

基于Python构建的专门进行数据操作和分析的开源软件库
嵌入式技术
描述
Pandas 是针对 Python 编程语言进行数据操作和数据分析的热门软件库。
什么是 PANDAS?
Pandas 是一个基于 Python 构建的专门进行数据操作和分析的开源软件库,可提供数据结构和运算,进行功能现强大、灵活且易于使用的数据分析和操作。Pandas 为热门编程语言赋予了处理类似电子表格的数据的能力,从而增强了 Python 功能,除其他关键功能外,加快了加载、对齐、操作和合并的速度。后端源代码以 C 或 Python 编写时,Pandas 可提供高度优化的性能,这一点备受赞赏。
“Pandas”的名称源自计量经济学术语“panel data”,用于描述包含多个时间段观察结果的数据集。Pandas 库是在 Python 中执行非常实用的现实分析的高级工具或构建块。未来,其创作者计划将 Pandas 发展为适用于任何编程语言的功能更加强大、更灵活的开源数据分析和数据操作工具。
有人称 Pandas 使用 Python 分析数据,“颠覆了游戏规则”;当前,它已跻身于最热门、广泛使用的数据整理工具之列。其中描述了将数据从不可用或错误的形式中提取到现代分析处理所需的结构和质量级别时使用的一组概念和一种方法。Pandas 的优势在于可轻松处理表格、矩阵和时间序列数据等结构化数据格式。此外,它还可以与其他 Python 科学库结合使用,且效果良好。
PANDAS 的工作原理
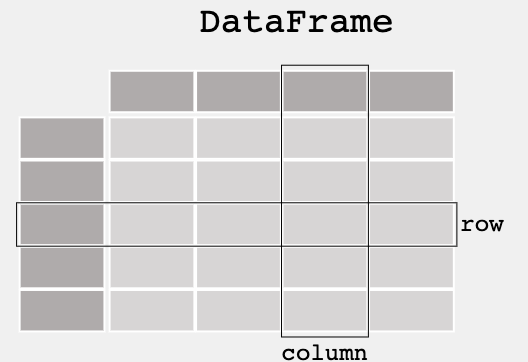
Pandas 开源库内提供了 DataFrame。DataFrame 是二维数组式数据表,其中每列包含一个变量的值,每行包含一组每列的值。DataFrame 中存储的数据可以是数字、系数,也可以是字符类型。也可以将 Pandas DataFrame 视作系列对象的词典或集合。
对 R 编程语言熟悉的数据科学家和编程人员都知道,可以使用 DataFrame 将数据存储在易于概述的网格中。这表明 Pandas 主要用于 DataFrame 形式的机器学习。
Pandas 支持导入和导出不同格式的表格数据,如 CSV 或 JSON 文件。

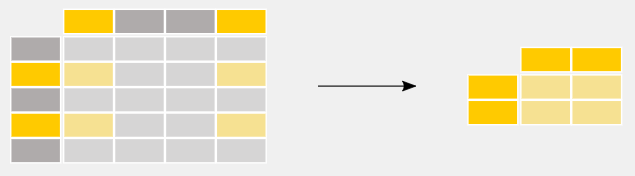
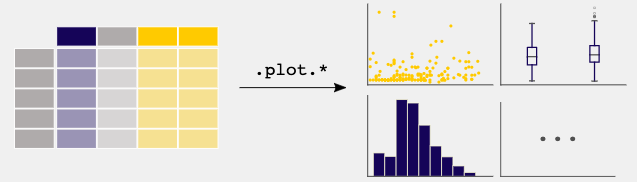
此外,Pandas 还支持各种数据操作运算和数据清理功能,包括选择子集、创建衍生列、排序、连接、填充、替换、汇总统计数据和绘图。

Python 软件包索引(Python 编程语言软件库)的编制者表示,Pandas 非常适合处理多种数据,包括:
包含异构类型列的表格数据,如 SQL 表或 Excel 电子表格
有序和无序(可能并非固定频率)时间序列数据
具有行和列标签的任意矩阵数据(同构类型或异构类型)
其他任何形式的可观察/统计数据集。实际上,数据完全无需标记即可放入 pandas 数据结构中。
PANDAS 的优势
此外,Python 软件包索引的编制者还表示,Pandas 为数据科学家和开发者提供了几个关键优势,包括:
轻松处理浮点和非浮点数据中的缺失数据(表示为 NaN)
大小易变性:可以从 DataFrame 和更高维度的对象中插入和删除列
自动和显式数据对齐:可以将对象显式对齐到一组标签;或者用户只需忽略标签,让序列、DataFrame 等在计算中自动调整数据
强大、灵活的分组功能,对数据集执行分割-应用-组合操作,进行数据聚合和转换
可轻松将其他 Python 和 Numpy 数据结构中参差不齐、索引不同的数据转换为 DataFrame 对象
大型数据集基于标签的智能切片、精美索引和子集构建
直观的数据集合并与连接
灵活的数据集重塑和旋转
坐标轴的分层标记(每个记号可能具有多个标签)
强大的 I/O 工具,用于加载平面文件(CSV 和分隔文件)、Excel 文件和数据库中的数据,以及保存/加载超快速 HDF5 格式的数据
特定于时间序列的功能:日期范围生成和频率转换、窗口统计数据迁移、日期调整和延迟
Pandas 库的其他优势还包括:缺失数据的数据对齐和集成处理;数据集合并与连接;数据集重塑和旋转;分层轴索引(以便在低维数据结构中处理高维数据)以及基于标签的切片。
PYTHON 和 PANDAS
由于 Pandas 是基于 Python 编程语言构建的,因此让我们简要回顾一下 Python 编程语言。
Python 因其易用性深受数据科学家喜爱,自 1991 年发布首个版本以来不断演进,已成为网络应用程序、数据分析和机器学习领域的热门编程语言之一。
Python 具有出色的易用性,它采用高度可读的语法,即使是初学者也无需花费多少时间学习即可生成程序。这样,开发者和数据科学家可以将更多时间用在解决业务问题上,同时也减少了处理语言复杂性的时间。
Python 可在当今使用的所有重要操作系统以及除 Pandas 之外的主要库上运行。API 服务还提供了 Python 链接或包装器。这样,Python 即可与其他服务和库交互。
除了易于使用之外,Python 深受数据科学家和机器学习开发者喜爱还有一个重要原因。随着 Pandas 和 Numpy 等数据处理库以及 Seaborn 和 Matplotlib 等数据可视化工具的推出,Python 成为了机器学习和数据科学家以及构建机器学习系统的开发者的通用语言。
PANDAS 与数据科学家
Pandas 解决了数据科学家在使用与科学和商业研究环境相关的语言时经常遇到的许多问题。在数据科学中,通常会将处理数据细分为多个阶段,包括之前所述的整理和数据清理;数据分析和建模;将分析整理成适合绘图的形式或以表格形式显示出来。在处理这些任务及其他任务关键型数据科学任务时,Pandas 表现卓越。
GPU 加速的 DATAFRAMES
CPU 由专为按序串行处理优化的几个核心组成,而 GPU 则拥有一个大规模并行架构,当中包含数千个更小、更高效的核心,专为同时处理多重任务而设计。与仅包含 CPU 的配置相比,GPU 的数据处理速度快得多。它们还因其超低浮点运算(性能)单价深受欢迎,其还可通过加快多核服务器的并行处理速度,解决当前的计算性能瓶颈问题。

过去几年 GPU 一直肩负着推动深度学习发展的重任,而 ETL 和传统机器学习工作负载依然是采用 Python 进行编写,并且通常是使用 Scikit-Learn 等单线程工具或通过 Spark 等大型多 CPU 分布式解决方案进行编写。
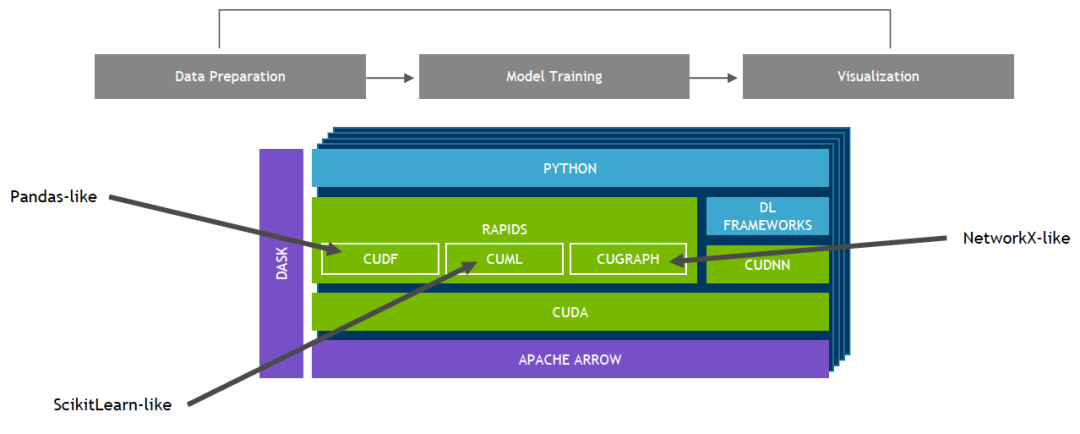
NVIDIA 开发了 RAPIDS,这是一个开源的数据分析和机器学习加速平台,用于完全在 GPU 中执行端到端数据科学训练管线。它依赖于 NVIDIA CUDA 基元进行低级别计算优化,但通过用户友好型 Python 界面实现 GPU 并行结构和极高的显存带宽。
RAPIDS 侧重于有关分析和数据科学的通用数据准备任务,可提供 GPU 加速的 DataFrame。DataFrame 模仿 pandas API,且构建在 Apache Arrow 之上。它集成了 scikit-learn 和各种机器学习算法,无需支付典型的序列化成本即可更大限度实现互操作性和高性能。这可加速端到端流程(从数据准备到机器学习,再到深度学习)。 RAPIDS 还包括对多节点、多 GPU 部署的支持,大大加快了对更大规模数据集的处理和训练。
审核编辑:汤梓红
-
如何使用SQL进行数据分析2024-11-19 3262
-
python有什么用 如何用python创建数据库2023-08-28 2170
-
应用MATLAB(或Python)对数据进行数字特征估计与频谱分析2023-08-02 819
-
Danfo.js提供高性能、直观易用的数据结构,支持结构化数据的操作和处理2020-09-23 6269
-
基于Python的数据分析2020-05-01 1959
-
如何利用Python进行数据分析2020-04-23 2545
-
利用Python进行数据分析之时间序列基础2020-03-20 1214
-
介绍如何利用Python对Ginkgo USB- CAN进行数据收发2019-05-08 2657
-
数据库教程之如何进行数据库设计2018-10-19 2139
-
怎么有效学习Python数据分析?2018-06-28 3011
-
python数据分析的类库2018-05-10 2800
-
如何快速学会Python?利用Python进行数据分析2018-04-17 11708
-
了解数据科学Python库2017-11-15 5669
全部0条评论

快来发表一下你的评论吧 !
