

Linux内核之内存映射原理分析
嵌入式技术
描述
作者简介:
余华兵,2005年毕业于华中科技大学计算机学院,取得硕士学位。毕业后的十余年一直在网络通信行业从事软件设计和开发工作,研究方向包括IPv4协议栈、IPv6协议栈和Linux内核。
3.4 内存映射
内存映射是在进程的虚拟地址空间中创建一个映射,分为以下两种。
(1)文件映射:文件支持的内存映射,把文件的一个区间映射到进程的虚拟地址空间,数据源是存储设备上的文件。
(2)匿名映射:没有文件支持的内存映射,把物理内存映射到进程的虚拟地址空间,没有数据源。
通常把文件映射的物理页称为文件页,把匿名映射的物理页称为匿名页。
根据修改是否对其他进程可见和是否传递到底层文件,内存映射分为共享映射和私有映射。
(1)共享映射:修改数据时映射相同区域的其他进程可以看见,如果是文件支持的映射,修改会传递到底层文件。
(2)私有映射:第一次修改数据时会从数据源复制一个副本,然后修改副本,其他进程看不见,不影响数据源。
两个进程可以使用共享的文件映射实现共享内存。匿名映射通常是私有映射,共享的匿名映射只可能出现在父进程和子进程之间。
在进程的虚拟地址空间中,代码段和数据段是私有的文件映射,未初始化数据段、堆和栈是私有的匿名映射。
内存映射的原理如下
(1)创建内存映射的时候,在进程的用户虚拟地址空间中分配一个虚拟内存区域。
(2)Linux 内核采用延迟分配物理内存的策略,在进程第一次访问虚拟页的时候,产生缺页异常。如果是文件映射,那么分配物理页,把文件指定区间的数据读到物理页中,然后在页表中把虚拟页映射到物理页;如果是匿名映射,那么分配物理页,然后在页表中把虚拟页映射到物理页。
3.4.1 应用编程接口
内存管理子系统提供了以下常用的系统调用。
(1)mmap()用来创建内存映射。
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
(2)mremap()用来扩大或缩小已经存在的内存映射,可能同时移动。
void *mremap(void *old_address, size_t old_size, size_t new_size, int flags, ... /* void *new_address */);
(3)munmap()用来删除内存映射。
int munmap(void *addr, size_t length);
(4)brk()用来设置堆的上界。
int brk(void *addr);
(5)remap_file_pages()用来创建非线性的文件映射,即文件区间和虚拟地址空间之间的映射不是线性关系,现在被废弃了。
(6)mprotect()用来设置虚拟内存区域的访问权限。
int mprotect(void *addr, size_t len, int prot);
(7)madvise()用来向内核提出内存使用的建议,应用程序告诉内核期望怎样使用指定的虚拟内存区域,以便内核可以选择合适的预读和缓存技术。
int madvise(void *addr, size_t length, int advice);
在内核空间中可以使用以下两个函数。
(1)remap_pfn_range 把内存的物理页映射到进程的虚拟地址空间,这个函数的用处是实现进程和内核共享内存。
int remap_pfn_range(struct vm_area_struct *vma, unsigned long addr,unsigned long pfn,unsigned long size, pgprot_t prot);
(2)io_remap_pfn_range 把外设寄存器的物理地址映射到进程的虚拟地址空间,进程可以直接访问外设寄存器。
int io_remap_pfn_range(struct vm_area_struct *vma, unsigned long addr,unsigned long pfn, unsigned long size, pgprot_t prot);
应用程序通常使用 C 标准库提供的函数 malloc()申请内存。glibc 库的内存分配器 ptmalloc使用 brk 或 mmap 向内核以页为单位申请虚拟内存,然后把页划分成小内存块分配给应用程序。默认的阈值是 128KB,如果应用程序申请的内存长度小于阈值,ptmalloc 分配器使用 brk 向内核申请虚拟内存,否则 ptmalloc 分配器使用 mmap 向内核申请虚拟内存。
应用程序可以直接使用 mmap 向内核申请虚拟内存。
1.系统调用 mmap()
系统调用 mmap()有以下用处。
(1)进程创建匿名的内存映射,把内存的物理页映射到进程的虚拟地址空间。
(2)进程把文件映射到进程的虚拟地址空间,可以像访问内存一样访问文件,不需要调用系统调用read()和write()访问文件,从而避免用户模式和内核模式之间的切换,提高读写文件的速度。
(3)两个进程针对同一个文件创建共享的内存映射,实现共享内存。
函数原型:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
参数如下。
(1)addr:起始虚拟地址。如果 addr 是 0,内核选择虚拟地址。如果 addr 不是 0,内核把这个参数作为提示,在附近选择虚拟地址。
(2)length:映射的长度,单位是字节。
(3)prot:保护位。

(4)flags:标志。常用的标志如下。

(5)fd:文件描述符。仅当创建文件映射的时候,这个参数才有意义。如果是匿名映射,有些实现要求参数 fd 是−1,可移植的应用程序应该保证参数 fd 是−1。
(6)offset:偏移,单位是字节,必须是页长度的整数倍。仅当创建文件映射的时候,这个参数才有意义。
返回值:
如果成功,返回起始虚拟地址,否则返回负的错误号。
2.系统调用 mprotect()
mprotect()用来设置虚拟内存区域的访问权限。
函数原型:
int mprotect(void *addr, size_t len, int prot);
参数如下。
(1)addr:起始虚拟地址,必须是页长度的整数倍。
(2)len:虚拟内存区域的长度,单位是字节。
(3)prot:保护位。

返回值:
如果成功,返回 0,否则返回负的错误号。
3.系统调用 madvise()
madvise()用来向内核提出内存使用的建议,应用程序告诉内核期望怎样使用指定的虚拟内存区域,以便内核可以选择合适的预读和缓存技术。
函数原型:
int madvise(void *addr, size_t length, int advice);
参数如下。
(1)addr:起始虚拟地址,必须是页长度的整数倍。
(2)length:虚拟内存区域的长度,单位是字节。
(3)advice:建议。
POSIX 标准定义的建议值如下。

Linux 私有的建议值如下。

返回值:
如果成功,返回 0,否则返回负的错误号。
3.4.2 数据结构
1.虚拟内存区域
虚拟内存区域是分配给进程的一个虚拟地址范围,内核使用结构体 vm_area_struct 描述虚拟内存区域,主要成员如表 3.4 所示。
表 3.4 虚拟内存区域的主要成员
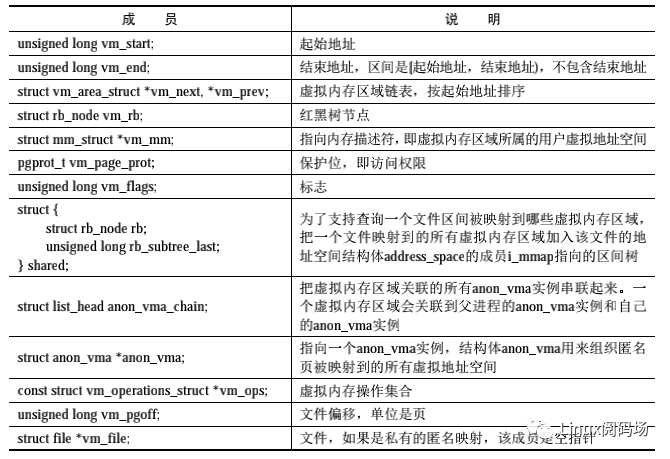
文件映射的虚拟内存区域如图 3.9 所示。
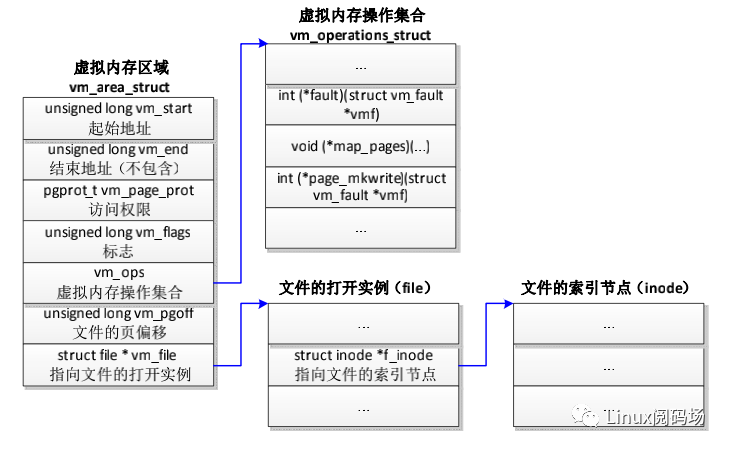
图3.9 文件映射的虚拟内存区域
(1)成员 vm_file 指向文件的一个打开实例(file)。索引节点代表一个文件,描述文件的属性。
(2)成员 vm_pgoff 存放文件的以页为单位的偏移。
(3)成员 vm_ops 指向虚拟内存操作集合,创建文件映射的时候调用文件操作集合中的 mmap 方法(file->f_op->mmap)以注册虚拟内存操作集合。例如:假设文件属于 EXT4文件系统,文件操作集合中的 mmap 方法是函数 ext4_file_mmap,该函数把虚拟内存区域的成员 vm_ops 设置为 ext4_file_vm_ops。
共享匿名映射的虚拟内存区域如图 3.10 所示,共享匿名映射的实现原理和文件映射相同,区别是共享匿名映射关联的文件是内核创建的内部文件。在内存文件系统 tmpfs 中创建一个名为“/dev/zero”的文件,名字没有意义,创建两个共享匿名映射就会创建两个名为“/dev/zero”的文件,两个文件是独立的,毫无关系。
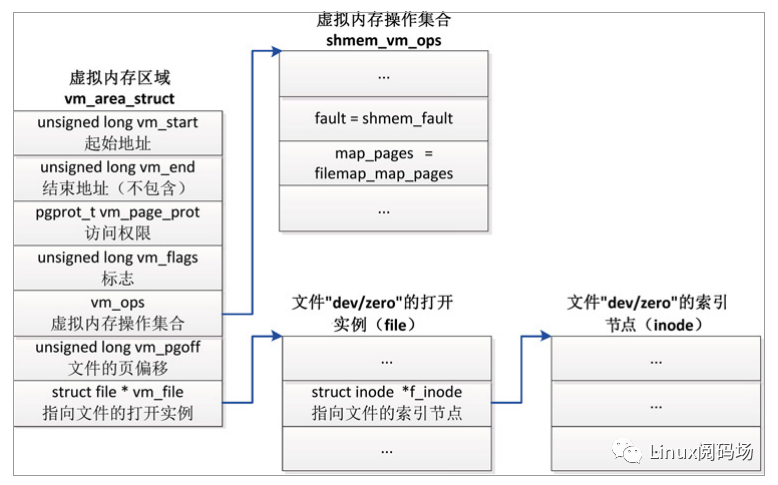
图3.10 共享匿名映射的虚拟内存区域
(1)成员 vm_file 指向文件的一个打开实例(file)。
(2)成员 vm_pgoff 存放文件的以页为单位的偏移。
(3)成员 vm_ops 指向共享内存的虚拟内存操作集合 shmem_vm_ops。
私有匿名映射的虚拟内存区域如图 3.11 所示。

图3.10 私有匿名映射的虚拟内存区域
成员 vm_file 没有意义,是空指针。
成员 vm_pgoff 没有意义。
成员 vm_ops 是空指针。
(1)页保护位(vm_area_struct.vm_page_prot):描述虚拟内存区域的访问权限。内核定义了一个保护位映射数组,把 VM_READ、VM_WRITE、VM_EXEC 和VM_SHARED 这 4 个标志转换成保护位组合。
每种处理器架构需要定义__P000 到__S111 的宏,P 代表私有(Private),S 代表共享(Shared),后面的 3 个数字分别表示可读、可写和可执行,例如__P000 表示私有、不可读、不可写和不可执行,__S111 表示共享、可读、可写和可执行。
mm/mmap.c pgprot_t protection_map[16] = { __P000, __P001, __P010, __P011, __P100, __P101, __P110, __P111, __S000, __S001, __S010, __S011, __S100, __S101, __S110, __S111 };
pgprot_t vm_get_page_prot(unsigned long vm_flags) { return __pgprot(pgprot_val(protection_map[vm_flags & (VM_READ|VM_WRITE|VM_EXEC|VM_SHARED)]) | pgprot_val(arch_vm_get_page_prot(vm_flags))); }
函数 arch_vm_get_page_prot 由每种处理器架构自定义,默认的实现如下:
include/linux/mman.h
include/linux/mman.h #ifndef arch_vm_get_page_prot #define arch_vm_get_page_prot(vm_flags) __pgprot(0) #endif
(2)虚拟内存区域标志:结构体 vm_area_struct 的成员 vm_flags 存放虚拟内存区域的标志,头文件“include/linux/mm.h”定义了各种标志,常用的标志如下。
1)VM_READ、VM_WRITE、VM_EXEC 和 VM_SHARED 分别表示可读、可写、可执行和可以被多个进程共享。
2)VM_MAYREAD 表示允许设置 VM_READ,VM_MAYWRITE 表示允许设置VM_WRITE,VM_MAYEXEC 表示允许设置 VM_EXEC,VM_MAYSHARE 表示允许设置VM_SHARED。这 4 个标志用来限制系统调用 mprotect 可以设置的访问权限。
3)VM_GROWSDOWN 表示虚拟内存区域可以向下(低的虚拟地址)扩展,VM_GROWSUP 表示虚拟内存区域可以向上(高的虚拟地址)扩展。VM_STACK 表示虚拟内存区域是栈,绝大多数处理器的栈是向下扩展,VM_STACK 等价于 VM_GROWSDOWN;少数处理器(例如 PA-RISC 处理器)的栈是向上扩展,VM_STACK 等价于 VM_GROWSUP。
4)VM_PFNMAP 表示页帧号(Page Frame Number,PFN)映射,特殊映射不希望关联页描述符,直接使用页帧号,可能是因为页描述符不存在,也可能是因为不想使用页描述符。
5)VM_MIXEDMAP 表示映射混合使用页帧号和页描述符。
6)VM_LOCKED 表示页被锁定在内存中,不允许换出到交换区。
7)VM_SEQ_READ 表示进程从头到尾按顺序读一个文件,VM_RAND_READ 表示进程随机读一个文件。这两个标志用来提示文件系统,如果进程按顺序读一个文件,文件系统可以预读文件,提高性能。
8)VM_DONTCOPY 表示调用 fork 以创建子进程时不把虚拟内存区域复制给子进程。
9)VM_DONTEXPAND 表示不允许使用 mremap()扩大虚拟内存区域。
10)VM_ACCOUNT 表示虚拟内存区域需要记账,判断所有进程申请的虚拟内存的总和是否超过物理内存容量。
11)VM_NORESERVE 表示不需要预留物理内存。
12)VM_HUGETLB 表示虚拟内存区域使用标准巨型页。
13)VM_ARCH_1 和 VM_ARCH_2 由各种处理器架构自定义。
14)VM_HUGEPAGE 表示虚拟内存区域允许使用透明巨型页,VM_NOHUGEPAGE表示虚拟内存区域不允许使用透明巨型页。
15)VM_MERGEABLE 表示 KSM(内核相同页合并,Kernel Samepage Merging)可以合并数据相同的页。
(3)虚拟内存操作集合(vm_operations_struct):定义了虚拟内存区域的各种操作方法,其代码如下。
include/linux/mm.h struct vm_operations_struct { void (*open)(struct vm_area_struct * area); void (*close)(struct vm_area_struct * area); int (*mremap)(struct vm_area_struct * area);
int (*fault)(struct vm_fault *vmf); int (*huge_fault)(struct vm_fault *vmf, enum page_entry_size pe_size); void (*map_pages)(struct vm_fault *vmf, pgoff_t start_pgoff, pgoff_t end_pgoff);
/* 通知以前的只读页即将变成可写,* 如果返回一个错误,将会发送信号SIGBUS给进程*/ int (*page_mkwrite)(struct vm_fault *vmf); /* 使用VM_PFNMAP或者VM_MIXEDMAP时调用,功能和page_mkwrite相同*/
int (*pfn_mkwrite)(struct vm_fault *vmf); … }
1)open 方法:在创建虚拟内存区域时调用 open 方法,通常不使用,设置为空指针。
2)close 方法:在删除虚拟内存区域时调用 close 方法,通常不使用,设置为空指针。
3)mremap 方法:使用系统调用 mremap 移动虚拟内存区域时调用 mremap 方法。
4)fault 方法:访问文件映射的虚拟页时,如果没有映射到物理页,生成缺页异常,异常处理程序调用 fault 方法来把文件的数据读到文件的页缓存中。
5)huge_fault 方法:和 fault 方法类似,区别是 huge_fault 方法针对使用透明巨型页的文件映射。
6)map_pages 方法:读文件映射的虚拟页时,如果没有映射到物理页,生成缺页异常,异常处理程序除了读入正在访问的文件页,还会预读后续的文件页,调用 map_pages 方法在文件的页缓存中分配物理页。
7)page_mkwrite 方法:第一次写私有的文件映射时,生成页错误异常,异常处理程序执行写时复制,调用 page_mkwrite 方法以通知文件系统页即将变成可写,以便文件系统检查是否允许写,或者等待页进入合适的状态。
8)pfn_mkwrite 方法:和 page_mkwrite 方法类似,区别是 pfn_mkwrite 方法针对页帧号映射和混合映射。
2.链表和树
如图 3.12 所示,进程的虚拟内存区域按两种方法排序。
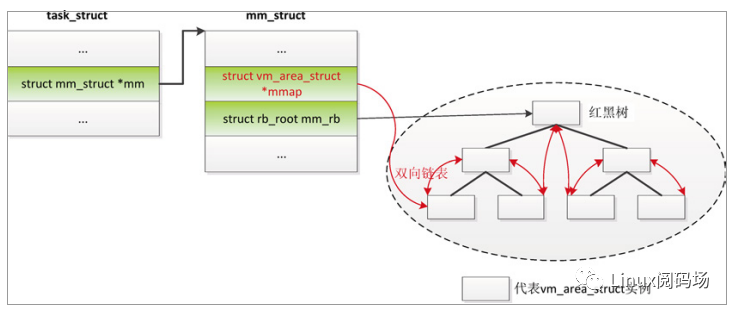
图3.12 虚拟内存区域的链表和树
(1)双向链表,mm_struct.mmap 指向第一个 vm_area_struct 实例。
(2)红黑树,mm_struct.mm_rb 指向红黑树的根。
虚拟内存区域使用起始地址和结束地址描述,链表按起始地址递增排序。红黑树是平衡的二叉查找树,按起始地址排序,使用红黑树有以下好处。
1)在红黑树中查找一个虚拟内存区域的速度快。
2)增加一个新的区域时,先在红黑树中找到刚好在新区域前面的区域,然后向链表和树中插入新区域,可以避免扫描链表。
3.4.3 创建内存映射
C 标准库封装了函数 mmap 用来创建内存映射,内核提供了 POSIX 标准定义的系统调用 mmap:
asmlinkage long sys_mmap(unsigned long addr, unsigned long len, unsigned long prot, unsigned long flags, unsigned long fd, off_t off);
Linux 内核从 2.3.31 版本开始提供私有的系统调用 mmap2:
asmlinkage long sys_mmap2(unsigned long addr, unsigned long len, unsigned long prot, unsigned long flags, unsigned long fd, off_t off);
两个系统调用的区别是:mmap 指定的偏移的单位是字节,而 mmap2 指定的偏移的单位是页。有的处理器架构实现了这两个系统调用,有的处理器架构只实现了其中一个系统调用,例如 ARM64 架构只实现了系统调用 mmap。
系统调用 sys_mmap 的执行流程如图 3.13 所示。
(1)检查偏移是不是页的整数倍,如果偏移不是页的整数倍,返回“-EINVAL”。
(2)如果偏移是页的整数倍,那么把偏移转换成以页为单位的偏移,然后调用函数sys_mmap_pgoff。
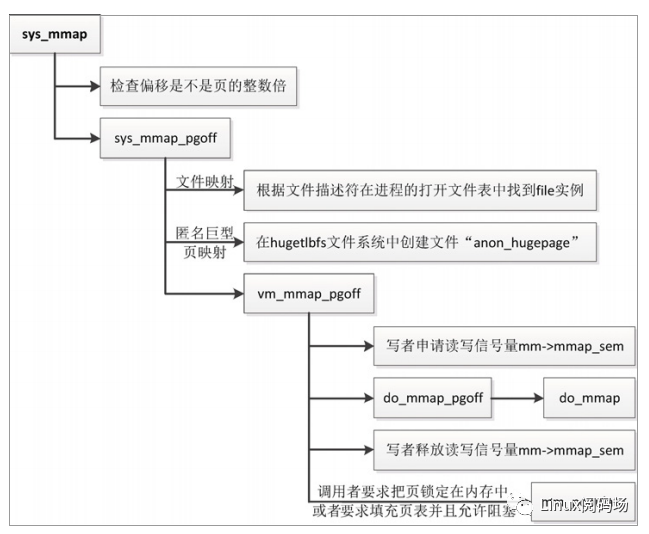
图3.13 系统调用sys_mmap的执行流程
函数 sys_mmap_pgoff 的执行流程如下。
(1)如果是创建文件映射,根据文件描述符在进程的打开文件表中找到 file 实例。
(2)如果是创建匿名巨型页映射,在 hugetlbfs 文件系统中创建文件“anon_hugepage”,并且创建该文件的一个打开实例 file。
注意:文件名没有实际意义,创建匿名巨型页映射两次,就会在 hugetlbfs 文件系统中创建两个名为“anon_hugepage”的文件,这两个文件没有关联。
(3)调用函数 vm_mmap_pgoff 进行处理。
函数 vm_mmap_pgoff 的执行流程如下。
(1)以写者身份申请读写信号量 mm->mmap_sem。
(2)把创建内存映射的主要工作委托给函数 do_mmap。
(3)释放读写信号量 mm->mmap_sem。
(4)如果调用者要求把页锁定在内存中,或者要求填充页表并且允许阻塞,那么调用函数 mm_populate,分配物理页,并且在页表中把虚拟页映射到物理页。
常见的情况是:创建内存映射的时候不分配物理页,等到进程第一次访问虚拟页的时候,生成页错误异常,页错误异常处理程序分配物理页,在页表中把虚拟页映射到物理页。
函数 do_mmap 实现创建内存映射的主要工作,执行流程如图 3.14 所示。
(1)调用函数 get_unmapped_area,从进程的虚拟地址空间分配一个虚拟地址范围。函数 get_unmapped_area 根据情况调用特定函数以分配虚拟地址范围。
1)如果是创建文件映射或匿名巨型页映射,那么调用 file->f_op->get_unmapped_area以分配虚拟地址范围。
2)如果是创建共享的匿名映射,那么调用 shmem_get_unmapped_area 以分配虚拟地址范围。
3)如果是创建私有的匿名映射,那么调用 mm->get_unmapped_area 以分配虚拟地址范围。ARM64 架构的内核在装载程序时,如果选择传统布局,函数 arch_pick_mmap_layout把 mm->get_unmapped_area 设置为函数 arch_get_unmapped_area。
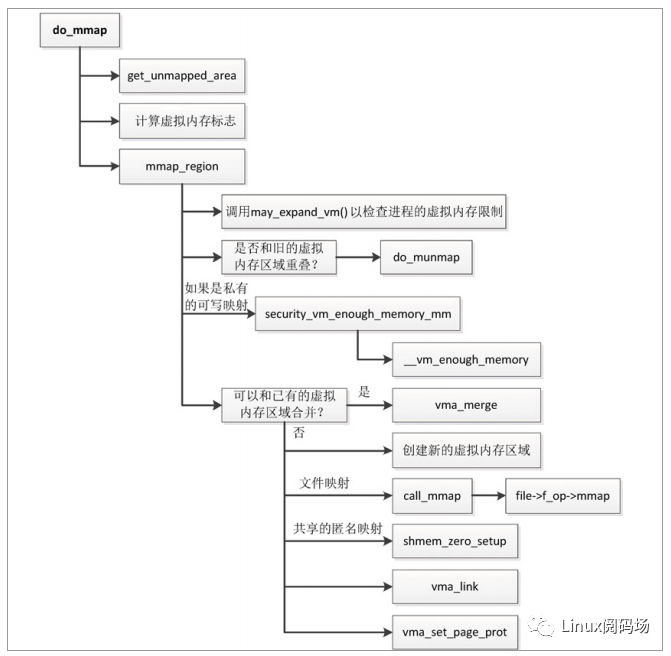
图3.14 函数do_mmap的执行流程
(2)计算虚拟内存标志。
vm_flags |= calc_vm_prot_bits(prot, pkey) | calc_vm_flag_bits(flags) | mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
把系统调用中指定的保护位和标志合并到一个标志集合中,函数 calc_vm_prot_bits把以“PROT_”开头的保护位转换成以“VM_”开头的标志,函数 calc_vm_flag_bits 把以“MAP_”开头的标志转换成以“VM_”开头的标志。
mm->def_flags 是默认的虚拟内存标志:进程默认的虚拟内存标志是 VM_NOHUGEPAGE,即不使用透明巨型页;内核线程默认的虚拟内存标志是 0。
VM_MAYREAD 表示允许设置标志 VM_READ,VM_MAYWRITE 表示允许设置标志VM_WRITE,VM_MAYEXEC 表示允许设置标志 VM_EXEC。这 3 个标志是系统调用 mprotect所需要的。
(3)调用函数 mmap_region 以创建虚拟内存区域。
函数 mmap_region 负责创建虚拟内存区域,执行流程如下。
(1)调用函数 may_expand_vm 以检查进程申请的虚拟内存是否超过限制。
首先检查(进程的虚拟内存总数 + 申请的页数)是否超过地址空间限制:mm->total_vm +npages > rlimit(RLIMIT_AS) >> PAGE_SHIFT。
如果是私有的可写映射,并且不是栈,那么检查(进程数据的虚拟内存总数 + 申请的页数)是否超过最大数据长度:mm->data_vm + npages > rlimit(RLIMIT_DATA) >> PAGE_SHIFT。
(2)如果是固定映射,调用者强制指定虚拟地址范围,可能和旧的虚拟内存区域重叠,那么需要从旧的虚拟内存区域删除重叠的部分。
(3)如果是私有的可写映射,检查所有进程申请的虚拟内存的总和是否超过物理内存的容量。
/** 如果是需要记账的映射,那么检查所有进程申请的虚拟内存的总和是否超过物理内存的容量。* 需要记账的映射具备以下3个条件。*
(1)私有的可写映射。*
(2)不是标准巨型页(因为标准巨型页单独记账)。 *
(3)需要预留物理内存(即未设置VM_NORESERVE)。*/
if (accountable_mapping(file, vm_flags)) { charged = len >> PAGE_SHIFT; /* 根据虚拟内存过量提交的策略,判断物理内存是否足够。*/
if (security_vm_enough_memory_mm(mm, charged)) return -ENOMEM; vm_flags |= VM_ACCOUNT; }
(4)如果可以和已有的虚拟内存区域合并,那么调用函数 vma_merge,和已有的虚拟内存区域合并。
(5)如果不能和已有的虚拟内存区域合并,处理如下。
1)创建新的虚拟内存区域。
2)如果是文件映射,那么调用文件的文件操作集合中的 mmap 方法(file->f_op->mmap),mmap 方法的主要功能是设置虚拟内存区域的虚拟内存操作集合(vm_area_struct.vm_ops),其中的 fault 方法很重要:第一次访问虚拟页的时候,触发页错误异常,异常处理程序将调用虚拟内存操作集合中的 fault 方法以把文件的数据读到内存。
文件的文件操作集合是在打开文件的时候设置的,和文件所属的文件系统相关。
很多文件系统把文件操作集合中的 mmap 方法设置为公共函数 generic_file_mmap,函数 generic_file_mmap 的主要功能是把虚拟内存区域的虚拟内存操作集合设置为 generic_file_vm_ops,其中 fault 方法是函数 filemap_fault。
EXT4 文件系统把文件操作集合中的 mmap 方法设置为函数 ext4_file_mmap,函数 ext4_file_mmap 的主要功能是把虚拟内存区域的虚拟内存操作集合设置为 ext4_file_vm_ops,其中 fault 方法是函数 ext4_filemap_fault。
3)如果是共享的匿名映射,那么在内存文件系统 tmpfs 中创建一个名为“/dev/zero”的文件,并且创建文件的一个打开实例 file,虚拟内存区域的成员 vm_file 指向这个打开实例,把虚拟内存操作集合设置为 shmem_vm_ops。如果没有开启共享内存的配置宏 CONFIG_SHMEM,shmem_vm_ops 等价于 generic_file_vm_ops。
4)调用函数 vma_link,把虚拟内存区域添加到链表和红黑树中。如果虚拟内存区域关联文件,那么把虚拟内存区域添加到文件的区间树中,文件的区间树用来跟踪文件被映射到哪些虚拟内存区域。
5)调用函数 vma_set_page_prot,根据虚拟内存标志(vma->vm_flags)计算页保护位(vma-> vm_page_prot),如果共享的可写映射想要把页标记为只读,目的是跟踪写事件,那么从页保护位删除可写位。
3.4.4 虚拟内存过量提交策略
虚拟内存过量提交,是指所有进程提交的虚拟内存的总和超过物理内存的容量,内存管理子系统支持 3 种虚拟内存过量提交策略。
(1)OVERCOMMIT_GUESS(0):猜测,估算可用内存的数量,因为没法准确计算可用内存的数量,所以说是猜测。
(2)OVERCOMMIT_ALWAYS(1):总是允许过量提交。
(3)OVERCOMMIT_NEVER(2):不允许过量提交。
默认策略是猜测,用户可以通过文件“/proc/sys/vm/overcommit_memory”修改策略。
在创建新的内存映射时,调用函数__vm_enough_memory 根据虚拟内存过量提交策略判断内存是否足够,主要代码如下:
mm/util.c1 int __vm_enough_memory(struct mm_struct *mm, long pages, int cap_sys_admin) 2 { 3 long free, allowed, reserve; 4 … 5
if (sysctl_overcommit_memory == OVERCOMMIT_ALWAYS) 6 return 0; 7 8 if (sysctl_overcommit_memory == OVERCOMMIT_GUESS)
{ 9 free = global_page_state(NR_FREE_PAGES); 10 free += global_node_page_state(NR_FILE_PAGES);
11 12 free -= global_node_page_state(NR_SHMEM); 13 14 free += get_nr_swap_pages(); 15 16 free += global_page_state(NR_SLAB_RECLAIMABLE);
137 第 3 章 内存管理
if (free <= totalreserve_pages) 19 goto error; 20 else 21 free -= totalreserve_pages; 22 23 if (!cap_sys_admin) 24 free -= sysctl_admin_reserve_kbytes >> (PAGE_SHIFT - 10);
25 26 if (free > pages) 27 return 0; 28 29 goto error; 30 } 31 32 allowed = vm_commit_limit(); 33 34 if (!cap_sys_admin) 35 allowed -= sysctl_admin_reserve_kbytes >> (PAGE_SHIFT - 10);
36 37 if (mm) { 38 reserve = sysctl_user_reserve_kbytes >> (PAGE_SHIFT - 10); 39 allowed -= min_t(long, mm->total_vm / 32, reserve); 40 } 41 42 if (percpu_counter_read_positive(&vm_committed_as) < allowed) 43 return 0;
44 error: 45 vm_unacct_memory(pages); 46 47 return -ENOMEM; 48 }
第 5 行代码,如果使用总是允许过量提交的策略,那么允许创建新的内存映射。
第 8 行代码,如果使用猜测的过量提交策略,那么估算可用内存的数量,处理如下。
1)第 9 行和第 10 行代码,空闲页加上文件页,文件页有后备存储设备支持,可以回收。
2)第 12 行代码,共享内存页不应该算作空闲页,它们不能被释放,只能换出到交换区。
3)第 14 行代码,加上交换区的空闲页数。
4)第 16 行代码,加上可回收的内存缓存页。使用 SLAB_RECLAIM_ACCOUNT 标志创建的内存缓存,宣称可回收,dentry 和 inode 缓存应该属于这种情况。
5)第 21 行代码,减去保留的页数。
6)第 23 行和第 24 行代码,如果进程没有系统管理权限,那么减去为根用户保留的页数。
7)第 26 行和第 27 行代码,如果可用内存的页数大于申请的页数,那么允许创建新的内存映射。
如果使用不允许过量提交的策略,那么处理如下。
1)第 32 行代码,计算提交内存的上限。有两个控制参数:sysctl_overcommit_kbytes是字节数,sysctl_overcommit_ratio 是比例值,sysctl_overcommit_kbytes 的默认值是 0,sysctl_overcommit_ratio 的默认值是 50。如果 sysctl_overcommit_kbytes 不是 0,那么上限等于“sysctl_overcommit_kbytes + 交换区的空闲页数”,否则上限等于“(物理内存容量 − 巨型页总数)* sysctl_overcommit_ratio/100 + 交换区的空闲页数”。
2)第34 行和第35 行代码,如果进程没有系统管理权限,那么需要为根用户保留一部分内存。
3)第 37~40 行代码,为了防止一个用户启动一个消耗内存大的进程,保留一部分内存:取“进程虚拟内存长度的 1/32”和“用户保留的页数”的较小值。
4)第 42 行和第 43 行代码,vm_committed_as 是所有进程提交的虚拟内存的总和,如果它小于 allowed,那么允许创建新的内存映射。
3.4.5 删除内存映射
系统调用 munmap 用来删除内存映射,它有两个参数:起始地址和长度。
系统调用 munmap 的执行流程如图 3.15 所示,它把主要工作委托给源文件“mm/mmap.c”中的函数 do_munmap。

图3.15 系统调用munmap的执行流程
(1)根据起始地址找到要删除的第一个虚拟内存区域 vma。
(2)如果只删除虚拟内存区域 vma 的一部分,那么分裂虚拟内存区域 vma。
(3)根据结束地址找到要删除的最后一个虚拟内存区域 last。
(4)如果只删除虚拟内存区域 last 的一部分,那么分裂虚拟内存区域 last。
(5)针对所有删除目标,如果虚拟内存区域被锁定在内存中(不允许换出到交换区),那么调用函数 munlock_vma_pages_all 以解除锁定。
(6)调用函数 detach_vmas_to_be_unmapped,把所有删除目标从进程的虚拟内存区域链表和树中删除,单独组成一条临时的链表。
(7)调用函数 unmap_region,针对所有删除目标,在进程的页表中删除映射,并且从处理器的页表缓存中删除映射。
(8)调用函数 arch_unmap 执行处理器架构特定的处理。各种处理器架构自定义函数arch_unmap,它默认是一个空函数。
(9)调用函数 remove_vma_list 删除所有目标。
编辑:黄飞
-
从史前文明到女娲补天:Linux内存逆向映射(reverse mapping)技术的前世今生2017-09-06 11262
-
虚拟机:linux高端内存管理之永久内核映射2020-06-23 4481
-
Linux内核内存泄漏怎么办2023-07-04 1388
-
Linux内核内存管理架构解析2024-01-04 2206
-
Linux内核内存管理之内核非连续物理内存分配2024-02-23 2254
-
Linux内核地址映射模型与Linux内核高端内存详解2018-05-08 3900
-
[新手引导]linux系统内核中ioremap映射分析2014-07-17 2211
-
linux系统内核中ioremap映射分析2014-08-05 2916
-
学会处理Linux内核访问外设I/O资源的方式2019-05-05 892
-
浅析linux内存映射原理2019-08-24 2089
-
Linux内核高端内存分析2020-12-01 960
-
ARM64 Linux内核页表的块映射2021-01-04 3482
-
STM32(CM3内核) 内存映射2021-12-07 873
-
《Linux内核深度解析》之内存地址空间2022-07-15 3563
-
Linux 内存管理总结2023-11-10 1575
全部0条评论

快来发表一下你的评论吧 !
