

浅谈GPU网络中光互连的光通信技术
通信网络
描述
作者:韩佳巍 光启智能研究院
摘要
GPU加速的计算系统可为诸多科学应用提供强大的计算能力支撑,亦是业界推动人工智能革命的重要手段。为了满足大规模数据中心和高性能计算场景的带宽拓展需求,光通信和光互连技术正在迅速而广泛地渗入此类系统的各个网络或链路层级。作为系列文章的第二篇,本文试图对GPU网络中光互连的光通信技术选项和长期技术需求做出简要分析。
在前篇“面向GPU网络的光互连(1):房间里有两头大象?”中,我们对GPU网络中光互连的历史趋势、短期的需求和权衡做出了简要梳理。在本篇中,读者不妨以一个随意涉猎者的身份、兴之所至地由笔者继续引导,将GPU网络中光互连的光通信技术、长期的技术需求等方面浏览一番。
01光通信的群星闪耀时
面对多GPU互连的高性能计算(High-Performance Computing, HPC)系统,本节尝试将具有高度适用性的若干种光通信技术选项做出“点到为止”的概要性描述。这样做,虽说是缘于笔者自身学养和全文篇幅的限制,但同时也有不妨碍读者自己去进一步深入阅读相关文献资料的好处。
1.1垂直腔面发射激光器光纤链路技术
从历史上来看,应用于数据通信或计算机通信的低成本光互连是建立在垂直腔面发射激光器(Vertical-Cavity Surface-Emitting Laser, VCSEL)和多模光纤的技术基础之上的[1]。VCSEL采用布拉格反射镜作为激光腔的腔镜,其横向结构通常为圆形对称,输出光束也为圆形对称,可与多模光纤实现高效耦合。尤为值得一提的是,机架到机架的集群互连结构便是广泛采用了基于上述技术的并行光模块。区别于电信场景中被广泛使用的单模技术,多模技术具有相对更为宽松的对准公差。相较于边发射单模激光器,多模VCSEL为人们测试光源提供了一个更为简单且便宜的方案;同时,多模VCSEL容易实现二维阵列集成,亦在功率效率方面具备明显优势。因此,虽然多模光纤的传输距离(通常在100米至数百米范围内,且随着数据速率的增大而减小)受限于不同模式之间的路径差异,但它依然是短距离数据通信和计算机通信的重要媒介。
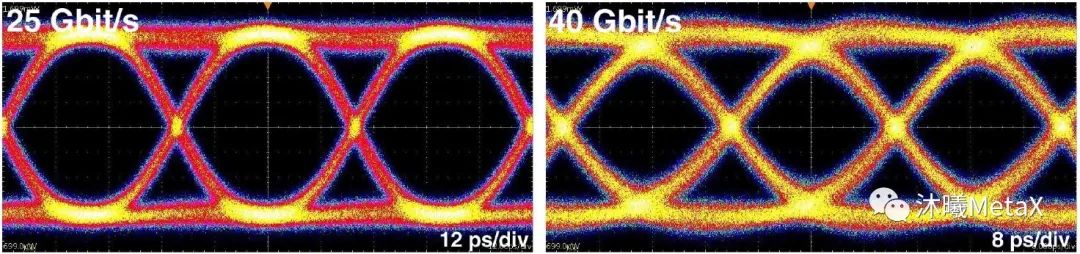
图1. 工作于25 Gbit/s和40 Gbit/s的高速原型VCSEL发射眼图
(来源于参考资料[2])
尽管VCSEL光纤链路技术占据着最为庞大的互连市场份额,且已经具备了低成本的制造基础设施,但是其改进空间仍然十分广阔。当前,许多中国大陆的VCSEL供应商已可高标准地实现适用于100 Gbit/s以太网的25 Gbit/s非归零码VCSEL光纤链路技术(4×25 Gbit/s并行光路)。图1为实验室实例演示中工作于25 Gbit/s和40 Gbit/s的VCSEL发射眼图[2]。为了充分满足数据中心或HPC系统中的光互连对于VCSEL链路的大量需求,人们正对高速率VCSEL的大规模制造方案做出广泛讨论和尝试。
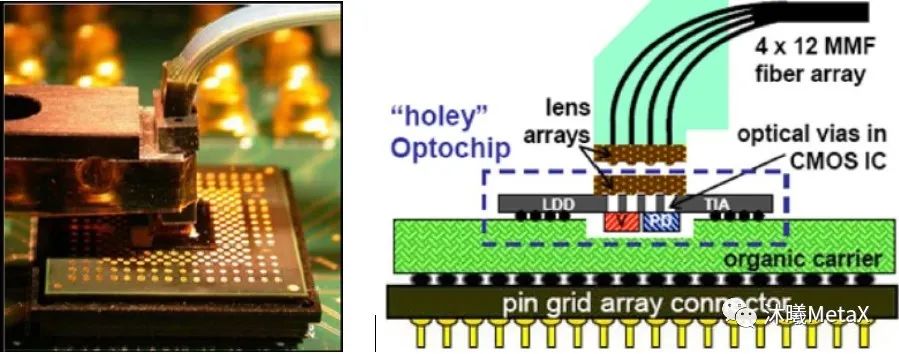
图2. 高密度光互连收发器制作原型
(来源于参考资料[3])
VCSEL光纤链路技术也正在向着更高速率、更低成本、更小功耗和更紧凑模块的方向继续演进。图2展示了一种高度紧凑的光模块制作原型。该模块采用倒装芯片方式,将VCSEL阵列和光电二极管阵列附着在一个具有“光通孔”(硅基底中的孔洞)的CMOS芯片上,从而实现与一组多模光纤阵列的耦合。该光模块在实现300 Gbit/s(24×12.5 Gbit/s)的同时,可以达到的功耗和带宽密度分别是8.2 pJ/bit和1 Tbps/cm2。
虽然VCSEL光纤链路长期以来(自1998年1 GbE被采用开始)是以850 nm作为标准波长的,但是人们对最佳波长的争论却一直在持续[4]。近几年,在使用铝镓砷和铟镓砷合金的基础上,处于900-1100 nm波段范围的长波长再次引起了学界和业界的广泛兴趣。该现象的促进因素包括:潜在的速率、效能和可靠性的提升,背发射VCSEL的制作(砷化镓基底在长波段范围内有着高度无损透明性,更适用于新型封装)更加简便,低成本粗波分复用收发器的使用,光电探测器在长波段范围内的响应度略有优势(每单位光功率可生成较大电流),以及长波长对人眼更为安全等[5]。然而,由于损耗在长波段范围内相对较大,这类长波长在搭配塑料光纤使用时却反倒具有一些劣势(如下文1.2部分所述)。
上述长波长VCSEL光纤链路在功率变换效率和可靠性方面均取得了长足进步。然而,人们又继而发现,在给定VCSEL结构的条件下,VCSEL的失效机制在整个780-910 nm波段范围内并无显著差别[6]。与此同时,学界和业界对于850 nm光器件的研发也有着不俗表现:仅以25-50 Gbit/s VCSEL为例,其功率损耗已经能够小于100 fJ/bit [7]。
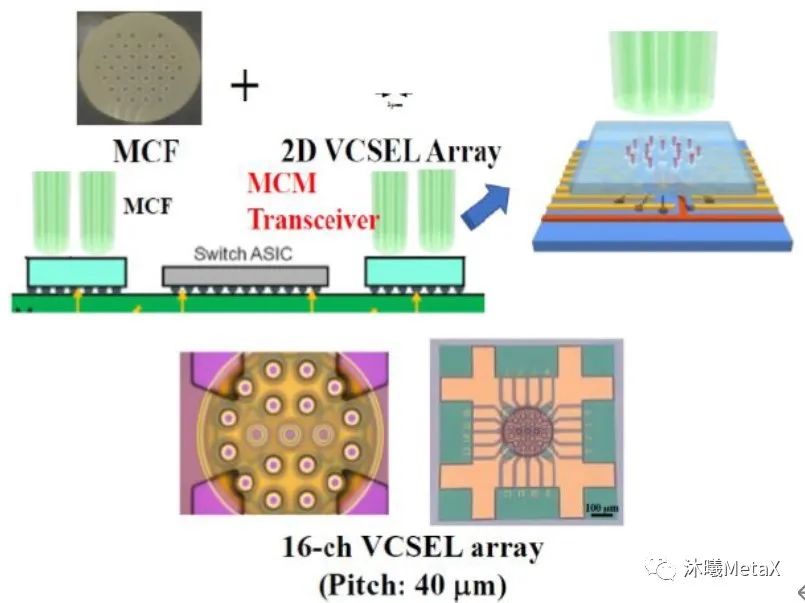
图3. 采用多芯多模光纤的光收发器原型
(来源于参考资料[8])
为了进一步降低VCSEL光纤链路的总体成本,人们在考虑如何减小光电收发器成本的同时,也有必要采取措施来降低诸如光纤连接器、光缆、光纤管理等组件的成本。虽然更高的数据速率可在一定程度上降低链路成本,但是这还不足以应对当前的带宽密度挑战。一种方法是在一根光纤中摈弃使用单个多模纤芯、而是使用多个多模纤芯,从而实现更为显著的数据速率提升[8]。如图3所示,近期,日本国家情报通信研究机构(NICT)在一根37芯光纤中采用了16芯作为空间信道与VCSEL阵列相匹配;而在使用800-1100 nm范围内多个波长的基础上,粗波分复用收发器更是可以进一步增加单根光纤的带宽。最为关键的是,虽然上述方法或将受限于封装集成的异质性特征和迅猛增加的光纤管理成本,但是目前以IBM、Nokia Bell Labs为代表的许多业界机构都认为它有着非常广阔的探索和改进空间[9, 10]。
1.2垂直腔面发射激光器光学印刷电路板技术
为了在封装集成的程度和成本方面获得更多收效,并在板卡距离互连场景中与铜线开展充分竞争,人们还将目光投向了基于塑料波导和VCSEL集成的光学印刷电路板(Printed Circuit Board, PCB)技术[11],认为它可将低成本制造、模块密度、可定制化集成等多个优点汇集于一身。
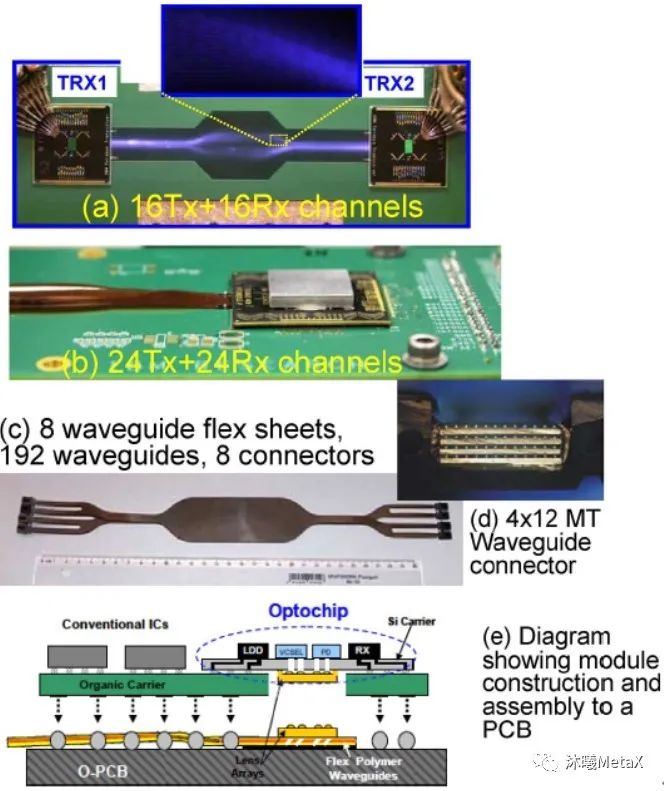
图4. (a) PCB基底之上的塑料波导,
适用于16个发射机、16个接收机信道的状况;
(b)柔性基底之上的塑料波导,适用于24个发射机、
24个接收机信道的状况;(c)无源混洗电缆;
(d)四层波导连接器;(e)光模块结构和组装的示意图
(来源于参考资料[12])
VCSEL光学PCB技术的各个组成部分如图4所示,具体包括:(a)在PCB上直接制作而成的塑料波导,(b)柔性基底上的塑料波导,(c)无源混洗电缆,(d)连接器。图4(e)展示了于图4(b)中所使用的光模块结构。VCSEL/光电二极管阵列和硅基驱动/接收端电路被焊接于一体,并附着在一个硅基载板之上。硅基载板上的孔洞使得光束可以通过,而光路则是通过一个双透镜系统耦合入波导的。对于将光模块附着在PCB这一步骤来说,虽然每个透镜阵列需要在各自的对应边缘以更小容差(约为5 μm)附着在光组件上,但是上述双透镜系统仍可具备较大的偏调容差(1 dB损耗时大于20 μm)。
VCSEL光学PCB技术不仅为光互连辅以一种崭新的光学手段,而且兼备电学PCB的技术特点。事实上,电学PCB仍旧基于低成本大批量制造方法,尚不具备面向特定用户需求的可定制化特征。而光学PCB可将板卡之内的光纤管理问题消弭于无形,并有利于实现物理接近GPU等处理芯片的高密度光收发器集成。为了进一步推动VCSEL光学PCB技术的应用,人们一直尝试去实现柔性基底组装件之上的可替换波导,并将该组装件安装在板上(与光纤并带类似)。然而,随着该项技术的不断成熟,塑料波导将会被合并于PCB上方或内部。尽管该项技术前景广阔,但是人们仍需克服诸多挑战,如进一步改进波导损耗和连接器损耗、实际实现相关的基础制作设备等。
1.3硅基光子技术
自上世纪80年代中期开始,硅基光子便被广泛认为是光通信领域中最具前景的技术之一[13]。该技术将单模光纤、未经调制的激光器、硅基调制器、硅基探测器等结合在一起使用;通过借助完善的CMOS制造来生产高度集成的装配组件。硅基光子技术能以较低成本在CMOS中直接制造大部分原件,或可为光电集成能力提供最佳解决方案[14]。此外,通过大幅降低相关波分复用系统(即在同一光纤中传输多个波长)的成本,光缆和连接器的成本便可由更高的单光纤带宽来分摊。
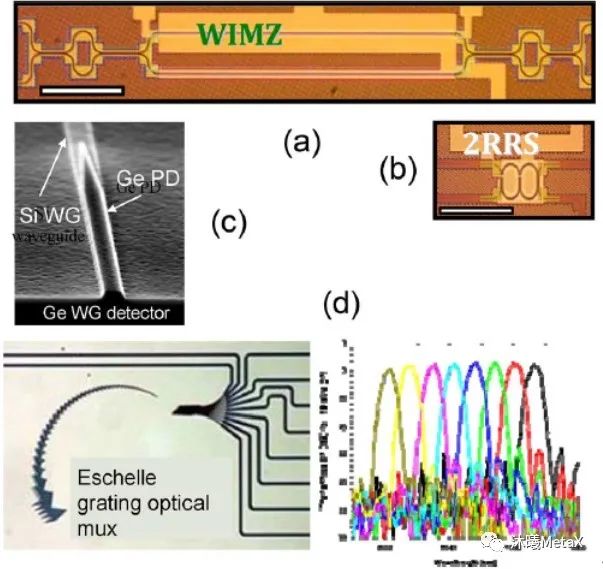
图5. (a)波长不敏感的马赫曾德尔调制器;
(b)双微环谐振腔调制器;(c)集成的锗光探测器和硅波导;
(d)基于埃谢勒光栅的光复用/解复用器及其关联的传输光谱
(来源于参考资料[12])
图5(a)-(d)展示了硅基光子技术所需要的几种技术元素:硅波导、集成的锗探测器、基于马赫曾德尔干涉仪的调制器、基于微环谐振腔的调制器、波分复用/解复用原件。自2014年起,硅基光子技术的产业化得以明显完善,其商业产品的主要形式为有源缆线[15]。因为该技术需使用长波长(通常为1300 nm窗口或1500 nm窗口,以充分利用成熟的电信场景连续波单模激光器)和单模光纤,所以基于硅光子的各类收发器件和基于VCSEL的短波长/多模光纤技术并不相容。有源光缆对于数据中心或HPC系统具有良好的互用性,这使得硅基光子技术已经开始在商用市场中展露锋芒。此外,长距离光通信在大规模装置的互连场景中很具吸引力,而这却是多模光纤链路的短板;而硅基光子链路中的单模光纤在长波长范围内具有很低的信号失真和本征损耗,可有效增大高数据速率光链路的通信距离。

表1. 两种不同的硅基光子调制器设计之比较
高度集成光电器件中的寄生效应并不明显,非常有利于降低高数据速率条件下的系统功耗。硅材料属间接带隙半导体材料,需要借助混合集成技术解决片上光源和光放大等难题。在设计调制器时,硅基光子技术需充分利用硅材料中的光子、电子及光电子器件的工作机理和光电特性。调制器设计需在光带宽、温度灵敏度及控制、功耗、光损耗之间寻求平衡。我们在这里试举一例:表1对马赫曾德尔和微环谐振腔两种调制器设计作了性能比较。可以看出,前者具有相对较大的光带宽、相对较小的温度灵敏度,却占用着相对较大的面积和较高的功耗。值得庆辛的是,未来GPU加速的大规模HPC机器或将普遍采用水冷方案,可将其工作温度范围大幅降低至几十摄氏度。然而,为了追寻更大的市场影响力,硅基光子技术必须在更为典型的温度范围内(如0-70 ℃)有所作为。
激光器光源可以封装在芯片之上、或是芯片之外一个较为方便的位置,并通过光纤与芯片耦合[16]。虽然芯片之上的位置选项有利于实现更为集成化和低成本的封装,但是它却面临着更为严峻的热环境挑战。相较而言,芯片之外的位置选项则能够为激光器提供一个独立的空间环境,从而可以更加精确地控制温度和波长;同时,较低的环境温度则更加有利于提升激光器的可靠性。进一步地讲,人们已开始考虑使用高功率的芯片外激光器:这类激光器可在不同的收发器之间实现分隔化使用,从而有效分摊多路光信道方案中激光器、激光器封装、冷却系统等各项成本。
封装是硅基光子技术探讨中常被忽视的另一重要领域。尽管硅基光子芯片自身有着较低的成本,但是芯片和光纤的耦合、连续波激光器的使用等却又无形中大幅增加了通信系统的成本。事实上,与满足多模工作条件的封装(约为10 μm)相比,满足单模工作条件的封装(通常小于1 μm)是非常昂贵的。另一方面,相较于多模VCSEL,单模边发射激光器对反射光更为敏感。因此,人们还需在硅基光子通信中使用光隔离器,且将光反馈的数量保持在较低水平(约-30-40 dB)。
最后,人们还需考虑硅基光子链路的总体功耗情况。尽管低功率光链路具有极大潜力(例如具有100 fJ/bit的调制器[17]),但是试图均衡考量性能、温度、所有功耗源(包括温度控制、连续波激光器、时钟逻辑电路控制)等因素的链路设计方案仍十分受限。值得一提的是,对于硅基光子技术在光互连方面的应用而言,学界和业界在近期普遍认为其终极形式将会是基于高密度2.5D或3D芯片堆叠的光收发器集成 [18]。而这又为其他匹配技术的发展和成熟提出了新的挑战。
1.4无源光连接器和线缆
除去上文所讨论的几种有源光收发器技术之外,人们还需借助无源光连接器和线缆将所有卡、板、机架上的光收发器连接起来。在VCSEL光纤链路中,这依赖于并行光纤并带和连接器(如已在多模光纤链路中得以长期使用的多路并行光路)。在考虑未对准容差的基础上,连接器损耗通常不得大于0.5 dB。
而对于基于塑料波导的光链路来说,具备低损耗特征的长距离连接(如1 m的板到板距离)便成为一种迫切需求。人们也可在这类链路中使用低损耗光纤(如图4(d)所示)。而由于圆形光纤纤芯或方形波导纤芯(根据尺寸选择,或为非对称结构)之间几何结构的不匹配,这些连接器会有大约0.5 dB的附加损耗。
硅基光子技术会对单模工作的光纤和连接器有所需求。基于更为严格的对准公差需求,这类连接器通常有着0.25 dB的附加损耗(事实上,人们亦可使用具有更高成本的低损耗器件)。此外,因为灰尘可较为容易地阻塞单模光纤纤芯(约为9 μm,而多模光纤纤芯通常为50 μm或62.5 μm),在连接器组装过程中还需重点关注环境颗粒对单模光纤连接器的污染问题。
02长期的技术需求
2.1从光互连到光交换
在光互连技术之外,光学技术的另一个重要角色则在于交换[19]。当前,对于网络功率预算而言,其大部分份额须分配给传统的电分组交换。这意味着光交换或才是真正需要业界去付诸实践、实现突破的领域。
面对光互连网络的交换需求,人们需要对超级计算机内的流量模式有着深入理解。事实上,能够和任意流量模式相匹配的单个最佳拓扑结构是不存在的。尽管在超级计算机中部署光电路交换的实际价值尚未被人们完全理解,但是近几年学界和业界对HPC应用的研究却已经对光/电通信模式结构的进一步演进指明了方向。
由光交叉互连而引入的信号损耗须在系统中得以修复。基于此,业界部分人士对采用光交换来应对百亿亿次计算挑战的实际效用仍持有怀疑态度。此外,较低的平均链路利用率也会对光交换的效能产生限制。因此,人们需要在改进利用率和最小化数据队列之间寻求技术均衡。在一个严格意义上的光交换网络中,比特在电路进行重构时是无法流动的,而存贮这些比特的光缓存技术还尚未实现。这就意味着,若数据包长度在若干个纳秒范围之内,则重构时间必须极短(在1纳秒之内)且光交换必须在纳秒级别的时间尺度内具有高度灵活性。
上述光交换能力的缺失使得人们对全光分组交换网络的实际应用有所疑问。既然光子还被限定在电路交换范围之内,将光路交换和电路交换融合在一起的解决方案便成为了必然选项。在这种方案中,数据缓存和数据包交换均在电域实现,且人们需要将光电转换的次数降至最低。基于微机电系统的光交换或可实现足够的端口密度。目前,由于微机电系统交换机的端口成本仍旧较高(约为每端口数百美元),所以它在市场中并未得到广泛使用。尽管HPC的市场规模并不足以大幅降低端口成本,但是微机电系统交换机在数据中心的使用或将增大其在HPC市场中的吸引力。
2.2协同设计
总体看来,光互连和光交换必将在GPU加速的HPC系统中扮演重要角色。然而,这在很大程度上依赖于一些新光学技术和新工作方式的采用。从工业应用角度出发,硬件、软件和应用工程师需要通力合作、协同开发一类可在集成环境中得以实施的新型架构和代码库。这种软硬件协同设计已然成为当前大规模HPC系统开发的关键。
为了促进协同设计,人们需减小系统集成商、设备供应商和光学产品供应商的市场区隔,并加速不同产业或技术实体之间的流通。事实上,当前这种市场区隔依然十分顽固。光学供应商在追寻更高的技术参数指标时,并未意识到新型设计或可推进整体系统性能的突破。于是,系统集成商反而将注意力放在了具有渐进式性能改进和小幅降低成本特征的产品路线图上。当前,人们已经对协同设计的必要性和重要性有了更为明晰的认识,读者不妨对此持谨慎乐观的态度。
03小结
GPU加速的HPC系统对光通信网络的信息传输、接收和处理能力提出了更高要求。对VCSEL光纤链路技术、VCSEL光学PCB技术、硅基光子技术三类光通信选项来说,未来的趋势主要在于:进一步提升系统的数据处理容量和效率,由单个器件向大规模、高速率的集成芯片发展,从单一的收发功能向完整的可重构系统发展,以及实现有源或无源器件的单片集成。
在本系列文章的第三篇,笔者将会对GPU网络光互连的市场和产业趋势、新兴的工作负荷、策略和计划做出介绍。
参考资料
[1] Anjin Liu et al., "Vertical-cavity surface-emitting lasers for data communication and sensing," Photonics Research 7, 121-136 (2019)
[2] N. Ledentsov Jr. et al., "Energy efficient 850-nm VCSEL based optical transmitter and receiver link capable of 56 Gbit/s NRZ operation," in 2019 SPIE 10938, Vertical-Cavity Surface-Emitting Lasers XXIII, 109380J
[3] F. Doany et al., "Dense 24 TX + 24 RX fiber-coupled optical module based on a holey CMOS transceiver IC," in 2010 60th Electronic Components and Technology Conference, 247-255
[4] M. V. Ramana Murty et al., "Development and characterization of 100 Gb/s data communication VCSELs," IEEE Photonics Technology Letters 33, 812-815 (2021)
[5] B. Wang et al., "4×112 Gbps/fiber CWDM VCSEL arrays for co-packaged interconnects," Journal of Lightwave Technology 38, 3439-3444 (2020)
[6] 刘安金, "单模直调垂直腔面发射激光器研究进展," 中国激光 47, 0701005 (2020)
[7] E. Haglund et al., "30 GHz bandwidth 850 nm VCSEL with sub-100 fJ/bit energy dissipation at 25-50 Gbit/s," Electronics Letters, 51, 1096-1098 (2015)
[8] F. Koyama, "Recent progress of VCSEL photonics and their applications," in 2021 European Conference on Optical Communication, paper We1D.1
[9] P. Maniotis et al., "Toward lower-diameter large-scale HPC and data center networks with co-packaged optics," Journal of Optical Communications and Networking 13, A67-A77 (2021)
[10] C. Li et al., "Co-packaged optics with multimode fiber interface employing 2-D VCSEL matrix," Journal of Lightwave Technology 40, 3325-3330 (2022)
[11] F. Doany et al., "Terabit/sec-class board-level optical interconnects through polymer waveguides using 24-channel bidirectional transceiver modules," in 2011 IEEE Electronic Components and Technology Conference, 790-797
[12] M. A. Taubenblatt, "Optical interconnects for high-performance computing," Journal of Lightwave Technology 30, 448-457 (2012)
[13] R. Soref, "The past, present, and future of silicon photonics," IEEE Journal of Selected Topics in Quantum Electronics, 12, 1678-1687 (2006)
[14] D. Mahgerefteh et al., "Techno-economic comparison of silicon photonics and multimode VCSELs," Journal of Lightwave Technology 34, 233-242 (2016)
[15] S. Y. Siew et al., "Review of silicon photonics technology and platform development," Journal of Lightwave Technology 39, 4374-4389 (2021)
[16] D. Guckenberger et al., "Advantages of CMOS photonics for future transceiver applications," in 2010 36th European Conference on Optical Communication, 1-6
[17] H. Thacker et al., "Hybrid integration of silicon nanophotonics with 40 nm-COMS VLSI drivers and receivers," in 2011 IEEE Electronic Components and Technology Conference, 829-835
[18] R. Mahajan et al., "Co-packaged photonics for high performance computing: status, challenges and opportunities," Journal of Lightwave Technology 40, 379-392 (2022)
[19] S. J. Ben Yoo, "Prospects and challenges of photonic switching in data centers and computing systems," Journal of Lightwave Technology 40, 2214-2243 (2022)
编辑:黄飞
-
光通信网络的优势分析2025-01-23 2142
-
光放大器与光通信的关系是什么2024-08-09 1706
-
何为相干光通信系统2023-05-17 904
-
光通信的概念 光通信优点与不足2023-05-09 9053
-
浅析紫外光通信技术2019-06-18 4318
-
易天光通信携系列光模块产品参展CIOE 20182018-09-11 2574
-
无线光通信在网络互连中的应用2016-03-21 885
-
光互连技术2016-01-29 2916
-
把握光通信行业演变脉动 CIOE2012光通信展即将起航!2012-08-16 3458
-
无线光通信(FSO)技术是什么意思2010-03-13 12362
-
光通信网络的相关技术2009-09-02 661
全部0条评论

快来发表一下你的评论吧 !
