

图像去噪方法总结
描述
图像降噪的英文名称是Image Denoising, 图像处理中的专业术语。是指减少数字图像中噪声的过程,有时候又称为图像去噪。
噪声是图像干扰的重要原因。一幅图像在实际应用中可能存在各种各样的噪声,这些噪声可能在传输中产生,也可能在量化等处理中产生。根据噪声和信号的关系可将其分为三种形式:(f(x, y)表示给定原始图像,g(x, y)表示图像信号,n(x, y)表示噪声。)
1) 加性噪声,此类噪声与输入图像信号无关,含噪图像可表示为f(x, y)=g(x, y)+n(x, y),信道噪声及光导摄像管的摄像机扫描图像时产生的噪声就属这类噪声;
2) 乘性噪声,此类噪声与图像信号有关,含噪图像可表示为f(x, y)=g(x, y)+n(x ,y)g(x, y),飞点扫描器扫描图像时的噪声,电视图像中的相干噪声,胶片中的颗粒噪声就属于此类噪声。
3) 量化噪声,此类噪声与输入图像信号无关,是量化过程存在量化误差,再反映到接收端而产生。 目前来说图像去噪分为三大类:基于滤波器的方法(Filtering-Based Methods)、基于模型的方法(Model-Based Methods)和基于学习的方法(Learning-Based Methods)。 接下来让我们分别来看一下,这几种去噪方法的优缺点。
01
基于滤波器的方法
经典的基于滤波的方法,如中值滤波和维纳滤波等,利用某些人工设计的低通滤波器来去除图像噪声。
中值滤波器[1]:它是一种常用的非线性平滑滤波器,其基本原理是把数字图像或数字序列中一点的值用该点的一个领域中各点值的中值代换,其主要功能是让周围像素灰度值的差比较大的像素改取与周围的像素值接近的值,从而可以消除孤立的噪声点,所以中值滤波对于滤除图像的椒盐噪声非常有效。
自适应维纳滤波器[2]:它能根据图像的局部方差来调整滤波器的输出,局部方差越大,滤波器的平滑作用越强。
同一个图像中具有很多相似的图像块,可以通过非局部相似块堆叠的方式去除噪声,如经典的非局部均值(NLM)算法[3]、基于块匹配的3D滤波(BM3D)算法[4]等。缺点:1. 块操作会导致模糊输出。2. 需要手动设置超参数。
02
基于模型的方法
基于模型的方法试图对自然图像或噪声的分布进行建模。然后,它们使用模型分布作为先验,试图获得清晰的图像与优化算法。基于模型的方法通常将去噪任务定义为基于最大后验(MAP)的优化问题,其性能主要依赖于图像的先验。如Xu等人[5]提出了一种基于低秩矩阵逼近的红外加权核范数最小化(WNNM)方法。Pang等人[9]引入了基于图的正则化器来降低图像噪声。 在过去的几十年中,各种基于模型的方法已经被用于图像先验建模,包括非局部自相似(NSS)模型,稀疏模型,梯度模型和马尔可夫随机场(MRF)模型。尽管它们具有高的去噪质量,但是大多数基于图像先验方法都有两个缺点:
这些方法在测试阶段通常涉及复杂的优化问题,使去噪过程时非常耗时的。因此,大多数基于先验图像先验方法在不牺牲计算效率的情况下很难获得高性能。
模型通常是非凸的并且涉及几个手动选择的参数,提供一些余地以提高去噪性能。
为了克服先验方法的局限性,最近开发了几种判别学习方法以在截断推理过程的背景下,学习图像先验模型。得到的先验模型能够摆脱测试阶段的迭代优化过程。Schmidt和Roth提出了一种收缩场级联(CSF)方法,该方法将基于随机场的模型和展开的半二次优化算法统一为一个学习框架。陈等人提出了一种可训练的非线性反应扩散(TNRD)模型,该模型通过展开固定数量的梯度下降推断步骤来学习改进的专家领域。尽管CSF和TNRD在弥补计算效率和去噪质量上的差距方面已经取得了好的效果,但它们的性能本质上仅限于先前那种特定的形式。具体而言,CSF和TNRD采用的先验是基于分析模型,这个模型在捕获图像结构整体特征上被限制。此外,通过阶段式贪婪训练以及所有阶段之间的联合微调来学习参数,并且涉及许多手工参数。另外一个不可忽视的缺点是他们针对特定水平的噪音训练特定的模型,并且在盲图像去噪上受限制。 虽然这些基于模型的方法有很强的数学推导性,但在重噪声下恢复纹理结构的性能将显著下降。此外,由于迭代优化的高度复杂性,它们通常是耗时的。
03
基于学习的方法
基于学习的方法侧重于学习有噪声图像到干净图像的潜在映射,可以分为传统的基于学习的方法和基于深度网络的学习方法。近年来,由于基于深度网络的方法比基于滤波、基于模型和传统的基于学习的方法获得了更有前景的去噪结果,它们已成为主流方法。 Zhang等人[6]通过叠加卷积、批归一化和校正线性单元(ReLU)层,提出了一种简单但有效的去噪卷积神经网络(CNN)。 受图像非局部相似度的启发,将非局部操作纳入到的循环神经网络中[7]。 Anwar等人[8]提出了一种带特征注意力的单阶段去噪网络。 DnCNN[10]、FFDnet[11]、CBDnet[12]这三篇觉得应该是联系十分紧密的一个系列,是逐步泛化,逐步考虑增加噪声复杂的一个过程,DnCNN主要针对高斯噪声进行去噪,强调残差学习和BN的作用,FFDnet考虑将高斯噪声泛化为更加复杂的真实噪声,将噪声水平图作为网络输入的一部分,CBDnet主要是针对FFDnet的噪声水平图部分入手,通过5层FCN来自适应的得到噪声水平图,实现一定程度上的盲去噪。 DnCNN使用了Batch Normalization和Residual Learning加速训练过程和提升去噪性能。网络的结构图如下:
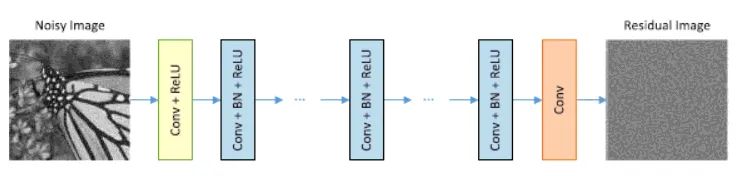
FFDNet侧重与去除更加复杂的高斯噪声。主要是不同的噪声水平。之前的基于卷积神经网络的去噪算法,大多数都是针对于某一种特定噪声的,为了解决不同噪声水平的问题,FFDNet的作者利用noise level map作为输入,使得网络可以适用于不同噪声水平的图片:

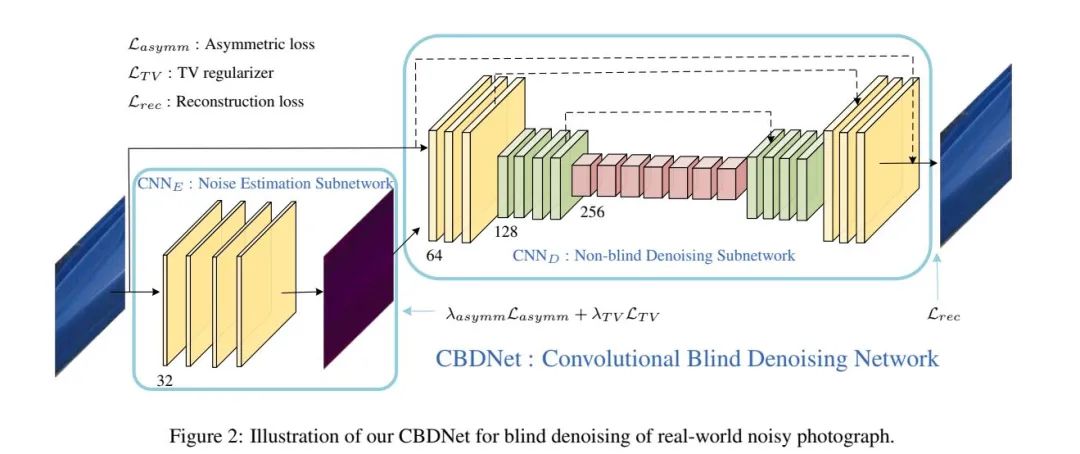
CBDNet网络由噪声估计子网络和去噪子网络两部分组成。同时进行end to end的训练。并采用基于信号独立的噪声以及相机内部处理的噪声合成的图片和真是的噪声图片(所谓“真实”的噪声图片是来自于别人的数据集RENOIR、DND、NC12等,)联合训练。提高去噪网络的泛化能力,也增强去噪的效果:
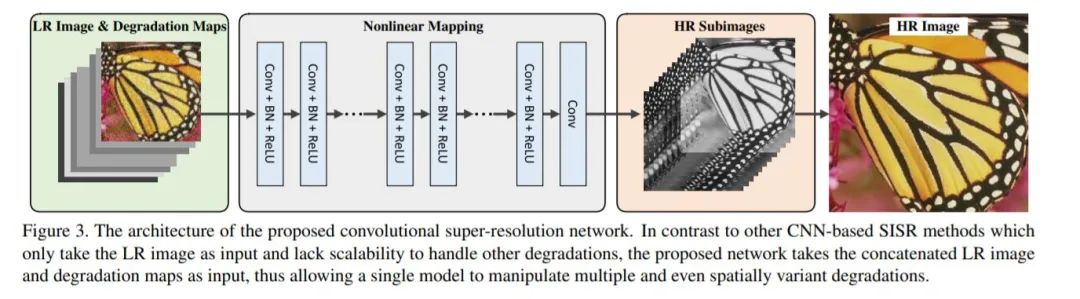
SRMD[13]不同于前三篇,主要是从bicubic入手,考虑模糊核和噪声水平的影响,将LR、模糊核、噪声水平统一的输入网络中,来实现对不同退化模型的复原。可以将退化图和LR图像合并在一起作为CNN的输入。为了证明此策略的有效性,选取了快速有效的ESPCN超分辨网络结构框架。值得注意的是为了加速训练过程的收敛速度,同时考虑到LR图像中包含高斯噪声,因此网络中加入了Batch Normalization层。网络结构如下图所示:
等等等...... 基于深度网络的方法具有很大的发展潜力,但是它主要依靠于经验设计,没有充分考虑到传统的方法,在一定程度上缺乏可解释性。所以最新的CVPR2021论文:Adaptive Consistency Prior based Deep Network for Image Denoising就是通过可解释性来设计网络的,它首先,在传统一致性先验中引入非线性滤波算子、可靠性矩阵和高维特征变换函数,提出一种新的自适应一致性先验(ACP)。其次,将ACP项引入最大后验框架,提出了一种基于模型的去噪方法。该方法进一步用于网络设计,形成了一种新颖的端到端可训练和可解释的深度去噪网络,称为DeamNet。网络结构如下如所示:
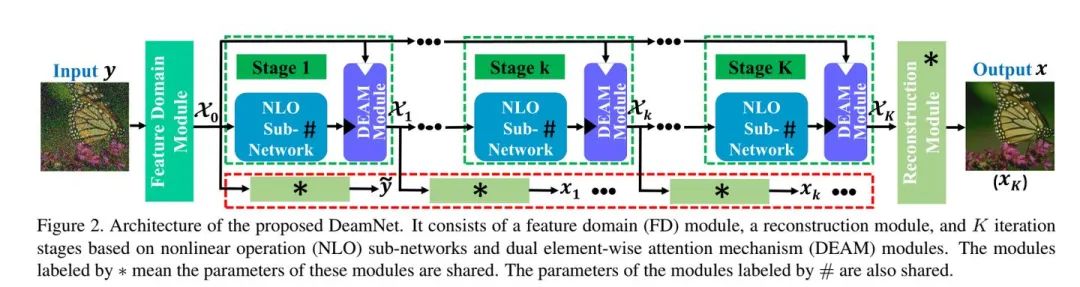
DeamNet整体的网络结构
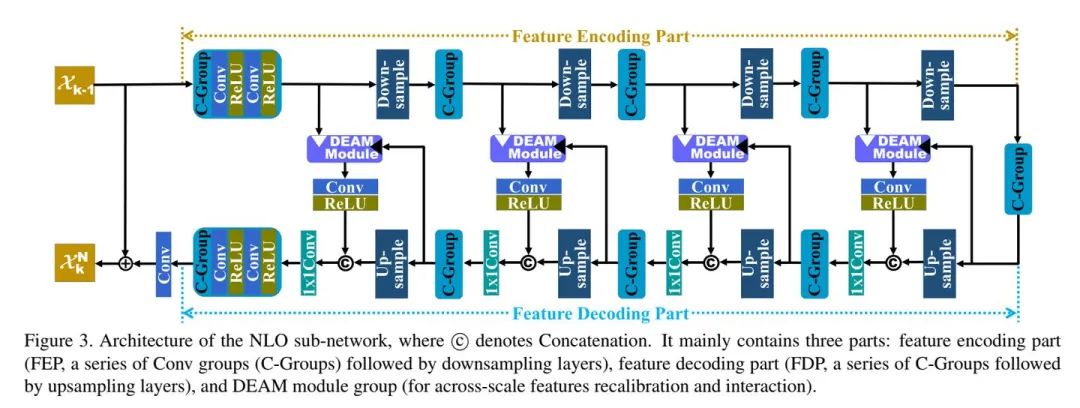
NLO子网络结构
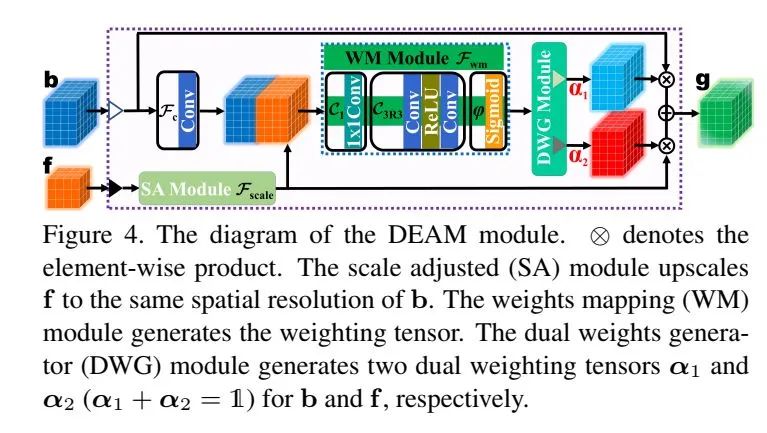
DEAM注意力模块
04
数据集的发展
近年来,去噪问题的研究焦点已经从AWGN(添加高斯白噪声)如BSD68、Set12等转向了更真实的噪声。最近的一些研究工作在真实噪声图像方面取得了进展,通过捕获真实的噪声场景,建立了几个真实的噪声数据集如DnD、RNI15、SIDD等,促进了对真实图像去噪的研究。

‘test039’from BSD68 (合成的噪声图像)

‘Starfish’from Set12 (合成的噪声图像)
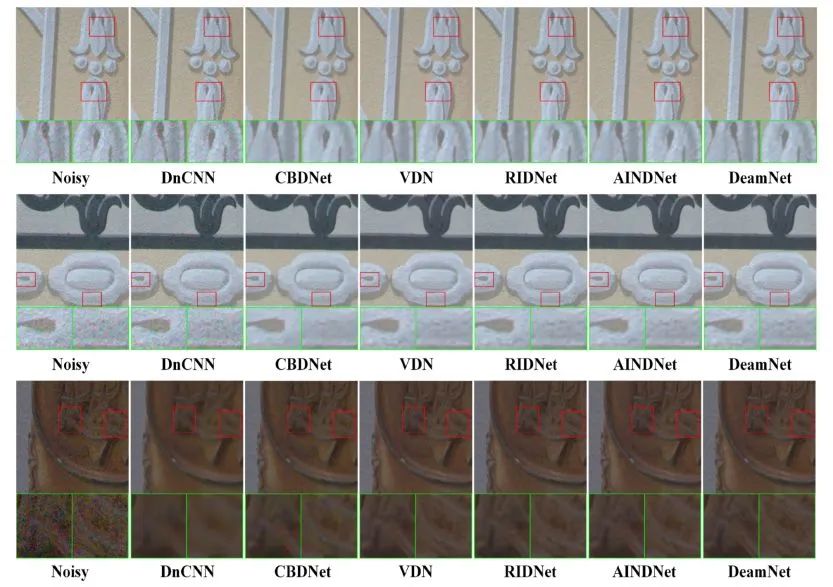
DnD(真实的噪声图像)

RNI15(真实的噪声图像)

SIDD(真实的噪声图像)
审核编辑 :李倩
-
如何使用PDE实现线条痕迹图像去噪算法的设计2020-09-02 1338
-
如何解决图像去噪在去除噪声的同时容易丢失细节信息的问题2019-01-03 2248
-
基于多通道联合估计的非局部均值彩色图像去噪方法2018-02-27 1288
-
基于中值滤波和小波变换的火电厂炉膛火焰图像去噪方法2017-11-27 1385
-
基于数据驱动紧框架图像去噪模型2017-11-05 1517
-
基于Gauss滤波和Euler修复模型的SAR图像去噪2017-01-07 874
-
免疫机理的图像去噪方法研究2017-01-03 642
-
求基于fpga的图像去噪的设计2013-05-12 3665
-
基于NSCT子带自适应Bayes阈值图像去噪方法2011-12-28 1039
-
基于边缘检测的NSCT自适应阈值图像去噪2010-01-22 1235
-
基于一种新阈值函数的小波医学图像去噪2010-01-15 962
-
基于提升小波的图像去噪算法的FPGA设计2009-12-26 1117
-
基于小波变换气动光学效应模糊图像去噪2009-08-06 815
-
基于稀疏分解的图像去噪2008-12-03 1312
全部0条评论

快来发表一下你的评论吧 !
