

PyTorch开源深度学习框架简介
描述
PyTorch 是一种开源深度学习框架,以出色的灵活性和易用性著称。这在一定程度上是因为与机器学习开发者和数据科学家所青睐的热门 Python 高级编程语言兼容。
什么是 PyTorch ?
PyTorch 是一种用于构建深度学习模型的功能完备框架,是一种通常用于图像识别和语言处理等应用程序的机器学习。使用 Python 编写,因此对于大多数机器学习开发者而言,学习和使用起来相对简单。PyTorch 的独特之处在于,它完全支持 GPU,并且使用反向模式自动微分技术,因此可以动态修改计算图形。这使其成为快速实验和原型设计的常用选择。
为何选择 PyTorch ?
PyTorch 是 Facebook AI Research 和其他几个实验室的开发者的工作成果。该框架将 Torch 中高效而灵活的 GPU 加速后端库与直观的 Python 前端相结合,后者专注于快速原型设计、可读代码,并支持尽可能广泛的深度学习模型。Pytorch 支持开发者使用熟悉的命令式编程方法,但仍可以输出到图形。它于 2017 年以开源形式发布,其 Python 根源使其深受机器学习开发者的喜爱。
值得注意的是,PyTorch 采用了 Chainer 创新技术,称为反向模式自动微分。从本质上讲,它就像一台磁带录音机,录制完成的操作,然后回放,计算梯度。这使得 PyTorch 的调试相对简单,并且能够很好地适应某些应用程序,例如动态神经网络。由于每次迭代可能都不相同,因此非常适用于原型设计。
PyTorch 在 Python 开发者中特别受欢迎,因为它使用 Python 编写,并使用该语言的命令式、运行时定义即时执行模式,在这种模式下,从 Python 调用运算时执行运算。随着 Python 编程语言的广泛采用,一项调查显示,AI 和机器学习任务受到越来越多的关注,并且相关 PyTorch 的采用也随之提升。这使得 PyTorch 对于刚接触深度学习的 Python 开发者来说是一个很好的选择,而且越来越多的深度学习课程基于 PyTorch。从早期版本开始,API 一直保持一致,这意味着代码对于经验丰富的 Python 开发者来说相对容易理解。
PyTorch 的独特优势是快速原型设计和小型项目。其易用性和灵活性也使其深受学术和研究界的喜爱。
Facebook 开发者一直努力改进 PyTorch 的高效应用。新版本已提供增强功能,例如支持谷歌的 TensorBoard 可视化工具以及即时编译。此外,还扩展了对 ONNX(开放神经网络交换)的支持,使开发者能够匹配适合其应用程序的深度学习框架或运行时。
PyTorch 的主要优势
PyTorch 的一些重要特性包括:
PyTorch.org 社区有一个充满活力的大型社区,具有优秀的文档和教程。论坛十分活跃,并能给予帮助和支持。
采用 Python 编写,并集成了热门的 Python 库,例如用于科学计算的 NumPy、SciPy 和用于将 Python 编译为 C 以提高性能的 Cython。由于 PyTorch 的语法和用法类似于 Python,因此对于 Python 开发者来说,学习起来相对容易。
受主要云平台的有力支持。
脚本语言(称为 TorchScript)在即时模式下易于使用且灵活。这是一种快速启动执行模式,从 Python 调用运算时立即执行运算,但也可以在 C++ 运行时环境中转换为图形模型,以提高速度和实现优化。
它支持 CPU、GPU、并行处理以及分布式训练。这意味着计算工作可以在多个 CPU 和 GPU 核心之间分配,并且可以在多台机器上的多个 GPU 上进行训练。
PyTorch 支持动态计算图形,能够在运行时更改网络行为。与大多数机器学习框架相比,提供了更大的灵活性优势,因为大多数机器学习框架要求在运行时之前将神经网络定义为静态对象。
PyTorch Hub 是一个预训练模型库,在某些情况下只需使用一行代码就可以调用。
新自定义组件可创建为标准 Python 类的子类,可以通过 TensorBoard 等外部工具包轻松共享参数,并且可以轻松导入和内联使用库。
PyTorch 拥有一组备受好评的 API,可用于扩展核心功能。
既支持用于实验的“即时模式”,也支持用于高性能执行的“图形模式”。
拥有从计算机视觉到增强学习等领域的大量工具和库。
支持 Python 程序员熟悉的纯 C++ 前端接口,可用于构建高性能 C++ 应用程序。
PyTorch 的工作原理
PyTorch 和 TensorFlow 的相似之处在于,两者的核心组件都是张量和图形。
张量
张量是一种核心 PyTorch 数据类型,类似于多维数组,用于存储和操作模型的输入和输出以及模型的参数。张量与 NumPy 的 ndarray 类似,只是张量可以在 GPU 上运行以加速计算。
图形
神经网络将一系列嵌套函数应用于输入参数,以转换输入数据。深度学习的目标是通过计算相对损失指标的偏导数(梯度),优化这些参数(包括权重和偏差,在 PyTorch 中以张量的形式存储)。在前向传播中,神经网络接受输入参数,并向下一层的节点输出置信度分数,直至到达输出层,在该层计算分数误差。在一个称为梯度下降的过程中,通过反向传播,误差会再次通过网络发送回来,并调整权重,从而改进模型。
图形是由已连接节点(称为顶点)和边缘组成的数据结构。每个现代深度学习框架都基于图形的概念,其中神经网络表示为计算的图形结构。PyTorch 在由函数对象组成的有向无环图 (DAG) 中保存张量和执行操作的记录。在以下 DAG 中,叶是输入张量,根是输出张量。
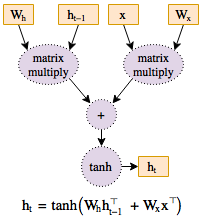
在许多热门框架(包括 TensorFlow)中,计算图形是一个静态对象。PyTorch 基于动态计算图形,即,在运行时构建和重建计算图形,并使用与执行前向传递的计算相同的代码,同时还创建反向传播所需的数据结构。PyTorch 是首个运行时定义深度学习框架,与 TensorFlow 等静态图形框架的功能和性能相匹配,非常适合从标准卷积网络到时间递归神经网络等所有网络。
PyTorch 用例
众所周知,PyTorch 框架十分便捷且灵活,增强学习、图像分类和自然语言处理等示例是比较常见的用例。
商业、研究和教育示例
自然语言处理 (NLP):从 Siri 到 Google Translate,深度神经网络在机器理解自然语言方面取得了突破性进展。其中大多数模型都将语言视为单词或字符的平面序列,并使用一种称为时间递归神经网络 (RNN) 的模型处理该序列。但是,许多语言学家认为,语言极易理解为一个由短语组成的层次树,因此,大量研究已经进入称为递归神经网络的深度学习模型,该模型将这种结构考虑在内。虽然这些模型难以实现且运行效率低下,但 PyTorch 使这些模型和其他复杂自然语言处理变得容易得多。Salesforce 正在使用 PyTorch 进行 NLP 和多任务学习。
研究:PyTorch 具有易用性、灵活性和快速原型设计,是研究的首选。斯坦福大学正在利用 PyTorch 的灵活性高效研究新的算法方法。
教育:Udacity 正在使用 PyTorch 培养 AI 创新者。
PyTorch 的重要意义
数据科学家
对于熟悉 Python 的程序员而言,PyTorch 学习起来相对容易。它提供了简单的调试、简单的 API ,并且兼容各种内置 Python 的扩展。其动态执行模型也非常适合原型设计,尽管会产生一些性能开销。
软件开发者
PyTorch 支持各种功能,可以快速轻松地部署 AI 模型。它还具有丰富的库生态系统,如 Captum(用于模型可解释性)、skorch(scikit-learn 兼容性)等,以支持开发。PyTorch 具有出色的加速器生态系统,例如,Glow(用于训练)和 NVIDIA TensorRT(用于推理)。
GPU:深度学习的关键
在架构方面,CPU 仅由几个具有大缓存内存的核心组成,一次只可以处理几个软件线程。相比之下,GPU 由数百个核心组成,可以同时处理数千个线程。

先进的深度学习神经网络可能有数百万乃至十亿以上的参数需要通过反向传播进行调整。由于神经网络由大量相同的神经元构建而成,因此本质上具有高度并行性。这种并行性会自然地映射到 NGC (NVIDIA GPU Cloud),用户可以在其中提取容器,这些容器具有可用于各种任务(例如计算机视觉、自然语言处理等)的预训练模型,且所有依赖项和框架位于一个容器中。借助 NVIDA 的 TensorRT,使用 NVIDIA GPU 时,可以在 PyTorch 上显著提高推理性能。
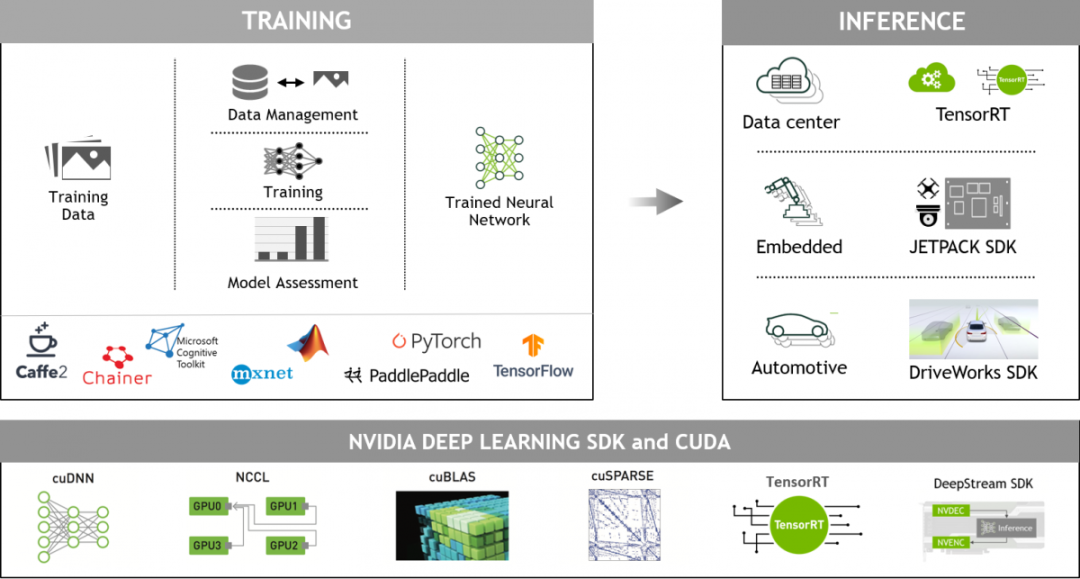
面向开发者的 NVIDIA 深度学习
GPU 加速深度学习框架能够为设计和训练自定义深度神经网络带来灵活性,并为 Python 和 C/C++ 等常用编程语言提供编程接口。MXNet、PyTorch、TensorFlow 等广泛使用的深度学习框架依赖于 NVIDIA GPU 加速库,能够提供高性能的多 GPU 加速训练。
NVIDIA GPU 加速的端到端数据科学
基于 CUDA-X AI 创建的 NVIDIA RAPIDS 开源软件库套件使您完全能够在 GPU 上执行端到端数据科学和分析流程。此套件依靠 NVIDIA CUDA 基元进行低级别计算优化,但通过用户友好型 Python 接口实现了 GPU 并行化和高带宽显存速度。
借助 RAPIDS GPU DataFrame,数据可以通过一个类似 Pandas 的接口加载到 GPU 上,然后用于各种连接的机器学习和图形分析算法,而无需离开 GPU。这种级别的互操作性是通过 Apache Arrow 这样的库实现的。这可加速端到端流程(从数据准备到机器学习,再到深度学习)。
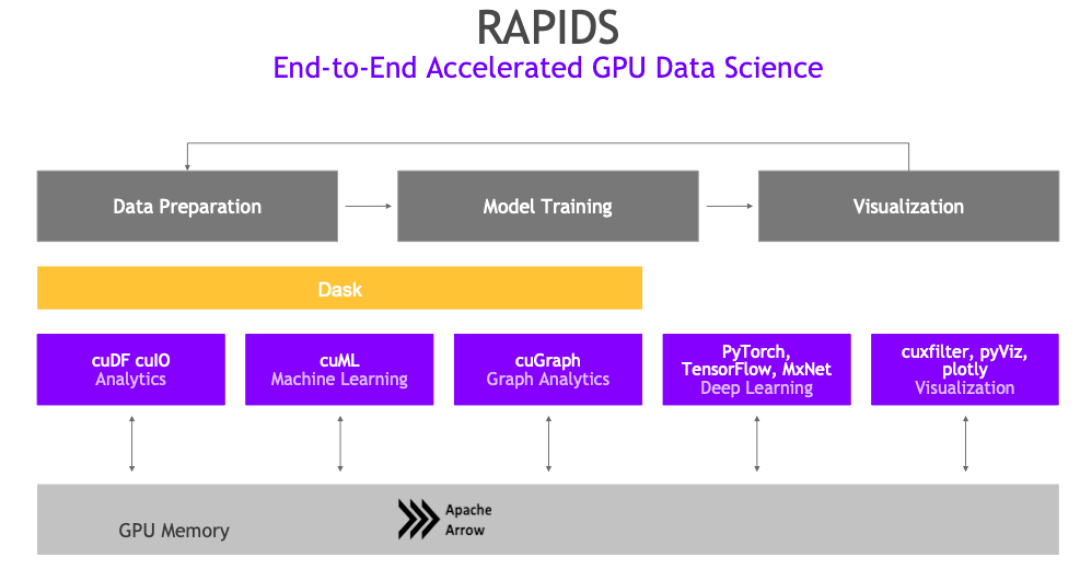
RAPIDS 支持在许多热门数据科学库之间共享设备内存。这样可将数据保留在 GPU 上,并省去了来回复制主机内存的高昂成本。
审核编辑:汤梓红
-
PyTorch深度学习开发环境搭建指南2024-07-16 4403
-
TensorFlow与PyTorch深度学习框架的比较与选择2024-07-02 2967
-
深度学习框架pytorch入门与实践2023-08-17 2694
-
深度学习框架PyTorch和TensorFlow如何选择2023-02-02 1636
-
八种主流深度学习框架的介绍2022-04-26 10331
-
基于PyTorch的深度学习入门教程之PyTorch的安装和配置2021-02-16 3435
-
天才黑客George Hotz开源了一个小型深度学习框架tinygrad2020-12-16 5179
-
Facebook研究开放新框架,让深度学习更加容易2020-03-13 2346
-
PyTorch版《动手学深度学习》开源了2019-09-20 3472
-
为什么学习深度学习需要使用PyTorch和TensorFlow框架2019-09-14 4332
-
Facebook与CMU联手打造开源框架PyRobot2019-06-24 4323
-
Facebook致力AI 开源PyTorch1.0 AI框架2018-06-18 3845
-
Facebook致力AI开源PyTorch 1.0 AI框架2018-05-08 3976
全部0条评论

快来发表一下你的评论吧 !
