

基于配准的少样本异常检测的框架
描述
近年来,异常检测在工业缺陷检测、医疗诊断,自动驾驶等领域有着广泛的应用。“异常”通常定义为 “正常” 的对立面,即所有不符合正常规范的样本。通常来说,相比于正常,异常事件的种类是不可穷尽的,且十分稀有,难以收集,因此不可能收集详尽的异常样本进行训练。因此,近期关于异常检测的研究主要致力于无监督学习,即仅使用正常样本,通过使用单类别(one-class)分类,图像重建(reconstruction),或其他自监督学习任务对正常样本进行建模,之后,通过识别不同于模型分布的样本来检测异常。
大多数现有的异常检测方法都专注于为每个异常检测任务训练一个专用模型。然而,在诸如缺陷检测之类的真实场景中,考虑到要处理数百种工业产品,为每种产品均收集大量训练集是不划算的。对此,上海交通大学 MediaBrain 团队和上海人工智能实验室智慧医疗团队等提出了一个基于配准的少样本异常检测框架,通过学习多个异常检测任务之间共享的通用模型,无需进行模型参数调整,便可将其推广到新的异常检测任务。目前,这项研究已被 ECCV2022 接收为 Oral 论文,完整训练代码及模型已经开源。

方法简介
在这项工作中,少样本异常检测通用模型的训练受到了人类如何检测异常的启发。事实上,当尝试检测图像中的异常时,人们通常会将该检测样本与某个已经被确定为正常的样本进行比较,从而找出差异,有差异的部分就可以被认为是异常。为了实现这种类似于人类的比较的过程,本文作者采用了配准技术。本文作者认为,对于配准网络而言,只要知道如何比较两个极度相似的图像,图像的实际语义就不再重要,因此模型就更能够适用于从未见过的异常检测新任务。配准特别适用于少样本异常检测,因为配准可以非常方便地进行跨类别推广,模型无需参数微调就能够快速应用于新的异常检测任务。
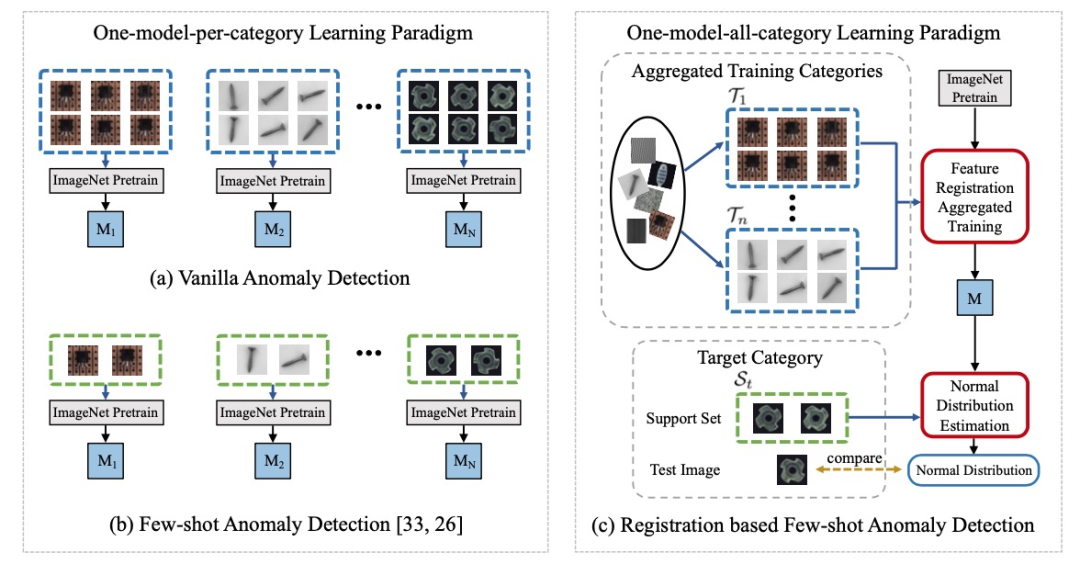
上图概述了基于配准的少样本异常检测的框架。与常规的异常检测方法(one-model-per-category)不同,这项工作(one-model-all-category)首先使用多类别数据联合训练一个基于配准的异常检测通用模型。来自不同类别的正常图像一起用于联合训练模型,随机选择来自同一类别的两个图像作为训练对。在测试时,为目标类别以及每个测试样本提供了由几个正常样本组成的支撑集。给定支撑集,使用基于统计的分布估计器估计目标类别注册特征的正态分布。超出统计正态分布的测试样本被视为异常。
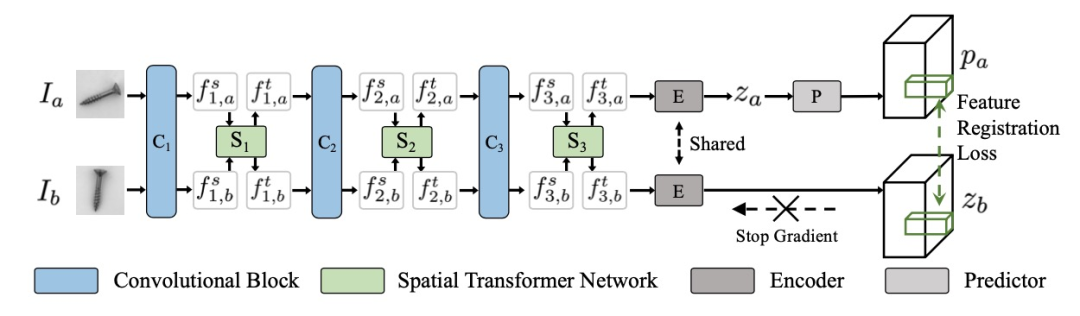
这项工作采用了一个简单的配准网络,同时参考了 Siamese [1], STN [2] 和 FYD [3]。具体地说,以孪生神经网络(Siamese Network)为框架,插入空间变换网络(STN)实现特征配准。为了更好的鲁棒性,本文作者利用特征级的配准损失,而不是像典型的配准方法那样逐像素配准,这可以被视为像素级配准的松弛版本。
实验结果
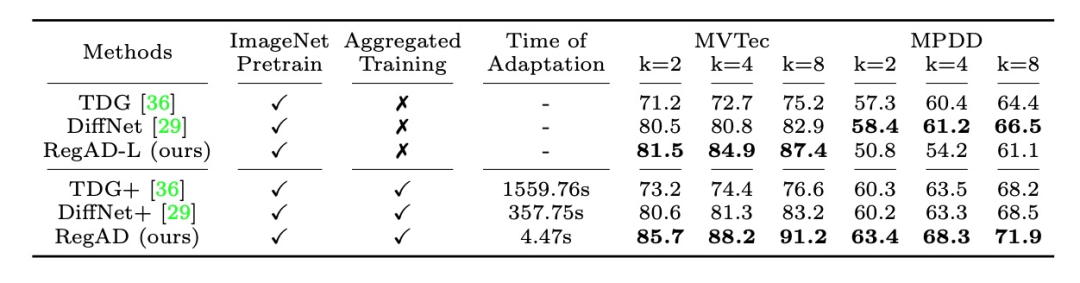
在与其他少样本异常检测方法的比较上,RegAD 无论在检测性能、适用到新类别数据的自适应时间上,相比于基准方法 TDG [4] 和 DiffNet [5] 都有显著的优势。这是由于其他的方法都需要针对新的类别数据进行模型的多轮迭代更新。另外,RegAD 相比于没有进行多类别特征配准联合训练的版本(RegAD-L),性能也得到了显著的提升,体现出基于配准的通用异常检测模型的训练是十分有效的。本文在异常检测数据集 MVTec [6] 和 MPDD [7] 上进行实验。更多的实验结果和消融实验可参考原论文。
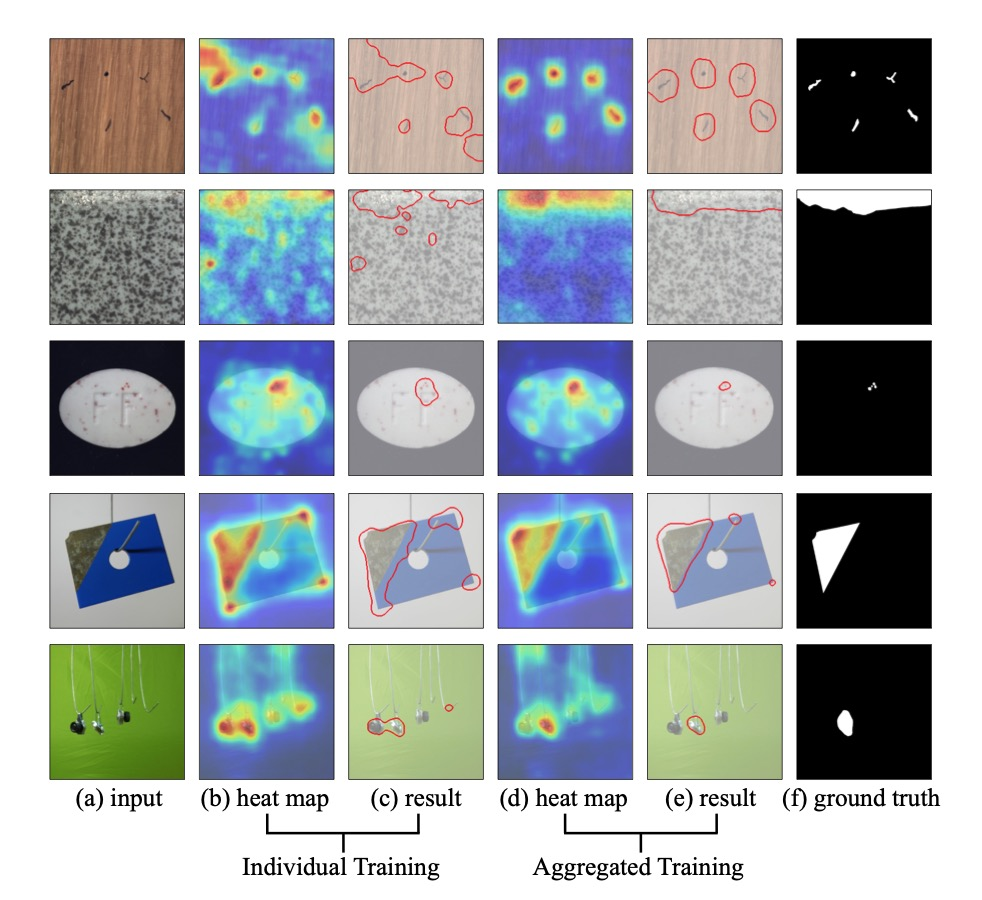
此外,作者还展示了异常定位可视化的结果。可以看到,联合训练可以使得模型的异常定位变得更加准确。
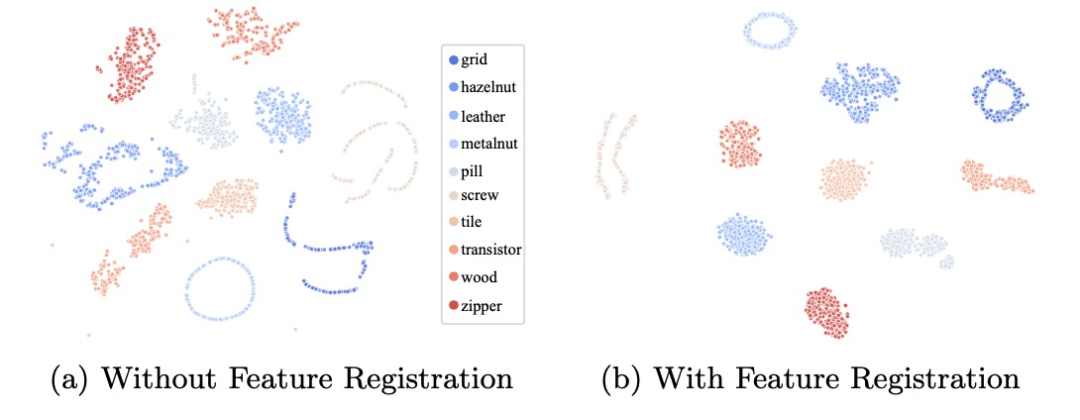
T-SNE 的可视化也显示出,基于配准的训练可以使得同类别的正常图像特征变得更加紧凑,从而有利于异常数据的检出。
总结
这项工作主要探索了异常检测的一个具有挑战性但实用的设置:1)训练适用于所有异常检测任务的单一模型(无需微调即可推广);2)仅提供少量新类别图像(少样本);3)只有正常样本用于训练(无监督)。尝试探索这种设置是异常检测走向实际大规模工业应用的重要一步。为了学习类别无关的模型,本文提出了一种基于比较的解决方案,这与流行的基于重建或基于单分类的方法有很大不同。具体采用的配准模型建立在已有的配准方案基础上,充分参考了现有的杰出工作 [1,2,3],在不需要参数调整的前提下,在新的异常检测数据上取得了令人印象深刻的检测效果。
-
基于恒星配准的空间点目标检测算法2009-12-19 812
-
少缺陷样本的PCB焊点智能检测方法_卢盛林2017-02-07 793
-
基于异常区域的高分辨率遥感图像配准2017-12-11 1265
-
基于时间卷积网络的通用日志序列异常检测框架2021-03-30 1670
-
基于生成对抗网络的异常检测方法2022-04-06 4335
-
如何在缺陷样本少的情况下实现高精度的检测2023-06-26 2967
全部0条评论

快来发表一下你的评论吧 !
