加计算loss时的负样本数据,因为总显存是有限的。Moco设计了一种巧妙的方式,在训练的过程中维护一个队列,将历史batch 中的特征(这里的特征由于没有梯度,所以占显存很小)存入到队列中,这样一个新的batch 在计算的时候,可以在队列中找到足够多的负样本进行迭代优化。但是这样有一个问题是,不同batch提取特征时的模型参数是在一直更新的,所以作者设计了一个momentum-encoder,其结构与encoder完全相同,每次更新的时候以较小的步长从encoder中copy 参数,这样momentum-encoder参数不是通过loss 来进行学习的,所以提取的特征无需梯度,占用显存就比较小,同时momentum-encoder 参数变化很缓慢,所以队列中维护负样本特征就保证了足量且相对一致(来自同一个模型参数),以保证对比学习的效果。
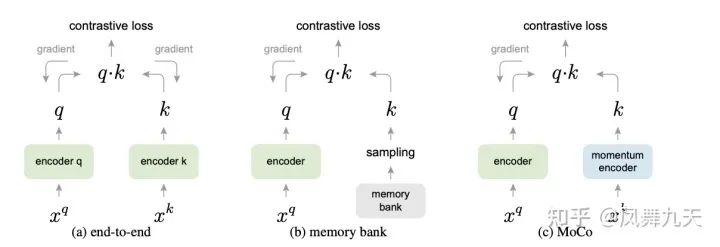
A Simple Framework for Contrastive Learning of Visual Representations
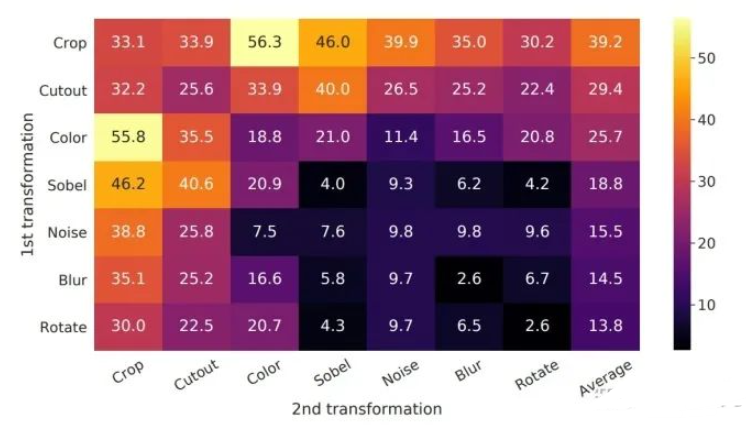
接下来介绍的就是Simclr这篇文章。Simclr可以说有钱任性,直接暴力加足够的机器以保证4096的batch size,这样一来损失函数就可以直接计算。Simclr主要研究了对图像的不同变换以及特征表达的影响,Simclr做了大量不同的尝试,最后发现在对比学习中,预处理效果最好。
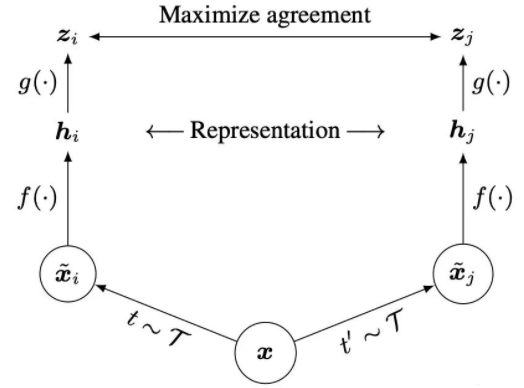
除此之外,Cimclr还在encoder之外加了mlp结构,进一步提升了效果(其实不知道这个为什么会有效)。其模型结构为:
Moco 在借鉴的Simclr的数据增强方式以及mlp结构之后形成了moco-v2,效果也有很大的提升,说明simclr本身的实验结论十分solid。
最初在看到Moco这篇文章的时候确实觉得这个思路很巧妙,而且很明显作者将其做work了,因为论文中的指标完全可复现。不过当我复现simclr的时候设计了另外一种在一定量显存的前提下模拟大batch size的实现方式,简单讲就是小batch 先不带梯度推理保存结果,再带梯度推理计算loss,但是需要重复推理,浪费了训练时间。
我们看论文的目的除了直接用论文的方法之外,还可以借鉴论文中的部分思路。比如说Simclr中的数据增强以及mlp结构,可以说是类似文章的标配了,而Moco论文利用momentum-encoder以及队列来实现在小batch size情况下得到足够量的负样本也很值得借鉴,在我训练CLIP(多模态对比学习)的时候采用的就是Moco的思路,比如ALBEF这篇文章也是用了类似的思路(当然人家还有别的优化点,所以能发表论文)。
同时自己在做目标检测的时候发现了一篇DetCo,其实就是将Moco适配到了目标检测领域,设计了多尺度的对比以及增加了局部VS全局的对比,自己实验下来,目标检测的任务下,DetCo确实比Moco好一些。在视频领域也有由Moco改进而来的VideoMoco,不过这篇文章没实验过。
最后写一些是自己应用中的一些思考。首先是在自己的业务数据上训练类似Moco或者Simclr的时候,由于对比损失函数的特点,如果数据中相似数据占比较高的话最好做一下去重;其次是在多机多卡训练的过程中,正样本都是在同一机器同一张卡上计算,但是负样本会来自不同的机器,所以当encoder 选用ResNet等CNN结构时,BN层会有一定的信息泄漏,Moco中采用的是shuffle bn,而Simclr采用的是sync bn。
特征重构
刚刚有提到,如果直接最大化两张图像特征的距离,模型很容易陷入坍塌。但是也有一些文章进行直接进行特征重构但是却能收敛(其实从原理上并不是很清楚收敛原因)。这里主要是介绍BYOL和SimSiam。
BYOL可以说是我在尝试的论文中效果最好的一个,其最显著的特点是训练的时候不需要负样本,只需要正样本就好。
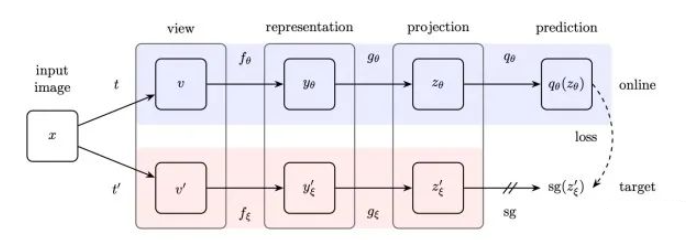
BYOL在Simclr的mlp(projection)之后额外加了新的mlp结构(predition),利用predition的结果和另一种增强方式得到的projection直接构建l2 loss。BYOL中target emcoder其实就是Moco中的momentum-encoder,其参数更新来自于online-encoder,而不是由loss计算。可以说BYOL在Moco-v2的基础上直接去掉了负样本的对比,而是在正样本projection之后再进行predition来预测图像特征。
SimSiam就更简单了,SimSiam 相当于在BYOL的基础上进一步去掉了momentum-encoder,仅用一个encoder,而且作者研究发现保证模型不坍塌的原因是target 数据的梯度不回传。
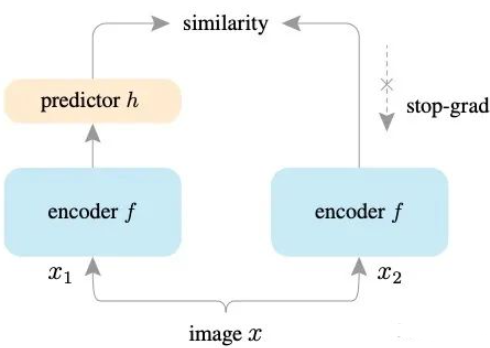
BYOL和Simsiam我自己也有有过尝试,开源的代码也并不复杂,确实能复现论文的效果,但是目前仍然不是很理解为何target 网络 stop gradient就能使得无监督训练不坍塌,对我而言仍然是有一点点玄学。
其他思路
接下来的几篇文章,是我个人觉得思路比较值得借鉴的文章,这里一并介绍下。
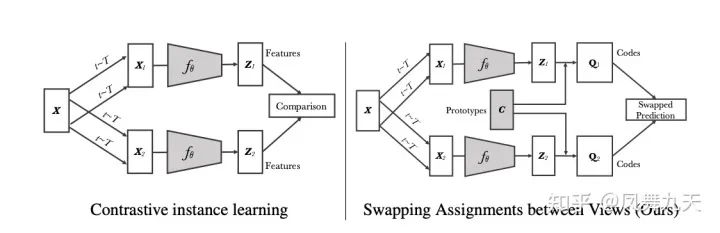
首先是SwAV这篇文章。这篇文章比较有意思的点是虽然loss采用的仍然是类似对比学习,但是其无需负样本计算loss。具体实现方式为其中一个增强结果所提的特征会进行聚类,得到一个one-hot编码,我个人理解为就是为这张图像打了一个label,然后对另一个增强结果进行分类(特征与聚类中心点乘)。还有一个值得借鉴的点是其数据增强引入了低分辨率(小size),一张图像经过数据增强之后可以得到8个不同的view,其中两个是高分辨率,其余六个是低分辨率,view1(利用distributed_sinkhorn 计算q)与其余7个view计算loss,view2(利用distributed_sinkhorn 计算q)与其余7个view计算loss。其loss 表达式和模型结构为:

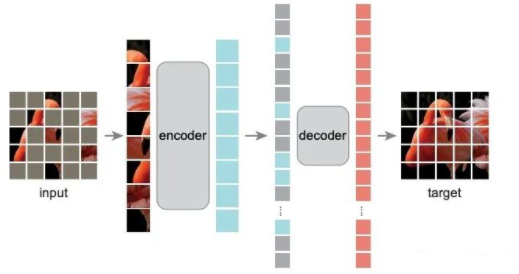
其次是MAE这篇文章,是凯明大神继Moco系列之后的又一力作,其实自从BERT、GPT在NLP领域内被成功应用之后,在图像领域也有相当一部分研究集中在对图像进行一定mask然后重建的工作上,IGPT,BEiT是其中的代表作。其实自己也跑过类似IGPT的代码,结果当然是有点惨不忍睹。凯明大神一贯作风是思路简单,效果拔群,然而能将简单的思路实现,并最终work,才真是硬实力。MAE 选用的模型是VIT结构,首先对原图进行patch划分,mask 的粒度也是在patch上完成。AutoEncoder 的结构其实比较简单,一个encoder,一个decoder,配合上VIT以及patch 划分,整体模型结构便呼之欲出。
MAE之所以能成功,个人认为有两个比较重要的关键点。
1. 75% mask 比例,与文本不同的是,一张图像信息是非常冗余的,如果类似于BERT 采用随机15%的mask比例的话,重建任务非常简单,模型很容易就从mask部分的邻域学到信息完成重建任务。
2. 非对称的encoder、decoder结构。在论文中指出,因为训练的目的是拿到比较好的encoder模型,所以encoder模型相对重一些(参数多),而轻量级(参数少)decoder已经能很好的完成重建任务,与此同时,Mask token 不参与encoder计算,仅参与decoder计算,这样一来,参数多的encoder只输入25%的图像数据,而输入100%图像数据的decoder参数又比较少,能够加速计算。
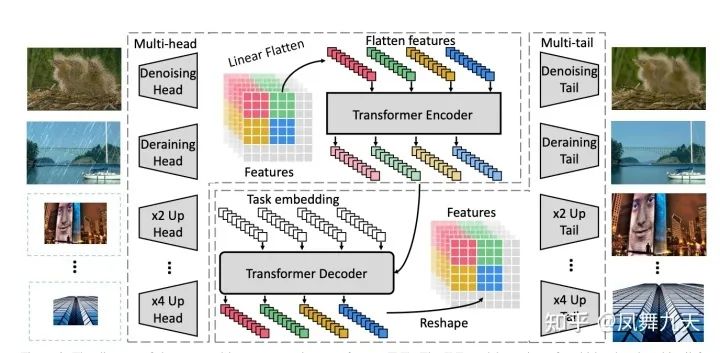
最后是IPT这篇文章。IPT与之前文章最大的不同点在于IPT模型更加关注细粒度信息,当然其负责的任务也主要是降噪、去雨、超分等low level 的任务,其模型以及任务的设计也比较巧妙,为每个任务设计独立的head和tail模块,中间层则是共享参数的transformer结构,预训练任务就是人为对原始数据加噪声、缩小等各种操作进行复原,这篇文章感觉在low level 的任务上有很好的启发意义。
总结
以上提到的大多数文章自己都有相关的实验,但是做无监督有一点点心塞的是随着自己业务上的标注数据越来越多,无监督预训练带来的收益会越来越少,所以无监督预训练在业务上应用一般是启动的时候第一版本,手中只有少量的数据,这个时候加上无监督预训练,而后随着数据回流与标注,有监督训练的效果会越来越好。同时这里介绍的这么多篇文章,自己实验下来在业务数据上效果其实并没有差很多,同时无监督预训练也需要大量的数据,而且epoch也要更长(其实也比较消耗资源),最好是先load 各家在imagenet上预训练好的开源模型。
编辑:黄飞
-
使用MATLAB进行无监督学习2025-05-16 1830
-
【阿里云大学免费精品课】机器学习入门:概念原理及常用算法2017-06-23 3627
-
如何用卷积神经网络方法去解决机器监督学习下面的分类问题?2021-06-16 3049
-
人工智能基本概念机器学习算法2021-09-06 2814
-
你想要的机器学习课程笔记在这:主要讨论监督学习和无监督学习2018-12-03 1075
-
如何用Python进行无监督学习2019-01-21 5586
-
机器学习算法中有监督和无监督学习的区别2020-07-07 6903
-
最基础的半监督学习2020-11-02 3615
-
为什么半监督学习是机器学习的未来?2020-11-27 4893
-
半监督学习:比监督学习做的更好2020-12-08 2405
-
基于人工智能的自监督学习详解2021-03-30 7239
-
机器学习中的无监督学习应用在哪些领域2022-01-20 5709
-
每日一课 | 智慧灯杆人工智能之实践方法二:机器学习2022-03-22 1756
-
人工智能的关键技术包括哪些2023-08-28 5399
-
深度学习中的无监督学习方法综述2024-07-09 3380
全部0条评论

快来发表一下你的评论吧 !
