

编写的一个协议相关代码,位域的值解析
描述
1. 粉丝问题
自己编写的一个协议相关代码,位域的值解析和自己想象的有出入。
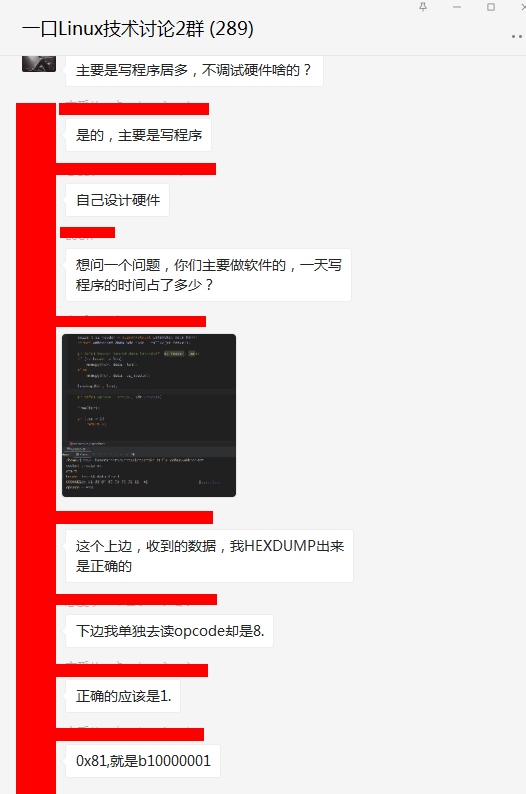
结构体的头:
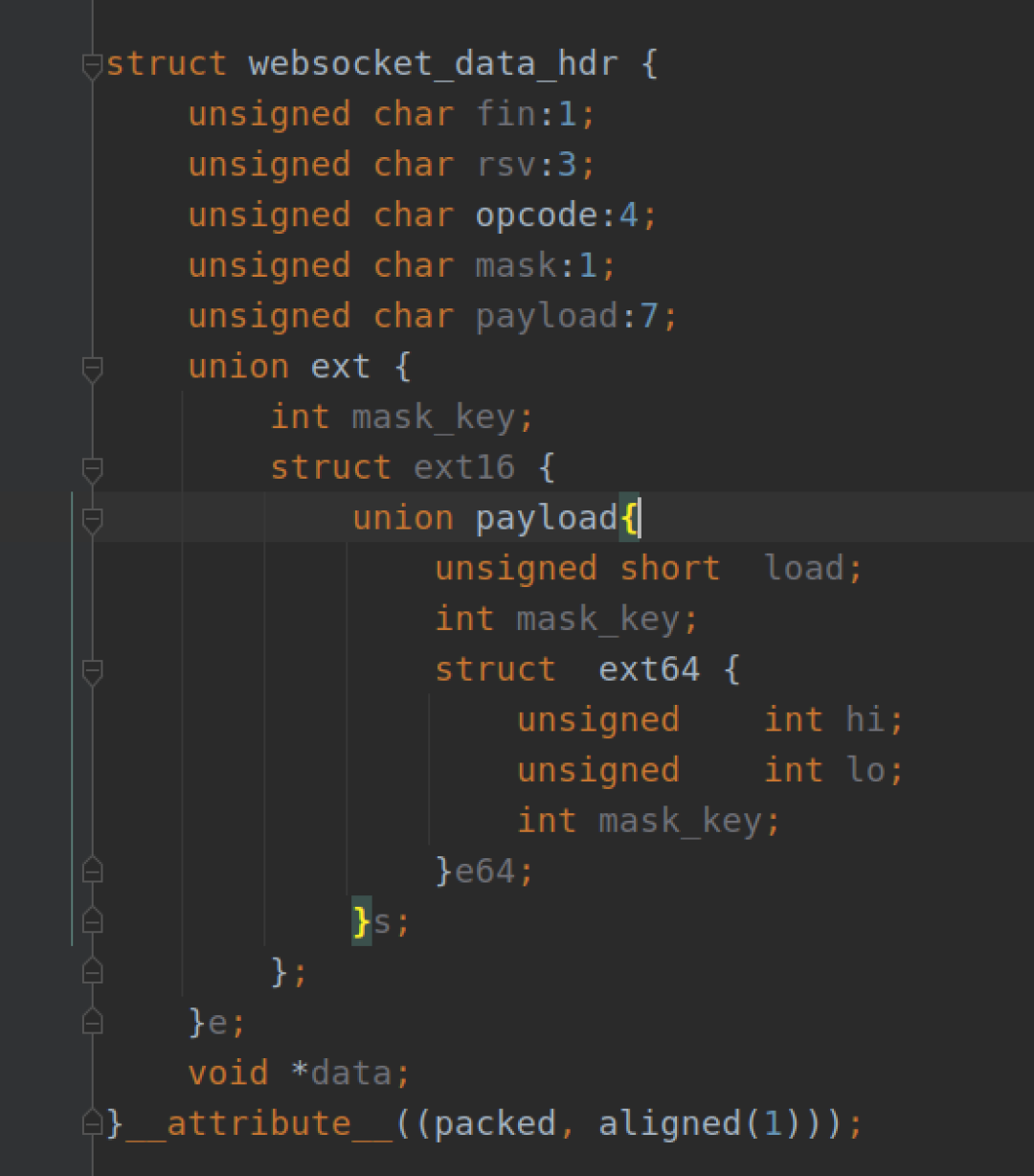
解析代码和测试结果:
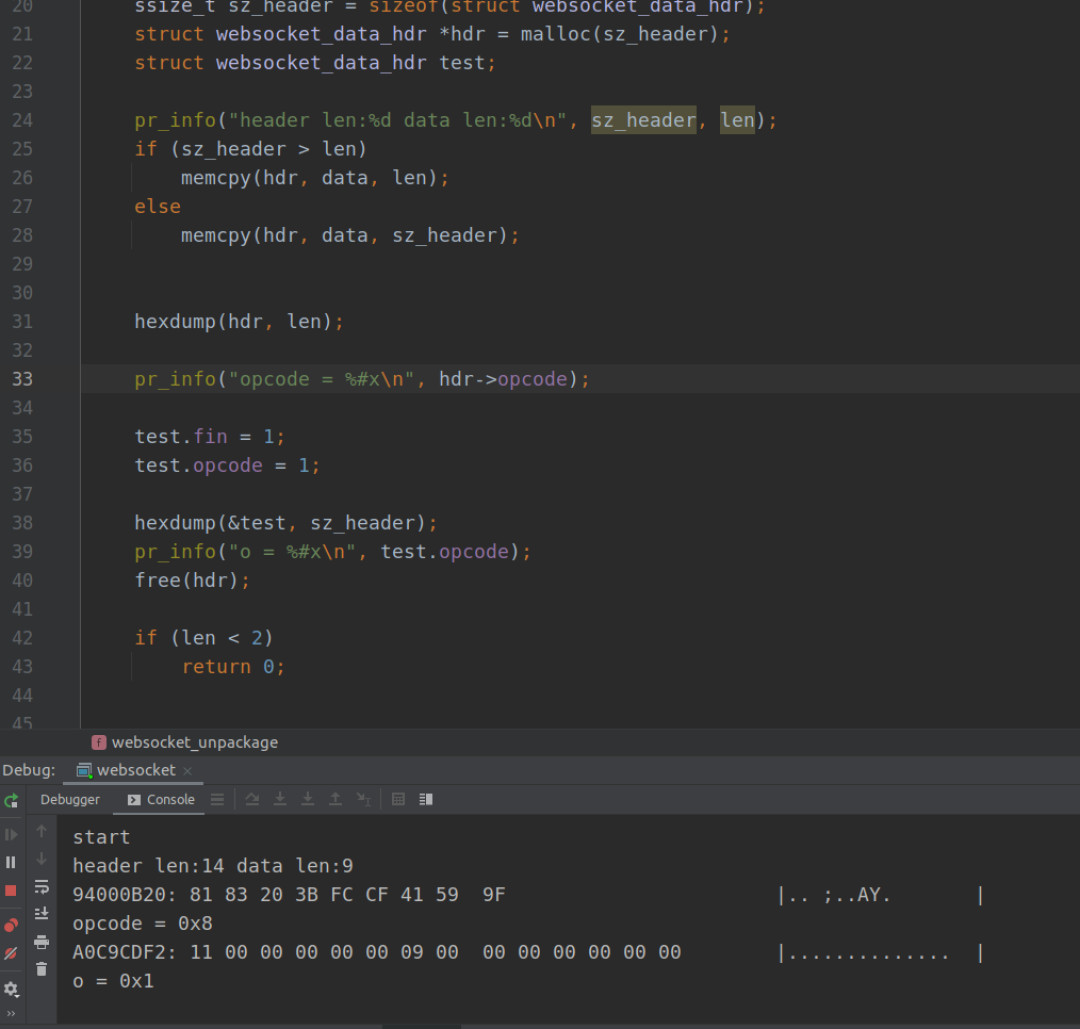
就是说通过函数hexdump()解析出的内存是十六进制是 81 83 20 3B ......
从数据帧解析出的
opcode = 0x8
该粉丝不明白为什么解析出的值是0x8。
这个问题其实就是位域的问题和字节序的问题。
测试代码
废话不多说,直接写个测试代码
#include
执行结果:
fin:1,rsv:0,opcode:8,mask:1 paylod:65
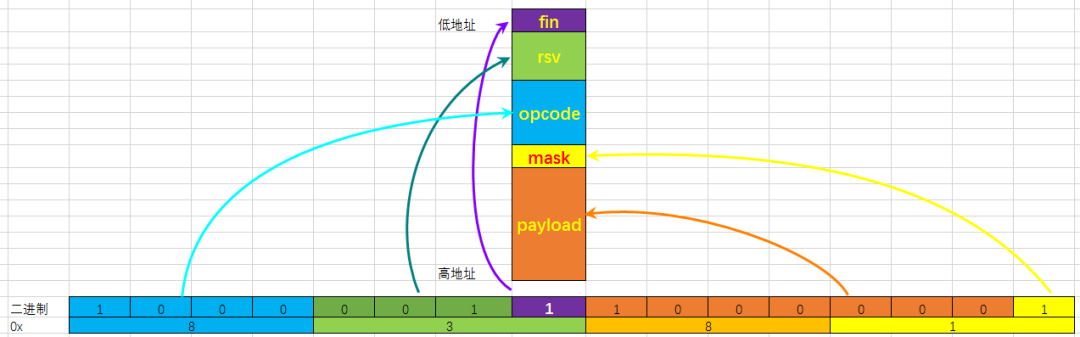
分析:如下图所示,紫色部分是位域成员对应的内存中的实际空间布局,地址从左到右增加第一个字节的0x81赋值后,各位域对应的二进制:
fin:1
rsv:0
opcode:1000
mask:1
paylod:1000001
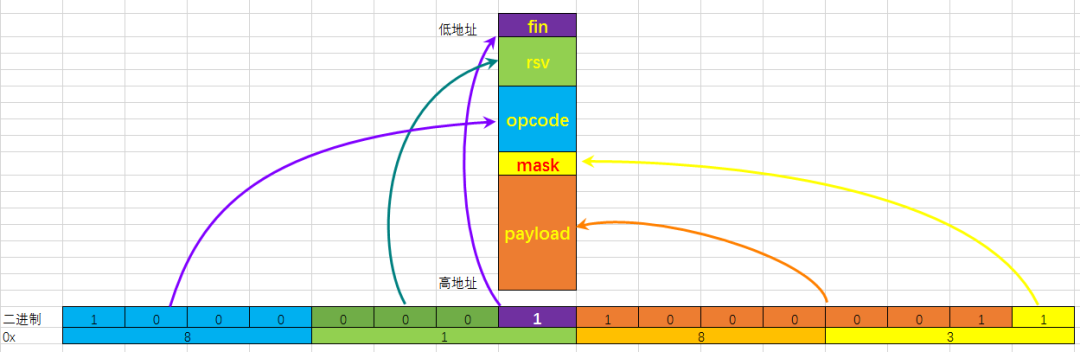
如上图多少,内存的第1个字节是0x81,第2个字节是0x83;
第一个字节0x81的最低的bit[0]对应fin,bit[3:1]对应rsv,bit[7:4]对应opcode;第二个字节0x83的最低bit[0]对应mask,bit[7:1]对应payload。
所以结果显而易见。
2、什么是位域?
有些信息在存储时,并不需要占用一个完整的字节, 而只需占几个或一个二进制位。
例如在存放一个开关量时,只有0和1 两种状态, 用一位二进位即可。为了节省存储空间,并使处理简便,C语言又提供了一种数据结构,称为“位域”或“位段”。
所谓“位域”是把一个字节中的二进位划分为几个不同的区域,并说明每个区域的位数。
每个域有一个域名,允许在程序中按域名进行操作。这样就可以把几个不同的对象用一个字节的二进制位域来表示。一、位域的定义和位域变量的说明位域定义与结构定义相仿,其形式为:
struct 位域结构名
{
位域列表
};
其中位域列表的形式为:
类型说明符 位域名:位域长度
如粉丝所举的实例:
struct iphdr {
unsigned char fin:1;
unsigned char rsv:3;
unsigned char opcode:4;
unsigned char mask:1;
unsigned char payload:7;
unsigned char a;
unsigned char b;
};
位域变量的说明与结构变量说明的方式相同。可采用先定义后说明,同时定义说明或者直接说明这三种方式。例如:
struct bs
{
int a:8;
int b:2;
int c:6;
}data;
说明data为bs变量,共占两个字节。其中位域a占8位,位域b占2位,位域c占6位。对于位域的定义尚有以下几点说明:
一个位域必须存储在同一个字节中,不能跨两个字节。
如一个字节所剩空间不够存放另一位域时,应从下一单元起存放该位域。也可以有意使某位域从下一单元开始。例如:
struct bs
{
unsigned a:4
unsigned :0 /空域/
unsigned b:4 /从下一单元开始存放/
unsigned c:4
};
在这个位域定义中,a占第一字节的4位,后4位填0表示不使用,b从第二字节开始,占用4位,c占用4位。
位域可以无位域名,这时它只用来作填充或调整位置。无名的位域是不能使用的。例如:
struct k
{
int a:1
int :2 /该2位不能使用/
int b:3
int c:2
};
从以上分析可以看出,位域在本质上就是一种结构类型, 不过其成员是按二进位分配的。
这是位域操作的表示方法,也就是说后面加上“:1”的意思是这个成员的大小占所定义类型的1 bit,“:2”占2 bit,依次类推。当然大小不能超过所定义类型包含的总bit数。
一个bytes(字节)是8个 bit(二进制位)。例如你的结构体中定义的类型是u_char,一个字节,共8个bit,最大就不能超过8。32位机下,short是2字节,共16bit,最大就不能超过16,int是4字节,共32bit,最大就不能超过32.依次类推。
位域定义比较省空间。
例如你上面的结构,定义的变量类型是u_char,是一字节类型,即8bit。
fc_subtype占了4bit,fc_type占2bit,fc_protocol_version占2bit,共8bit,正好是一个字节。
其他八个成员,各占1bit,共8bit,正好也是一个字节。
因此你的结构的大小如果用sizeof(struct frame_control)计算,就是2bytes。
3. 如何测试当前是大端还是小端?
计算机硬件有两种储存数据的方式:大端字节序(big endian)和小端字节序(little endian)。大端字节序:高位字节在前,低位字节在后,这是人类读写数值的方法。小端字节序:低位字节在前,高位字节在后。
0x1234567的大端字节序和小端字节序的写法如下图。
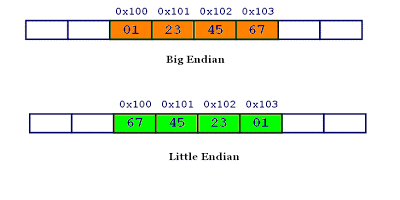
为什么会有小端字节序?
答案是,计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。
但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
计算机处理字节序的时候,不知道什么是高位字节,什么是低位字节。它只知道按顺序读取字节,先读第一个字节,再读第二个字节。
如果是大端字节序,先读到的就是高位字节,后读到的就是低位字节。小端字节序正好相反。
理解这一点,才能理解计算机如何处理字节序。
处理器读取外部数据的时候,必须知道数据的字节序,将其转成正确的值。然后,就正常使用这个值,完全不用再考虑字节序。
即使是向外部设备写入数据,也不用考虑字节序,正常写入一个值即可。外部设备会自己处理字节序的问题。
实例
仍然用上面的例子,但是做如下修改
#include
执行结果:
fin:1 rsv:1 opcode:8 mask:1 paylod:64
由结果可知,收到的0x8183这个值与对应的的二进制关系:
fin:1
rsv:001
opcode:1000
mask:1
paylod:1000000
如上图多少,内存的第1个字节是0x83,第2个字节是0x81【和前面的例子不一样了,因为我们是直接赋值0x8183,而该常数是小字节序,所以低字节是0x83】;
可见:
低字节83给了 fin+rsv+opcode
所以,这说明了一口君的ubuntu是小端字节序。
4. 拓展例子
继续将结构体做如下修改,当位域成员大小加一起不够一个整字节的时候,验证各成员在内存中的布局。
#include

fin:1
opcode:1111
内存中形式如下:

如果修改fin的值为0:
t.fin = 0;
执行结果如下:

fin:0
opcode:1111
内存中形式如下:

5. 总结
大家遇到类似问题的时候,一定要写一些实例去验证,对于初学者来说,建议多参考上述实例。
审核编辑 :李倩-
请问有DS26334芯片的中文资料,和相关配置的源代码吗?以及相关的传输协议解析。2024-09-04 7992
-
谁有ISO/IEC3309.1993这个协议2013-12-13 3517
-
请问LWIP的ping解析和数据解析在哪个协议里?2019-10-10 1305
-
介绍一些与变量相关的存储属性与作用域2022-02-14 783
-
嵌入式开发中自定义协议的解析与组包相关案例分享2022-10-27 2922
-
域间路由协议,域间路由协议的内容有哪些?2010-04-06 3947
-
基于单片机的串口通讯变长协议编写代码2017-09-15 866
-
C语言中编写协议相关代码位域的值解析不对劲怎么办?2021-05-03 2289
-
单片机最小JSON解析,含编写了一个非常简单的JSON资料下载2021-04-27 1507
-
编写一个闪烁LED灯代码2022-10-24 1475
-
TCP/IP协议不止是两个协议2023-07-31 2400
全部0条评论

快来发表一下你的评论吧 !
