

如何使用TinyML和Edge Impulse构建一个咳嗽检测系统
医疗电子
描述
在本文中,我们将展示如何使用 TinyML 和 Edge Impulse 为 Arduino Nano BLE Sense 构建咳嗽检测系统。
这篇文章主要讲述如何使用Edge Impulse在 Arduino Nano BLE Sense 上进行机器学习,以检测实时音频中是否存在咳嗽。我们构建了咳嗽和背景噪声样本的数据集,并应用了高度优化的 TInyML 模型,构建了一个咳嗽检测系统,该系统在 Nano BLE Sense 上 20 kB 的 RAM 中实时运行。同样的方法适用于许多其他嵌入式音频模式匹配应用,例如老年人护理、安全和机器监控。该项目和数据集最初由 Kartik Thakore 启动,以帮助 COVID-19 工作。
前提
要想完成该项目,首先有以下要求:
对软件开发和Arduino的基本了解
安装 Arduino IDE 或 CLI
安卓或iOS手机
带麦克风的Arduino Nano BLE Sense或等效 Cortex-M4+ 板(可选)
我们将使用 Edge Impulse,一个在边缘设备上进行机器学习的在线开发平台。你需要先注册创建一个免费帐户。登录您的帐户,并通过单击标题为您的新项目命名。我们称之为“Arduino Cough Tutorial”。
收集数据集
任何机器学习项目的第一步都是收集一个数据集,该数据集代表我们希望能够在我们的 Arduino 设备上匹配的已知数据样本。首先,我们创建了一个包含 10 分钟音频的小型数据集,分为“咳嗽”和“噪音”两个类别。我们将展示如何将此数据集导入您的 Edge Impulse 项目,添加您自己的样本,甚至从头开始您自己的数据集。该数据集很小,并且具有有限数量的咳嗽和软背景噪声样本。因此,该数据集仅适用于实验,本教程中生成的模型只能区分安静的背景噪音和小范围的咳嗽。我们鼓励您使用更广泛的咳嗽、背景噪音和其他类别(如人类语音)来扩展数据集,以提高性能。
注意:强迫自己咳嗽对声带的伤害很大,收集数据和测试时要小心!
首先下载我们的咳嗽数据集并在您的 PC 上您选择的位置提取文件:https ://cdn.edgeimpulse.com/datasets/cough.zip
您可以使用Edge Impulse CLI Uploader将此数据集导入您的 Edge Impulse 项目。按照这些安装说明安装 Edge Impulse CLI。
打开终端或命令提示符,然后导航到您提取文件的文件夹。
运行:
$ edge-impulse-uploader --clean
$ edge-impulse-uploader --category training training/*
$ edge-impulse-uploader --category testing testing/*
系统将提示您输入 Edge Impulse 用户名、密码和要添加数据集的项目。数据集样本现在将在数据采集页面上可见。通过单击示例,我们可以看到示例的外观,并通过单击每个图表下方的播放按钮来收听音频。
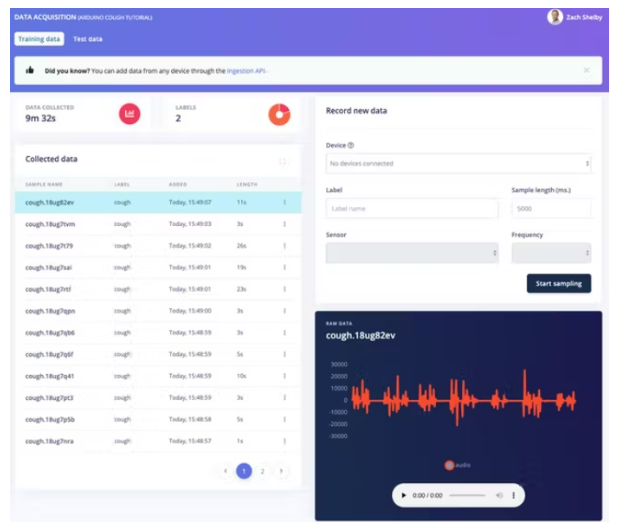
10 分钟的咳嗽和噪音数据样本足以开始。您可以选择使用自己的咳嗽和背景噪声样本扩展数据集。我们可以从数据采集页面直接从设备收集新的数据样本。WAV 格式的音频样本也可以使用Edge Impulse CLI Uploader 上传。
重要提示:现实世界应用程序中使用的模型应使用尽可能多样化的数据集进行训练和测试。这个初始数据集相对较小,因此当暴露于不同类型的背景噪音或来自不同人的咳嗽时,模型的表现会不一致。
最简单的入门方法是使用手机收集音频数据。转到“设备”页面,然后单击右上角的“+ 连接新设备”按钮。选择“使用您的手机”。这将生成一个唯一的 QR 码,以在您的手机浏览器上打开一个 Web 应用程序。对二维码拍照,然后选择打开链接。
Web 应用程序将连接到您的 Edge Impulse 项目,应该如下所示:
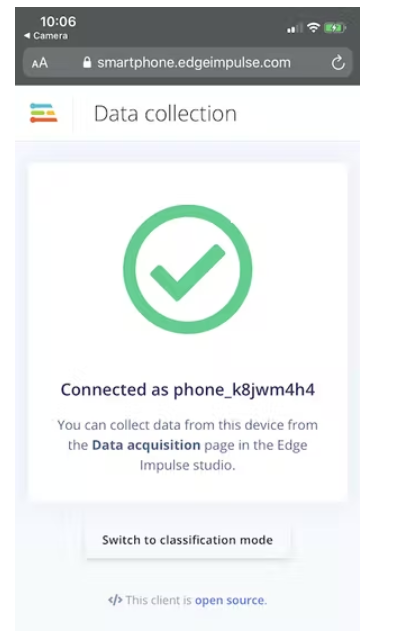
我们现在可以从Edge Impulse的数据采集页面直接从手机中收集音频数据样本。在“记录新数据”部分,输入“咳嗽”或“噪音”标签,确保选择“麦克风”作为传感器,然后单击“开始采样”。您的手机现在将收集音频样本,并将其添加到您的数据集中。

还支持直接从 Nano BLE Sense 板收集音频数据。按照这些说明安装 Edge Impulse 固件和守护程序。一旦设备连接到 Edge Impulse,您就可以像上面的手机一样收集数据样本。

创造你的脉冲
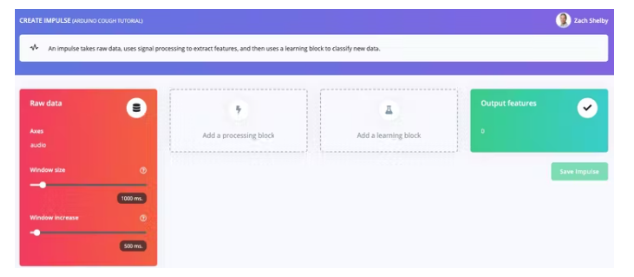
接下来,我们将在创建脉冲页面上选择信号处理和机器学习模块。脉冲将从空白开始,带有原始数据和输出特征块。保留 1000 ms 窗口大小和 500 ms 窗口增加的默认设置。这意味着我们的音频数据将一次处理 1 秒,每 0.5 秒开始。使用小窗口可以节省嵌入式设备上的内存,但这意味着我们需要在两次咳嗽之间没有大间隔的咳嗽数据样本。
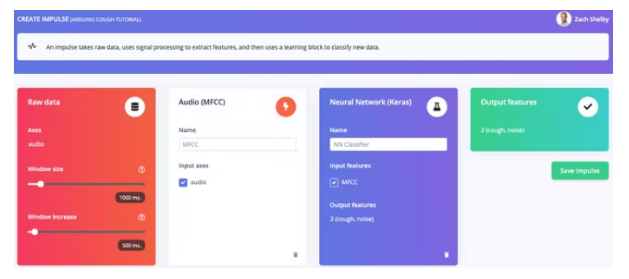
单击“添加处理块”并选择音频 (MFCC)块。接下来单击“添加学习块”并选择神经网络 (Keras)块。点击“保存冲动”。音频块将为每个音频窗口提取频谱图,神经网络块将被训练以根据我们的训练数据集将频谱图分类为“咳嗽”或“噪音”。您产生的脉冲将如下所示:
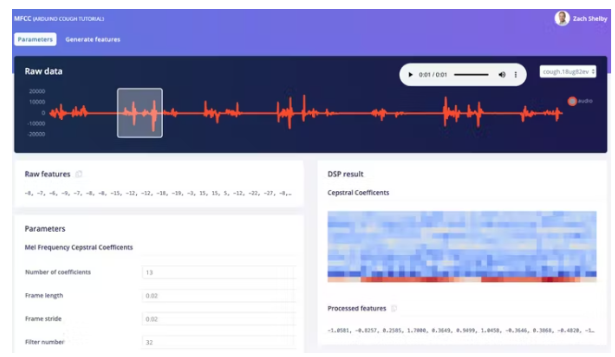
接下来,我们将从MFCC页面上的训练数据集生成特征。此页面显示从任何数据集样本中提取的每 1 秒窗口的频谱图的样子。我们可以将参数保留为默认值。
接下来单击“生成特征”按钮,然后使用此处理块处理整个训练数据集。这将创建完整的特征集,用于在下一步训练我们的神经网络。按“生成特征”按钮开始处理,这需要几分钟才能完成。

我们现在可以在 NN 分类器页面上继续设置和训练我们的神经网络。默认神经网络适用于流水等连续声音。咳嗽检测更复杂,因此我们将在每个窗口的频谱图上使用 2D 卷积配置更丰富的网络。2D 卷积以与图像分类类似的方式处理音频频谱图。按“神经网络设置”部分的右上角,然后选择“切换到 Keras(专家)模式”。

将“神经网络架构”定义替换为以下代码,并将“最小置信度”设置为“0.70”。然后继续单击“开始培训”按钮。训练将需要几秒钟。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, InputLayer, Dropout, Flatten, Reshape, BatchNormalization, Conv2D, MaxPooling2D, AveragePooling2D
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.constraints import MaxNorm
# model architecture
model = Sequential()
model.add(InputLayer(input_shape=(X_train.shape[1], ), name='x_input'))
model.add(Reshape((int(X_train.shape[1] / 13), 13, 1), input_shape=(X_train.shape[1], )))
model.add(Conv2D(10, kernel_size=5, activation='relu', padding='same', kernel_constraint=MaxNorm(3)))
model.add(AveragePooling2D(pool_size=2, padding='same'))
model.add(Conv2D(5, kernel_size=5, activation='relu', padding='same', kernel_constraint=MaxNorm(3)))
model.add(AveragePooling2D(pool_size=2, padding='same'))
model.add(Flatten())
model.add(Dense(classes, activation='softmax', name='y_pred', kernel_constraint=MaxNorm(3)))
# this controls the learning rate
opt = Adam(lr=0.005, beta_1=0.9, beta_2=0.999)
# train the neural network
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
model.fit(X_train, Y_train, batch_size=32, epochs=9, validation_data=(X_test, Y_test), verbose=2)
该页面将显示训练性能和设备上的性能,根据您的数据集应如下所示:

我们的咳嗽检测算法现在可以试用了!
测试
实时分类页面允许我们使用数据集附带的现有测试数据或通过手机或 Arduino 设备中的流式音频数据来测试算法。我们可以从一个简单的测试开始,选择任何测试样本,然后按“加载样本”。这将对测试样本进行分类并显示结果:
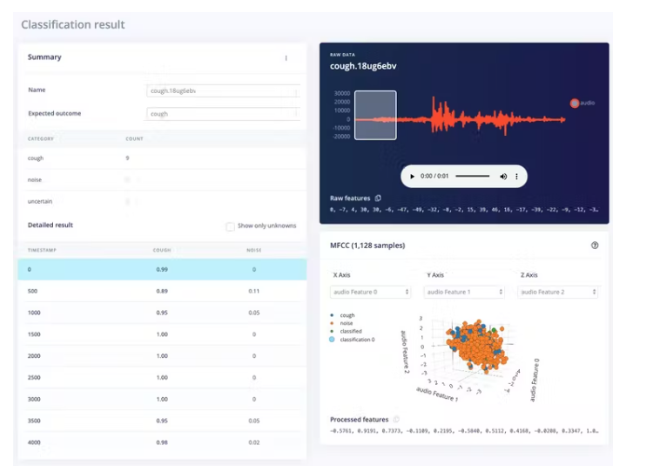
我们还可以使用实时数据测试算法。通过刷新我们之前打开的手机上的浏览器页面,从您的手机开始。然后在“分类新数据”部分中选择您的设备,然后按“开始采样”。当通过 edge-impulse-daemon 连接到项目时,您可以类似地从 Nano BLE Sense 流式传输音频样本,就像在数据收集步骤中一样。
部署
我们可以轻松地将我们的咳嗽检测算法部署到手机上。转到手机上的浏览器窗口并刷新,然后按“切换到分类模式”按钮。这将自动将项目构建到 WebAssembly 包中并在您的手机上连续执行(之后无需云,甚至进入飞行模式!)
接下来,我们可以通过转到部署页面将算法部署到 Nano BLE Sense。在“构建固件”下选择“Arduino Nano 33 BLE Sense”,然后单击“构建”。
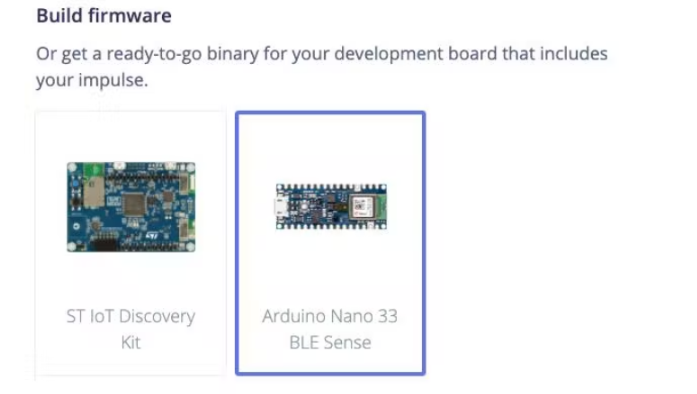
这将为 Nano BLE Sense 构建一个完整的固件,包括您的最新算法。按照屏幕上的说明使用二进制文件刷新您的 Arduino 板。

刷新 Arduino 后,我们可以在设备以 115、200 波特插入 USB 时打开设备的串行端口。串口打开后,按回车键得到提示,然后:
> AT+RUNIMPULSE
Inferencing settings:
Interval: 0.06 ms.
Frame size: 16000
Sample length: 1000 ms.
No. of classes: 2
Starting inferencing, press 'b' to break
Recording...
Recording done
Predictions (DSP: 495 ms., Classification: 84 ms., Anomaly: 0 ms.):
cough: 0.01562
noise: 0.98438
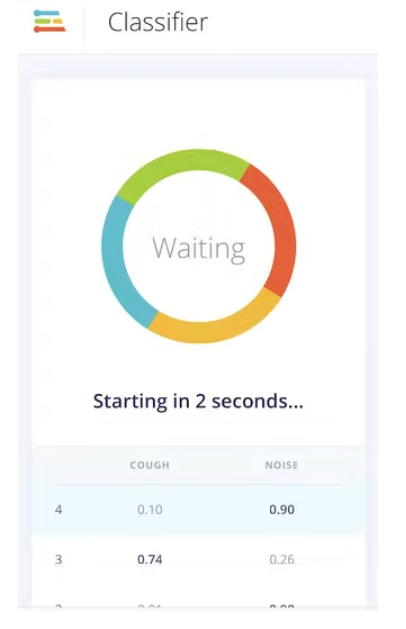
Starting inferencing in 2 seconds...
Recording...
Recording done
Predictions (DSP: 495 ms., Classification: 84 ms., Anomaly: 0 ms.):
cough: 0.01562
noise: 0.98438
Starting inferencing in 2 seconds...
Recording...
Recording done
Predictions (DSP: 495 ms., Classification: 84 ms., Anomaly: 0 ms.):
cough: 0.86719
noise: 0.13281
Starting inferencing in 2 seconds...
Recording...
Recording done
Predictions (DSP: 495 ms., Classification: 84 ms., Anomaly: 0 ms.):
cough: 0.01562
noise: 0.98438
未来可能的拓展
使用您自己的咳嗽和背景声音扩展默认数据集,记得定期重新训练和测试。您可以在测试页面下设置单元测试,以确保模型在扩展时仍然有效。
为不咳嗽的人类声音添加一个新类和数据,例如背景语音、打哈欠等。
从一个新数据集开始,收集音频样本以检测新事物。
根据这些说明部署到 Arduino 库,作为 Arduino Sketch 的一部分,以使用 LED 或显示器显示咳嗽检测
-
咳嗽检测深度神经网络算法2024-05-15 16137
-
使用Edge Impulse关键字识别控制笔记本电脑2023-07-13 878
-
使用Edge Impulse和Nvidia Jetson的面罩检测器2023-06-26 1419
-
使用XIAO BLE Sense&Edge Impulse的宠物活动追踪器2023-06-25 1044
-
在MaaXBoard Mini上使用Edge Impulse进行安全帽检测2023-06-15 1155
-
使用Edge Impulse在pico上进行手势识别2023-02-03 1619
-
借助 Edge Impulse 实现 AI 开发的民主化2022-12-30 3016
-
通过Edge Impulse开始使用TinyML2022-12-15 1665
-
使用Edge Impulse的Covid患者健康评估设备2022-11-11 1052
-
使用Edge Impulse识别大象活动2022-11-02 1308
-
使用Arduino 33 BLE Sense和Edge Impulse构建的咳嗽检测系统2022-08-11 3679
-
Syntiant TinyML板搭建Edge Impulse模型实现语音识别效果2022-07-22 1997
-
什么是TinyML?微型机器学习2022-04-12 12330
-
Edge Impulse的回归模型2021-12-20 1390
全部0条评论

快来发表一下你的评论吧 !
