

FPGA上部署深度学习的算法模型的方法以及平台
可编程逻辑
1397人已加入
描述
今天给大家介绍一下FPGA上部署深度学习的算法模型的方法以及平台。希望通过介绍,算法工程师在FPGA的落地上能“稍微”缓和一些,小白不再那么迷茫。阿chai最近在肝一个开源的项目,等忙完了会给大家出几期FPGA上从零部署的教程,包括一些底层的开发、模型的量化推理等等,因为涉及的东西太多了,所以得分开写。
 这个到底有多方便,我们看一段代码,首先我们调用模型:
这个到底有多方便,我们看一段代码,首先我们调用模型: 我们首先clone下来项目并且编译:
我们首先clone下来项目并且编译: 对于ZYNQ+DPU的开发过程阿chai会单独出一期,因为涉及的东西太多了。。。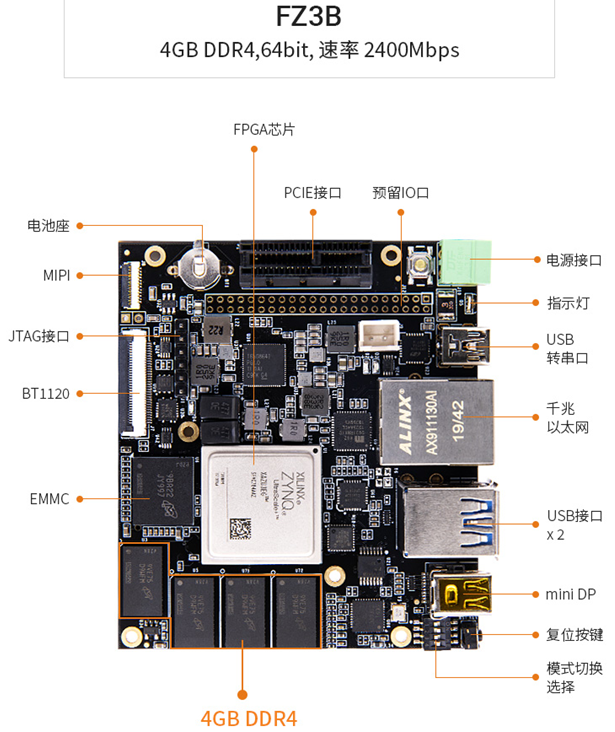 其实部署的思路小伙伴们应该有一些眉目了,就是将自己训练的深度学习模型转换成Paddle Lite模型,然后移植到EdgeBoard开发板上进行测试。接下来我们简单看看是怎样操作的。EdgeBoard中模型的测试由json文件做管理:
其实部署的思路小伙伴们应该有一些眉目了,就是将自己训练的深度学习模型转换成Paddle Lite模型,然后移植到EdgeBoard开发板上进行测试。接下来我们简单看看是怎样操作的。EdgeBoard中模型的测试由json文件做管理: g_predictor; PaddleMobileConfig config; std::string model_dir = j["model"]; config.precision = PaddleMobileConfig::FP32; config.device = PaddleMobileConfig::kFPGA; config.prog_file = model_dir + "/model"; config.param_file = model_dir + "/params"; config.thread_num = 4; g_predictor = CreatePaddlePredictor(config); 2、输入输出参数 paddle_tensor_feeds; PaddleTensor tensor; tensor.shape = std::vector<int>({1, 3, input_height, input_width}); tensor.data = PaddleBuf(input, sizeof(input)); tensor.dtype = PaddleDType::FLOAT32; paddle_tensor_feeds.push_back(tensor); PaddleTensor tensor_imageshape; tensor_imageshape.shape = std::vector<int>({1, 2}); tensor_imageshape.data = PaddleBuf(image_shape, 1 * 2 * sizeof(float)); tensor_imageshape.dtype = PaddleDType::FLOAT32; paddle_tensor_feeds.push_back(tensor_imageshape); PaddleTensor tensor_out; tensor_out.shape = std::vector<int>({}); tensor_out.data = PaddleBuf(); tensor_out.dtype = PaddleDType::FLOAT32; std::vector outputs(1, tensor_out) ; 3、预测
安装paddlemobile-python SDK,在根目录中解压
FPGA与“迷宫”
深度学习这里就不多介绍了,我们接下来介绍一下FPGA是什么。FPGA是现场可编程逻辑门阵列,灵活性非常高,现场编程真的香。说到这里小伙伴们可能还是不太明白,那么我们和ARM对比一下,ARM可以理解为比如这有一个迷宫,迷宫有很多进口也有对应的出口,道路中间有很多“暗门”可以走,对ARM芯片做编程就是触发当中一条通路,路是死的,我们不好改变。FPGA是如果我们想要一个迷宫,FPGA给提供了一个大的“盒子”,里面有很多的“隔板”,我们自己搭建一条就可以了,你想要什么样的路就什么样子,类似玩我的世界,只不过“矿”是各种逻辑门。那就意味着,FPGA可以设计外围电路也可以设计CPU,是不是很爽,当然,爽的背后开发难度也是相当的大的,这种“特定属性”非常时候做人工智能的算法加速。由于制作特殊电路,FPGA之前经常用做信号处理中,配合DSP或者ARM使用,后来也有用FPGA或者CPLD搭建“矿机”当“矿老板”(祝愿”挖矿“的天天矿难)。小白入门A:PYNQ
PYNQ是Python + ZYNQ,用Python进行FPGA开发,首先强调一点,Python近几年非常火,虽然很强大,但是他开发硬件不是真的就做硬件,希望大家不要迷。教程:https://github.com/xupsh/Advanced-Embedded-System-Design-Flow-on-Zynq我们类比一下很火的MicroPython,使用Python开发硬件是得有特定的电路设计的,除非自己是大佬修改底层的固件,但是都修改底层了,是不是可以自己开发就好了。当然这个是面向小白的,对应的开发板如下图。 这个板子类似我们之前玩MicroPython,也是各种调包。实际上ZYNQ是一个双核ARM Cortex-A9处理器和一个FPGA,使用Python的话可以通过Jupyter进行开发,是不是很香,所以这个非常适合小白。FPGA上跑BNN(二值神经网络)是非常不错的,“PYNQ-Z1不同的机器学习数据集(dataset)的测试结果显示:对于MNIST数据集PYNQ-Z1能实现每秒168000张图片的分类,延迟102微妙,准确率达98.4%;对于CIFAR-10、SVHN、GTSRB数据集PYN1-Z1能实现每秒1700张图片的分类,延迟2.2毫秒,准确率分别为80.1%、96.69%和97.66%,系统功耗均保持在2.5W左右。”这个到底有多方便,我们看一段代码,首先我们调用模型:import bnn hw_classifier = bnn.CnvClassifier(bnn.NETWORK_CNVW1A1,'cifar10',bnn.RUNTIME_HW) sw_classifier = bnn.CnvClassifier(bnn.NETWORK_CNVW1A1,'cifar10',bnn.RUNTIME_SW) 进行测试:
from IPython.display import display im = Image.open('car.png') im.thumbnail((64, 64), Image.ANTIALIAS) display(im) car_class = hw_classifier.classify_image_details(im) print("{: >10}{: >13}".format("[CLASS]","[RANKING]")) for i in range(len(car_class)): print("{: >10}{: >10}".format(hw_classifier.classes[i],car_class[i])) 同样支持matplotlib进行数据可视化:
%matplotlib inline import matplotlib.pyplot as plt x_pos = np.arange(len(car_class)) fig, ax = plt.subplots() ax.bar(x_pos - 0.25, (car_class/100.0), 0.25) ax.set_xticklabels(hw_classifier.classes, rotation='vertical') ax.set_xticks(x_pos) ax.set plt.show() 这不就是Python嘛,真的是非常的方便,而且图像处理也兼容使用Pillow。文件中给出了一些图像识别的例子,大家可以去看看。改天阿chai给大家出一个从零搭建PYNQ的教程,包括模型的量化推理等等。
小白入门B:DPU
DPU是一个用于卷积神经网络的可编程引擎。该单元包含寄存器配置模块、数据控制器模块和卷积计算模块。当然,强大的PYNQ也是支持使用DPU的,如果用这个直接看Python的API就可以了,开发板可以使用ZCU104。大神很多直接用ZYNQ开整的,但是那个难度真的不适合初学者去看,等忙完了项目阿chai给小伙伴们整个这个的教程。我们首先clone下来项目并且编译:git clone https://github.com/Xilinx/DPU-PYNQ.git cd DPU-PYNQ/upgrade make 安装pynq-dpu:
pip install pynq-dpu 启动jupyter-notebook:
pynq get-notebooks pynq-dpu -p . 模型库在如下链接中。模型库:https://github.com/Xilinx/Vitis-AI/tree/v1.3对于DPU的设计,我们需要在自己的电脑上进行,在添加模块后,我们使用如下命令进行编译:
make BOARD=
支持国产框架:Paddle-Lite
既然python都可以,那肯定Paddle-Lite这种推理框架也是可行的,百度也有专门的部署开发套件 EdgeBoard。EdgeBoard是基于Xilinx Zynq UltraScale+ MPSoC系列芯片打造的计算卡,芯片内部集成ARM处理器+GPU+FPGA的架构,既具有多核处理能力、也有视频流硬解码处理能力,还具有FPGA的可编程的特点。其实部署的思路小伙伴们应该有一些眉目了,就是将自己训练的深度学习模型转换成Paddle Lite模型,然后移植到EdgeBoard开发板上进行测试。接下来我们简单看看是怎样操作的。EdgeBoard中模型的测试由json文件做管理:{ "model":"测试的模型", "combined_model":true, "input_width":224, "input_height":224, "image":"测试的路径", "mean":[104,117,124], "scale":1, "format":"BGR" "threshold":0.5 } 详细的操作请前往Paddle Lite的GitHub,这里只做简单的流程介绍。GitHub: https://github.com/PaddlePaddle/Paddle-Lite如果不想编译,直接在如下网址中下载编译好的文件即可。编译后的文件:https://ai.baidu.com/ai-doc/HWCE/Yk3b95s8o
1.安装测试
我们首先在有在开发板上编译Paddle Lite,编译的时候需要设置cmake的参数,设置LITE_WITH_FPGA=ON和LITE_WITH_ARM=ON,问就是我们都用到。对应的FPGA的编译脚本是lite/tools/build_FPGA.sh,我们执行即可。sh ./lite/tools/build_fpga.sh make publish_inference -j2 接下来我们编译示例demo,demo也在刚才的下载链接中。板子的使用过程请参考百度官方的文档,文档介绍的非常的清楚,阿chai这里就不花时间去讲解使用过程了。然后进入demo中进行编译:
# classification cd /home/root/workspace/sample/classification/ mkdir build cd build cmake .. make build目录下会出现image_classify和video_classify两个可执行文件,图片预测运行image_classify文件。使用FPGA 进行resnet50进行测试:
./image_classify_fpga_preprocess ../configs/resnet50/drink.json 可以看到对应的输出结果,同样detection的模型测试方式也这样操作。
2.可调用的接口
C++
C++的主要包括预处理以及预测库的接口。- 预处理接口主要是使用FPGA完成图片的缩放、颜色空间转换和mean/std操作。
- 预测库接口主要完成模型的初始化、输入参数构造、预测和结果获取。
/** * 判断输入图像是否是wc 16对齐 * width 输入图像宽度 * channel 输入图像高度 **/ bool img_is_align(int width, int channel); /** * 对齐后的大小 * width 输入图像宽度 * channel 输入图像高度 **/ int align_size(int width, int channel); /** * 分配存放图片的内存,析构函数会自动释放 (目前支持BGR->RGB RGB->BGR YUV422->BGR YUV->RGB) 图像最大分辨率支持1080p * height 输入图像的框 * width 输入图像宽度 * in_format 输入图像格式 参考image_format * return uint8_t* opencv Mat CV_8UC3 **/ uint8_t* mem_alloc(int img_height, int img_width, image_format in_format); 预测库使用步骤1、模型初始化,构建预测对象
std::unique_ptr
std::vector
g_predictor->Run(paddle_tensor_feeds, &outputs); 4、获取结果
float *data = static_cast<float *>(outputs[0].data.data()); int size = outputs[0].shape[0];
Python
EdgeBoard系统已经安装了python环境,用户可直接使用即可,同时python接口为用户提供了paddlemobile的python安装包以及示例工程。文件名称说明| paddlemobile-0.0.1.linux-aarch64-py2.tar.gz | paddlemobile的python2安装包 |
| edgeboard.py | 基于python的模型预测示例 |
| api.py | edgeboard.py的api示例 |
| configs.classification | 分类模型的配置文件目录,同C++示例的配置文件 |
| configs.detection | 检测模型的配置文件目录,同C++示例的配置文件 |
| models.classification | 分类模型的模型文件目录,同C++示例的模型文件 |
| models.detection | 检测模型的模型文件目录,同C++示例的模型文件 |
tar -xzvf home/root/workspace/paddlemobile-0.0.1.linux-aarch64-py2.tar.gz 例如使用分类模型的测试如下:
python api.py -j 你测试的json文件 详细的使用说明请关注Paddle-Lite的GitHub。 介绍了这几种,其实大家可以看出来,入门使用并不难,难的是底层的硬件设计与算法加速量化等等,这些都是打包好的东西,我们真的开发还是得慢慢的扣底层的。在这里借用一位大神说的话,现在人工智能算法工程师和十年前的嵌入式工程师差不多,从需求到硬件、软件、算法、应用等等都能做,貌似真的是这样,太卷了,不多学点真的要凉。工具是越来越好用,难的是轮子怎么造,一起加油。
审核编辑:彭静
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
FPGA加速深度学习模型的案例2024-10-25 2328
-
深度学习算法在嵌入式平台上的部署2024-07-15 5025
-
想在STM32 MCU上部署机器学习模型?这份入门教程,让你一学就会~2023-10-18 7955
-
什么是深度学习算法?深度学习算法的应用2023-08-17 3482
-
如何部署ML模型到Google云平台2023-07-05 1513
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2178
-
深度学习模型的部署方法2022-12-01 3339
-
在Arm虚拟硬件上部署PP-PicoDet模型的设计方案2022-09-23 4221
-
在Arm虚拟硬件上部署PP-PicoDet模型2022-09-16 3523
-
如何用Arm虚拟硬件在Arm Cortex-M上部署PaddlePaddle2022-09-02 3221
-
介绍在STM32cubeIDE上部署AI模型的系列教程2021-12-14 3383
-
深度融合模型的特点2021-07-16 2247
-
FPGA上部署深度学习的算法模型的方法以及平台2021-06-10 4482
-
【详解】FPGA:深度学习的未来?2018-08-13 4042
全部0条评论

快来发表一下你的评论吧 !
