

基于蜂鸟E203和神经网络硬件加速器
描述
摘要
语音关键词识别(Keyword Spotting, KWS)技术已普遍应用在以电池为主的供电设备中,对于此类设备低功耗是一个重要考虑的因素。然而,单独的低功耗神经网络因注重功耗的降低,难以适应高噪声环境下的使用,为了能灵活适应不同噪声场景,并尽可能降低系统功耗与面积,本文提出了一种基于蜂鸟E203和神经网络硬件加速器的自适应噪声环境超低功耗语音关键词识别系统。
本文设计的SoC系统处理器基于RISC-V指令集,通过NICE协处理器接口接入所设计的语音识别神经网络加速器,处理器通过自定义指令可控制加速器开关并读取运算数据,数据最后通过E203处理器处理并将识别结果实时显示在OLED屏上,同时可通过语音控制OLED屏上的贪吃蛇小游戏。此外,该系统可针对低信噪比和高信噪比噪声环境切换不同精度的神经网络,实现在噪声持续变化的环境中,根据信噪比大小自动选择合适的工作模式。在语音识别加速器算法上,本文实现了基于SNR预测模块的神经网络。第一,本文引入了SNR预测模块,对环境噪声进行预测。在高信噪比环境下使用超低功耗的近似权重二值化神经网络(Binary Weight Neural Network, BWN),在低信噪比环境下使用带噪声训练的精确BWN神经网络。第二,在高信噪比环境下,为了降低神经网络的复杂度,本文针对神经网络训练提出了逐步量化方案,筛选出适合将网络权重量化到1bit的网络模型,引入近似计算单元以降低功耗,同时针对能量化为BWN的网络模型,采用软硬件协同设计的方法进行算法定制优化,整体算法能实现12个语音关键词的识别,在近麦克风语音环境下准确率为89.1%,在15dB信噪比环境下准确率为86.5%。第三,在低信噪比环境下,为了不降低神经网络的识别率,本文选择带噪声训练的精确BWN神经网络,在0dB信噪比环境下准确率为88%。
本文基于TSMC 22nm ULL工艺,完成了语音识别加速器的综合(Design Compiler, DC)、功耗分析(PrimeTime PX, PTPX)以及后端版图设计工作,版图设计面积为0.6mm2。当工作频率为250kHz,IO驱动电压为1.8V,SRAM电压为0.6V,logic电路电压为0.39V时可以实现对语音关键词的实时判断,HVT工艺下加速器芯片功耗约为6.7μW。
系统功能介绍
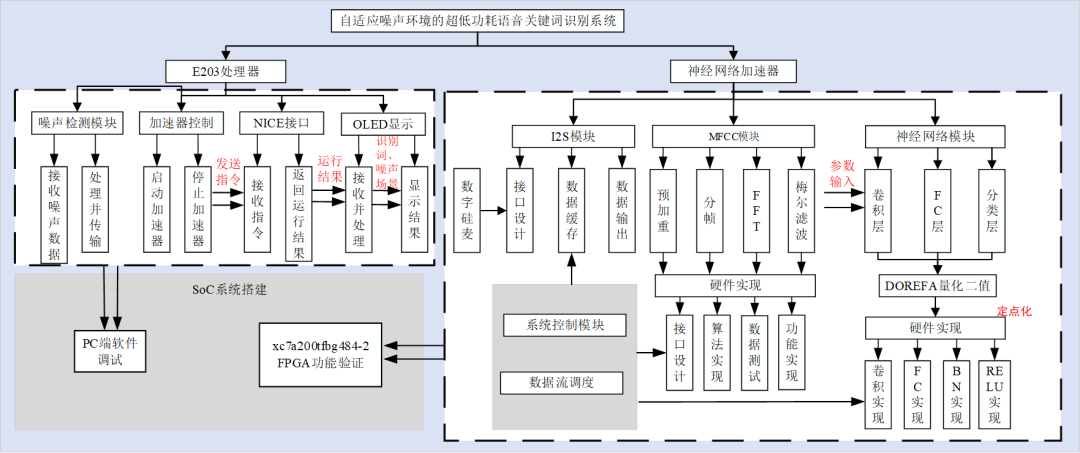
图1 自适应噪声环境的超低功耗语音关键词识别系统功能框图
自适应噪声环境的超低功耗语音关键词识别系统总体功能框图如上图1所示,总体功能框图主要分为E203处理器部分、语音识别加速器部分,以及软硬件分别验证成功后的SoC系统搭建部分,各部分实现的功能如下所述:
E203处理器实现功能:E203处理器主要负责通过在软件与硬件语音识别加速器之间进行控制与数据读写,并通过按键与屏幕显示的方式实现良好的人机交互体验,其主要包括如下三个部分:NICE接口、加速器控制以及OLED显示。
NICE接口:NICE接口部分实现了通过E203处理器对语音识别加速器的控制与数据读写,语音识别加速器通过标准的NICE接口接入E203处理器中,在NICE接口中自定义指令,接收E203发送的从加速器控制部分写入的指令,实现对语音识别加速器的开启和关闭,并持续使用寄存器接收加速器运行结果,接收的运行结果通过NICE接口返回到E203处理器中,并传送到OLED显示部分。
加速器控制:语音识别加速器控制部分首先在软件实现了NICE自定义指令的函数,通过实现加速器开关函数以及全局变量的控制,实现软件控制加速器的开启和关闭。此外,通过接入外部的按键中断实现按键控制语音识别的开启和关闭。
OLED显示:OLED显示部分通过E203处理器接收NICE接口返回的运行结果,对运行结果进行处理,得到每次的关键词识别结果以及当前所处的噪声场景。处理后得到的结果,通过软件与E203处理器驱动连接的OLED屏幕,并实时显示在屏幕上。
语音识别加速器部分主要实现了通过使用数字硅麦对当前环境声音进行采样,对输入语音信号进行MFCC特征提取以及SNR噪声预测,提取后的特征作为神经网络的输入,在经过SNR噪声预测选择使用不同的网络模块后,输入进对应的神经网络当中,神经网络将输入特征进行运算、处理后,得到最终识别的结果,并通过NICE接口返回E203处理器当中,其主要包括如下三个部分,I2S模块、MFCC模块、神经网络模块以及数据流调度和系统控制部分。
I2S模块:I2S模块主要用于将数字硅麦输入的串行信号缓存并转成并行数据输出到MFCC中,其硬件功能实现主要通过接口设计对输入输出信号定义的接口进行规范设计,并输出对硅麦的控制信号,数据缓存用于将输入的串行数据暂存、转化成并行数据,以及最后将并行数据输出的输出部分。
MFCC模块:MFCC模块主要用于将输入的语音信号进行特征提取,转化成更易于神经网络识别的特征数据,此外,还通过SNR预测模块对输入语音信号的噪声场景进行区分。MFCC算法的实现主要分为预加重、分帧、FFT,梅尔滤波,以及SNR噪声预测算法。硬件功能的实现主要分为接口的设计、MFCC和SNR预测的算法实现,数据测试以及功能实现部分。
神经网络模块:神经网络模块主要用于将MFCC输出的特征信号通过前馈神经网络进行运算并输出最终的识别精度。在算法层次部分,神经网络模块主要分为卷积层、全连接(FC)层,以及之间的RELU、BN层,算法部分通过MATLAB搭建并训练得出识别精度,验证了模型的可行性,在低噪声场景下,为满足低功耗的需求,采用DOREFA量化二值化与近似计算单元相结合的方式,而在高噪声场景下,为满足抗噪声需求,采用带噪声训练与精确计算相结合的方式。硬件实现部分主要是将前馈神经网络进行电路上的设计与实现,主要分为神经网络算法的实现,包括卷积层、FC层、BN层以及RELU层的电路实现,权重、数据的存储以及数据调度。
控制模块:系统控制模块与数据调度主要负责控制整体的加速器系统结构以及各个功能模块之间的数据流调度。
E203处理器部分实现的功能主要通过C语言进行软件代码的编写,并在IDE上进行调试,语音识别加速器部分的功能实现主要通过Verilog进行编写,仿真后烧录到FPGA板上进行功能验证。两部分均完成后,通过Nuclei_Studio IDE将软件代码烧录到开发板上进行整体SoC的搭建及功能验证。
系统架构介绍
架构设计
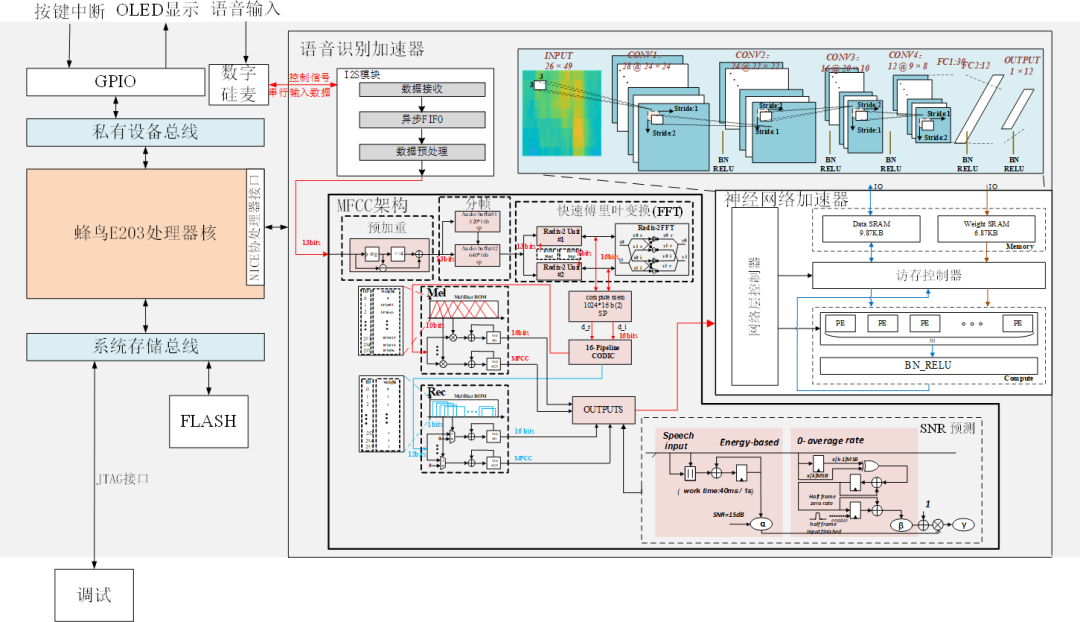
图2 自适应噪声环境的超低功耗语音关键词识别系统架构设计框图
自适应噪声环境的超低功耗语音关键词识别系统架构设计框图如上图2所示,蜂鸟E203核通过系统存储总线访问FLASH存储,FLASH用于存放烧录进开发板的软件代码,此外,系统存储总线还连接JTAG接口用于外部的软件调试和代码的烧录。E203核还通过私有设备总线访问GPIO,GPIO外接按键中断以及OLED屏幕,以外部的控制输入及显示输出。处理器核还通过NICE协处理器接口访问语音识别加速器,并进行指令的写入与运算结果的读出。
语音加速器主要I2S模块、MFCC架构以及神经网络加速器模块组成,外部的语音输入通过数字硅麦接收,并将串行输入数据输入I2S模块,同时I2S模块输出数字硅麦的片选、声道选择等控制信号。
I2S模块由数据接收、异步FIFO、以及数据预处理三个部分组成。数据接收用于接收外部串行输入信号并进行移位寄存,输出32bit的并行数据,异步FIFO用于将输出32bit并行数据暂存,并同步到读时钟域,当读使能信号到来后,32bit的输出经过数据预处理,最终转化成13bit有效输出输入到MFCC模块当中。
MFCC模块的硬件架构主要由预加重、分帧、FFT、Mel滤波、以及SNR预测模块组成,各个模块架构主要负责实现对应的功能及算法(如基-2FFT、CODIC算法、SNR预测算法),模块之间除直接进行输入输出外,还有相应的存储RAM和输出RAM负责数据的调度。MFCC模块实现对语音输入的特征提取,并输出到神经网络加速器模块当中。
在神经网络加速器模块,首先需要在软件层次进行神经网络结构的确定、以及BWN网络模型参数的训练验证,在硬件架构层次上则要实现对应的前馈神经网络每层运算需要的算法以及整体的控制与数据调度。神经网络硬件架构主要分为网络层控制器、访存控制器、以及存储和计算单元,其中,网络层控制器负责架构整体的控制,当前层的确定以及不同层的切换。访存控制器在接收网络层控制器的控制信号后,负责将当前层所需数据从存储单元调度到计算单元,以及当前层计算完成后将运算完成的输出数据写回存储单元。存储单元主要分为数据存储RAM以及权重存储RAM,分别负责存储每一层所需的输入数据以及相应的权重。计算单元主要负责对应计算算法的实现,PE阵列实现数据与权重的卷积/二值,以及全连接运算,BN_RELU则用于实现对应的激活函数以及归一化函数。
其次,从低功耗角度出发,我们设计了复用的PE子计算,可适配完成卷积(二值)和全连接(二值全连接)计算,重新调整了神经网络加速器模块的数据调度方式,减少了整个电路的面积。
版图设计
对于语音识别加速器模块,我们还完成了后端版图设计,如下图3所示,具体的面积参数如下表1所示。电路综合后的功耗细节图如下图4所示,整体电路的功耗为6.70uW,其中神经网络加速器模块的功耗为3.66uW,MFCC模块功耗为1.07uW,I2S模块和其他模块功耗为0.45uW。图4(b)展示了电路中组合逻辑功耗、寄存器功耗以及SRAM功耗占比,可以看到访存功耗占比为67.6%,寄存器功耗占比为19.3%,组合逻辑功耗占比为13.1%,由此可见本电路实际的计算功耗占比较少,这得益于所采用的权重二值化处理方式,使得电路大量的乘法操作变为加法操作。
表1 版图参数
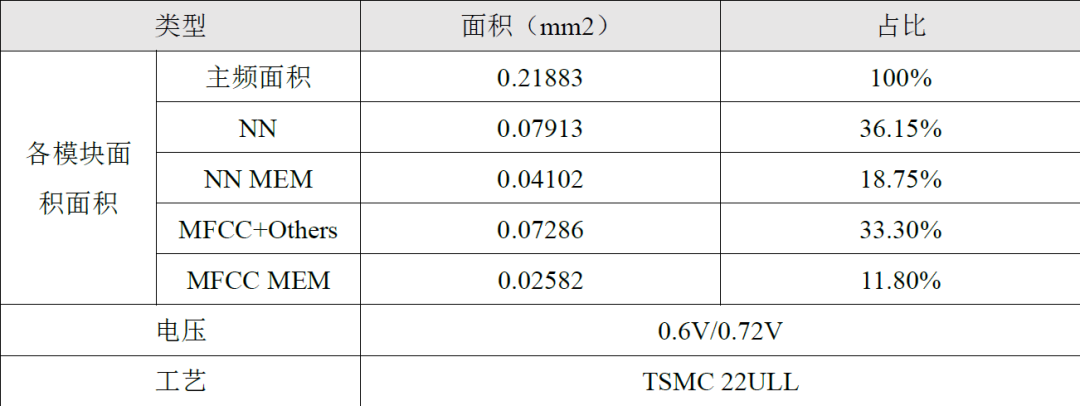
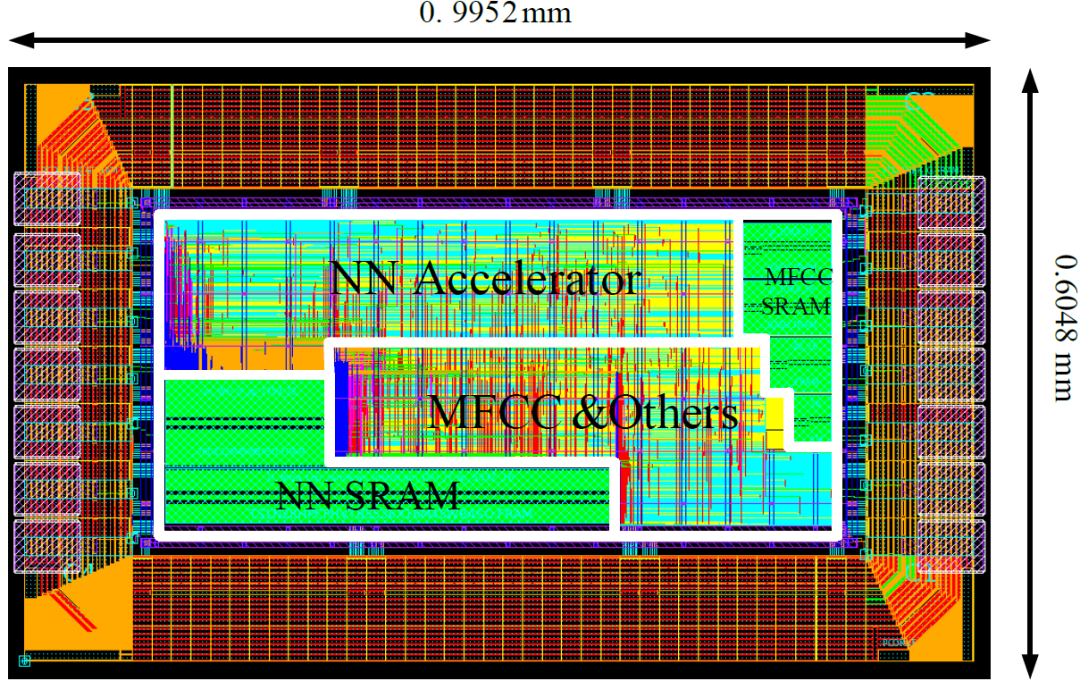
图3 神经网络加速器模块的VLSI实现版图设计
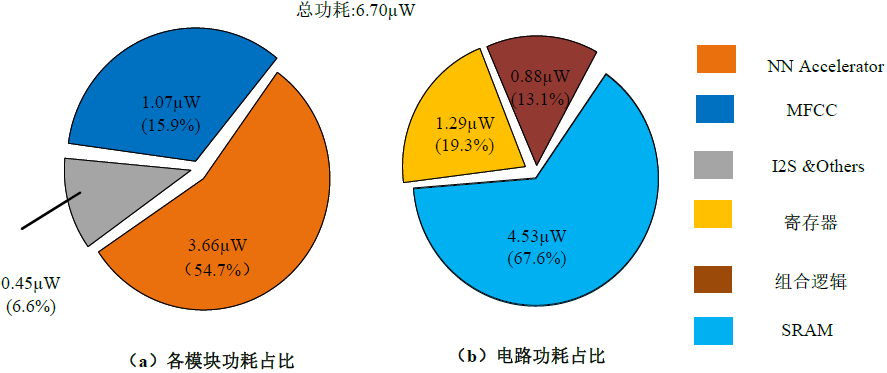
图4 神经网络加速器模块的 VLSI实现功耗占比
硬件加速器详细设计
高噪声环境——带噪声精确BWN神经网络
在高噪声场景中,语音信号的信噪比往往很低,因此,本系统采用精度较高的精确BWN神经网络,同时在训练集中加载了0dB的白噪声训练,实现噪声场景下的高精度。
低噪声环境——无噪声近似BWN神经网络
在低噪声场景中,输入的语音信号相对来说更为清晰,被系统识别到的难度更低,在电路实现中,满足性能要求前提下功耗是衡量电路设计的重要指标之一,完全可以采用加入近似计算单元的功耗BWN来设计,同时去除数据集中的白噪声,使用clean的数据集训练,最终识别精度并没有下降太多。该方案在不增加网络结构的复杂度,不增加网络深度和神经元个数的情况下,使系统在常开工作时的功耗更低。
由于神经网络具有天然容错性,有许多传统的近似乘法单元曾经被应用在DNN神经网络中,比如截断进位乘法器,共享乘法器,迭代对数乘法器等。虽然BWN网络权重已经量化到了1bit, 但是仍然保有继续优化的空间。在3×3的卷积核里,会有9个16bit的数据进行位运算,之后这9个数据再累加,输出卷积核最后的结果。9个数据的累加最终会得到一个最大为20bit的数据,对于一个20bit的数据来说,在其低位如果有部分信息丢失,其实对整个数据的整体精度影响不大,况且神经网络本身就带有一定的容错性,微小的误差可能并不会对网络的结果带来极大的变动,但是从硬件电路的实现角度来考虑,引入近似计算可较大地降低整个电路的功耗以及面积,十分具有研究价值,正是基于上述考量,来评估在加法运算中引入近似的可行性。
乘法运算涉及到移位、位运算和累加三个过程,因此能够实现近似的空间更大,对于纯累加的运算过程,能够使用近似的就是在单个加法器了,最常用的加法器近似手段则是LOA,即Low Or Adder,低位或门加法器,用逻辑或门来替换低位的加法器来实现近似,其电路结构如图5所示:
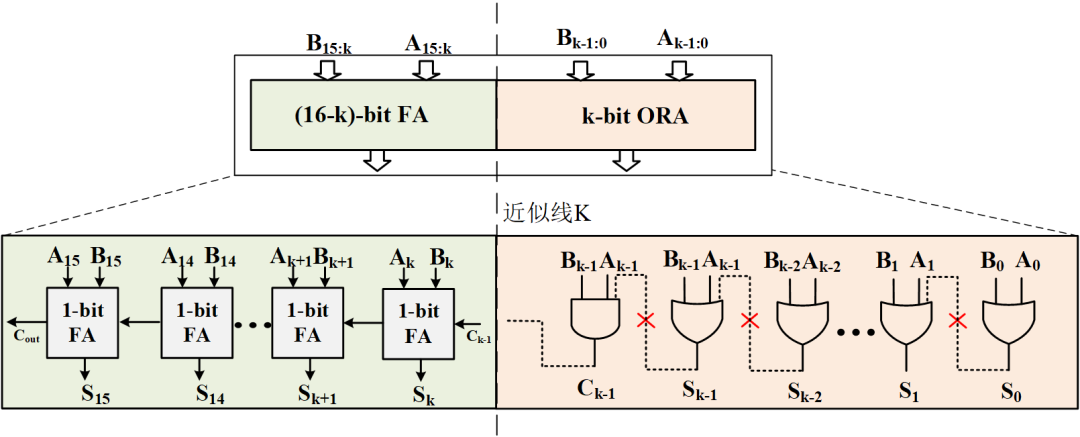
图5 LOA加法器
面向多信噪比的KWS神经网络设计
在前面已经提出了本系统的两种神经网络,在本节中,将对网络中的主要模块进行可重构复用设计,可以从模块级了解本文的神经网络的具体工作模式。由前文中可知神经网络算法中在面向高信噪比语音环境时,为了降低功耗,使用了LOA近似计算单元。具体结构如图6。
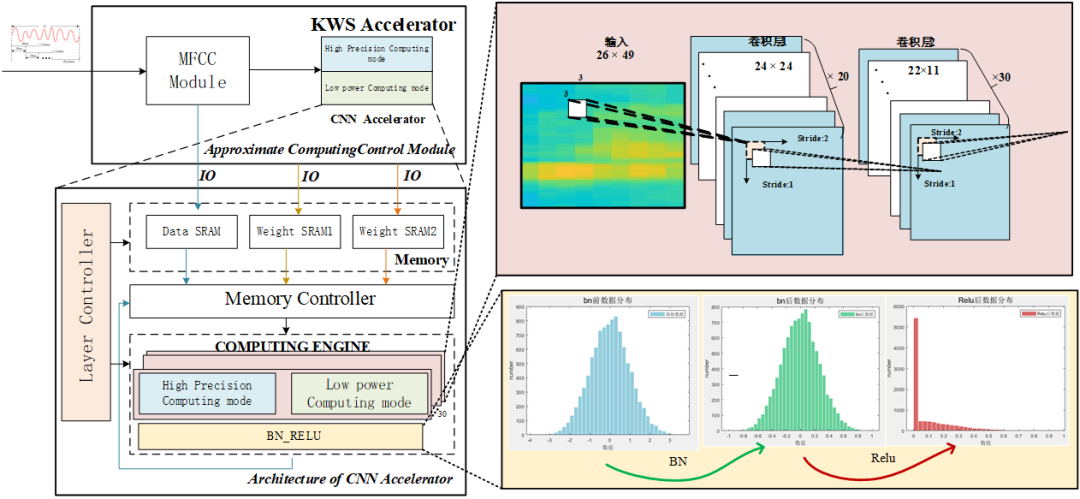
图6 CNN加速器架构图
如图6所示的是在语音关键词分类模块中,语音数据和权重数据分别存储在SRAM中,当SNR预测模块得到的是低信噪比的噪声环境时,语音数据经过可重构PE_ARRAY阵列模块进行网络计算。当SNR预测模块得到的结果是高信噪比时,语音数据经过可重构PE_ARRAY阵列模块进行网络计算。
如图6所示,硬件中有三片sram,分别存储语音数据,在高信噪比环境下的权重1和在低信噪比环境下的权重2。Memory controller模块用于生成地址和计算时分别调用SRAM中的具体数据。Layer controller是使用状态机控制当前计算网络所处层级。可重构PE_ARRAY阵列模块用于网络计算,共有BN_RELU模块用于每层卷积操作之后对数据进行归一化处理。
软件实现
自定义指令的编写
软件实现最关键的问题是实现RISC-V自定义指令并可以确实控制蜂鸟核里nice接口连接的协处理器,具体的语音识别加速器的设计在上一节已被充分介绍,蜂鸟E203的开源核给我们拓展协处理器预留了nice接口,并且学习资料丰富,根据预留的拓展接口以及相应的通信协议,我们成功把语音识别加速器挂载到核上面,具体不再赘述。
自适应噪声切换
在实现噪声模块功能这方面,我们团队提出了两种方案,分别是根据SNR预测在硬件上设计电路的硬件方案以及在软件上设置阈值来检测环境的软件方案。
硬件方案的具体思路是在运算时,累加一段时间区间内的语音信号能量,噪声信号实际上就是能量的高低,噪声越高信号中也就含有越多的能量,硬件方案正是基于这个思路来检测环境噪声强度。
而软件方案则是借助我们系统内蜂鸟E203处理器,利用处理器的灵活控制的特点,外接声音检测模块,并设置一个噪声阈值,当模块检测到外部环境中的噪声超过这个阈值时,给处理器发送一个低信号,而在处理器中则记录低信号出现的次数,一段时间内,如果出现低信号的次数超过了处理器中设置的高噪声的阈值,那么可以认为当前环境噪声较高,需要切换工作模式。
系统实物图

致谢
在此表示衷心的感谢芯来科技设立的RISV-MCU 社区,社区中丰富的学习资料帮助我们团队快速上手了蜂鸟E203的初步使用,清晰的文件分类让我们查阅学习非常方便,跟社区中其他参赛队伍交流也使得我们受益良多。
同时特别感谢社区中的胡灿等其他老师,我们团队在设计这个系统的过程中,遇到了许多问题,胡灿老师平易近人,很耐心地解答问题,让我们学到了很多,帮助我们最终完成了整个系统。
感谢芯来科技的创始人胡振波先生,胡先生为了RISC-V在国内的推广殚精竭虑,特别编写了基于RISC-V的开源蜂鸟核E203,十分令人倾佩,我们团队购买了先生编写的《嵌入式开发快速入门》和《教你设计CPU》两本书,学习书中的内容让我们团队在应用蜂鸟核时更加得心应手。
在项目设计之初,我们团队也遇到很多问题,能解决这些问题,得益于队友之间的信任和鼓励,也得益于大赛组委会给大家提供了这样的优秀平台。希望集创赛可以越办越好!
审核编辑 :李倩
-
蜂鸟E203硬件集成步骤2025-10-30 225
-
NucleiStudio基于一代蜂鸟E203的工程创建2025-10-29 191
-
基于FPGA平台的蜂鸟E203 JTAG debug出错问题的解决思路2025-10-28 205
-
如何对蜂鸟e203内核乘除法器进行优化2025-10-24 289
-
蜂鸟E203内核优化方法2025-10-21 276
-
什么是神经网络加速器?它有哪些特点?2024-07-11 2208
-
西门子推出Catapult AI NN软件,赋能神经网络加速器设计2024-06-19 1877
-
《 AI加速器架构设计与实现》+第一章卷积神经网络观后感2023-09-11 2275
-
请问蜂鸟E203支持硬件断点吗?2023-08-16 670
-
什么是AI加速器 如何确需要AI加速器2022-02-06 6215
-
神经网络加速器简述2021-05-27 1136
-
firefly神经网络硬件加速简介2019-11-01 2941
-
Firefly-RK3399 Android8.1固件,可调用神经网络API进行硬件加速2018-07-31 4829
全部0条评论

快来发表一下你的评论吧 !
