

Linux内核之伙伴分配器
描述
目录
3.7 伙伴分配器
3.7.1 基本的伙伴分配器3.7.2 分区的伙伴分配器
3.7.3 根据可移动性分组
3.7.4 每处理器页集合
3.7.5 分配页
3.7.6 释放页
3.7 伙伴分配器
内核初始化完毕后,使用页分配器管理物理页,当前使用的页分配器是伙伴分配器,伙伴分配器的特点是算法简单且效率高。
3.7.1 基本的伙伴分配器
连续的物理页称为页块(page block)。阶(order)是伙伴分配器的一个术语,是页的数量单位,2n个连续页称为 n 阶页块。满足以下条件的两个 n 阶页块称为伙伴(buddy)。
(1)两个页块是相邻的,即物理地址是连续的。
(2)页块的第一页的物理页号必须是 2n的整数倍。
(3)如果合并成(n+1)阶页块,第一页的物理页号必须是 2n+1 的整数倍。
这是伙伴分配器(buddy allocator)这个名字的来源。以单页为例说明,0 号页和 1 号页是伙伴,2 号页和 3 号页是伙伴,1 号页和 2 号页不是伙伴,因为 1 号页和 2 号页合并组成一阶页块,第一页的物理页号不是 2 的整数倍。
伙伴分配器分配和释放物理页的数量单位是阶。分配 n 阶页块的过程如下。
(1)查看是否有空闲的 n 阶页块,如果有,直接分配;如果没有,继续执行下一步。
(2)查看是否存在空闲的(n+1)阶页块,如果有,把(n+1)阶页块分裂为两个 n 阶页块,一个插入空闲 n 阶页块链表,另一个分配出去;如果没有,继续执行下一步。
(3)查看是否存在空闲的(n+2)阶页块,如果有,把(n+2)阶页块分裂为两个(n+1)阶页块,一个插入空闲(n+1)阶页块链表,另一个分裂为两个 n 阶页块,一个插入空闲 n阶页块链表,另一个分配出去;如果没有,继续查看更高阶是否存在空闲页块。
释放 n 阶页块时,查看它的伙伴是否空闲,如果伙伴不空闲,那么把 n 阶页块插入空闲的 n 阶页块链表;如果伙伴空闲,那么合并为(n+1)阶页块,接下来释放(n+1)阶页块。
内核在基本的伙伴分配器的基础上做了一些扩展。
(1)支持内存节点和区域,称为分区的伙伴分配器(zoned buddy allocator)。
(2)为了预防内存碎片,把物理页根据可移动性分组。
(3)针对分配单页做了性能优化,为了减少处理器之间的锁竞争,在内存区域增加 1个每处理器页集合。
3.7.2 分区的伙伴分配器
1.数据结构
分区的伙伴分配器专注于某个内存节点的某个区域。内存区域的结构体成员 free_area 用来维护空闲页块,数组下标对应页块的阶数。结构体 free_area 的成员 free_list 是空闲页块的链表(暂且忽略它是一个数组,3.7.3 节将介绍),nr_free 是空闲页块的数量。内存区域的结构体成员 managed_pages 是伙伴分配器管理的物理页的数量,不包括引导内存分配器分配的物理页。
include/linux/mmzone.hstruct zone {…/* 不同长度的空闲区域 */struct free_area free_area[MAX_ORDER];…unsigned long managed_pages;…} ____cacheline_internodealigned_in_smp;struct free_area {struct list_head free_list[MIGRATE_TYPES];unsigned long nr_free;};
MAX_ORDER 是最大阶数,实际上是可分配的最大阶数加 1,默认值是 11,意味着伙伴分配器一次最多可以分配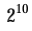 页。可以使用配置宏 CONFIG_FORCE_MAX_ZONEORDER指定最大阶数。
页。可以使用配置宏 CONFIG_FORCE_MAX_ZONEORDER指定最大阶数。
include/linux/mmzone.h/* 空闲内存管理-分区的伙伴分配器 */
2.根据分配标志得到首选区域类型
申请页时,最低的 4 个标志位用来指定首选的内存区域类型:
include/linux/gfp.h
标志组合和首选的内存区域类型的对应关系如表 3.5 所示。
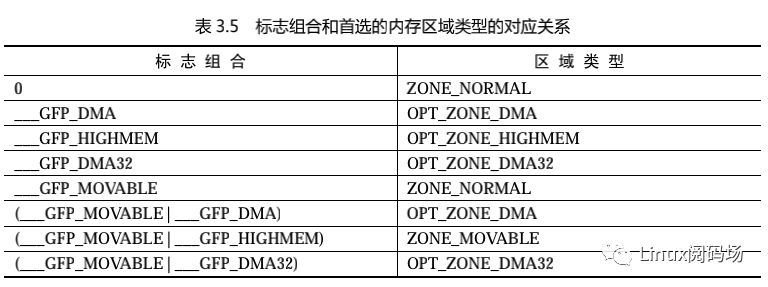
为什么要使用 OPT_ZONE_DMA,而不使用 ZONE_DMA?
因为 DMA 区域是可选的,如果不存在只能访问 16MB 以下物理内存的外围设备,那么不需要定义 DMA 区域,OPT_ZONE_DMA 就是 ZONE_NORMAL,从普通区域申请页。高端内存区域和 DMA32 区域也是可选的。
include/linux/gfp.h
内核使用宏 GFP_ZONE_TABLE 定义了标志组合到区域类型的映射表,其中 GFP_ZONES_SHIFT 是区域类型占用的位数,GFP_ZONE_TABLE 把每种标志组合映射到 32 位整数的某个位置,偏移是(标志组合 * 区域类型位数),从这个偏移开始的 GFP_ZONES_SHIFT 个二进制位存放区域类型。宏 GFP_ZONE_TABLE 是一个常量,编译器在编译时会进行优化,直接计算出结果,不会等到运行程序的时候才计算数值。
include/linux/gfp.h#define GFP_ZONE_TABLE ((ZONE_NORMAL << 0 * GFP_ZONES_SHIFT)| (OPT_ZONE_DMA << ___GFP_DMA * GFP_ZONES_SHIFT)| (OPT_ZONE_HIGHMEM << ___GFP_HIGHMEM * GFP_ZONES_SHIFT)| (OPT_ZONE_DMA32 << ___GFP_DMA32 * GFP_ZONES_SHIFT)| (ZONE_NORMAL << ___GFP_MOVABLE * GFP_ZONES_SHIFT)| (OPT_ZONE_DMA << (___GFP_MOVABLE | ___GFP_DMA) * GFP_ZONES_SHIFT)| (ZONE_MOVABLE << (___GFP_MOVABLE | ___GFP_HIGHMEM) * GFP_ZONES_SHIFT)| (OPT_ZONE_DMA32 << (___GFP_MOVABLE | ___GFP_DMA32) * GFP_ZONES_SHIFT))
内核使用函数 gfp_zone()根据分配标志得到首选的区域类型:先分离出区域标志位,然后算出在映射表中的偏移(区域标志位 * 区域类型位数),接着把映射表右移偏移值,最后取出最低的区域类型位数。
include/linux/gfp.hstatic inline enum zone_type gfp_zone(gfp_t flags){enum zone_type z;int bit = (__force int) (flags & GFP_ZONEMASK);z = (GFP_ZONE_TABLE >> (bit * GFP_ZONES_SHIFT)) &((1 << GFP_ZONES_SHIFT) - 1);VM_BUG_ON((GFP_ZONE_BAD >> bit) & 1);return z;}
3.备用区域列表
如果首选的内存节点和区域不能满足页分配请求,可以从备用的内存区域借用物理页,借用必须遵守以下原则。
(1)一个内存节点的某个区域类型可以从另一个内存节点的相同区域类型借用物理页,例如节点 0 的普通区域可以从节点 1 的普通区域借用物理页。
(2)高区域类型可以从低区域类型借用物理页,例如普通区域可以从 DMA 区域借用物理页。
(3)低区域类型不能从高区域类型借用物理页,例如 DMA 区域不能从普通区域借用物理页。
内存节点的 pg_data_t 实例定义了备用区域列表,其代码如下:
include/linux/mmzone.htypedef struct pglist_data {…struct zonelist node_zonelists[MAX_ZONELISTS];/* 备用区域列表 */…} pg_data_t;enum {ZONELIST_FALLBACK, /* 包含所有内存节点的备用区域列表 */ZONELIST_NOFALLBACK, /* 只包含当前内存节点的备用区域列表(__GFP_THISNODE) */MAX_ZONELISTS};struct zonelist {struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];};struct zoneref {struct zone *zone; /* 指向内存区域的数据结构 */int zone_idx; /* 成员zone指向的内存区域的类型 */};
UMA 系统只有一个备用区域列表,按区域类型从高到低排序。假设 UMA 系统包含通区域和 DMA 区域,那么备用区域列表是:{普通区域,DMA 区域}。
NUMA 系统的每个内存节点有两个备用区域列表:一个包含所有内存节点的区域,另一个只包含当前内存节点的区域。如果申请页时指定标志__GFP_THISNODE,要求只能从指定内存节点分配物理页,就需要使用指定内存节点的第二个备用区域列表。
包含所有内存节点的备用区域列表有两种排序方法。
(1)节点优先顺序:先根据节点距离从小到大排序,然后在每个节点里面根据区域类型从高到低排序。
(2)区域优先顺序:先根据区域类型从高到低排序,然后在每个区域类型里面根据节点距离从小到大排序。
节点优先顺序的优点是优先选择距离近的内存,缺点是在高区域耗尽以前就使用低区域,例如 DMA 区域一般比较小,节点优先顺序会增大 DMA 区域耗尽的概率。区域优先顺序的优点是减小低区域耗尽的概率,缺点是不能保证优先选择距离近的内存。默认的排序方法是自动选择最优的排序方法:如果是 64 位系统,因为需要 DMA 和DMA32 区域的设备相对少,所以选择节点优先顺序;如果是 32 位系统,选择区域优先顺序。
可以使用内核参数“numa_zonelist_order”指定排序方法:“d”表示默认排序方法,“n”表示节点优先顺序,“z”表示区域优先顺序,大小写字母都可以。在运行中可以使用文件“/proc/sys/vm/numa_zonelist_order”修改排序方法。
假设 NUMA 系统包含节点 0 和 1,节点 0 包含普通区域和 DMA 区域,节点 1 只包含普通区域。
如果选择节点优先顺序,两个节点的备用区域列表如图 3.17 所示。

图3.17 节点优先顺序的备用区域列表
如果节点 0 的处理器申请普通区域的物理页,应该依次尝试节点 0 的普通区域、节点0 的 DMA 区域和节点 1 的普通区域。如果节点 0 的处理器申请 DMA 区域的物理页,首选区域是节点 0 的 DMA 区域,备用区域列表没有其他 DMA 区域可以选择。
如果选择区域优先顺序,两个节点的备用区域列表如图 3.18 所示。

图3.18 区域优先顺序的备用区域列表
如果节点 0 的处理器申请普通区域的物理页,应该依次尝试节点 0 的普通区域、节点1 的普通区域和节点 0 的 DMA 区域。如果节点 0 的处理器申请 DMA 区域的物理页,首选区域是节点 0 的 DMA 区域,备用区域列表没有其他 DMA 区域可以选择。
4.区域水线
首选的内存区域在什么情况下从备用区域借用物理页?这个问题要从区域水线开始说起。每个内存区域有 3 个水线。
(1)高水线(high):如果内存区域的空闲页数大于高水线,说明该内存区域的内存充足。
(2)低水线(low):如果内存区域的空闲页数小于低水线,说明该内存区域的内存轻微不足。
(3)最低水线(min):如果内存区域的空闲页数小于最低水线,说明该内存区域的内存严重不足。
include/linux/mmzone.henum zone_watermarks {WMARK_MIN,WMARK_LOW,WMARK_HIGH,NR_WMARK};struct zone {…/* 区域水线,使用*_wmark_pages(zone) 宏访问 */unsigned long watermark[NR_WMARK];…} ____cacheline_internodealigned_in_smp;
最低水线以下的内存称为紧急保留内存,在内存严重不足的紧急情况下,给承诺“给我少量紧急保留内存使用,我可以释放更多的内存”的进程使用。
设置了进程标志位PF_MEMALLOC 的进程可以使用紧急保留内存,标志位PF_MEMALLOC表示承诺“给我少量紧急保留内存使用,我可以释放更多的内存”。内存管理子系统以外的子系统不应该使用这个标志位,典型的例子是页回收内核线程 kswapd,在回收页的过程中可能需要申请内存。
如果申请页时设置了标志位__GFP_MEMALLOC,即调用者承诺“给我少量紧急保留内存使用,我可以释放更多的内存”,那么可以使用紧急保留内存。
申请页时,第一次尝试使用低水线,如果首选的内存区域的空闲页数小于低水线,就从备用的内存区域借用物理页。如果第一次分配失败,那么唤醒所有目标内存节点的页回收内核线程 kswapd 以异步回收页,然后尝试使用最低水线。如果首选的内存区域的空闲页数小于最低水线,就从备用的内存区域借用物理页。
计算水线时,有两个重要的参数。
(1)min_free_kbytes 是最小空闲字节数。默认值 =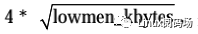
,并且限制在范围[128,65536]以内。其中 lowmem_kbytes 是低端内存大小,单位是 KB。参考文件“mm/page_alloc.c”中的函数 init_per_zone_wmark_min。可以通过文件“/proc/sys/vm/min_free_kbytes”设置最小空闲字节数。
(2)watermark_scale_factor 是水线缩放因子。默认值是 10,可以通过文件“/proc/sys/vm/watermark_scale_factor”修改水线缩放因子,取值范围是[1,1000]。
文件“mm/page_alloc.c”中的函数__setup_per_zone_wmarks()负责计算每个内存区域的最低水线、低水线和高水线。
计算最低水线的方法如下。
(1)min_free_pages = min_free_kbytes 对应的页数。
(2)lowmem_pages = 所有低端内存区域中伙伴分配器管理的页数总和。
(3)高端内存区域的最低水线 = zone->managed_pages/1024,并且限制在范围[32, 128]以内(zone->managed_pages 是该内存区域中伙伴分配器管理的页数,在内核初始化的过程中引导内存分配器分配出去的物理页,不受伙伴分配器管理)。
(4)低端内存区域的最低水线 = min_free_pages * zone->managed_pages / lowmem_pages,即把 min_free_pages 按比例分配到每个低端内存区域。
计算低水线和高水线的方法如下。
(1)增量 = (最低水线 / 4, zone->managed_pages * watermark_scale_factor / 10000)取最大值。
(2)低水线 = 最低水线 + 增量。
(3)高水线 = 最低水线 + 增量 * 2。
如果(最低水线 / 4)比较大,那么计算公式简化如下。
(1)低水线 = 最低水线 * 5/4。
(2)高水线 = 最低水线 * 3/2。
5.防止过度借用
和高区域类型相比,低区域类型的内存相对少,是稀缺资源,而且有特殊用途,例如DMA 区域用于外围设备和内存之间的数据传输。为了防止高区域类型过度借用低区域类型的物理页,低区域类型需要采取防卫措施,保留一定数量的物理页。
一个内存节点的某个区域类型从另一个内存节点的相同区域类型借用物理页,后者应该毫无保留地借用。
内存区域有一个数组用于存放保留页数:
include/linux/mmzone.hstruct zone {…long lowmem_reserve[MAX_NR_ZONES];…} ____cacheline_internodealigned_in_smp;
zone[i]->lowmem_reserve[j]表示区域类型 i 应该保留多少页不能借给区域类型 j,仅当 j大于 i 时有意义。
zone[i]->lowmem_reserve[j]的计算规则如下:
(i < j):lowmem_reserve[j]= (当前内存节点上从zone[i + 1] 到zone[j]伙伴分配器管理的页数总和)157第 3 章 内存管理/ sysctl_lowmem_reserve_ratio[i](i = j):lowmem_reserve[j]= 0(相同的区域类型不应该保留)(i > j):lowmem_reserve[j]= 0(没意义,不会出现低区域类型从高区域类型借用物理页的情况)
数组 sysctl_lowmem_reserve_ratio 存放各种区域类型的保留比例,因为内核不允许使用浮点数,所以使用倒数值。DMA 区域和 DMA32 区域的默认保留比例都是 256,普通区域和高端内存区域的默认保留比例都是 32。
mm/page_alloc.cint sysctl_lowmem_reserve_ratio[MAX_NR_ZONES-1] = {256,256,32,32,};
可以通过文件“/proc/sys/vm/lowmem_reserve_ratio”修改各种区域类型的保留比例。
3.7.3 根据可移动性分组
在系统长时间运行后,物理内存可能出现很多碎片,可用物理页很多,但是最大的连续物理内存可能只有一页。内存碎片对用户程序不是问题,因为用户程序可以通过页表把连续的虚拟页映射到不连续的物理页。但是内存碎片对内核是一个问题,因为内核使用直接映射的虚拟地址空间,连续的虚拟页必须映射到连续的物理页。内存碎片是伙伴分配器的一个弱点。
为了预防内存碎片,内核根据可移动性把物理页分为 3 种类型。
(1)不可移动页:位置必须固定,不能移动,直接映射到内核虚拟地址空间的页属于这一类。
(2)可移动页:使用页表映射的页属于这一类,可以移动到其他位置,然后修改页表映射。
(3)可回收页:不能移动,但可以回收,需要数据的时候可以重新从数据源获取。后备存储设备支持的页属于这一类。
内核把具有相同可移动性的页分组。为什么这种方法可以减少碎片?试想:如果不可移动页出现在可移动内存区域的中间,会阻止可移动内存区域合并。这种方法把不可移动页聚集在一起,可以防止不可移动页出现在可移动内存区域的中间。
内核定义了以下迁移类型:
include/linux/mmzone.henum migratetype {MIGRATE_UNMOVABLE, /* 不可移动 */MIGRATE_MOVABLE, /* 可移动 */MIGRATE_RECLAIMABLE, /* 可回收 */MIGRATE_PCPTYPES, /* 定义内存区域的每处理器页集合中链表的数量 */MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,/* 高阶原子分配,即阶数大于0,并且分配页时不能睡眠等待 */MIGRATE_CMA, /* 连续内存分配器 */MIGRATE_ISOLATE, /* 隔离,不能从这里分配 */MIGRATE_TYPES};
前面 3 种是真正的迁移类型,后面的迁移类型都有特殊用途:MIGRATE_HIGHATOMIC用于高阶原子分配(参考 3.7.5 节的“对高阶原子分配的优化处理”),MIGRATE_CMA 用于连续内存分配器(参考 3.20 节),MIGRATE_ISOLATE 用来隔离物理页(由连续内存分配器、内存热插拔和从内存硬件错误恢复等功能使用)。
对伙伴分配器的数据结构的主要调整是把空闲链表拆分成每种迁移类型一条空闲链表。
include/linux/mmzone.hstruct free_area {struct list_head free_list[MIGRATE_TYPES];unsigned long nr_free;};
只有当物理内存足够大且每种迁移类型有足够多的物理页时,根据可移动性分组才有意义。全局变量 page_group_by_mobility_disabled 表示是否禁用根据可移动性分组。
vm_total_pages 是所有内存区域里面高水线以上的物理页总数,pageblock_order 是按可移动性分组的阶数,pageblock_nr_pages 是 pageblock_order 对应的页数。如果所有内存区域里面高水线以上的物理页总数小于(pageblock_nr_pages * 迁移类型数量),那么禁用根据可移动性分组。
mm/page_alloc.cvoid __ref build_all_zonelists(pg_data_t *pgdat, struct zone *zone){…if (vm_total_pages < (pageblock_nr_pages * MIGRATE_TYPES))page_group_by_mobility_disabled = 1;elsepage_group_by_mobility_disabled = 0;…}
pageblock_order 是按可移动性分组的阶数,简称分组阶数,可以理解为一种迁移类型的一个页块的最小长度。如果内核支持巨型页,那么 pageblock_order 是巨型页的阶数,否则 pageblock_order 是伙伴分配器的最大分配阶。
include/linux/pageblock-flags.h/* 巨型页长度是可变的 */extern unsigned int pageblock_order;/* 巨型页长度是固定的 *//* 如果编译内核时没有开启巨型页,按伙伴分配器的最大分配阶分组 */
申请页时,可以使用标志__GFP_MOVABLE 指定申请可移动页,使用标志__GFP_RECLAIMABLE 指定申请可回收页,如果没有指定这两个标志,表示申请不可移动页。函数 gfpflags_to_migratetype 用来把分配标志转换成迁移类型:
include/linux/gfp.h/* 把分配标志转换成迁移类型 */static inline int gfpflags_to_migratetype(const gfp_t gfp_flags){…if (unlikely(page_group_by_mobility_disabled))return MIGRATE_UNMOVABLE;/* 根据可移动性分组 */return (gfp_flags & GFP_MOVABLE_MASK) >> GFP_MOVABLE_SHIFT;}
如果禁用根据可移动性分组,那么总是申请不可移动页。
申请某种迁移类型的页时,如果这种迁移类型的页用完了,可以从其他迁移类型盗用(steal)物理页。内核定义了每种迁移类型的备用类型优先级列表:
mm/page_alloc.cstatic int fallbacks[MIGRATE_TYPES][4] = {[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },#ifdef CONFIG_CMA[MIGRATE_CMA] = { MIGRATE_TYPES }, /* 从不使用 */#endif#ifdef CONFIG_MEMORY_ISOLATION[MIGRATE_ISOLATE] = { MIGRATE_TYPES }, /* 从不使用 */#endif};
不可移动类型的备用类型按优先级从高到低是:可回收类型和可移动类型。
可回收类型的备用类型按优先级从高到低是:不可移动类型和可移动类型。
可移动类型的备用类型按优先级从高到低是:可回收类型和不可移动类型。
如果需要从备用类型盗用物理页,那么从最大的页块开始盗用,以避免产生碎片。
mm/page_alloc.cstatic inline bool__rmqueue_fallback(struct zone *zone, unsigned int order, int start_migratetype){…/* 在备用类型的页块链表中查找最大的页块 */for (current_order = MAX_ORDER-1;current_order >= order && current_order <= MAX_ORDER-1;--current_order) {area = &(zone->free_area[current_order]);fallback_mt = find_suitable_fallback(area, current_order,start_migratetype, false, &can_steal);…}…}
释放物理页的时候,需要把物理页插入物理页所属迁移类型的空闲链表,内核怎么知道物理页的迁移类型?内存区域的 zone 结构体的成员 pageblock_flags 指向页块标志位图,页块的大小是分组阶数 pageblock_order,我们把这种页块称为分组页块。
include/linux/mmzone.hstruct zone {…/** 分组页块的标志参考文件pageblock-flags.h。* 如果使用稀疏内存模型,这个位图在结构体mem_section中。*/unsigned long *pageblock_flags;…} ____cacheline_internodealigned_in_smp;
每个分组页块在位图中占用 4 位,其中 3 位用来存放页块的迁移类型。
include/linux/pageblock-flags.h/* 影响一个页块的位索引 */enum pageblock_bits {PB_migrate,PB_migrate_end = PB_migrate + 3 - 1, /* 迁移类型需要3位 */PB_migrate_skip,/* 如果被设置,内存碎片整理跳过这个页块。*/NR_PAGEBLOCK_BITS};
函数 set_pageblock_migratetype()用来在页块标志位图中设置页块的迁移类型,函数get_pageblock_migratetype()用来获取页块的迁移类型。
内核在初始化时,把所有页块初始化为可移动类型,其他迁移类型的页是盗用产生的。
mm/page_alloc.cfree_area_init_core() -> free_area_init_core() -> memmap_init() -> memmap_init_zone()void __meminit memmap_init_zone(unsigned long size, int nid, unsigned long zone,unsigned long start_pfn, enum memmap_context context){…for (pfn = start_pfn; pfn < end_pfn; pfn++) {…if (!(pfn & (pageblock_nr_pages - 1))) { /* 如果是分组页块的第一页 */struct page *page = pfn_to_page(pfn);__init_single_page(page, pfn, zone, nid);set_pageblock_migratetype(page, MIGRATE_MOVABLE);} else {__init_single_pfn(pfn, zone, nid);}}}
可以通过文件“/proc/pagetypeinfo”查看各种迁移类型的页的分布情况。
3.7.4 每处理器页集合
内核针对分配单页做了性能优化,为了减少处理器之间的锁竞争,在内存区域增加 1个每处理器页集合。
include/linux/mmzone.hstruct zone {…struct per_cpu_pageset __percpu *pageset; /* 在每个处理器上有一个页集合 */…} ____cacheline_internodealigned_in_smp;struct per_cpu_pageset {struct per_cpu_pages pcp;…};struct per_cpu_pages {int count; /* 链表里面页的数量 */int high; /* 如果页的数量达到高水线,需要返还给伙伴分配器 */int batch; /* 批量添加或删除的页数量 */struct list_head lists[MIGRATE_PCPTYPES]; /* 每种迁移类型一个页链表 */};
内存区域在每个处理器上有一个页集合,页集合中每种迁移类型有一个页链表。页集合有高水线和批量值,页集合中的页数量不能超过高水线。申请单页加入页链表,或者从页链表返还给伙伴分配器,都是采用批量操作,一次操作的页数量是批量值。
默认的批量值 batch 的计算方法如下。
(1)batch = zone->managed_pages / 1024,其中 zone->managed_pages 是内存区域中由伙伴分配器管理的页数量。
(2)如果 batch 超过(512 * 1024) / PAGE_SIZE,那么把 batch 设置为(512 * 1024) / PAGE_SIZE,其中 PAGE_SIZE 是页长度。
(3)batch = batch / 4。
(4)如果 batch 小于 1,那么把 batch 设置为 1。
(5)batch = rounddown_pow_of_two(batch * 1.5) − 1,其中 rounddown_pow_of_two()用来把数值向下对齐到 2 的 n 次幂。
默认的高水线是批量值的 6 倍。
可以通过文件“/proc/sys/vm/percpu_pagelist_fraction”修改比例值,最小值是 8,默认值是 0。高水线等于(伙伴分配器管理的页数量 / 比例值),同时把批量值设置为高水线的1/4。
从某个内存区域申请某种迁移类型的单页时,从当前处理器的页集合中该迁移类型的页链表分配页,如果页链表是空的,先批量申请页加入页链表,然后分配一页。
缓存热页是指刚刚访问过物理页,物理页的数据还在处理器的缓存中。如果要申请缓存热页,从页链表首部分配页;如果要申请缓存冷页,从页链表尾部分配页。
释放单页时,把页加入当前处理器的页集合中。如果释放缓存热页,加入页链表首部;如果释放缓存冷页,加入页链表尾部。如果页集合中的页数量大于或等于高水线,那么批量返还给伙伴分配器。
3.7.5 分配页
1.分配接口
页分配器提供了以下分配页的接口。
(1)alloc_pages(gfp_mask, order)请求分配一个阶数为 order 的页块,返回一个 page 实例。
(2)alloc_page(gfp_mask)是函数 alloc_pages 在阶数为 0 情况下的简化形式,只分配一页。
(3)__get_free_pages(gfp_mask, order)对函数 alloc_pages 做了封装,只能从低端内存区域分配页,并且返回虚拟地址。
(4)__get_free_page(gfp_mask)是函数__get_free_pages 在阶数为 0 情况下的简化形式,只分配一页。
(5)get_zeroed_page(gfp_mask)是函数__get_free_pages 在为参数 gfp_mask 设置了标志位__GFP_ZERO 且阶数为 0 情况下的简化形式,只分配一页,并且用零初始化。
2.分配标志位
分配页的函数都带一个分配标志位参数,分配标志位分为以下 5 类(标志位名称中的GFP 是 Get Free Pages 的缩写)。
(1)区域修饰符:指定从哪个区域类型分配页,3.7.2 节已经描述了根据分配标志得到首选区域类型的方法。

(2)页移动性和位置提示:指定页的迁移类型和从哪些内存节点分配页。

(3)水线修饰符。

(4)回收修饰符。

(5)行动修饰符。

因为这些标志位总是组合使用,所以内核定义了一些标志位组合。常用的标志位组合如下。
(1)GFP_ATOMIC:原子分配,分配内核使用的页,不能睡眠。调用者是高优先级的,允许异步回收页。
(2)GFP_KERNEL:分配内核使用的页,可能睡眠。从低端内存区域分配页,允许异步回收页和直接回收页,允许读写存储设备,允许调用到底层文件系统。
(3)GFP_NOWAIT:分配内核使用的页,不能等待。允许异步回收页,不允许直接回收页,不允许读写存储设备,不允许调用到底层文件系统。
(4)GFP_NOIO:不允许读写存储设备,允许异步回收页和直接回收页。请尽量避免直接使用这个标志位,应该使用函数 memalloc_noio_save 和 memalloc_noio_restore 标记一个不能读写存储设备的范围,前者设置进程标志位 PF_MEMALLOC_NOIO,后者清除进程标志位 PF_MEMALLOC_NOIO。
(5)GFP_NOFS:不允许调用到底层文件系统,允许异步回收页和直接回收页,允许读写存储设备。请尽量避免直接使用这个标志位,应该使用函数 memalloc_nofs_save 和memalloc_nofs_restore 标记一个不能调用到文件系统的范围,前者设置进程标志位 PF_MEMALLOC_NOFS,后者清除进程标志位 PF_MEMALLOC_NOFS。
(6)GFP_USER:分配用户空间使用的页,内核或硬件也可以直接访问,从普通区域分配,允许异步回收页和直接回收页,允许读写存储设备,允许调用到文件系统,允许实施 cpuset 内存分配策略。
(7)GFP_HIGHUSER:分配用户空间使用的页,内核不需要直接访问,从高端内存区域分配,物理页在使用的过程中不可以移动。
(8)GFP_HIGHUSER_MOVABLE:分配用户空间使用的页,内核不需要直接访问,物理页可以通过页回收或页迁移技术移动。
(9)GFP_TRANSHUGE_LIGHT:分配用户空间使用的巨型页,把分配的页块组成复合页,禁止使用紧急保留内存,禁止打印警告信息,不允许异步回收页和直接回收页。
__GFP_NOMEMALLOC | __GFP_NOWARN) & ~__GFP_RECLAIM)
(10)GFP_TRANSHUGE:分配用户空间使用的巨型页,和 GFP_TRANSHUGE_LIGHT的区别是允许直接回收页。
3.复合页
如果设置了标志位__GFP_COMP 并且分配了一个阶数大于 0 的页块,页分配器会把页块组成复合页(compound page)。复合页最常见的用处是创建巨型页。
复合页的第一页叫首页(head page),其他页都叫尾页(tail page)。一个由 n 阶页块组成的复合页的结构如图 3.19 所示。

图3.19 复合页的结构
(1)首页设置标志 PG_head。
(2)第一个尾页的成员 compound_mapcount 表示复合页的映射计数,即多少个虚拟页映射到这个物理页,初始值是−1。这个成员和成员 mapping 组成一个联合体,占用相同的位置,其他尾页把成员 mapping 设置为一个有毒的地址。
(3)第一个尾页的成员 compound_dtor 存放复合页释放函数数组的索引,成员compound_order 存放复合页的阶数 n。这两个成员和成员 lru.prev 占用相同的位置。
(4)所有尾页的成员 compound_head 存放首页的地址,并且把最低位设置为 1。这个成员和成员 lru.next 占用相同的位置。
判断一个页是复合页的成员的方法是:页设置了标志位 PG_head(针对首页),或者页的成员 compound_head 的最低位是 1(针对尾页)。
结构体 page 中复合页的成员如下:
include/linux/mm_types.hstruct page {unsigned long flags;union {struct address_space *mapping;atomic_t compound_mapcount; /* 映射计数,第一个尾页 *//* page_deferred_list().next -- 第二个尾页 */};…union {struct list_head lru;/* 复合页的尾页 */struct {unsigned long compound_head; /* 首页的地址,并且设置最低位 *//* 第一个尾页 */unsigned int compound_dtor; /* 复合页释放函数数组的索引 */unsigned int compound_order; /* 复合页的阶数 */unsigned short int compound_dtor;unsigned short int compound_order;};};…};
4.对高阶原子分配的优化处理
高阶原子分配:阶数大于 0,并且调用者设置了分配标志位__GFP_ATOMIC,要求不能睡眠。
页分配器对高阶原子分配做了优化处理,增加了高阶原子类型(MIGRATE_HIGHATOMIC),在内存区域的结构体中增加 1 个成员“nr_reserved_highatomic”,用来记录高阶原子类型的总页数,并且限制其数量:
zone->nr_reserved_highatomic < (zone->managed_pages / 100) + pageblock_nr_pages,即必须小于(伙伴分配器管理的总页数 / 100 + 分组阶数对应的页数)。
include/linux/mmzone.hstruct zone {…unsigned long nr_reserved_highatomic;…} ____cacheline_internodealigned_in_smp;
执行高阶原子分配时,先从高阶原子类型分配页,如果分配失败,从调用者指定的迁移类型分配页。分配成功以后,如果内存区域中高阶原子类型的总页数小于限制,并且页块的迁移类型不是高阶原子类型、隔离类型和 CMA 迁移类型,那么把页块的迁移类型转换为高阶原子类型,并且把页块中没有分配出去的页移到高阶原子类型的空闲链表中。
当内存严重不足时,直接回收页以后仍然分配失败,针对高阶原子类型的页数超过pageblock_nr_pages 的目标区域,把高阶原子类型的页块转换成申请的迁移类型,然后重试分配,其代码如下:
mm/page_alloc.cstatic inline struct page *__alloc_pages_direct_reclaim(gfp_t gfp_mask, unsigned int order,unsigned int alloc_flags, const struct alloc_context *ac,unsigned long *did_some_progress){struct page *page = NULL;bool drained = false;*did_some_progress = __perform_reclaim(gfp_mask, order, ac);/* 直接回收页 */if (unlikely(!(*did_some_progress)))return NULL;retry:page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);if (!page && !drained) {/* 把高阶原子类型的页块转换成申请的迁移类型 */unreserve_highatomic_pageblock(ac, false);drain_all_pages(NULL);drained = true;goto retry;}return page;}
如果直接回收页没有进展超过 16 次,那么针对目标区域,不再为高阶原子分配保留页,把高阶原子类型的页块转换成申请的迁移类型,其代码如下:
mm/page_alloc.cstatic inline boolshould_reclaim_retry(gfp_t gfp_mask, unsigned order,struct alloc_context *ac, int alloc_flags,bool did_some_progress, int *no_progress_loops){…if (did_some_progress && order <= PAGE_ALLOC_COSTLY_ORDER)*no_progress_loops = 0;else(*no_progress_loops)++;if (*no_progress_loops > MAX_RECLAIM_RETRIES) {/* 在调用内存耗尽杀手之前,用完为高阶原子分配保留的页 */return unreserve_highatomic_pageblock(ac, true);}…}
5.核心函数的实现
所有分配页的函数最终都会调用到函数__alloc_pages_nodemask,这个函数被称为分区的伙伴分配器的心脏。函数原型如下:
struct page *__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,struct zonelist *zonelist, nodemask_t *nodemask);
参数如下。
(1)gfp_mask:分配标志位。
(2)order:阶数。
(3)zonelist:首选内存节点的备用区域列表。如果指定了标志位__GFP_THISNODE,选择 pg_data_t.node_zonelists[ZONELIST_NOFALLBACK],否则选择 pg_data_t.node_zonelists [ZONELIST_FALLBACK]。
(4)nodemask:允许从哪些内存节点分配页,如果调用者没有要求,可以传入空指针。
算法如下。
(1)根据分配标志位得到首选区域类型和迁移类型。
(2)执行快速路径,使用低水线尝试第一次分配。
(3)如果快速路径分配失败,那么执行慢速路径。
页分配器定义了以下内部分配标志位:
mm/internal.h
(1)快速路径。快速路径调用函数 get_page_from_freelist,函数的代码如下:
mm/page_alloc.c1 static struct page *2 get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,3 const struct alloc_context *ac)4 {5 struct zoneref *z = ac->preferred_zoneref;6 struct zone *zone;7 struct pglist_data *last_pgdat_dirty_limit = NULL;89 for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx,10 ac->nodemask) {11 struct page *page;12 unsigned long mark;1314 if (cpusets_enabled() &&15 (alloc_flags & ALLOC_CPUSET) &&16 !__cpuset_zone_allowed(zone, gfp_mask))17 continue;1819 if (ac->spread_dirty_pages) {20 if (last_pgdat_dirty_limit == zone->zone_pgdat)21 continue;2223 if (!node_dirty_ok(zone->zone_pgdat)) {24 last_pgdat_dirty_limit = zone->zone_pgdat;25 continue;26 }27 }2829 mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];30 if (!zone_watermark_fast(zone, order, mark,31 ac_classzone_idx(ac), alloc_flags)) {32 int ret;3334 BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);35 if (alloc_flags & ALLOC_NO_WATERMARKS)36 goto try_this_zone;3738 if (node_reclaim_mode == 0 ||39 !zone_allows_reclaim(ac->preferred_zoneref->zone, zone))40 continue;4142 ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);43 switch (ret) {44 case NODE_RECLAIM_NOSCAN:16917045 /* 没有扫描 */46 continue;47 case NODE_RECLAIM_FULL:48 /* 扫描过但是不可回收 */49 continue;50 default:51 /* 回收了足够的页,重新检查水线 */52 if (zone_watermark_ok(zone, order, mark,53 ac_classzone_idx(ac), alloc_flags))54 goto try_this_zone;5556 continue;57 }58 }5960 try_this_zone:61 page = rmqueue(ac->preferred_zoneref->zone, zone, order,62 gfp_mask, alloc_flags, ac->migratetype);63 if (page) {64 prep_new_page(page, order, gfp_mask, alloc_flags);6566 /* 如果这是一个高阶原子分配,那么检查这个页块是否应该被保留 */67 if (unlikely(order && (alloc_flags & ALLOC_HARDER)))68 reserve_highatomic_pageblock(page, zone, order);6970 return page;71 }72 }7374 return NULL;75 }
第 9 行代码,扫描备用区域列表中每个满足条件的区域:“区域类型小于或等于首选区域类型,并且内存节点在节点掩码中的相应位被设置”,处理如下。
1)第 14~17 行代码,如果编译了 cpuset 功能,调用者设置 ALLOC_CPUSET 要求使用 cpuset 检查,并且 cpuset 不允许当前进程从这个内存节点分配页,那么不能从这个区域分配页。
2)第 19~27 行代码,如果调用者设置标志位__GFP_WRITE,表示文件系统申请分配一个页缓存页用于写文件,那么检查内存节点的脏页数量是否超过限制。如果超过限制,那么不能从这个区域分配页。
3)第 30 行代码,检查水线,如果(区域的空闲页数− 申请的页数)小于水线,处理如下。
- 第 35 行代码,如果调用者要求不检查水线,那么可以从这个区域分配页。
- 第 38~40 行代码,如果没有开启节点回收功能,或者当前节点和首选节点之间的距离大于回收距离,那么不能从这个区域分配页。
- 第 42~57 行代码,从节点回收没有映射到进程虚拟地址空间的文件页和块分配器申请的页,然后重新检查水线,如果(区域的空闲页数 − 申请的页数)还是小于水线,那么不能从这个区域分配页。
4)第 61 行代码,从当前区域分配页。
5)第 64~68 行代码,如果分配成功,调用函数 prep_new_page 以初始化页。如果是高阶原子分配,并且区域中高阶原子类型的页数没有超过限制,那么把分配的页所属的页块转换为高阶原子类型。
函数 zone_watermark_fast 负责检查区域的空闲页数是否大于水线,其代码如下:
mm/page_alloc.c1 static inline bool zone_watermark_fast(struct zone *z, unsigned int order,2 unsigned long mark, int classzone_idx, unsigned int alloc_flags)3 {4 long free_pages = zone_page_state(z, NR_FREE_PAGES);5 long cma_pages = 0;678 if (!(alloc_flags & ALLOC_CMA))9 cma_pages = zone_page_state(z, NR_FREE_CMA_PAGES);101112 /* 只快速检查0阶 */13 if (!order && (free_pages - cma_pages) > mark + z->lowmem_reserve[classzone_idx])14 return true;1516 return __zone_watermark_ok(z, order, mark, classzone_idx, alloc_flags,17 free_pages);18 }
第 7~14 行代码,针对 0 阶执行快速检查。
1)第 8 行和第 9 行代码,如果不允许从 CMA 迁移类型分配,那么不要使用空闲的CMA 页,必须把空闲页数减去空闲的 CMA 页数。
2)第 13 行代码,如果空闲页数大于(水线 + 低端内存保留页数),即(空闲页数 − 申请的一页)大于等于(水线 + 低端内存保留页数),那么允许从这个区域分配页。
第 16 行代码,如果是其他情况,那么调用函数__zone_watermark_ok 进行检查。
函数__zone_watermark_ok 更加仔细地检查区域的空闲页数是否大于水线,其代码如下:
mm/page_alloc.c1 bool __zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,2 int classzone_idx, unsigned int alloc_flags,3 long free_pages)4 {5 long min = mark;6 int o;7 const bool alloc_harder = (alloc_flags & ALLOC_HARDER);89 free_pages -= (1 << order) - 1;1011 if (alloc_flags & ALLOC_HIGH)12 min -= min / 2;1314 /* 如果调用者没有要求更努力分配,那么减去为高阶原子分配保留的页数 */15 if (likely(!alloc_harder))16 free_pages -= z->nr_reserved_highatomic;17 else18 min -= min / 4;192021 if (!(alloc_flags & ALLOC_CMA))22 free_pages -= zone_page_state(z, NR_FREE_CMA_PAGES);232425 if (free_pages <= min + z->lowmem_reserve[classzone_idx])26 return false;2728 if (!order)29 return true;3031 /* 对于高阶请求,检查至少有一个合适的页块是空闲的 */32 for (o = order; o < MAX_ORDER; o++) {33 struct free_area *area = &z->free_area[o];34 int mt;3536 if (!area->nr_free)37 continue;3839 if (alloc_harder)40 return true;4142 for (mt = 0; mt < MIGRATE_PCPTYPES; mt++) {43 if (!list_empty(&area->free_list[mt]))44 return true;45 }464748 if ((alloc_flags & ALLOC_CMA) &&49 !list_empty(&area->free_list[MIGRATE_CMA])) {50 return true;51 }5253 }54 return false;55 }
第 9 行代码,把空闲页数减去申请页数,然后减 1。
第 12 行代码,如果调用者是高优先级的,把水线减半。
第 15~18 行代码,如果调用者要求更努力分配,把水线减去 1/4;如果调用者没有要求更努力分配,把空闲页数减去高阶原子类型的页数。
第 21~22 行代码,如果不允许从 CMA 迁移类型分配,那么不能使用空闲的 CMA 页,把空闲页数减去空闲的 CMA 页数。
第 25 行代码,如果(空闲页数 − 申请页数 + 1)小于或等于(水线 + 低端内存保留页数),即(空闲页数 − 申请页数)小于(水线 + 低端内存保留页数),那么不能从这个区域分配页。
第 28 行代码,如果只申请一页,那么允许从这个区域分配页。
第 32~53 行代码,如果申请阶数大于 0,检查过程如下。
1)第 39 行代码,如果调用者要求更努力分配,只要有一个阶数大于或等于申请阶数的空闲页块,就允许从这个区域分配页。
2)第 42~45 行代码,不可移动、可移动和可回收任何一种迁移类型,只要有一个阶数大于或等于申请阶数的空闲页块,就允许从这个区域分配页。
3)第 48~51 行代码,如果调用者指定从 CMA 迁移类型分配,CMA 迁移类型只要有一个阶数大于或等于申请阶数的空闲页块,就允许从这个区域分配页。
4)其他情况不允许从这个区域分配页。
函数 rmqueue 负责分配页,其代码如下:
mm/page_alloc.c1 static inline2 struct page *rmqueue(struct zone *preferred_zone,3 struct zone *zone, unsigned int order,4 gfp_t gfp_flags, unsigned int alloc_flags,5 int migratetype)6 {7 unsigned long flags;8 struct page *page;910 if (likely(order == 0)) {11 page = rmqueue_pcplist(preferred_zone, zone, order,12 gfp_flags, migratetype);13 goto out;14 }1516 /* 如果申请阶数大于1,不要试图无限次重试。*/17 WARN_ON_ONCE((gfp_flags & __GFP_NOFAIL) && (order > 1));18 spin_lock_irqsave(&zone->lock, flags);1920 do {21 page = NULL;22 if (alloc_flags & ALLOC_HARDER) {23 page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);24 …25 }26 if (!page)27 page = __rmqueue(zone, order, migratetype);28 } while (page && check_new_pages(page, order));29 spin_unlock(&zone->lock);30 if (!page)31 goto failed;32 …33 local_irq_restore(flags);3435 out:36 VM_BUG_ON_PAGE(page && bad_range(zone, page), page);37 return page;3839 failed:40 local_irq_restore(flags);41 return NULL;42 }
第 10~14 行代码,如果申请阶数是 0,那么从每处理器页集合分配页。
如果申请阶数大于 0,处理过程如下。
1)第 22 行和第 23 行代码,如果调用者要求更努力分配,先尝试从高阶原子类型分配页。
2)第 27 行代码,从指定迁移类型分配页。
函数 rmqueue_pcplist 负责从内存区域的每处理器页集合分配页,把主要工作委托给函数__rmqueue_pcplist。函数__rmqueue_pcplist 的代码如下:
mm/page_alloc.c1 static struct page *__rmqueue_pcplist(struct zone *zone, int migratetype,2 bool cold, struct per_cpu_pages *pcp,3 struct list_head *list)4 {5 struct page *page;67 do {8 if (list_empty(list)) {9 pcp->count += rmqueue_bulk(zone, 0,10 pcp->batch, list,11 migratetype, cold);12 if (unlikely(list_empty(list)))13 return NULL;14 }1516 if (cold)17 page = list_last_entry(list, struct page, lru);18 else19 page = list_first_entry(list, struct page, lru);2021 list_del(&page->lru);22 pcp->count--;23 } while (check_new_pcp(page));2425 return page;26 }
第 8~11 行代码,如果每处理器页集合中指定迁移类型的链表是空的,那么批量申请页加入链表。
第 16~19 行代码,分配一页,如果调用者指定标志位__GFP_COLD 要求分配缓存冷页,就从链表尾部分配一页,否则从链表首部分配一页。
函数__rmqueue 的处理过程如下。
1)从指定迁移类型分配页,如果分配成功,那么处理结束。
2)如果指定迁移类型是可移动类型,那么从 CMA 类型盗用页。
3)从备用迁移类型盗用页。
mm/page_alloc.cstatic struct page *__rmqueue(struct zone *zone, unsigned int order,int migratetype){struct page *page;retry:page = __rmqueue_smallest(zone, order, migratetype);if (unlikely(!page)) {if (migratetype == MIGRATE_MOVABLE)page = __rmqueue_cma_fallback(zone, order);if (!page && __rmqueue_fallback(zone, order, migratetype))goto retry;}…return page;}
函数__rmqueue_smallest 从申请阶数到最大分配阶数逐个尝试:如果指定迁移类型的空闲链表不是空的,从链表取出第一个页块;如果页块阶数比申请阶数大,那么重复分裂页块,把后一半插入低一阶的空闲链表,直到获得一个大小为申请阶数的页块。
mm/page_alloc.cstatic inlinestruct page *__rmqueue_smallest(struct zone *zone, unsigned int order,int migratetype){unsigned int current_order;struct free_area *area;struct page *page;/* 在首选迁移类型的空闲链表中查找长度合适的页块 */for (current_order = order; current_order < MAX_ORDER; ++current_order) {area = &(zone->free_area[current_order]);page = list_first_entry_or_null(&area->free_list[migratetype],struct page, lru);if (!page)continue;list_del(&page->lru);rmv_page_order(page);area->nr_free--;expand(zone, page, order, current_order, area, migratetype);set_pcppage_migratetype(page, migratetype);return page;}return NULL;}
函数__rmqueue_fallback 负责从备用迁移类型盗用页,从最大分配阶向下到申请阶数逐个尝试,依次查看备用类型优先级列表中的每种迁移类型是否有空闲页块,如果有,就从这种迁移类型盗用页。
mm/page_alloc.cstatic inline bool__rmqueue_fallback(struct zone *zone, unsigned int order, int start_migratetype){struct free_area *area;unsigned int current_order;struct page *page;int fallback_mt;bool can_steal;/* 在备用迁移类型的空闲链表中找到最大的页块 */for (current_order = MAX_ORDER-1;current_order >= order && current_order <= MAX_ORDER-1;--current_order) {area = &(zone->free_area[current_order]);fallback_mt = find_suitable_fallback(area, current_order,start_migratetype, false, &can_steal);if (fallback_mt == -1)continue;page = list_first_entry(&area->free_list[fallback_mt],struct page, lru);steal_suitable_fallback(zone, page, start_migratetype,can_steal);...return true;}return false;}
(2)慢速路径。如果使用低水线分配失败,那么执行慢速路径,慢速路径是在函数__alloc_pages_slowpath 中实现的,执行流程如图 3.20 所示,主要步骤如下。
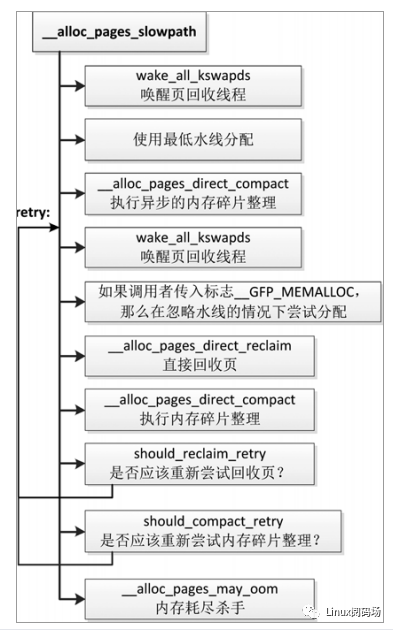
图3.20 慢速路径
1)如果允许异步回收页,那么针对每个目标区域,唤醒区域所属内存节点的页回收线程。
2)使用最低水线尝试分配。
3)针对申请阶数大于 0:如果允许直接回收页,那么执行异步模式的内存碎片整理,然后尝试分配。
4)如果调用者承诺“给我少量紧急保留内存使用,我可以释放更多的内存”,那么在忽略水线的情况下尝试分配。
5)直接回收页,然后尝试分配。
6)针对申请阶数大于 0:执行同步模式的内存碎片整理,然后尝试分配。
7)如果多次尝试直接回收页和同步模式的内存碎片整理,仍然分配失败,那么使用杀伤力比较大的内存耗尽杀手选择一个进程杀死,然后尝试分配。
页分配器认为阶数大于 3 是昂贵的分配,有些地方做了特殊处理。
函数__alloc_pages_slowpath 的主要代码如下:
mm/page_alloc.cstatic inline struct page *__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,struct alloc_context *ac){bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM;const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER;struct page *page = NULL;unsigned int alloc_flags;unsigned long did_some_progress;enum compact_priority compact_priority;enum compact_result compact_result;int compaction_retries;int no_progress_loops;unsigned long alloc_start = jiffies;unsigned int stall_timeout = 10 * HZ;unsigned int cpuset_mems_cookie;/* 申请阶数不能超过页分配器支持的最大分配阶 */if (order >= MAX_ORDER) {WARN_ON_ONCE(!(gfp_mask & __GFP_NOWARN));return NULL;}...retry_cpuset:compaction_retries = 0;no_progress_loops = 0;compact_priority = DEF_COMPACT_PRIORITY;/** 后面可能检查cpuset是否允许当前进程从哪些内存节点申请页,* 需要读当前进程的成员mems_allowed。使用顺序锁保护*/cpuset_mems_cookie = read_mems_allowed_begin();/* 把分配标志位转换成内部分配标志位 */alloc_flags = gfp_to_alloc_flags(gfp_mask);/* 获取首选的内存区域 */ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,ac->high_zoneidx, ac->nodemask);if (!ac->preferred_zoneref->zone)goto nopage;/* 异步回收页,唤醒页回收线程 */if (gfp_mask & __GFP_KSWAPD_RECLAIM)wake_all_kswapds(order, ac);/* 使用最低水线分配页 */page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);if (page)goto got_pg;/** 针对申请阶数大于0,如果满足以下3个条件。* (1)允许直接回收页。* (2)申请阶数大于3,或者指定迁移类型不是可移动类型。177 第 3 章 内存管理* (3)调用者没有承诺“给我少量紧急保留内存使用,我可以释放更多的内存”。* 那么执行异步模式的内存碎片整理*/if (can_direct_reclaim &&(costly_order ||(order > 0 && ac->migratetype != MIGRATE_MOVABLE))&& !gfp_pfmemalloc_allowed(gfp_mask)) {page = __alloc_pages_direct_compact(gfp_mask, order,alloc_flags, ac,INIT_COMPACT_PRIORITY,&compact_result);if (page)goto got_pg;/* 申请阶数大于3,并且调用者要求不要重试 */if (costly_order && (gfp_mask & __GFP_NORETRY)) {/** 同步模式的内存碎片整理最近失败了,所以内存碎片整理被延迟执行,* 没必要继续尝试分配*/if (compact_result == COMPACT_DEFERRED)goto nopage;/** 同步模式的内存碎片整理代价太大,继续使用异步模式的* 内存碎片整理*/compact_priority = INIT_COMPACT_PRIORITY;}}retry:/* 确保页回收线程在我们循环的时候不会意外地睡眠 */if (gfp_mask & __GFP_KSWAPD_RECLAIM)wake_all_kswapds(order, ac);/** 如果调用者承诺“给我少量紧急保留内存使用,我可以释放更多的内存”,* 则忽略水线*/if (gfp_pfmemalloc_allowed(gfp_mask))alloc_flags = ALLOC_NO_WATERMARKS;/** 如果调用者没有要求使用cpuset,或者要求忽略水线,那么重新获取区域列表*/if (!(alloc_flags & ALLOC_CPUSET) || (alloc_flags & ALLOC_NO_WATERMARKS)) {ac->zonelist = node_zonelist(numa_node_id(), gfp_mask);ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,ac->high_zoneidx, ac->nodemask);}/* 使用可能调整过的区域列表和分配标志尝试 */page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);if (page)goto got_pg;/* 调用者不愿意等待,不允许直接回收页,那么放弃 */if (!can_direct_reclaim)goto nopage;…/** 直接回收页的时候给进程设置了标志位PF_MEMALLOC,在直接回收页的过程中* 可能申请页,为了防止直接回收递归,这里发现进程设置了标志位PF_MEMALLOC,* 立即放弃*/if (current->flags & PF_MEMALLOC)goto nopage;/* 直接回收页 */page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,&did_some_progress);if (page)goto got_pg;/* 针对申请阶数大于0,执行同步模式的内存碎片整理 */page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,compact_priority, &compact_result);if (page)goto got_pg;/* 如果调用者要求不要重试,那么放弃 */if (gfp_mask & __GFP_NORETRY)goto nopage;/* 如果申请阶数大于3,并且调用者没有要求重试,那么放弃 */if (costly_order && !(gfp_mask & __GFP_REPEAT))goto nopage;/* 检查重新尝试回收页是否有意义 */if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags,did_some_progress > 0, &no_progress_loops))goto retry;/** 申请阶数大于0:判断是否应该重试内存碎片整理。* did_some_progress > 0表示直接回收页有进展。* 如果直接回收页没有进展,那么重试内存碎片整理没有意义,* 因为内存碎片整理的当前实现依赖足够多的空闲页*/if (did_some_progress > 0 &&should_compact_retry(ac, order, alloc_flags,compact_result, &compact_priority,&compaction_retries))goto retry;/* 如果cpuset修改了允许当前进程从哪些内存节点申请页,那么需要重试 */if (read_mems_allowed_retry(cpuset_mems_cookie))goto retry_cpuset;/* 使用内存耗尽杀手选择一个进程杀死 */page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);if (page)goto got_pg;/** 如果当前进程正在被内存耗尽杀手杀死,并且忽略水线或者不允许使用* 紧急保留内存,那么不要无限循环*/if (test_thread_flag(TIF_MEMDIE) &&(alloc_flags == ALLOC_NO_WATERMARKS ||(gfp_mask & __GFP_NOMEMALLOC)))goto nopage;/* 如果内存耗尽杀手取得进展,那么重试 */if (did_some_progress) {no_progress_loops = 0;goto retry;}nopage:/* 如果cpuset修改了允许当前进程从哪些内存节点申请页,那么需要重试 */if (read_mems_allowed_retry(cpuset_mems_cookie))goto retry_cpuset;/* 确保不能失败的请求没有漏掉,总是重试 */if (gfp_mask & __GFP_NOFAIL) {/* 同时要求不能失败和不能直接回收页,是错误用法 */if (WARN_ON_ONCE(!can_direct_reclaim))goto fail;…/** 先使用标志位ALLOC_HARDER|ALLOC_CPUSET尝试分配,* 如果分配失败,那么使用标志位ALLOC_HARDER尝试分配*/page = __alloc_pages_cpuset_fallback(gfp_mask, order, ALLOC_HARDER, ac);if (page)goto got_pg;cond_resched();goto retry;}fail:warn_alloc(gfp_mask, ac->nodemask,"page allocation failure: order:%u", order);got_pg:return page;}
页分配器使用函数 gfp_to_alloc_flags 把分配标志位转换成内部分配标志位,其代码如下:
mm/page_alloc.cstatic inline unsigned intgfp_to_alloc_flags(gfp_t gfp_mask){/* 使用最低水线,并且检查cpuset是否允许当前进程从某个内存节点分配页 */unsigned int alloc_flags = ALLOC_WMARK_MIN | ALLOC_CPUSET;/* 假设__GFP_HIGH和ALLOC_HIGH相同,为了节省一个if分支 */BUILD_BUG_ON(__GFP_HIGH != (__force gfp_t) ALLOC_HIGH);alloc_flags |= (__force int) (gfp_mask & __GFP_HIGH);if (gfp_mask & __GFP_ATOMIC) {/* 原子分配 *//** 原子分配:* 如果没有要求禁止使用紧急保留内存,那么需要更努力地分配。* 如果要求禁止使用紧急保留内存,那么不需要更努力地分配*/if (!(gfp_mask & __GFP_NOMEMALLOC))alloc_flags |= ALLOC_HARDER;/* 对于原子分配,忽略cpuset。*/alloc_flags &= ~ALLOC_CPUSET;} else if (unlikely(rt_task(current)) && !in_interrupt())/* 如果当前进程是实时进程,并且没有被中断抢占,那么需要更努力地分配 */alloc_flags |= ALLOC_HARDER;/* 可移动类型可以从CMA类型盗用页 */if (gfpflags_to_migratetype(gfp_mask) == MIGRATE_MOVABLE)alloc_flags |= ALLOC_CMA;return alloc_flags;}
3.7.6 释放页
页分配器提供了以下释放页的接口。
(1)void __free_pages(struct page *page, unsigned int order),第一个参数是第一个物理页的 page 实例的地址,第二个参数是阶数。
(2)void free_pages(unsigned long addr, unsigned int order),第一个参数是第一个物理页的起始内核虚拟地址,第二个参数是阶数。
函数__free_pages 的代码如下:
mm/page_alloc.cvoid __free_pages(struct page *page, unsigned int order){if (put_page_testzero(page)) {if (order == 0)free_hot_cold_page(page, false);else__free_pages_ok(page, order);}}
首先把页的引用计数减 1,只有页的引用计数变成零,才真正释放页:如果阶数是 0,不还给伙伴分配器,而是当作缓存热页添加到每处理器页集合中;如果阶数大于 0,调用函数__free_pages_ok 以释放页。
函数 free_hot_cold_page 把一页添加到每处理器页集合中,如果页集合中的页数量大于或等于高水线,那么批量返还给伙伴分配器。第二个参数 cold 表示缓存冷热程度,主动释放的页作为缓存热页,回收的页作为缓存冷页,因为回收的是最近最少使用的页。
mm/page_alloc.cvoid free_hot_cold_page(struct page *page, bool cold){struct zone *zone = page_zone(page);struct per_cpu_pages *pcp;unsigned long flags;unsigned long pfn = page_to_pfn(page);int migratetype;if (!free_pcp_prepare(page))return;migratetype = get_pfnblock_migratetype(page, pfn);/* 得到页所属页块的迁移类型 */set_pcppage_migratetype(page, migratetype);/* page->index保存真实的迁移类型 */local_irq_save(flags);__count_vm_event(PGFREE);/** 每处理器集合只存放不可移动、可回收和可移动这3种类型的页,* 如果页的类型不是这3种类型,处理方法是:* (1)如果是隔离类型的页,不需要添加到每处理器页集合,直接释放;* (2)其他类型的页添加到可移动类型链表中,page->index保存真实的迁移类型。*/if (migratetype >= MIGRATE_PCPTYPES) {if (unlikely(is_migrate_isolate(migratetype))) {free_one_page(zone, page, pfn, 0, migratetype);goto out;}migratetype = MIGRATE_MOVABLE;}/* 添加到对应迁移类型的链表中,如果是缓存热页,添加到首部,否则添加到尾部 */pcp = &this_cpu_ptr(zone->pageset)->pcp;if (!cold)list_add(&page->lru, &pcp->lists[migratetype]);elselist_add_tail(&page->lru, &pcp->lists[migratetype]);pcp->count++;/* 如果页集合中的页数量大于或等于高水线,那么批量返还给伙伴分配器 */if (pcp->count >= pcp->high) {unsigned long batch = READ_ONCE(pcp->batch);free_pcppages_bulk(zone, batch, pcp);pcp->count -= batch;}out:local_irq_restore(flags);}
函数__free_pages_ok 负责释放阶数大于 0 的页块,最终调用到释放页的核心函数__free_one_page,算法是:如果伙伴是空闲的,并且伙伴在同一个内存区域,那么和伙伴合并,注意隔离类型的页块和其他类型的页块不能合并。算法还做了优化处理:
假设最后合并成的页块阶数是 order,如果 order 小于(MAX_ORDER−2),则检查(order+1)阶的伙伴是否空闲,如果空闲,那么 order 阶的伙伴可能正在释放,很快就可以合并成(order+2)阶的页块。为了防止当前页块很快被分配出去,把当前页块添加到空闲链表的尾部。
函数__free_pages_ok 的代码如下:
mm/page_alloc.c__free_pages_ok() -> free_one_page() -> __free_one_page()static inline void __free_one_page(struct page *page,unsigned long pfn,struct zone *zone, unsigned int order,int migratetype){unsigned long combined_pfn;unsigned long uninitialized_var(buddy_pfn);struct page *buddy;unsigned int max_order;/* pageblock_order是按可移动性分组的阶数 */max_order = min_t(unsigned int, MAX_ORDER, pageblock_order + 1);…continue_merging:/*如果伙伴是空闲的,和伙伴合并,重复这个操作直到阶数等于(max_order-1)。*/while (order < max_order - 1) {buddy_pfn = __find_buddy_pfn(pfn, order);/* 得到伙伴的起始物理页号 */buddy = page + (buddy_pfn - pfn); /* 得到伙伴的第一页的page实例 */if (!pfn_valid_within(buddy_pfn))goto done_merging;/* 检查伙伴是空闲的并且在相同的内存区域 */if (!page_is_buddy(page, buddy, order))goto done_merging;/** 开启了调试页分配的配置宏CONFIG_DEBUG_PAGEALLOC,伙伴充当警戒页。*/if (page_is_guard(buddy)) {clear_page_guard(zone, buddy, order, migratetype);} else {/* 伙伴是空闲的,把伙伴从空闲链表中删除 */list_del(&buddy->lru);zone->free_area[order].nr_free--;rmv_page_order(buddy);}combined_pfn = buddy_pfn & pfn;page = page + (combined_pfn - pfn);pfn = combined_pfn;order++;}if (max_order < MAX_ORDER) {/** 运行到这里,意味着阶数大于或等于分组阶数pageblock_order,* 阻止把隔离类型的页块和其他类型的页块合并*/if (unlikely(has_isolate_pageblock(zone))) {int buddy_mt;buddy_pfn = __find_buddy_pfn(pfn, order);buddy = page + (buddy_pfn - pfn);buddy_mt = get_pageblock_migratetype(buddy);/*如果一个是隔离类型的页块,另一个是其他类型的页块,不能合并 */if (migratetype != buddy_mt&& (is_migrate_isolate(migratetype) ||is_migrate_isolate(buddy_mt)))goto done_merging;}/* 如果两个都是隔离类型的页块,或者都是其他类型的页块,那么继续合并 */max_order++;goto continue_merging;}done_merging:set_page_order(page, order);/** 最后合并成的页块阶数是order,如果order小于(MAX_ORDER-2),* 则检查(order+1)阶的伙伴是否空闲,如果空闲,那么order阶的伙伴可能正在释放,* 很快就可以合并成(order+2)阶的页块。为了防止当前页块很快被分配出去,* 把当前页块添加到空闲链表的尾部*/if ((order < MAX_ORDER-2) && pfn_valid_within(buddy_pfn)) {struct page *higher_page, *higher_buddy;combined_pfn = buddy_pfn & pfn;higher_page = page + (combined_pfn - pfn);buddy_pfn = __find_buddy_pfn(combined_pfn, order + 1);higher_buddy = higher_page + (buddy_pfn - combined_pfn);if (pfn_valid_within(buddy_pfn) &&page_is_buddy(higher_page, higher_buddy, order + 1)) {list_add_tail(&page->lru,&zone->free_area[order].free_list[migratetype]);goto out;}}/* 添加到空闲链表的首部 */list_add(&page->lru, &zone->free_area[order].free_list[migratetype]);out:zone->free_area[order].nr_free++;}
审核编辑:汤梓红
-
单线分配器与双线分配器的区别是什么2024-07-10 3485
-
Linux内核内存管理之slab分配器2024-02-22 2951
-
Linux内核内存管理之ZONE内存分配器2024-02-21 2223
-
Linux内核引导内存分配器的原理2023-04-03 964
-
Linux内核之块分配器2022-07-27 3023
-
Linux之引导内存分配器2022-07-22 2628
-
深入剖析SLUB分配器和SLAB分配器的区别2022-05-17 1773
-
分配器,什么是分配器2010-04-02 4140
-
音视频/信号分配器,音视频/信号分配器是什么意思2010-03-26 3237
-
脉冲分配器2010-01-12 2767
-
分配器的产品类型2010-01-07 1499
-
数据分配器2009-04-07 11257
-
分配器2008-10-19 2823
全部0条评论

快来发表一下你的评论吧 !
