

AI常识推理再突破 单模型全球首次超过人类平均水平
人工智能
描述
2022年7月25日,由科大讯飞承建的我国首个认知智能全国重点实验室荣登科学常识推理挑战赛OpenBookQA榜首,创新性提出X-Reasoner模型,以准确率94.2%的绝对优势夺冠,常识推理单模型首超人类平均水平。

OpenBookQA是由艾伦人工智能研究所(AI2)推出的科学常识推理阅读理解数据集,旨在评估机器对常识的理解和应用能力。该评测吸引了众多研究机构和知名高校的关注,例如南京大学、香港中文大学、MSRA、斯坦福大学、谷歌、阿里巴巴等。科大讯飞此次参赛,创新性提出X-Reasoner模型,以准确率94.2%的显著优势大幅刷新榜单最好成绩,领先榜单最优单模型4.4%, 成为全球首个超越人类平均水平(91.7%)的单模型。
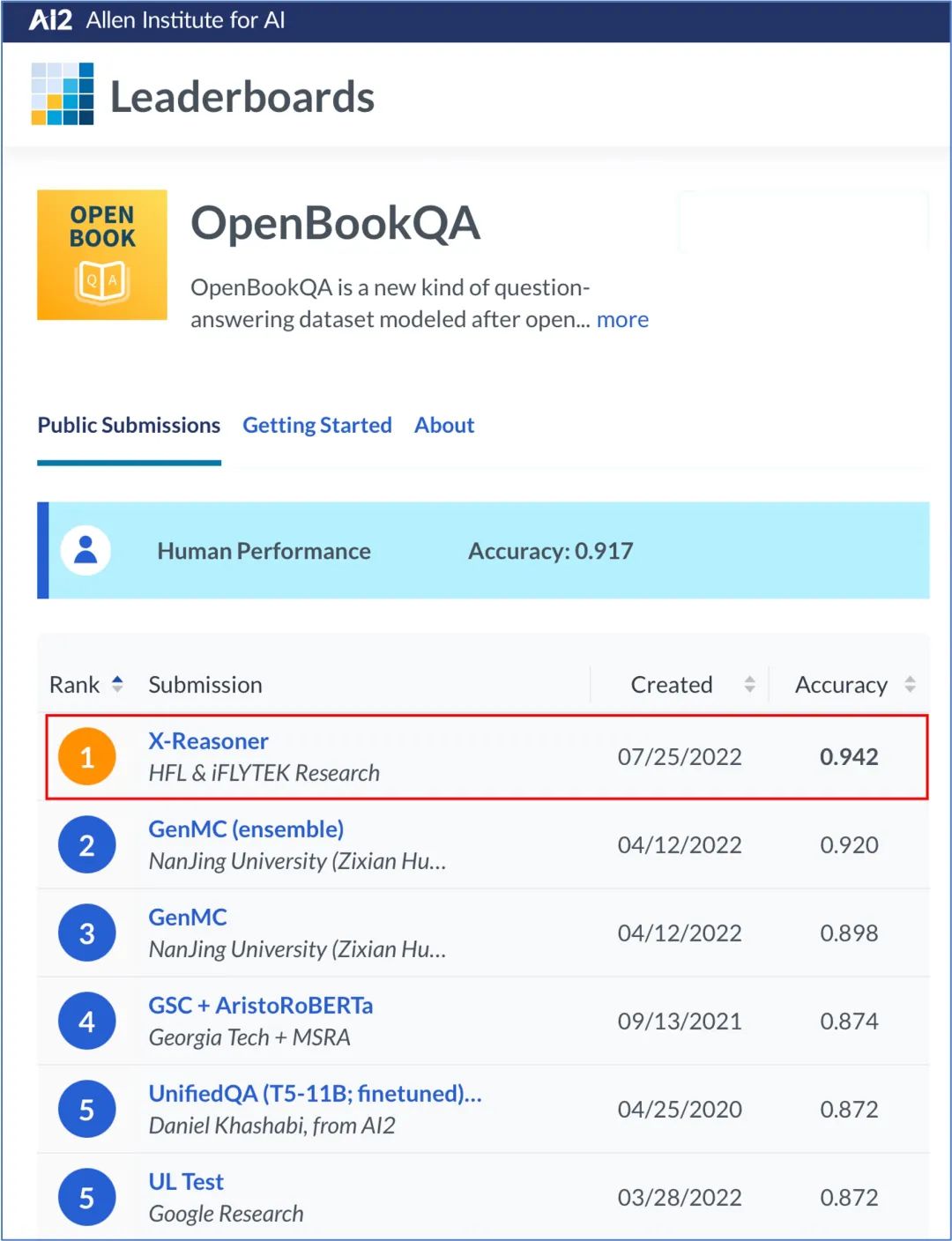
OpenBookQA评测榜单
新挑战
机器不仅需要正确理解问题
还要能够进行推理
OpenBookQA数据集中的每一个题目都由问题和四个选项构成,需要机器从选项中找出正确答案。该任务的难点在于,为了正确作出回答,机器不仅需要能够正确理解问题和选项的表面语义,还需要结合外部常识知识进行推理,这对AI系统的阅读理解能力提出了新的挑战。
例如在下面的例子中,若要正确回答问题,需要了解“星球旋转会导致昼夜交替”这一科学常识,同时也需知道“地球自转”与其他选项相关的科学常识没有关系。

OpenBookQA问题示例
科大讯飞提出X-Reasoner系统
从知识检索和阅读理解两个角度破解难题
面对此类问题,即使对于人类也需要掌握一定的外部知识后才能正确作答。那么机器是如何回答此类需要常识推理的问题呢?
本次由科大讯飞承建的认知智能全国重点实验室与哈工大联合团队提出的X-Reasoner系统分别从知识检索和阅读理解两个角度解决科学常识推理问题,知识检索模块负责依据问题和选项从科学知识库中找到最相关的知识;阅读理解模块结合检索出的知识、问题和选项进行推理,给出最终答案。依托以上技术,X-Reasoner不仅在性能上大幅刷新榜单最好成绩,同时还成为了首个超过人类平均水平的单模型。
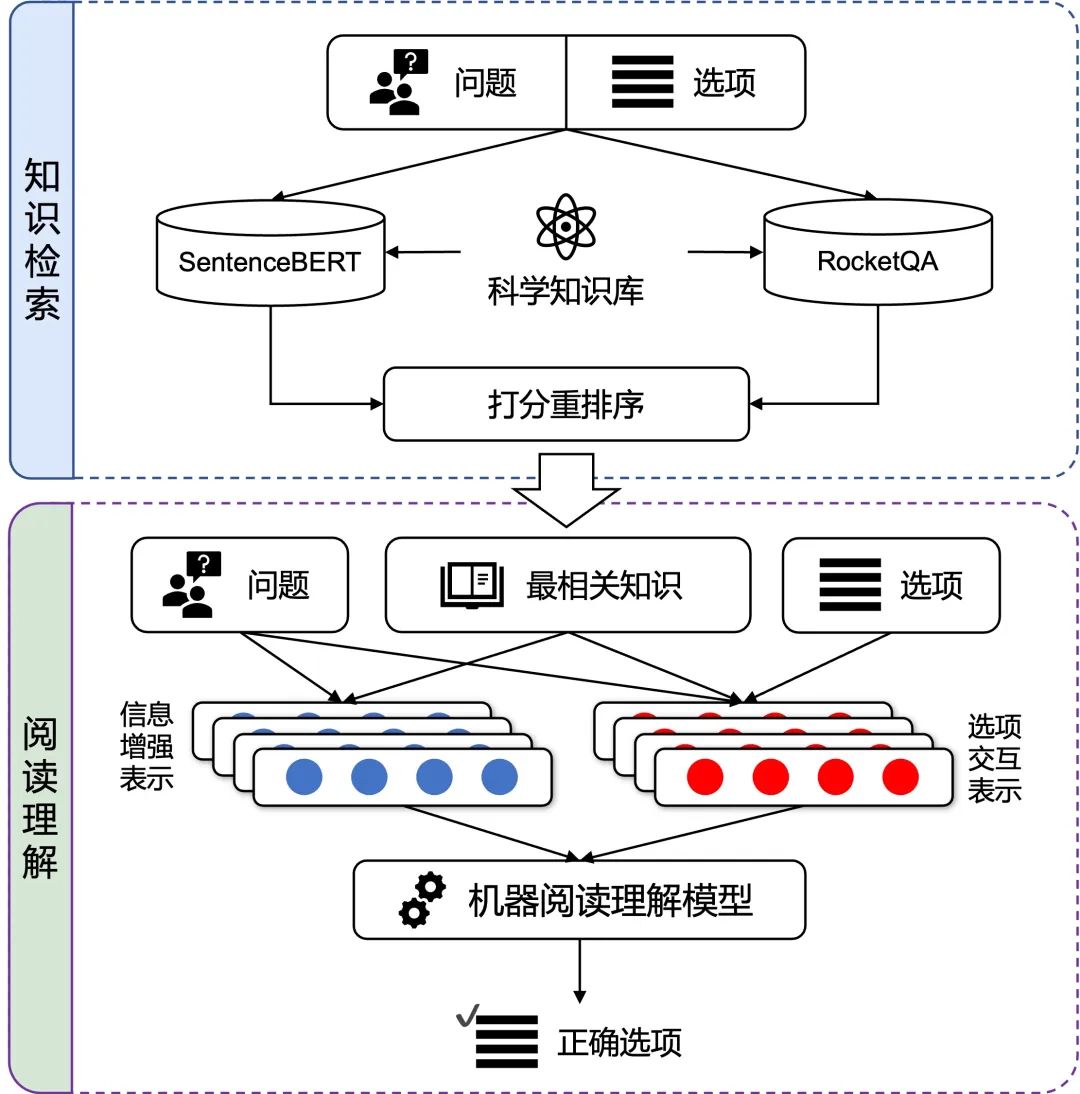
X-Reasoner模型框架
更准确的知识:复合交互式检索
只有检索出了准确的问题相关知识,才能根据相关知识做出有效推理。因此知识检索作为系统的第一步,其准确性至关重要。X-Reasoner中提出了一种基于SentenceBERT和RocketQA两种检索模型的复合交互式检索方案。通过重打分、重排序等手段,对两种模型在同一问题选项上的检索结果进行重要性的重新估计,综合挑选出最重要的10条知识作为检索结果送入阅读理解模块。
更丰富的表示:基于知识的信息增强
在获得精确的相关知识后,下一步将根据知识进行推理。X-Reasoner采用了联合知识和问题的方式,让模型进行隐式推理,给出一个答案相关的信息增强表示。该表示隐含了利用相关知识和问题所能推理得到的信息,与选项交互表示一起送入阅读理解模型进行计算。
更智能的理解:多选项对比交互
人类在回答选择题的过程中,如果对所选答案不确定,通常会采取对比不同选项的策略。例如,排除掉最不可能是答案的三个选项,那么唯一剩下的选项就是正确答案。X-Reasoner的一个特点便是模仿了人类的这种答题方式。X-Reasoner一次性对问题、四个选项以及相关的科学常识进行编码,并通过注意力机制进行交互,获得了对比选项回答问题的能力。
通过以上三个创新点的结合,X-Reasoner大幅提升了常识推理的效果,相比榜单之前最好的单模型在准确率上显著提升4.4%。 科大讯飞持续深入认知智能领域前沿技术研究,尤其在机器阅读理解领域中不断取得技术突破,先后在机器阅读理解权威评测SQuAD 2.0中全球首次超过人类平均水平,获得对话型阅读理解评测CoQA和QuAC冠军,多步推理阅读理解HotpotQA双赛道冠军,多模态阅读理解评测VCR冠军。 本次在科学常识推理阅读理解评测OpenBookQA夺得冠军并成为全球首个超过人类平均水平的单模型,使得机器能够进一步“融会贯通”,不仅能够有效地理解文本表面的意思,还能够通过融合外部知识来辅助进行推理;同时也在教育、医疗、养老等国计民生场景中,让人工智能产品更具备实用价值。未来,科大讯飞将持续深耕,“让机器能听会说、能理解会思考”,探索A.I的更多可能!
-
图解:中国信息化指数首超G20国家平均水平2016-11-24 1127
-
英伟达Cosmos-Reason1 模型深度解读2025-03-29 3492
-
睿海光电800G光模块助力全球AI基建升级2025-08-13 1239
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片到AGI芯片2025-09-18 6090
-
论马斯克的预言:AI使人类边缘化2026-03-14 1002
-
人工智能上路需要知道什么常识2019-05-13 4177
-
HarmonyOS:使用MindSpore Lite引擎进行模型推理2023-12-14 475
-
印度线上智能手机出货年增23% 超过了2017年平均水平2018-03-13 6065
-
科大讯飞机器翻译首次达到专业译员水平 机器阅读超越人类平均水平2019-05-24 9315
-
超越微软!阿里AI在常识QA领域刷新世界纪录2019-07-17 3642
-
扑克牌是是AI首次在超过两个人的游戏中击败人类玩家2019-07-19 4339
-
机器的理解能力已经强大到可以超过人类?2019-08-27 3684
-
AI与移动终端融合应用场景不断丰富2020-10-29 3217
-
基于大语言模型辩论的多智能体协作推理分析2023-11-29 3020
-
深度探讨VLMs距离视觉演绎推理还有多远?2024-03-19 868
全部0条评论

快来发表一下你的评论吧 !
