

使用 PCIe 交换矩阵优化多主机系统中的资源部署
今日头条
描述
数据中心和其他高性能计算环境越来越多地使用 GPU,因为它们能够快速处理深度学习和机器学习应用程序中生成的大量数据。然而,就像许多提高应用程序性能的新数据中心创新一样,新的系统瓶颈也暴露出来了。在这些应用程序中提高系统性能的新兴架构涉及通过 PCIe 结构在多个主机之间共享系统资源。
PCIe 标准,尤其是其传统的基于树的层次结构,限制了资源共享的实现方式(以及效果如何)。尽管如此,可以实施低延迟、高速结构方法,允许在多个主机之间共享 GPU 和 NVMe SSD 池,同时仍支持标准系统驱动程序。
PCIe 结构方法采用动态分区和多主机、单根 I/O 虚拟化 (SR-IOV) 共享。PCIe 结构直接跨结构路由对等传输。这允许对等传输的最佳路由,减少根端口拥塞并允许更有效的 CPU 资源负载平衡。
按照惯例,GPU 传输必须访问 CPU 的系统内存,这会导致端点之间的内存共享争用。当 GPU 使用其共享的内存映射资源而不是 CPU 内存时,它可以在本地摄取数据,从而无需首先通过 CPU 传递数据。这消除了跃点和链接以及由此产生的延迟,使 GPU 能够更有效地处理数据。
PCIe 的固有限制
PCIe 主要层次结构是一种树形结构,其中每个域有一个根复合体,从该点扩展为通过交换机和桥接端点的“叶子”。链路的严格层次结构和方向性对多主机、多交换机系统提出了昂贵的设计要求。
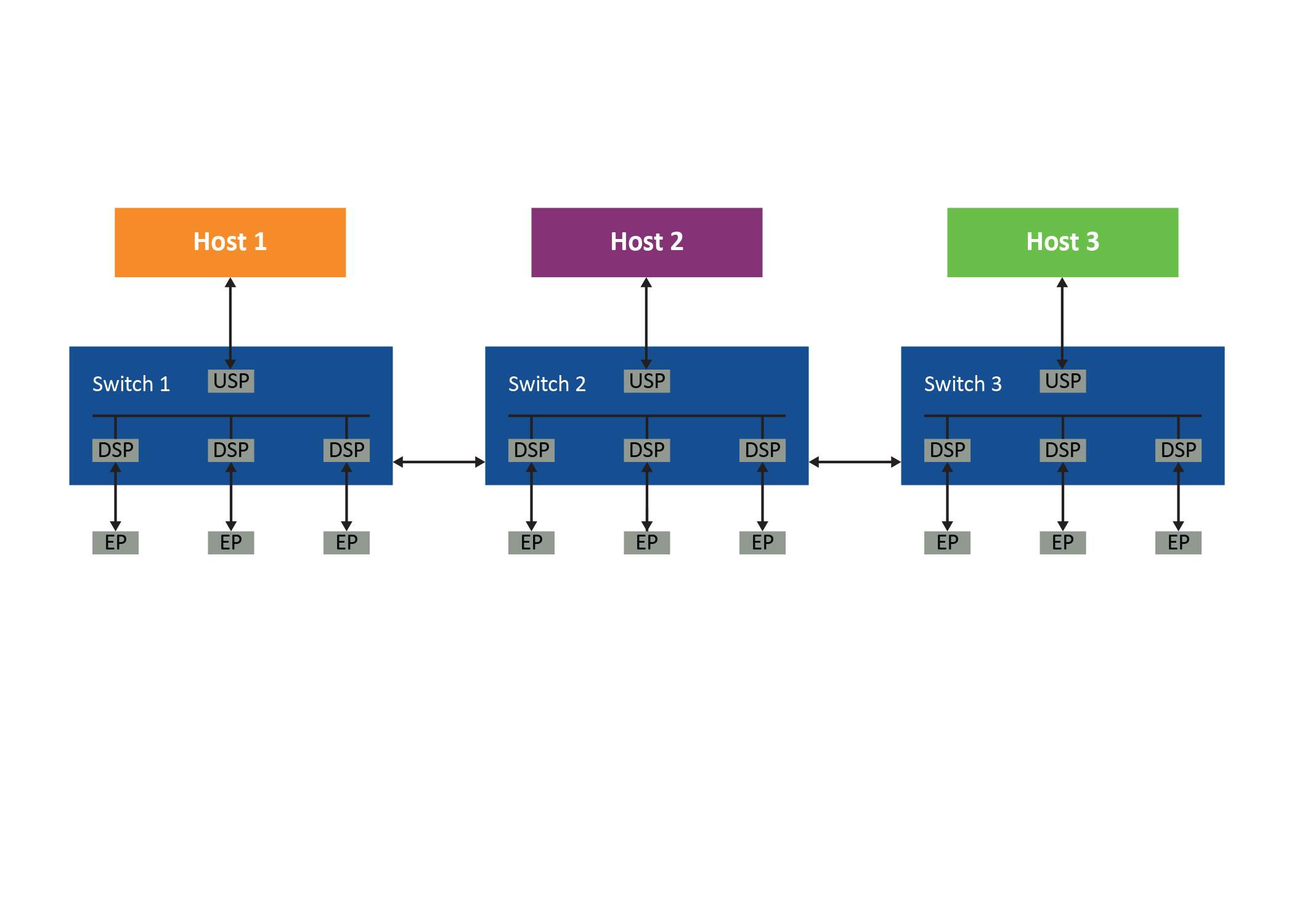
图 1:多主机拓扑
考虑图 1所示的系统。为了符合 PCIe 的层次结构,主机 1 必须在交换机 1 中有一个专用的下行端口,该端口连接到交换机 2 中的一个专用上行端口。它还需要交换机 2 中的一个专用下行端口连接到交换机 3 中的一个专用上行端口,等等。主机 2 和 3 也存在类似的要求,如图 2 所示。
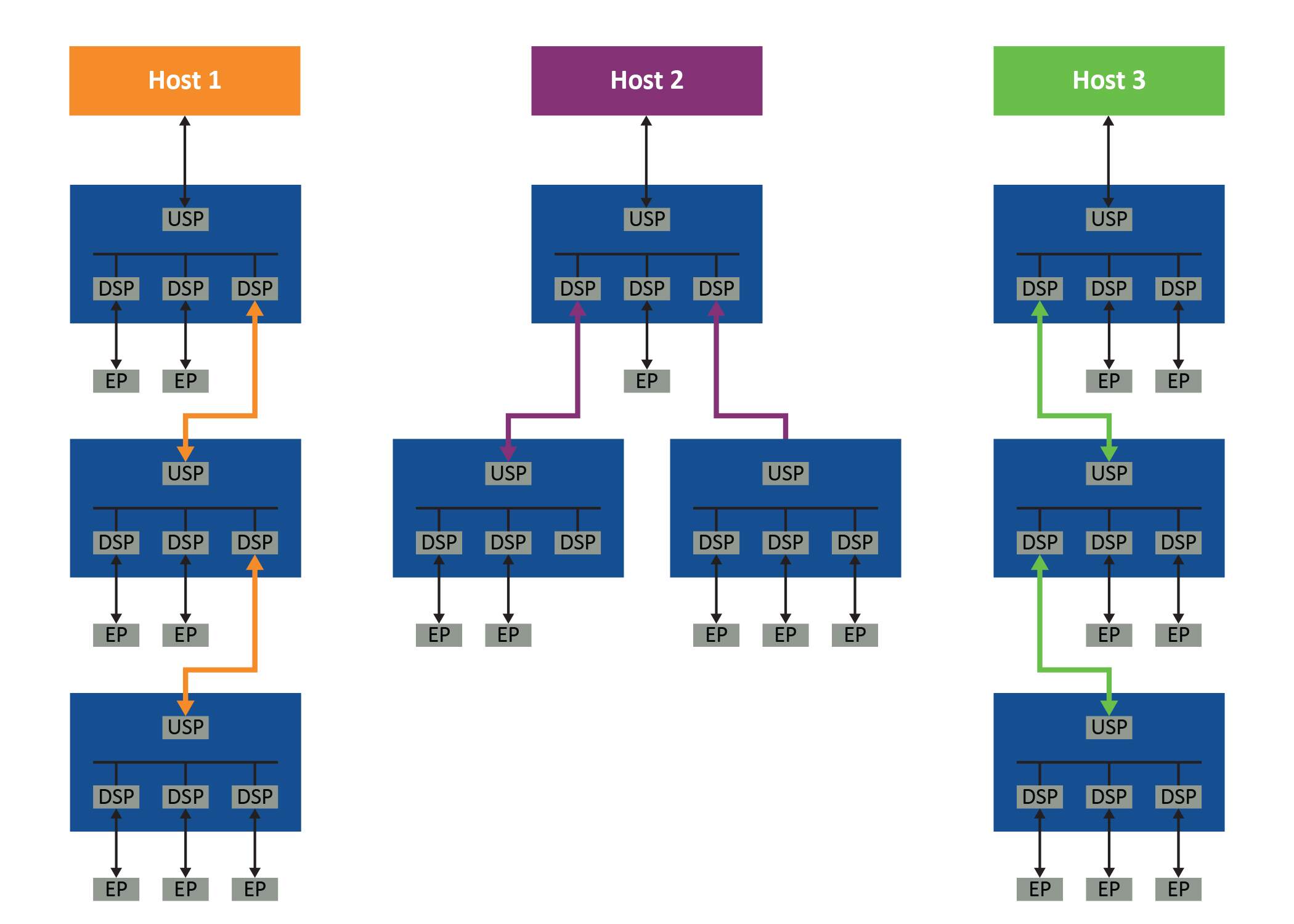
图 2:每个主机的层次结构要求
即使是最基本的基于 PCIe 树结构的系统也需要每个交换机之间的三个链路专用于每个主机的 PCIe 拓扑。而且由于无法在主机之间共享这些链接,系统很快就会变得非常低效。
此外,典型的符合 PCIe 的层次结构只有一个根端口,虽然多根 I/O 虚拟化和共享规范中支持多个根,但它使设计更加复杂,目前主流 CPU 不支持。结果是未使用的 PCIe 设备(即端点)被困在分配它们的主机中。在使用许多 GPU、存储设备及其控制器和交换机的大型系统中,不难想象这将变得多么低效。
例如,如果第一台主机(主机 1)消耗了所有计算资源,而主机 2 和 3 的资源未充分利用,那么主机 1 显然需要访问它们。但它不能,因为它们在其层次结构域之外,因此陷入困境。非透明桥接 (NTB) 是该问题的潜在解决方案,但也使系统变得复杂,因为它需要用于每种类型的共享 PCIe 设备的非标准驱动程序和软件。更好的方法是使用允许标准 PCIe 拓扑的 PCIe 结构来容纳可以访问每个端点的多个主机。
实现方法
该系统是使用 PCIe 架构交换机(在本例中是 Microchip 的 Switchtec PAX 系列的成员)在两个离散但透明可互操作的域中实现的:包含所有端点和架构链路的架构域以及专用于每个主机的主机域(图 3)。主机通过在嵌入式 CPU 上运行的 PAX 交换机固件保存在单独的虚拟域中,因此交换机将始终显示为具有直接连接端点的标准单层 PCIe 设备,无论这些端点出现在结构中的什么位置。
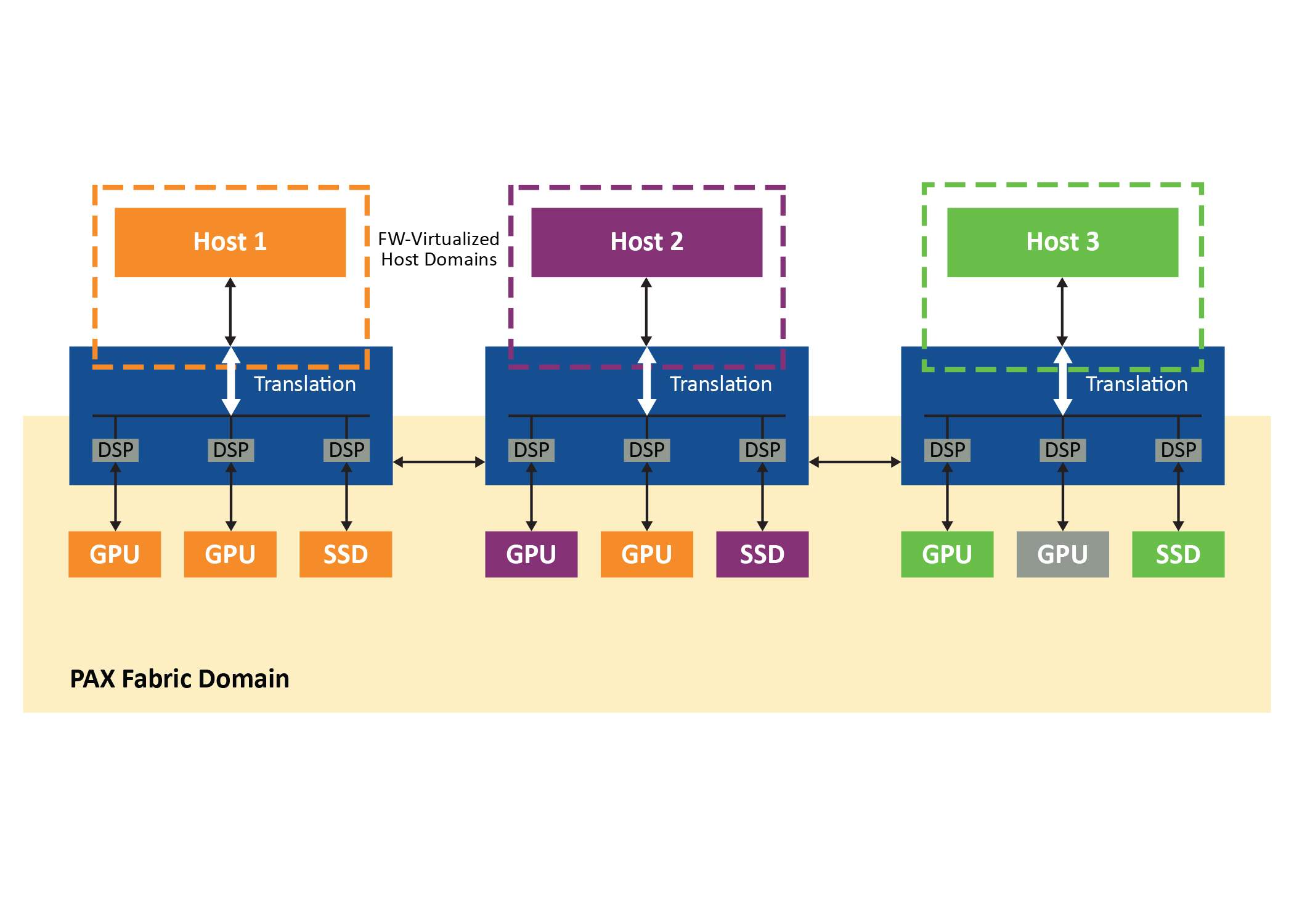
图 3:每个结构的独立域
来自主机域的事务被转换为结构域中的 ID 和地址,反之亦然,结构域中的流量的非分层路由。这允许系统中的所有主机共享连接交换机和端点的结构链路。交换机固件拦截来自主机的所有配置平面流量,包括 PCIe 枚举过程,并虚拟化一个简单的、符合 PCIe 规范的交换机,并具有可配置数量的下游端口。
虽然所有控制平面流量都路由到交换机固件进行处理,但数据平面流量直接路由到端点。其他主机域中未使用的 GPU 不再搁浅,因为它们可以根据每个主机的需要动态分配。结构内支持对等流量,使其能够适应机器学习应用程序。由于功能以符合 PCIe 规范的方式呈现给每个主机,因此可以使用标准驱动程序。
实际
应用要了解这种方法的工作原理,请考虑图 4中的系统,该系统由两台主机(主机 1 用于 Windows 主机 2 用于 Linux)、四个 PAX PCIe 结构交换机、四个 Nvidia M40 GPGPU 和一个三星 NVMe SSD支持 SR-IOV。在本练习中,主机运行代表实际机器学习工作负载的流量,包括 Nvidia 的 CUDA 点对点流量基准测试实用程序和训练 CIFAR-10 图像分类 TensorFlow 模型。嵌入式交换机固件处理交换机的低级配置和管理,系统由 Microchip 的 ChipLink 调试和诊断实用程序管理。
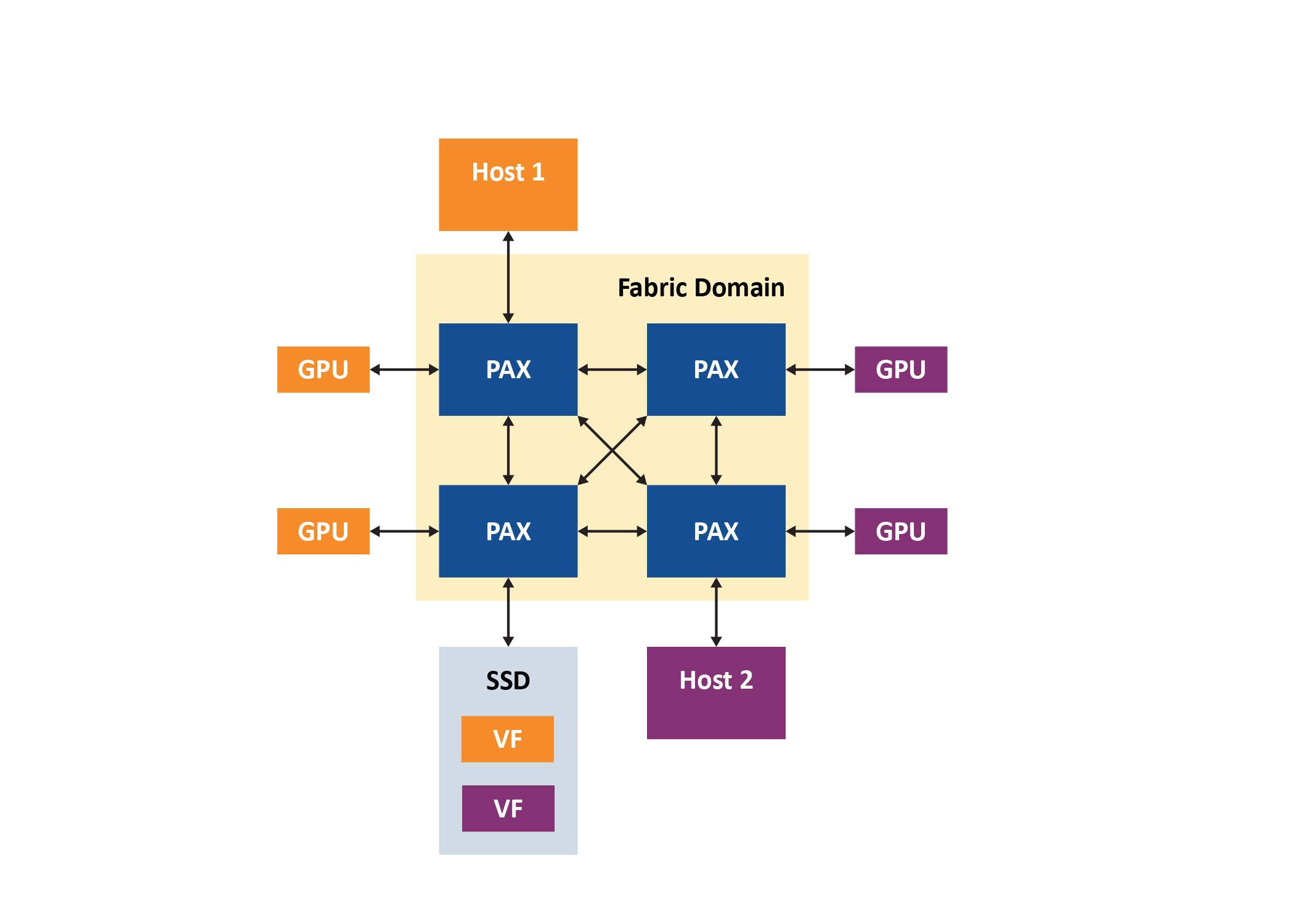
图 4:两主机 PCIe 结构引擎
四个 GPU 最初分配给主机 1,PAX 结构管理器显示在结构中发现的所有设备,其中 GPU 绑定到 Windows 主机。但是,主机掩盖了结构的复杂性,所有 GPU 看起来好像直接连接到虚拟交换机。然后结构管理器绑定所有设备,Windows 设备管理器显示 GPU。主机将交换机视为具有可配置数量的下游端口的简单物理 PCIe 交换机。
CUDA 发现四个 GPU 后,点对点带宽测试显示单向传输的速度为 12.8 GB/s,双向传输的速度为 24.9 GB/s。这些传输直接通过 PCIe 结构而不通过主机。运行 TensorFlow 模型训练 CIFAR-10 图像分类算法,工作负载分布在所有四个 GPU 上,可以将两个 GPU 释放回结构池,将它们与主机解除绑定。这可以释放剩余的两个 GPU 来执行其他工作负载。Linux 主机和它的 Windows 主机一样,可以看到一个简单的 PCIe 开关,而不需要自定义驱动程序,并且 CUDA 也可以发现 GPU 并在 Linux 主机上运行 P2P 传输。性能类似于使用 Windows 主机实现的性能,如表 1所示。
表 1:GPU 点对点传输带宽
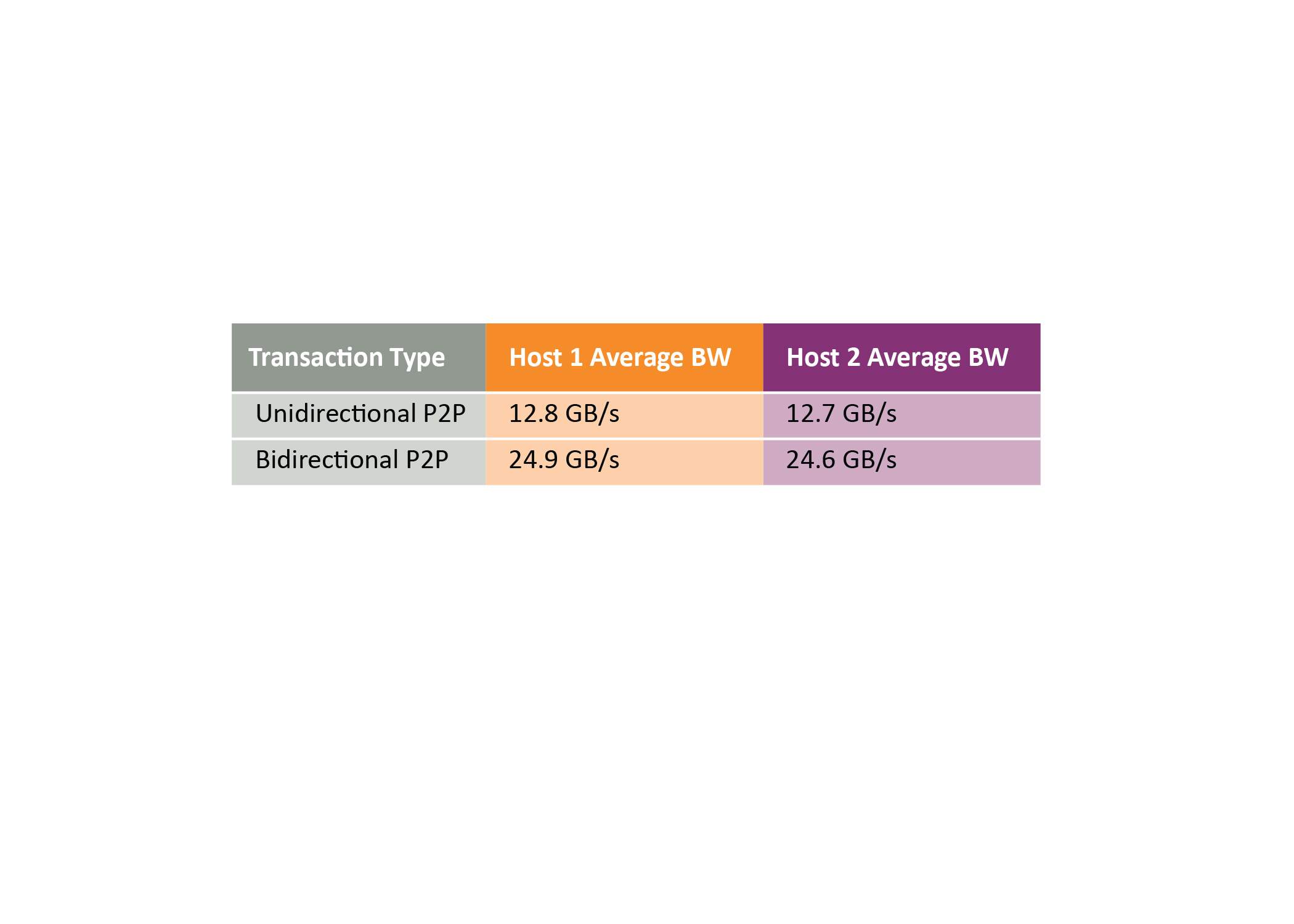
下一步是将 SR-IOV 虚拟功能附加到 Windows 主机,PAX 将其作为标准物理 NVM 设备呈现,允许主机使用标准 NVMe 驱动程序。在此之后,一个虚拟功能被组合到 Linux 主机,一个新的 NVMe 设备出现在块设备列表中。这个练习的结果是两台主机现在都可以独立使用它们的虚拟功能。
需要注意的是,虚拟 PCIe 开关和所有动态分配操作都以完全符合 PCIe 规范的方式呈现给主机,从而使主机能够使用标准驱动程序。嵌入式交换机固件提供了一个简单的管理接口,因此 PCIe 结构可以通过廉价的外部处理器进行配置和管理。设备点对点事务默认启用,不需要外部结构管理器的额外配置或管理。
总结
尽管 PCIe 标准本身存在一些障碍,但 PCIe 交换结构是充分利用 CPU 的海量性能的绝佳手段。但是,可以通过使用动态分区和多主机单根 I/O 虚拟化共享技术来解决这些限制,从而可以将 GPU 和 NVMe 资源实时动态分配给多主机系统中的任何主机以满足机器学习工作负载的不同需求。
-
FPGA的PCIE接口应用需要注意哪些问题2024-05-27 3483
-
PCIe协议分析仪能测试哪些设备?2025-07-25 1742
-
C6678通过PCIe与windows xp主机连接及设备资源分配的问题!!!2018-05-25 4701
-
基于PCIe DMA的多通道数据采集和回放IP2020-11-25 2528
-
Embedded SIG | 多 OS 混合部署框架2022-06-29 1733
-
多单片机系统中的数据交换2009-05-15 687
-
如何使用两段式的加速资源部署算法提高网络利用率2019-01-04 1375
-
Switchtec PAX网络互联Gen 4 PCIe交换机系列现已投产2020-06-24 3367
-
使用PCIe交换网结构在多主机系统中优化资源部署2020-10-26 3208
-
如何使用PCIe交换网结构在多主机系统中优化资源部署2022-08-01 2472
-
如何优化 PCIe 应用中的时钟分配2022-11-07 689
-
PEX8749 PCIe交换机Broadcom2023-06-06 2412
-
PEX8733 PCIe交换机Broadcom2023-07-04 2064
-
如何利用RAKsmart服务器实现高效多站点部署方案2025-05-19 735
-
PCI11101 PCIe交换机集成USB3.2主机控制器技术解析2025-10-10 1301
全部0条评论

快来发表一下你的评论吧 !
