

OpenVINO2022版本Python API演示
描述
OpenVINO2022 API介绍
OpenVINO2022 版本的SDK在使用比之前版本简单,而且功能比较丰富,特别是支持动态输入设置,一次可以推理多张图像;相比之前的模型输入只支持一种尺度输入跟每次一张图片推理来说是大大的提升执行效率。特别是Python版本的API简单易学,容易上手,只需要掌握下面几个函数就可以完成从模型加载到推理。
导入支持
要使用Python SDK,首先需要导入支持语句,

加载模型
2022版本加载模型提供了两种模式分别是read_model与compile_model方式,这两种方式得到分别是model跟compiled model,其中通过read_model方式读取的model对象可以通过compile_model函数转换为compiled model,同时它们都支持直接访问属性获取输入与输出层信息(inputs/outputs),函数如下:

修改模型输入
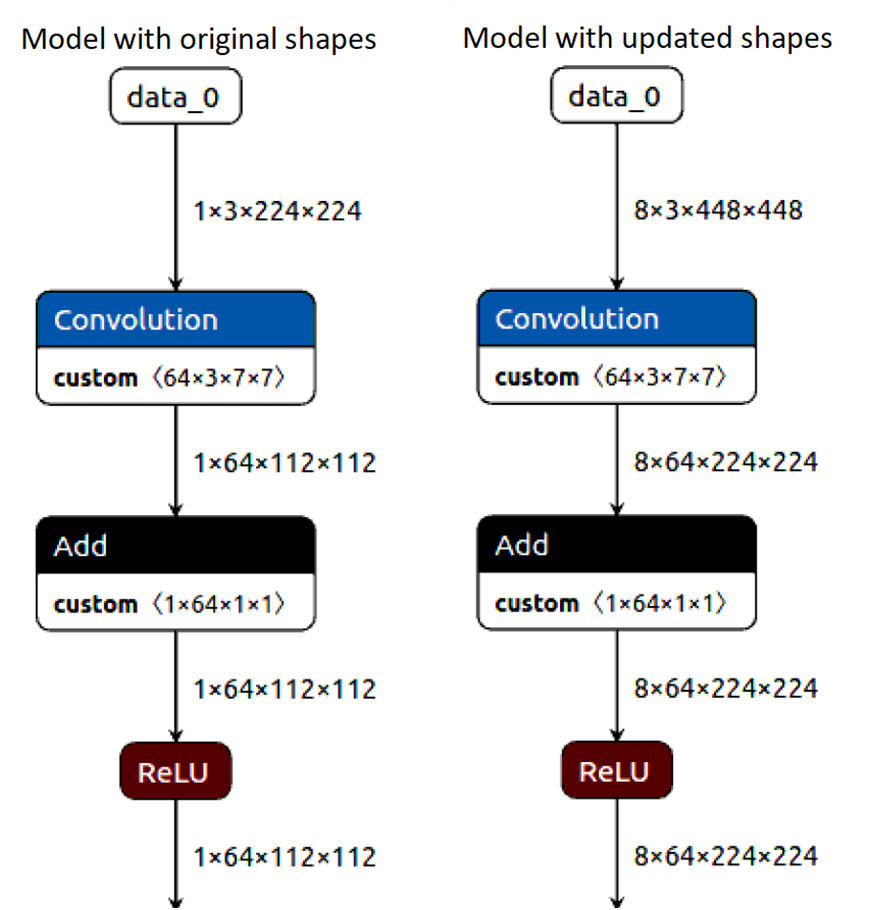
Model的reshape方法支持把模型输入修改,同时会修改整个模型的下行转发推理,当前支持的修改参数包括batch size、输入图像的宽高、假设模型的原始输入为:
1x3x224x224
修改为:
8x3x448x448
只需要调用reshape方法,一行代码即可完成:
model.reshape([8, 3, 448, 448])
前后对比示意图如下:
上述是从一种静态输入各种,设置为另外一种静态输入格式。OpenVINO的reshape还支持动态输入(不定长)的推理输入设置,假设把模型的输入格式从:
[?x3x640x640]
修改为:
[4x3x640x?]
其中 ?表示不定长,可以用如下代码:
 其中 -1表示不定长!
注意:修改输入/动态输入在iGPU上暂时还无法被支持,所以AUTO模式下修改以后可能会遇到推理失败的情况!这块建议参考官方文档说明。
其中 -1表示不定长!
注意:修改输入/动态输入在iGPU上暂时还无法被支持,所以AUTO模式下修改以后可能会遇到推理失败的情况!这块建议参考官方文档说明。
模型推理
Python SDK支持两种方式,一种是通过complied model直接推理,这种方式跟很多深度学习的推理方式非常类似,另外一种方式是先通过compiled model创建InferRequest实例对象,然后调用infer方法完成推理,个人推荐第一种方法,简单快捷明了,希望OpenVINO以后直接把第二种方法给disable了,同时官方的教程也更新为第一种方式推理!两种推理方式代码示意,
方法一:
results = compiled_model(input_data)
方法二:
infer_request = compiled_model.create_infer_request()
infer_request.infer()
output_tensor = infer_request.get_output_tensor()
场景文字检测模型演示
下面是基于2022版本最新Python SDK调用OpenVINO官方提供的自带场景文字检测模型,完成了一个简单的场景文字检测OpenVINO2022版本 Python SDK演示,代码如下:
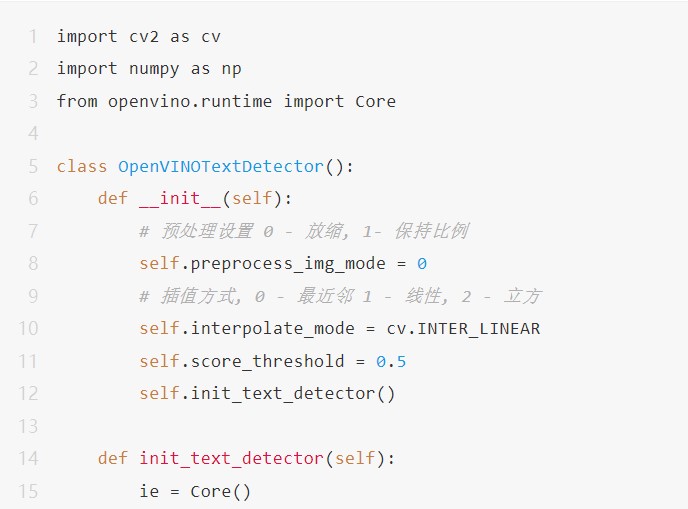

 resized_image = cv.resize(image, (w, h), interpolation=self.interpolate_mode)
resized_image = cv.resize(image, (w, h), interpolation=self.interpolate_mode)

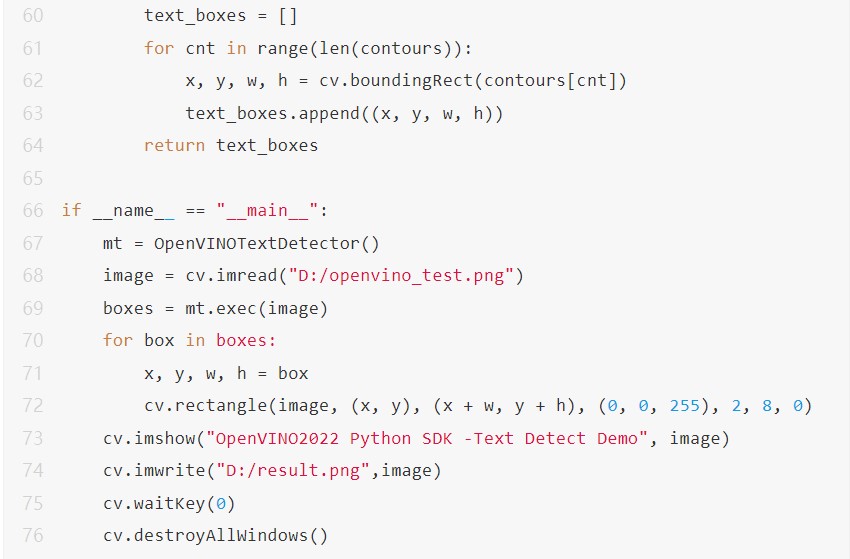
 contours, hiearchy = cv.findContours(mask, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
contours, hiearchy = cv.findContours(mask, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)

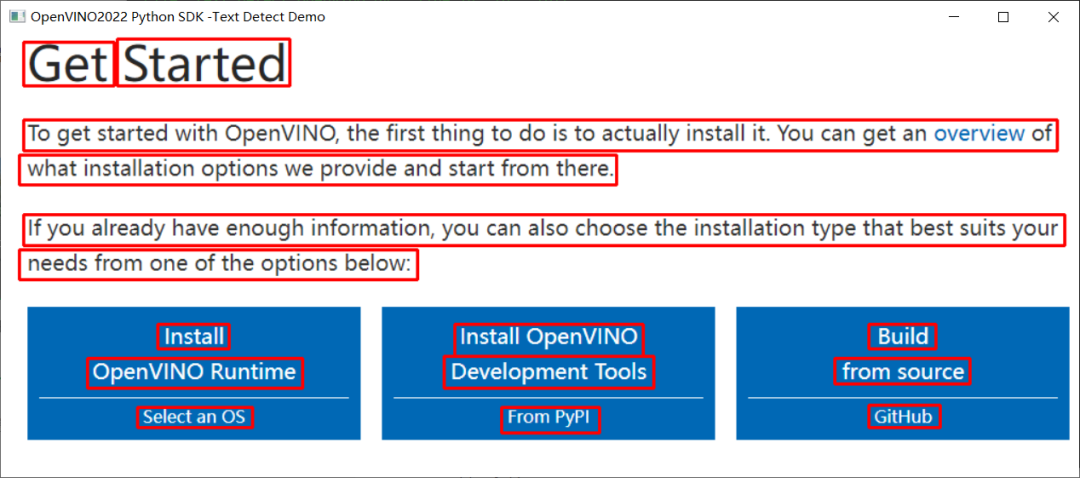
场景文字检测结果:
一个trick的地方,当你修改为动态输入的时候有时候会遇到这个错误:
ValueError: get_shape was called on a descriptor::Tensor with dynamic shape
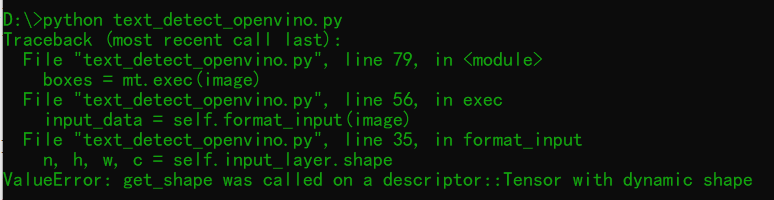
这个时候你需要把Core初始化为全局类属性变量或者一个全局变量一般情况下就会修正这个错误,这个是使用动态输入推理最有玄机的地方!原因我也解释不清楚,也许OpenVINO还需要持续改进,提升开发者满意度!
审核编辑:刘清
-
使用Python API在OpenVINO™中创建了用于异步推理的自定义代码,输出张量的打印结果会重复,为什么?2025-03-06 468
-
OpenVINO2024 C++推理使用技巧2024-07-26 2407
-
如何使用OpenVINO C++ API部署FastSAM模型2023-11-17 2016
-
基于OpenVINO C# API部署RT-DETR模型2023-11-10 2073
-
OpenVINO Java API详解与演示2023-11-09 1798
-
基于OpenVINO C++ API部署RT-DETR模型2023-11-03 2494
-
如何使用OpenVINO Python API部署FastSAM模型2023-10-27 1807
-
基于OpenVINO Python API部署RT-DETR模型2023-10-20 2582
-
OpenVINO™ C# API详解与演示2023-10-13 2042
-
如何使用Python包装器正确构建OpenVINO工具套件2023-08-15 728
-
OpenVINO2022系统应用指南2023-04-12 1281
-
OpenVINO工具套件预处理API的概念及使用方法2022-06-09 3142
-
OpenVINO开发配置应必备哪些基础知识?2021-05-18 2740
-
四个有趣的关于Python 3.9版本新特性2020-10-08 3920
全部0条评论

快来发表一下你的评论吧 !
