

轻量级视觉模型设计的新启发
描述
计算机视觉两大门派功力合体,给移动端视觉任务减负增速。
当下,计算机视觉领域最热议的方向,莫过于近两年越来越火的视觉Transformer(ViT)和传统的卷积神经网络(ConvNet),谁才能主宰计算机视觉的未来?
风头正盛的ViT,是计算机视觉领域过去十年最瞩目的研究突破之一。2020年,谷歌视觉大模型Vision Transformer(ViT)横空出世,凭借碾压各路ConvNet的性能表现,一举掀起Transformer在计算机视觉领域的研究热潮。
但“ConvNet派”还没到低头认输的时候。2022年1月,Meta AI研究院、加州大学伯克利分校的研究人员发表了卷积神经网络的“扛鼎之作”——ConvNeXt,基于纯ConvNet新架构,取得了超过先进ViT的计算速度和精度。
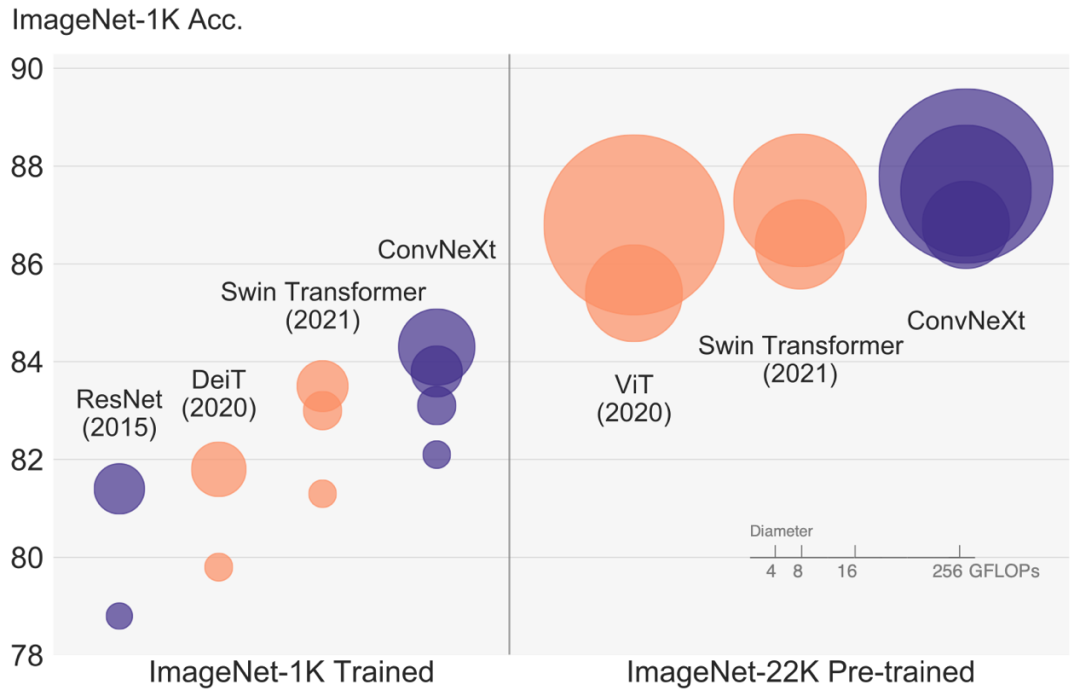
▲ConvNet与ViT模型图像分类实验结果对比
ViT论文:https://arxiv.org/abs/2010.11929
ConvNeXt论文:https://arxiv.org/abs/2201.03545
那如果将这两类模型的优势互补,会不会产生1+1》2的效果?
近日,基于这一思路的论文《ParC-Net:继承ConvNet和Transformer优点的位置敏感的循环卷积》入选了计算机视觉顶会ECCV 2022,并引发国内外广泛关注。
这篇论文提出了一种面向移动端、融入ViT优点的纯卷积结构模型ParC-Net,能以更小的参数量,在常见视觉任务中实现比主流轻量级ConvNet更好的性能。

▲ParC-Net在三种视觉任务实验中均以更小参数量取得最佳性能表现
值得一提的是,论文提出一种既有全局感受野、又对位置信息保持敏感的基础卷积算子ParC,它能与现有主流网络结构融合,兼顾模型性能和计算速度的提升,相关代码现已开源。
具体是怎么实现的?我们联系到论文第一作者张号逵博士,并与其进行深入交流。
ParC论文:https://arxiv.org/abs/2203.03952
源代码:https://github.com/hkzhang91/ParC-Net
01.
取ViT的三个亮点,将纯卷积结构变强
在计算机视觉领域,ViT模型性能彪悍,门槛和成本却惊人,无论是庞大数据量,还是超高算力需求,都离不开“钞能力”的支撑。
相比之下,轻量级ConvNet虽然性能难以与ViT媲美,但具有易训练、参数量少、计算成本低、推理速度快等优势,对硬件资源的需求不像ViT那么受限,可部署在各种移动或边缘计算设备上。此前较流行的轻量级ConvNet有ShuffleNet、MobileNet、EfficientNet、TinyNet等等。
经对比,云天励飞的研究人员借鉴ViT的优点,基于卷积结构设计了一个轻量级骨干模型ParC-Net。
论文作者认为,ViT和ConvNet有三个主要区别:ViT更擅长提取全局特征,采用meta-former结构,而且信息集成由数据驱动。ParC的设计思路便是从这三点着手来优化ConvNet。
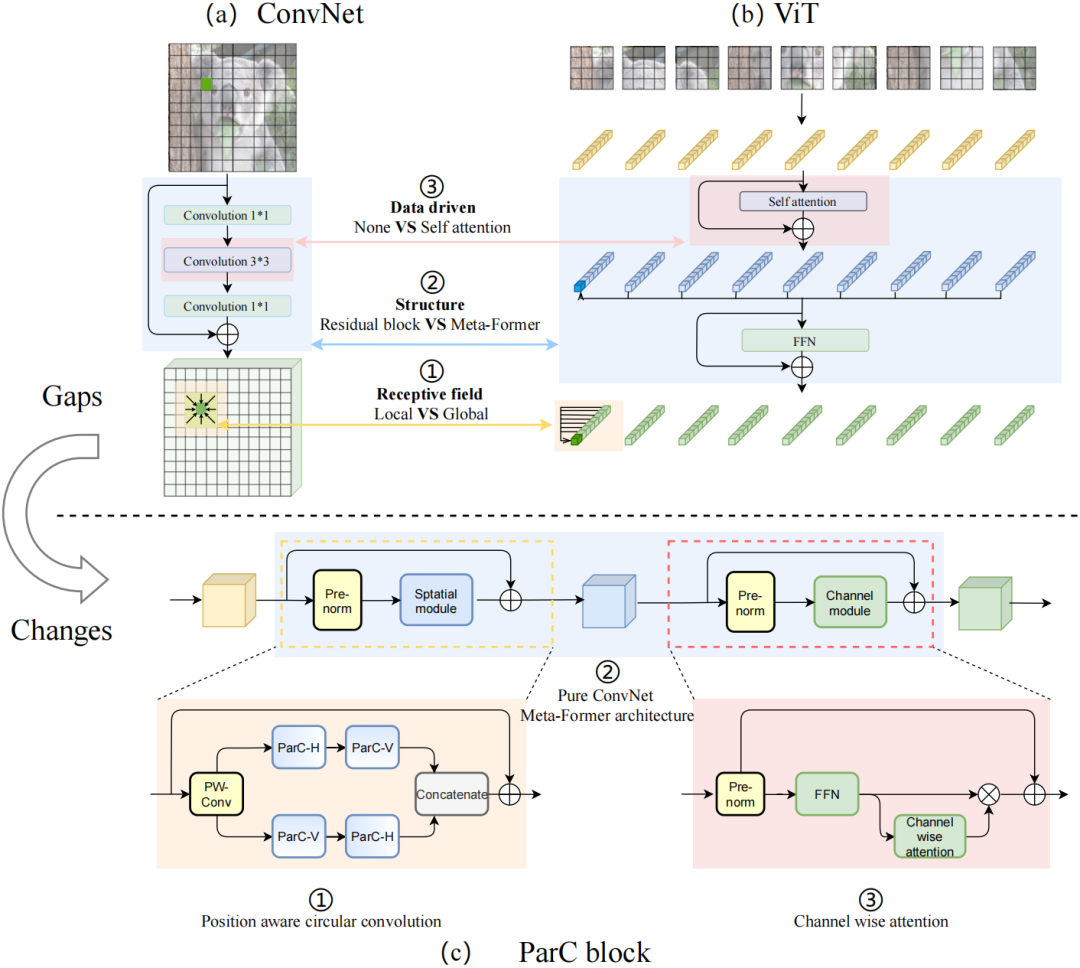
▲普通ConvNet和ViT之间的三个主要区别。(a) ConvNet常用的Residual block;(b) ViT中常用的Meta-Former 结构;(c) 本文提出的ParC block。
具体而言,研究人员设计了一种位置信息敏感的循环卷积(Position aware circular convolution, ParC)。这是一种简单有效的轻量卷积运算算子,既拥有像ViT类结构的全局感受野,同时产生了像局部卷积那样的位置敏感特征,能克服依赖自注意力结构提取全局特征的问题。
ParC结构主要包含三部分改动:1)结合circular padding和大感受野低秩分解卷积核提取全局特征;2)引入位置嵌入,保证输出特征对于空间位置信息的敏感性;3)动态插值实时生成尺寸适配的卷积核和位置编码,应对输入分辨率变化情况,这增强了对不同尺寸输入的适应能力。
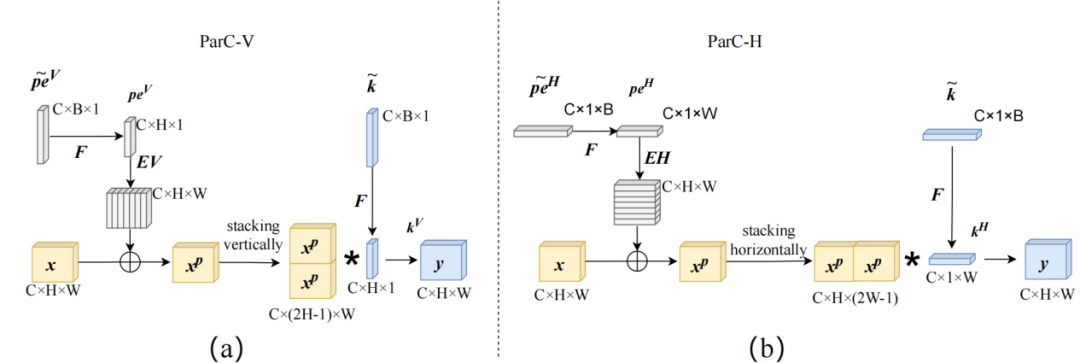
▲ParC结构示例
研究人员还将ParC和squeeze exictation(SE)操作结合起来,构建了一个纯卷积结构的meta former结构。该结构舍弃了自注意力硬件支持不友好的操作,但保留了传统Transformer块提取全局特征的特点。
然后,研究人员在channel mixer部分引入硬件支持较友好的通道注意力机制,使其纯卷积meta former结构也具备自注意力的特点。
基于ParC结构最终得到的ParC块,可作为一个即插即用的基础单元,替换现有ViT或ConvNet模型中的相关块,从而提升精度,并降低计算成本,有效克服硬件支持的问题。
▲ParC实验结果
02.
三大视觉任务表现出色 多项指标打败苹果MobileViT
“据我们所知,这是第一次尝试结合ConvNet和ViT的优点来设计一个轻量级Pure-ConvNet的结构。”论文作者如此描述ParC-Net的开创性。
实验结果表明,在图像分类、物体检测、语义分割这三类常见的视觉任务中,混合结构的模型性能表现普遍高于当前主流的一些纯卷积结构、ViT结构的模型,其中ParC-Net模型取得了最好的整体性能表现。
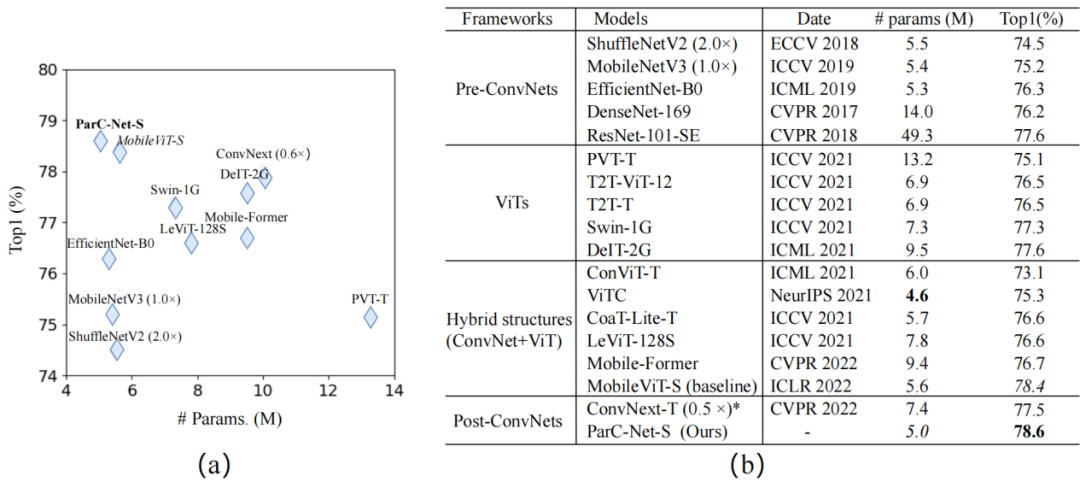
▲对于ImageNet-1k的图像分类实验结果
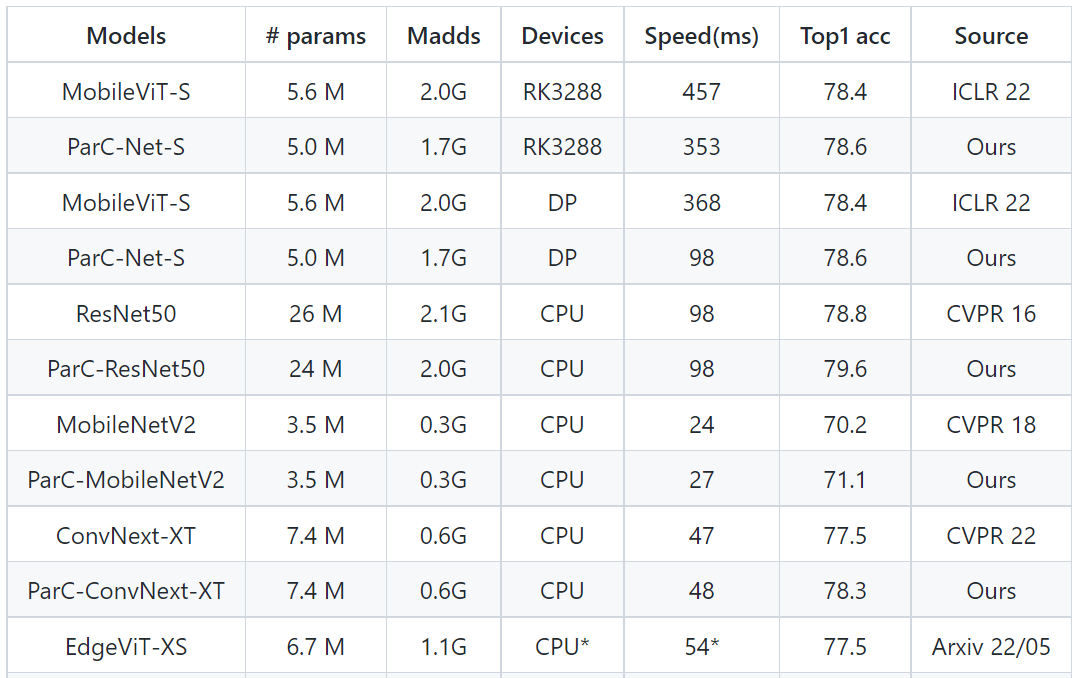
在图像分类实验中,对于ImageNet-1k的分类,ParC-Net使用的参数规模最小(大约500万个参数),却实现了最高准确率78.6%。
MobileViT是苹果公司2022年在国际深度学习顶会ICLR22上提出的轻量级通用ViT模型。同样部署在基于Arm的瑞芯微RK3288芯片上,相较基线模型MobileViT,ParC-Net节省了11%的参数和13%的计算成本,同时准确率提高了0.2%,推理速度提高了23%。

▲与基准模型的推理速度对比
与基于ViT结构的模型相比,ParC-Net的参数量只有Meta AI团队DeiT模型参数的一半左右,准确率却比DeiT提高了2.7%。
在MS-COCO物体检测和PASCAL VOC分割任务中,ParC-Net同样基于较少的参数,实现了更好的性能、更快的推理速度。
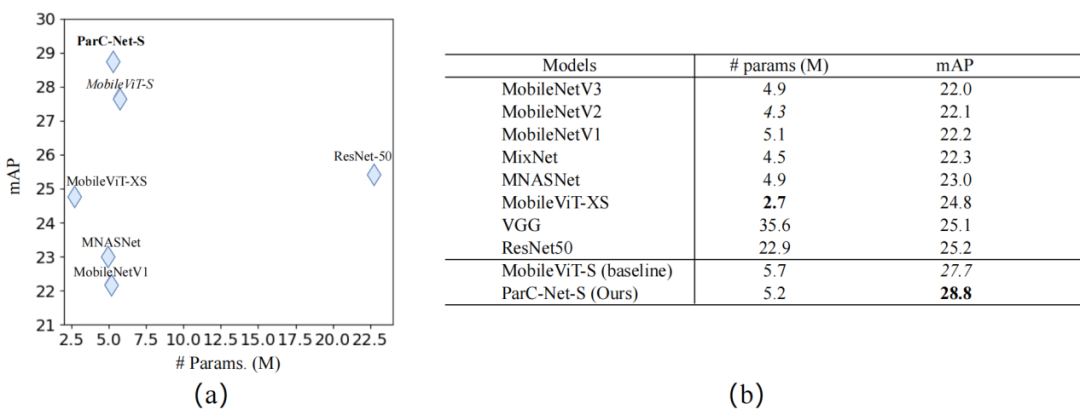
▲MS-COCO物体检测实验结果
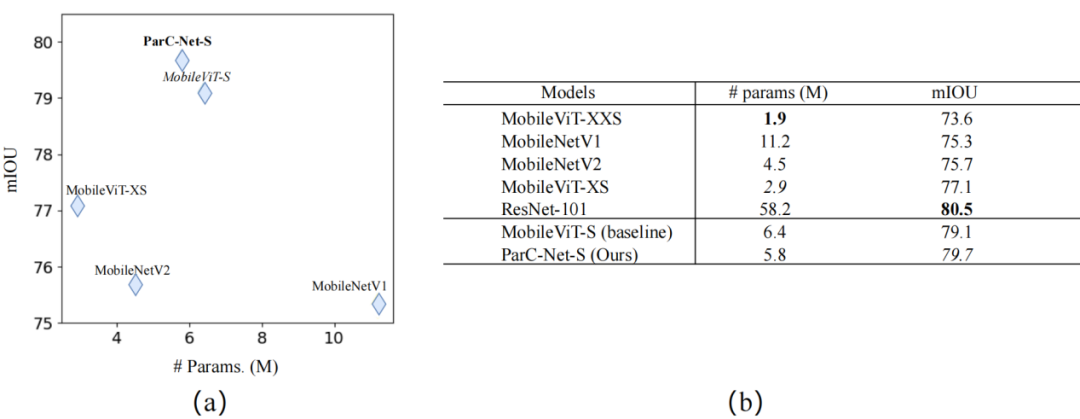
▲PASCAL VOC分割任务实验结果
张号逵博士是ParC-Net论文的第一作者,现任深圳云天励飞资深算法研究员,研究领域包括网络结构搜索、深度估计、轻量化骨干模型、信息检索及高光谱图像分类等。
他告诉智东西,传统ConvNet可以适应视觉任务中输入分辨率的变化,而具有全局感受野的纯卷积结构的缺陷是卷积核必须跟输入分辨率保持一致,为了更好应对分辨率的变化,其团队正在研究将模型做成动态卷积的形式,以提高鲁棒性。
目前这项研究成果已经可以用在算力受限的移动端或边缘设备中,实现更高准确率的视觉任务。如果进行一些小的改动,ParC-Net还可以被用于其他的视觉任务,例如6DOF姿态评估及其他dense prediction的任务。
03.
与自研芯片协同 运算速度可提升快3~4倍
那么ParC-Net模型的研究成果,具体如何在实际业务场景中发挥价值?
据介绍,一方面,ParC-Net模型可以集成到开源算法训练平台YMIR中,然后被部署至终端设备;另一方面,通过与云天励飞自研芯片协同,它能将运算速度和精度进一步提升。
YMIR是一个高度自动化的AI模型开发平台,能做到利用鼠标简单操作就可以完成数据收集、模型训练、数据挖掘、数据标注等功能。将拥有高运算效率的ParC-Net模型版本上传至YMIR后,用户可在该平台上直接选用ParC-Net模型,也可以针对具体业务场景,添加相应的数据集对ParC-Net进行再训练,从而获得能更好满足业务需求的模型。
以前有些对精度要求高或者采用ViT结构的移动端视觉任务,受限于计算效率问题,难以在摄像头设备或手机上运行,而上传到云端做运算,对有较高实时性要求的视觉任务不是很友好。
ParC-Net则较好地改善了这类问题,在模型精度和推理效率之间实现平衡,使得边缘设备可以在本地运行一些对精度要求高的视觉任务。比如,人脸识别终端设备可运用ParC-Net直接对路过的人进行高质量特征值提取,无需将数据传输到云端,就能与数据库进行检索比对。
与云天励飞自研芯片搭配后,ParC-Net模型的性能表现还能再上一个台阶。
张号逵博士谈道,其团队考虑到软硬件设计协同问题,在研发之初参考了云天励飞自研芯片工具链的设计及算子支持情况,然后进行模型网络结构及算子的设计,以更好地发挥出芯片算力。
研究人员将ParC-Net和基线模型MobileVit均部署到自研低功耗芯片DP上进行推理速度测试。从实验结果可以看到,ParC-Net的推理速度能够达到MobileViT速度的3~4倍。

▲与基准模型在不同芯片平台上的推理速度对比
这也是研究团队决定选择基于纯卷积结构来设计ParC-Net的原因之一。ConvNet已经统治计算机视觉领域十年之久,而ViT在这一领域兴起时间较短,很多现有的神经网络加速器、硬件优化策略,都是围绕卷积结构设计。因此部署在移动端时,纯ConvNet往往能比ViT享有更好的软硬件及工具链支持,并实现更快的推理速度。
即便搭载在对支持ViT更友好的芯片上,张号逵博士说,ParC-Net依然能取得比现有其他混合模型更好的性能表现。
绝大多数视觉任务可以分为两类:一类对位置信息不敏感,如图像分类等;另一类对位置信息较敏感,如物体检测、3D姿态估计、AR试穿等。对于这些视觉任务,无论用在智能门禁、手机识图还是自动驾驶汽车的摄像头,ParC-Net都能够发挥出其兼顾模型精度和计算效率的优势,并且不会受部署终端设备配置的限制。
04.
结语:轻量级视觉模型设计的新启发
当前ViT与ConvNet两大研究方向在计算机视觉领域旗鼓相当,ViT在学术界四处屠榜,ConvNet则在工业界主导地位难以撼动,将两者融合的相关研究也如雨后春笋般涌现。
此次入选ECCV顶会的ParC-Net模型,既顾及边缘设备对模型规模的限制,基于纯卷积结构,确保其具备易训练、易部署、推理效率高、硬件更友好等特点,又吸纳了ViT的设计特征,实现比其他ConvNet模型更高的精度。这可以给移动端视觉任务的模型设计带来一些启发。
审核编辑 :李倩
-
创建51轻量级操作系统2016-09-29 4293
-
10个轻量级框架2019-07-17 2557
-
轻量级深度学习网络是什么2020-04-23 3177
-
轻量级的ui框架如何去制作2021-07-14 1277
-
Dllite_micro (轻量级的 AI 推理框架)2021-08-05 2044
-
Lite Actor:方舟Actor并发模型的轻量级优化2022-07-18 4753
-
基于ARM的轻量级TCPIP协议栈的移植及应用2011-10-14 1461
-
基于树形模型的轻量级RFID组证明协议OTLP和FLTP2018-03-05 1412
-
基于YOLO改进的轻量级交通标识检测模型2021-04-19 1454
-
轻量级的SDN数据包转发验证方案2021-06-08 1171
-
首届risc-v中国峰会:一种轻量级仿真快照LightSSS2021-06-23 2974
-
PSoC NeoPixel Easy轻量级库2022-11-17 1013
-
测评分享 | 如何在先楫HPM6750上运行轻量级AI推理框架TinyMaix2022-12-12 3118
-
轻量级数据库有哪些2023-08-28 7972
-
百度智能云推出全新轻量级大模型2024-03-22 1621
全部0条评论

快来发表一下你的评论吧 !
