

说话人识别和验证系统解决方案
电子说
描述
说话人识别和验证系统的应用与日俱增。该技术的使用有助于控制和访问自动驾驶汽车、计算机、手机和其他设备。还建立了各种机器学习模型来保护说话人识别和验证系统。这是通过分析声音的情绪反应和压力水平来检测对个人的威胁以及触发他们安全的机制来实现的。
介绍
说话者和验证系统根据一个人的声音或讲话的特性来识别说话者。人类每天都习惯于识别和响应说话者,但通过技术进行语音识别是复杂的,需要大量计算。由于数字信号处理和计算机系统的进步,自动说话人识别系统的使用在过去十年中变得普遍。
说话人识别系统的组成部分
说话人识别系统包括三个部分:
说话人识别:从一组登记的说话人中查明说话人的身份。目标是从已存储的几个模型中找到合适的扬声器。(检查多人)
说话人验证:验证未知声音是否属于某个说话人。当一个人将自己标识为 John Doe/Jane Doe 时,说话人验证系统会将语音数据与录制的模型进行比较,以确定说话人的身份是否与他/她声称的身份相符。(检查声称的身份)
说话者分类:根据语音的特殊特征(基于从语音内容中提取的特征)将包含说话者语音的音频流划分为同质段/时间帧,以对说话者进行身份分类。
说话人验证系统的应用
访问控制:一个人必须说出一个特定的短语来表明自己的身份,才能访问受限场所和特权信息。
交易认证:一个人必须说出一个特定的短语来识别他/她自己,以启动电话银行/信用卡授权或类似的交易。
扬声器验证系统基础知识

图 1:扬声器验证基础
Front-End 部分捕获说话者的声音,并将语音信号转换为一组代表说话者特征的特征向量。后端部分将特征向量与说话者的存储模型(即通用背景模型,如下所述)进行比较,以确定它们匹配的精确程度以验证说话者的身份。一旦说话者的声音与数据库中的声音模型匹配,他们就可以访问。
用于记录和创建“扬声器模型”的机制的变化增加了复杂性。由于可变的语音/语音保真度,说话人识别/验证变得更加复杂。例如,在银行使用高分辨率、高保真录音机创建扬声器模型时,语音保真度会有所不同,但基于语音的交易是使用具有嘈杂背景的手机完成的。
说话人识别/验证流程图
最初创建了一个大型模型数据库,其中包含许多说话者和来自这些说话者的数小时语音数据。录音包含来自不同来源的各种高保真和低保真语音输入。分析从大量语音数据中提取的特征并训练模型以创建通用的男性/女性模型。该模型数据库被称为“通用背景模型”(UBM)。
然后,创建想要识别/验证自己的说话者模型数据库。该模型数据库被称为“扬声器模型”。该模型是从“通用背景模型”派生/创建的,该模型对通用男性/女性声音进行分类。目标扬声器型号与 UBM 略有不同。这些差异被记录并保存在“扬声器模型”数据库中。
现在,当这个人说:“我是 John Doe”时,这个语音片段被记录下来并分割成 10 毫秒的帧,并通过特征提取模型,产生语音的一些特征/特征。
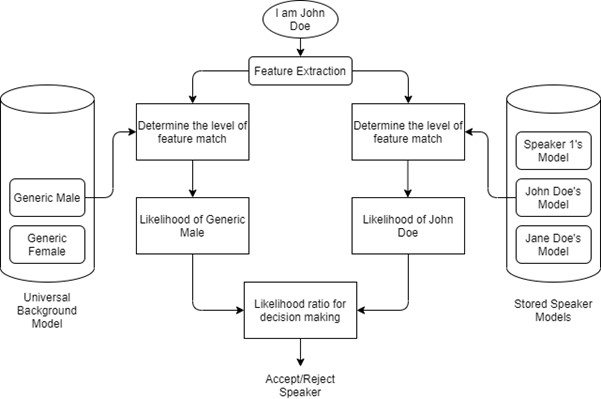
图 2:说话人验证流程图
如果 John Doe 想要验证他的名字,我们将从输入语音“I am John Doe”中提取的特征输入到他的说话人模型(特征提取)中,该模型确定特征匹配的水平并计算它是“John多伊'。
然后,对于相同的输入声音,“我是 John Doe”,我们将提取的特征输入到通用背景模型中,以确定特征匹配的水平,并得出他是普通男性声音的可能性。
决策的似然比由上述两个似然比得出。接受/拒绝决定是基于根据呼叫者是“John Doe”的可能性和呼叫者是普通男性的可能性(基于通用背景模型)计算的某个阈值做出的。
eInfochips 为基于语音和音频的中间件提供嵌入式系统和软件开发、移植、优化、支持和维护解决方案,其中包括:DSP 域中的编码器、解码器、预处理和后处理算法。还提供语音/音频相关工具和服务的维护和开发。eInfochips 还迎合了多核平台上自定义算法的实现和并行化。
作者:瑞诗凯诗·阿加什
Rhishikesh Agashe 是 eInfochips 技术团队的一员,他在 IT 行业拥有近 19 年的经验。4 年的企业家生涯和 15 年的嵌入式领域经验,其中他的大部分经验是在嵌入式媒体处理领域,他参与了音频和语音算法的实施。
审核编辑:汤梓红
- 相关推荐
- 热点推荐
- 识别系统
-
基于GMM的实时说话人识别系统2023-10-08 577
-
基于TDSDM642EVM数字处理芯片实现实时说话人识别系统的设计2020-08-06 1283
-
基于DSP嵌入式说话人识别系统该怎么设计?2019-11-04 1659
-
DSP嵌入式说话人识别系统设计方案2019-07-29 1843
-
基于CS的说话人识别算法2018-01-18 733
-
一种新的说话人识别系统框架2018-01-08 892
-
基于MAP+CMLLR的说话人识别中发声力度问题2017-12-05 996
-
DSP嵌入式说话人识别系统的设计方案2017-11-02 1107
-
基于FPGA的说话人识别系统设计2017-01-18 1103
-
作为说话人识别特征参量的MFCC的提取过程2012-08-20 2401
-
基于DTW的编码域说话人识别研究2010-11-22 1001
-
DSP嵌入式说话人识别系统的设计与实现2009-12-28 793
-
基于Cohort相似度的说话人识别2009-12-16 806
-
说话人识别算法研究及其在SOC上的实现2009-08-15 844
全部0条评论

快来发表一下你的评论吧 !
