

全球首款一站式处理因果学习完整流程的开源算法工具包
描述
根据福布斯的统计数据,全球范围只有 13% 左右的机器学习项目能够真正上线运行,项目失败的一个重要原因是模型的泛化能力不足,在真实数据上的表现和完全达不到训练数据上的效果。 随着机器学习建模越来越多的应用,企业对人工智能的要求也在进一步提高。近几年提及的「数智化」核心是智能决策,以数据驱动的方式实现自动化决策来提高整体运营效率。用户的需求的重心从预测性分析向指导性分析升级转移,预测性分析是告诉企业未来可能会发生什么,指导性分析也叫处方性分析,是告诉企业我们如果想要实现一个目标需要如何做,这是典型的智能决策问题。 机器学习主要用在预测性分析上,基本上没有能力解决指导性分析这样的决策问题,因此,因果学习正被学界和业界逐渐重视起来,其可以补充机器学习的一些短板,也满足了智能决策这类问题的需求。因果推断的重要性逐渐显示,被认为是人工智能领域的一次范式革命。 7 月 12 日,九章云极 DataCanvas 发布了 YLearn 因果学习开源项目,是全球首款一站式处理因果学习完整流程的开源算法工具包。 一个典型的完整因果推断流程主要由三个部分组成。图灵奖得主 Judea Pearl 曾表示,现有的机器学习模型不过是对数据的精确曲线拟合,只是在上⼀代的基础上提升了性能,在基本的思想方面没有任何进步。
-
第一,数据中的因果结构应当首先被学习和发现,用作这一任务的手段通常被称为因果发现(causal discovery)。这些被发现的因果关系会被表示为因果结构公式(structural causal models, SCM)或因果图(一种有向无环图,directed acyclic graphs, DAG)。
-
第二,我们需要将我们感兴趣的因果问题中的量用因果变量(causal estimand)表示,其中一个例子是平均治疗效应(average treatment effect, ATE)。这些因果变量接下来会通过因果效应识别转化为统计变量(statistical estimand),这是因为因果变量无法从数据中直接估计,只有识别后的因果变量才可以从数据中被估计出来。
-
最后,我们需要选择合适的因果估计模型从数据中去学些这些被识别后的因果变量。完成这些事情之后,诸如策略估计问题和反事实问题等因果问题也可以被解决了。
GitHub 开源地址:https://github.com/DataCanvasIO/YLearn YLearn 的应用目前主要集中在两个方向: 用于弥补机器学习理论上的缺陷。在机器学习模型中加入因果机制,利用因果关系的稳定性和可解释性,优化模型、提升效率; 帮助实现用户需求从预测到决策的迁移,例如使用基于因果推断的推荐算法帮助企业进行客户增长和智能营销等。 它具有一站式、新而全、用途广等特点:
-
一站式:通常的因果学习流程包括从数据中发现因果结构,对因果结构建立因果模型,使用因果模型进行因果效应识别和对从数据中对因果效应进行估计。YLearn 一站式地支持这些功能,使用户以最低的学习成本使用与部署因果学习。
-
新而全:YLearn 实现了多个近年来在因果学习领域中发展出的各类算法,例如 Meta-Learner、Double Machine Learning 等。也将一直致力于紧跟前沿进展,保持因果识别与估计模型的先进和全面。
-
用途广:YLearn 支持对估计得到的因果效应进行解释、根据因果效应在各种方案中选取收益最大的方案并可视化决策过程等功能。除此之外,YLearn 也支持将因果结构中识别出的因果效应的概率分布表达式以 LaTex 的形式输出等小功能,帮助用户将因果学习与其他方向交叉。
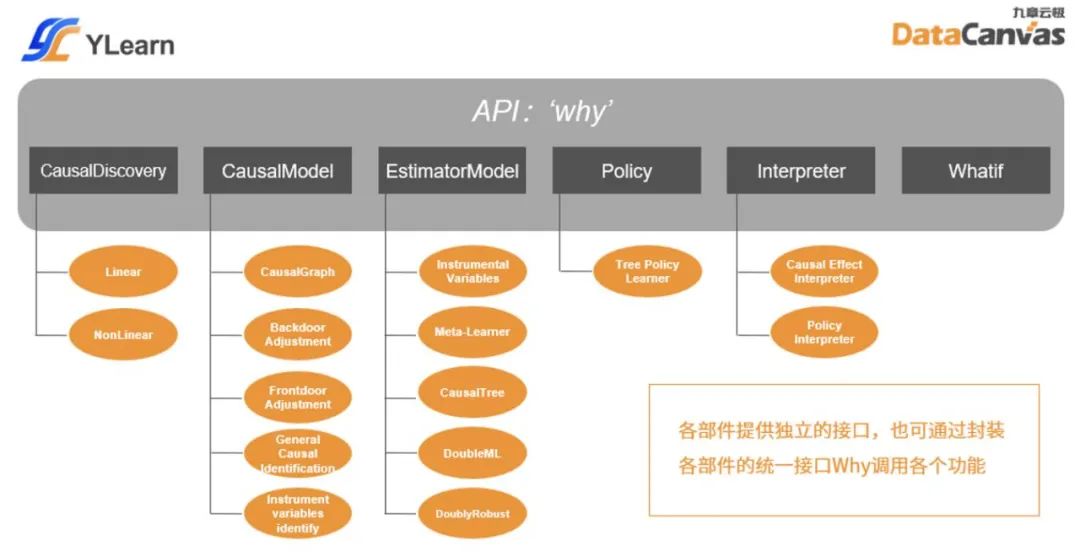
- CausalDiscovery. 发现数据集中线性和非线性的因果关系并用因果图表示。
- CausalModel. 确定感兴趣的因果量之后,识别因果图中的工具变量,操作因果图,识别因果效应(Causal Effect)的估计表达式,也可判断给定集合是否可以作为后门调整集合,前门调整集合等。
- EstimatorModel. 给定因过量的估计表达式与训练数据集,从训练数据集中训练多种估计模型,使用训练好的估计模型在新的测试数据集上估计因果效应。
- Policy. 给定感兴趣的因果效应和数据集,寻找一种最佳方案以提升因果效应,获取理想收益。
- Interpreter. 解释估计模型(EstimatorModel)所预测的因果效应,解释策略模型(Policy)所给出的最佳方案。
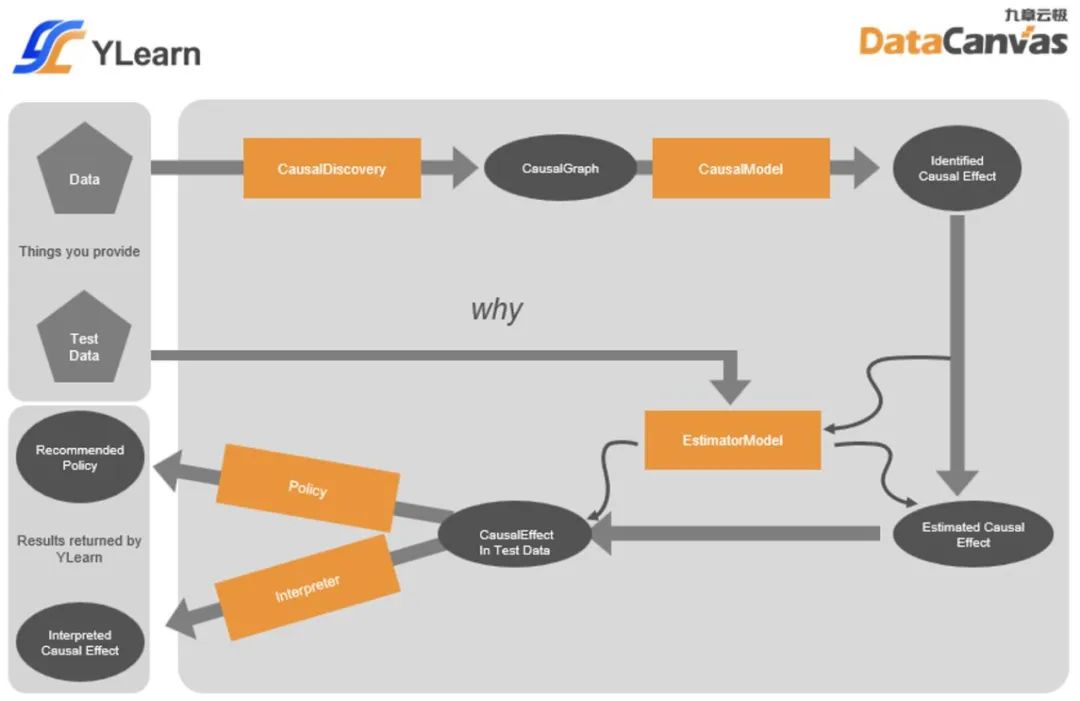
- 使用 CausalDiscovery 去发现数据中的因果关系和因果结构,它们会以 CausalGraph 的形式表示和存在。
- 这些因果图接下来会被输入进 CausalModel, 在这里用户感兴趣的因果变量会通过因果效应识别转化为相应的可被估计的统计变量(也叫识别后的因果变量)。
- 一个特定的 EstimatorModel 此时会在训练集中训练,得到训练好的估计模型,用来从数据中估计识别后的因果变量。
- 这个(些)训练好的 EstimatorModel 就可以被用来在测试数据集上估计各类不同的因果效应,同时也可以被用来作因果效应解释或策略方案的制定。
causation = {'X': ['W'], 'W':[], 'Y':['W']}
cg = CausalGraph(causation=causation)
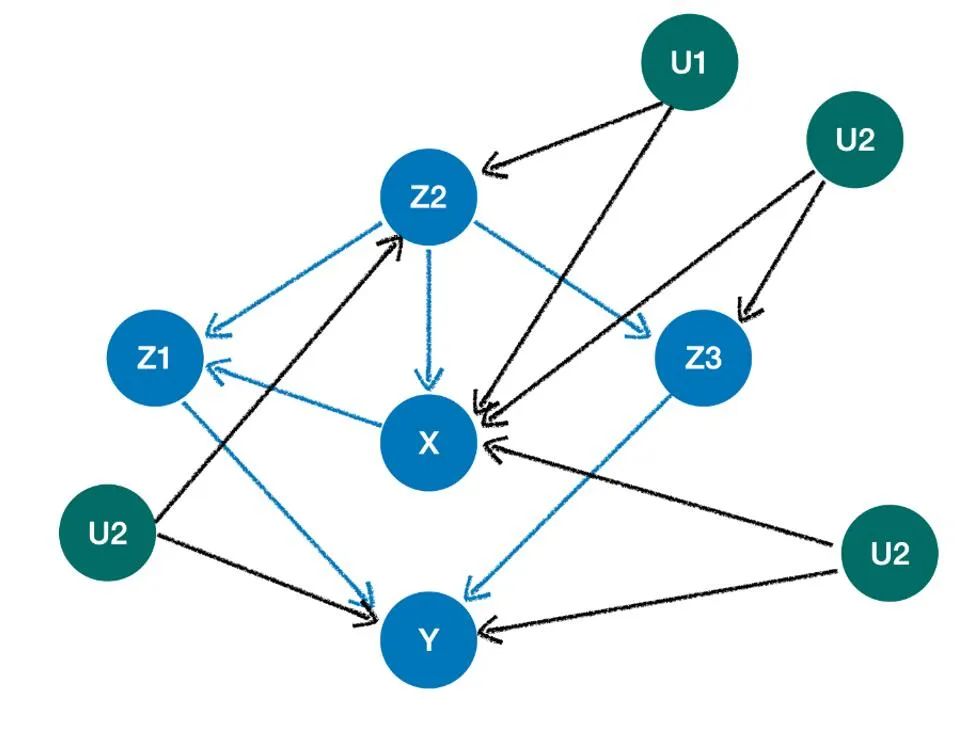
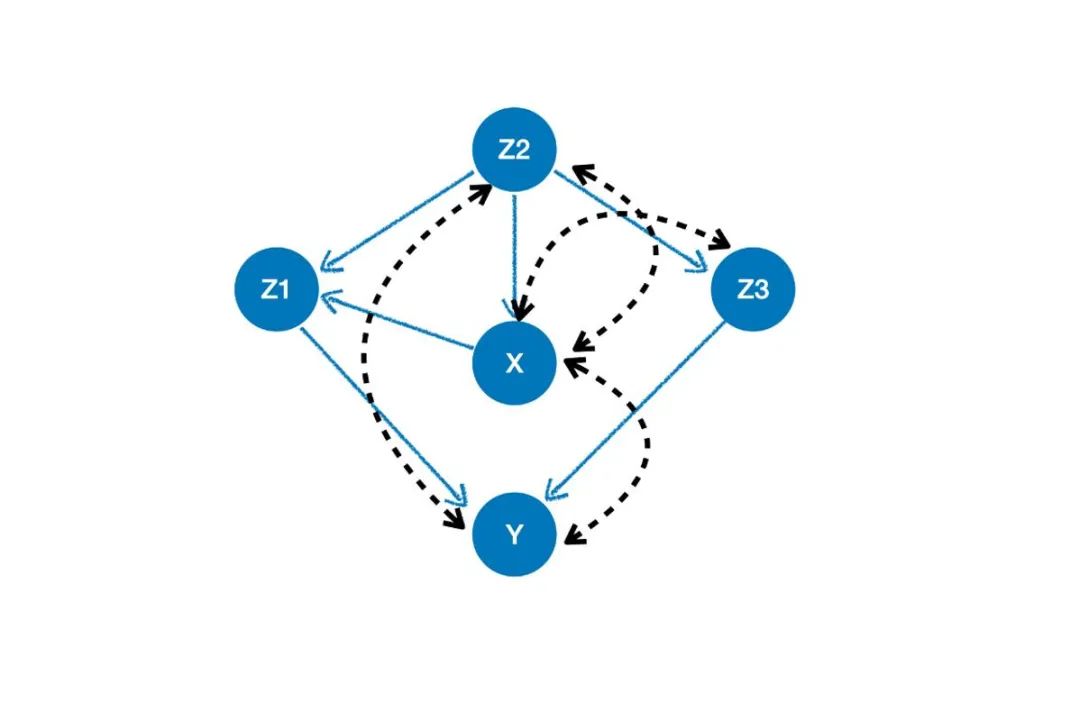
from ylearn.causal_model.graph import CausalGraph
causation_unob = {
'X': ['Z2'],
'Z1': ['X', 'Z2'],
'Y': ['Z1', 'Z3'],
'Z3': ['Z2'],
'Z2': [],
}
arcs = [('X', 'Z2'), ('X', 'Z3'), ('X', 'Y'), ('Z2', 'Y')]
cg_unob = CausalGraph(causation=causation_unob, latent_confounding_arcs=arcs)
cm = CausalModel(causal_graph=cg)
cm.identify(treatment={'X'}, outcome={'Y'}, identify_method=('backdoor', 'simple'))
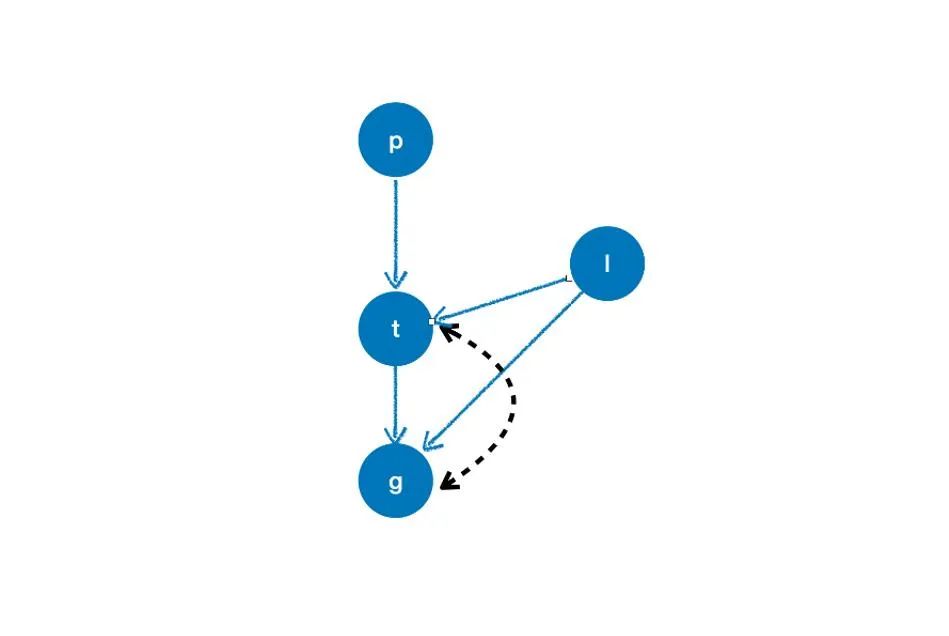
causation = {
'p': [],
't': ['p', 'l'],
'l': [],
'g': ['t', 'l']
}
arc = [('t', 'g')]
cg = CausalGraph(causation=causation, latent_confounding_arcs=arc)
cm = CausalModel(causal_graph=cg)
cm.get_iv('t', 'g')
- 给定 pandas.DataFrame 形式的数据,确定 treatment, outcome, adjustment, covariate 的变量名。
- 调用 EstimatorModel 的 fit() 方法训练模型。
- 调用 EstimatorModel 的 estimate() 方法得到估计好的因果效应。
from sklearn.datasets import fetch_california_housing
from ylearn import Why
housing = fetch_california_housing(as_frame=True)
data = housing.frame
outcome = housing.target_names[0]
data[outcome] = housing.target
why = Why()
why.fit(data, outcome, treatment=['AveBedrms', 'AveRooms'])
print(why.causal_effect())
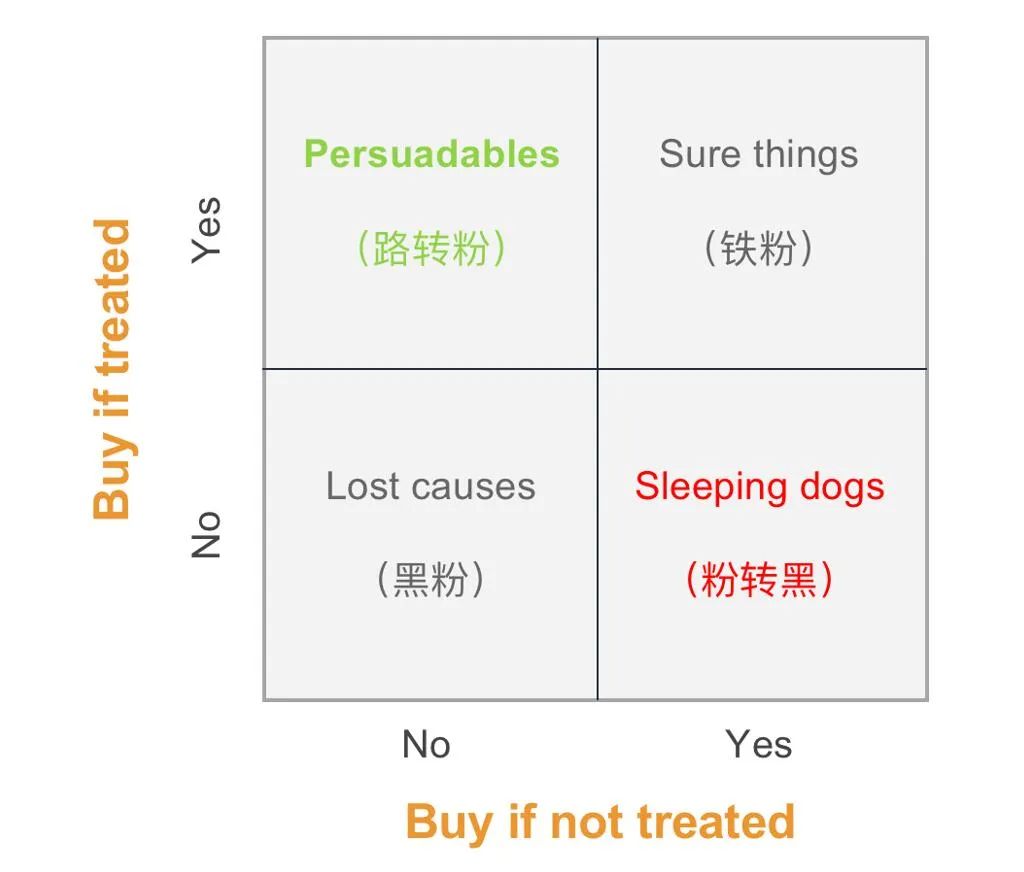
- 确定会购买的用户,不管我是否推荐这类用户都会购买(铁粉)
- 不管我是否推荐他都不会购买(黑粉),
- 我的推荐会提高用户购买转化的,如果不推荐他不会购买(路转粉)
- 是一些静默用户本来已经订阅了我们的服务,一旦收到我们的推荐提醒反而取消了订阅(粉转黑)。
审核编辑 :李倩
-
上海海思创新一站式集成开发环境HiSpark Studio开源2026-06-04 514
-
迅为3568开发板从零学习Linux驱动开发:迅为一站式资料包如何让我效率翻倍2025-11-05 700
-
一站式PCBA加工全流程大揭秘!从设计到交付一站式搞定2025-06-11 1612
-
一文解析一站式代工代料服务2025-06-10 1333
-
高性能BMS AFE打造一站式储能电池包高压监测解决方案2024-12-24 1755
-
一站式PCBA包工包料服务具有哪些明显的优势呢?2024-04-17 1120
-
为什么选择一站式PCBA加工?PCBA一站式服务的优势2024-01-03 1845
-
电子产业一站式服务平台华秋电子加入开放原子开源基金会,成为openDACS项目B类捐赠人2022-07-08 34734
-
使用NVIDIA TAO工具包构建对话AI和应用程序2022-04-01 2942
-
怎样去使用基于LiteOS一站式开发工具LiteOS Studio呢2021-11-26 2584
-
STM32CubeIDE属于一站式工具介绍2020-03-01 9513
-
嵌入式Linux 学习,一站式服务2015-03-25 2137
-
LinuxC编程一站式学习2012-08-26 6749
-
Linux C编程一站式学习2012-08-09 7694
全部0条评论

快来发表一下你的评论吧 !
