

NVIDIA CUDA深度神经网络库实现高性能GPU加速
人工智能
描述
NVIDIA CUDA 深度神经网络库(cuDNN)是一个 GPU 加速的深度神经网络基元库,能够以高度优化的方式实现标准例程(如前向和反向卷积、池化层、归一化和激活层)。
全球的深度学习研究人员和框架开发者都依赖 cuDNN 来实现高性能 GPU 加速。借助 cuDNN,研究人员和开发者可以专注于训练神经网络及开发软件应用,而不必花时间进行低层级的 GPU 性能调整。cuDNN 可加速广泛应用的深度学习框架,包括 Caffe2、Chainer、Keras、MATLAB、MXNet、PaddlePaddle、PyTorch 和 TensorFlow。
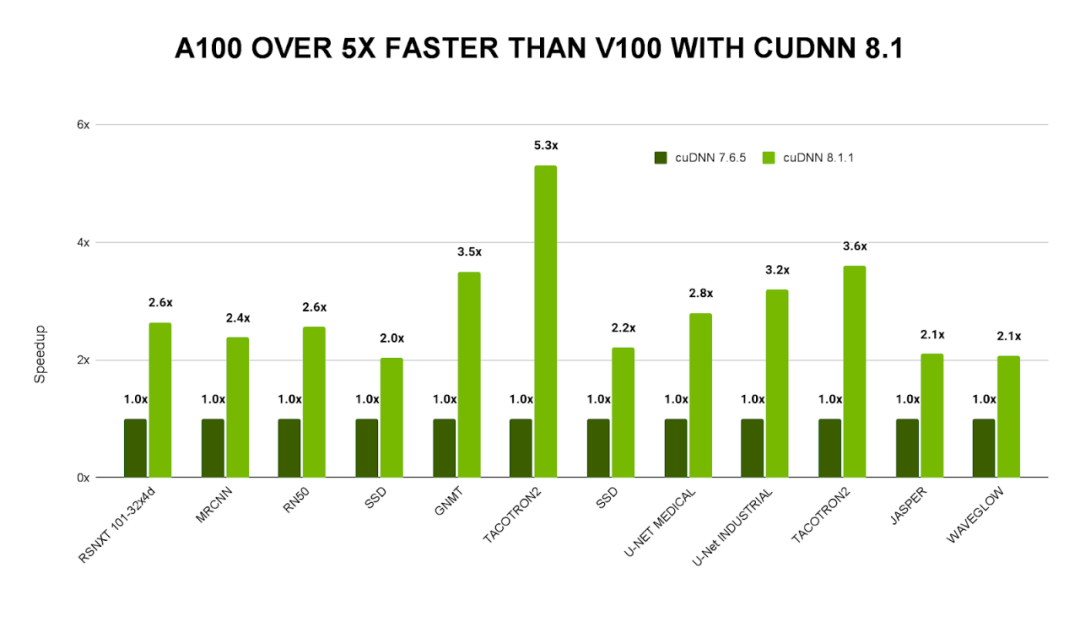
在 21.02 NGC 容器上比较使用 cuDNN 7.6.5 的单个 DGX-1V 服务器与使用 cuDNN 8.1.1 的 DGX-A100 的吞吐量。端到端性能趋于收敛。
cuDNN 8.3 的新变化
cuDNN 8.3 针对 A100GPU 进行了优化,可提供高达 V100 GPU 5 倍的开箱即用性能,并且包含适用于对话式 AI 和计算机视觉等应用的新优化和 API。它已经过重新设计,可实现易用性和应用集成,同时还能为开发者提供更高的灵活性。
cuDNN 8.3 的亮点包括:
为基于转换器的模型提供优化加速;
运行时融合,通过新的运算符、启发式算法和融合迅速编译内核;
将下载包大小缩减 30%。
cuDNN 8.3 现以六个较小的库的形式提供,能够更精细地集成到应用中。开发者可以下载 cuDNN,也可从 NGC 上的框架容器中将其提取出来。
注册成为 NVIDIA 开发者计划会员,下载 cnDNN:https://developer.nvidia.cn/rdp/form/cudnn-download-survey
NGC 框架容器提取:https://catalog.ngc.nvidia.com/
cuDNN 的主要特性
为各种常用卷积实现了 Tensor Core 加速,包括 2D 卷积、3D 卷积、分组卷积、深度可分离卷积以及包含 NHWC 和 NCHW 输入及输出的扩张卷积;
为诸多计算机视觉和语音模型优化了内核,包括 ResNet、ResNext、EfficientNet、EfficientDet、SSD、MaskRCNN、Unet、VNet、BERT、GPT-2、Tacotron2 和 WaveGlow;
支持 FP32、FP16、BF16 和 TF32 浮点格式以及 INT8 和 UINT8 整数格式;
4D 张量的任意维排序、跨步和子区域意味着可轻松集成到任意神经网络实现中;
能为各种 CNN 体系架构上的融合运算提速。
在数据中心和移动 GPU 中采用 Ampere、Turing、Volta、Pascal、Maxwell 和 Kepler GPU 体系架构的 Windows 和 Linux 系统均支持 cuDNN。
审核编辑:刘清
-
NMSIS神经网络库使用介绍2025-10-29 296
-
NVIDIA火热招聘深度学习/高性能计算解决方案架构师2017-08-25 5529
-
NVIDIA火热招聘GPU高性能计算架构师2017-09-01 5201
-
从AlexNet到MobileNet,带你入门深度神经网络2018-05-08 2869
-
基于赛灵思FPGA的卷积神经网络实现设计2019-06-19 4284
-
【大联大世平Intel®神经计算棒NCS2试用体验】0.开箱帖2020-07-27 2839
-
深度神经网络是什么2021-07-12 2157
-
基于深度神经网络的激光雷达物体识别系统2021-12-21 3950
-
NVIDIA深度学习平台2016-08-06 2402
-
NVIDIA深度神经网络加速库cuDNN软件安装教程2017-12-08 2681
-
基于虚拟化的多GPU深度神经网络训练框架2018-03-29 1290
-
NVIDIA GPU加快深度神经网络训练和推断2022-02-18 3130
-
卷积神经网络和深度神经网络的优缺点 卷积神经网络和深度神经网络的区别2023-08-21 5401
-
什么是神经网络加速器?它有哪些特点?2024-07-11 2322
-
NVIDIA实现神经网络渲染技术的突破性增强功能2025-04-07 1584
全部0条评论

快来发表一下你的评论吧 !
