

NVIDIA对 NeMo Megatron 框架进行更新 将训练速度提高 30%
描述
随着大型语言模型(LLM)的规模和复杂性日益增加,NVIDIA 于今日宣布对 NeMo Megatron 框架进行更新,将训练速度提高 30%。
此次更新包括两项开创性的技术和一个超参数工具,用于优化和扩展任意数量 GPU 上的 LLM 训练,这为使用 NVIDIA AI 平台训练和部署模型提供了新功能。
BLOOM 是全球最大的开放科学、开放存取多语言模型,具有 1760 亿参数。该模型最近在NVIDIA AI 平台上进行了训练,支持 46 种语言和 13 种编程语言的文本生成。NVIDIA AI 平台还提供了最强大的转换器语言模型,具有 5300 亿参数,Megatron-Turing NLG 模型 (MT-NLG) 。
LLMs 的最新进展
LLM 是当今最重要的先进技术之一,涉及从文本中学习的多达数万亿参数。但 LLM 的开发过程昂贵而耗时,需要深厚的技术知识、分布式基础设施和全栈式方法。
LLM 也大大有助于推动实时内容生成、文本摘要、客服聊天机器人以及对话式AI问答界面的发展。
为了推动 LLM 的发展,人工智能(AI)社区正在继续对 Microsoft DeepSpeed, Colossal-AI 和Hugging Face BigScience 和 Fairscale 等工具进行创新,这些工具均由 NVIDIA AI 平台提供支持,包括 Megatron-LM、Apex 和其他 GPU 加速库。
这些对 NVIDIA AI 平台的全新优化有助于解决整个堆栈中现有的许多痛点。NVIDIA 期待着与 AI 社区合作,让每个人都能享受到 LLM 的力量。
更快速构建 LLMs
NeMo Megatron 的最新更新令 GPT-3 模型的训练速度提高了 30%,这些模型的规模从 220 亿到 1 万亿个参数不等。现在使用 1024 个 NVIDIA A100 GPU 只需 24 天就可以训练一个拥有 1750 亿个参数的模型。相比推出新版本之前,获得结果的时间缩短了 10 天或约 25 万个小时的 GPU 计算。
NeMo Megatron 是快速、高效、易于使用的端到端容器化框架,它可以用于收集数据、训练大规模模型、根据行业标准基准评估模型,并且以最高水准的延迟和吞吐性能进行推理。
它让 LLM 训练和推理在各种 GPU 集群配置上变得简单、可复制。目前,早期访问用户客户可在NVIDIA DGX SuperPOD、NVIDIA DGX Foundry 以及 Microsoft Azure 上运行这些功能。对其他云平台的支持也即将推出。
另外,用户还可以在 NVIDIA LaunchPad上进行功能试用。LaunchPad 是一项免费计划,可提供短期内访问 NVIDIA 加速基础设施上的动手实验室目录的机会。
NeMo Megatron 是 NeMo 的一部分,开源框架 NeMo,用于为对话式 AI、语音 AI 和生物学构建高性能和灵活的应用程序。
两项加速 LLM 训练的新技术
此次更新包括两项用于优化和扩展 LLM 训练的新技术——序列并行(SP)和选择性激活重计算(SAR)。
SP 通过注意到变换器层中尚未并行化的区域在序列维度是独立的,以此扩展张量级模型的并行性。
沿序列维度分割层,可以将算力以及最重要的内激活内存分布到张量并行设备上。激活是分布式的,因此可以将更多的激活保存到反向传播中,而无需重新计算。
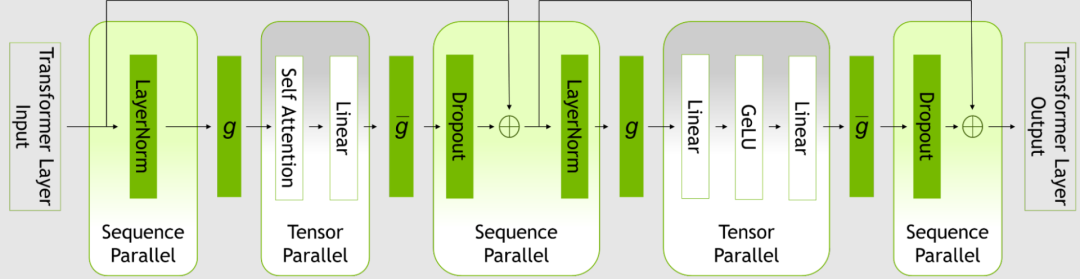
图1. Transformer 层内的并行模式
SAR 通过注意到不同的激活在重计算时需要不同数量的运算,改善了内存限制迫使重新计算部分(但不是所有)激活的情况。
可以只对每个 Transformer 层中占用大量内存,但重新计算成本不高的部分设置检查点和进行重新计算,而不是针对整个变换器层。
有关更多信息,请参见减少大型 Transformer 模型中的激活重计算: https://arxiv.org/abs/2205.05198
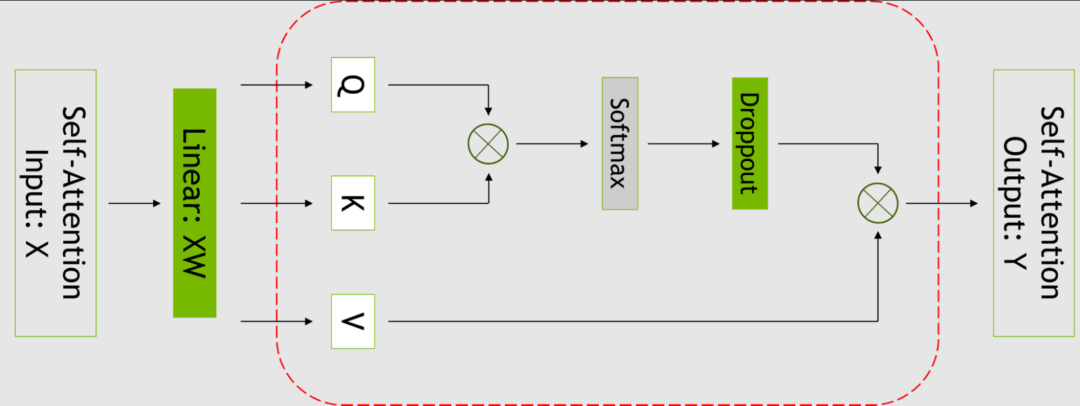
图2. 自注意力块。红色虚线表示使用选择性激活重计算的区域
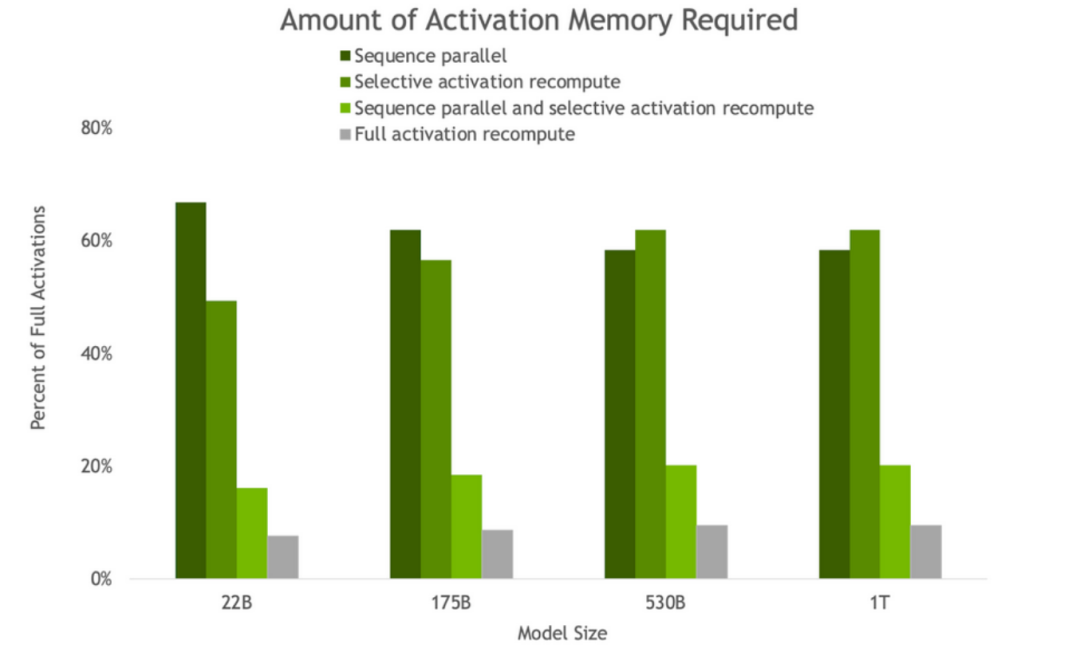
图3. 反向传播中因 SP 和 SAR 的存在而获得的激活内存量。随着模型大小的增加,SP 和 SAR 都会产生类似的内存节省,将内存需求减少约 5 倍。
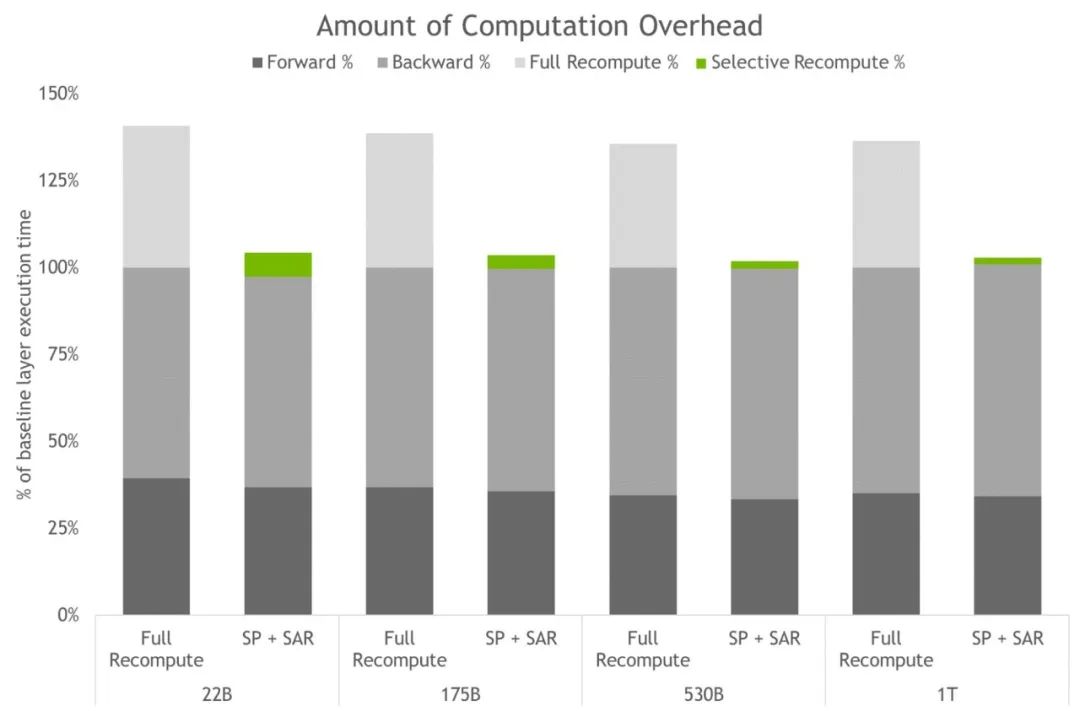
图4. 完全激活重计算和 SP+SAR 的计算开销。条形图表示每层的前向、反向和重计算时间细分。基线代表没有重计算和序列并行时的情况。这些技术有效地减少了所有激活被重计算而不是保存时产生的开销。最大模型的开销从 36% 下降到仅为 2%。
运用 LLM 的力量,还需要高度优化的推理策略。用户可以十分轻松地将训练好的模型用于推理并使用 P-tuning 和提示调整功能优化不同的用例。
这些功能是轻量化微调的有效替代方案,使 LLM 能够适应新的用例,而不需要采取微调全部预训练模型这种繁琐的方法。在这项技术中,原始模型的参数并没有被改变,因此避免了与微调模型相关的灾难性的“遗忘”问题。
有关更多信息,请参见采用 P-Tuning 解决非英语下游任务: https://developer.nvidia.com/blog/adapting-p-tuning-to-solve-non-english-downstream-tasks/
用于训练和推理的新超参数工具
在分布式基础设施中为 LLM 寻找模型配置十分耗时。NeMo Megatron 带来了超参数工具,它能够自动找到最佳训练和推理配置,而不需要修改代码,这使 LLM 从第一天起就能在训练中获得推理收敛性,避免了在寻找高效模型配置上所浪费的时间。
该工具对不同的参数使用启发法和经验网格搜索来寻找具有最佳吞吐量的配置,包括数据并行性、张量并行性、管道并行性、序列并行性、微批大小和激活检查点设置层的数量(包括选择性激活重计算)。
通过使用超参数工具以及在 NGC 容器上的 NVIDIA 测试,NVIDIA 在 24 小时内就得到了 175B GPT-3 模型的最佳训练配置(见图5)。与使用完整激活重计算的通用配置相比,NVIDIA 将吞吐量速度提高了 20%-30%。对于参数超过 200 亿的模型,NVIDIA 使用这些最新技术将吞吐量速度进一步提升 10%-20%。
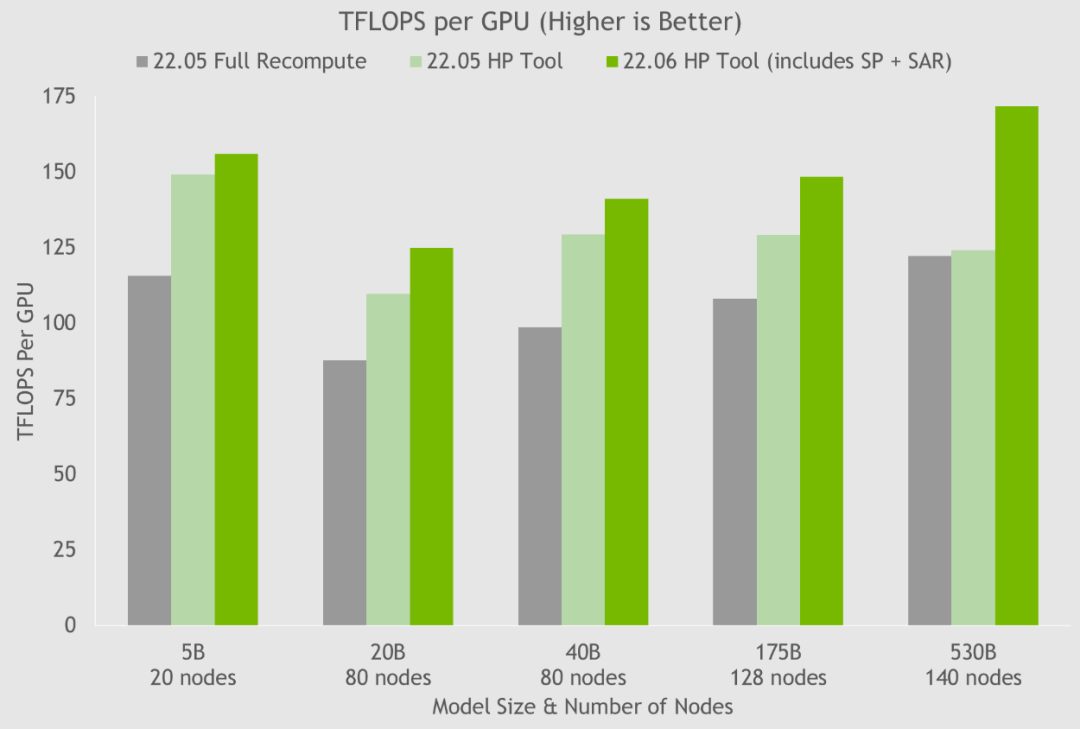
图5. HP 工具在几个容器上的结果显示了通过序列并行和选择性激活重计算实现的速度提升,其中每个节点都是 NVIDIA DGX A100。
超参数工具还可以找到在推理过程中实现最高吞吐量或最低延迟的模型配置。模型可以设置延迟和吞吐量限制,该工具也将推荐合适的配置。
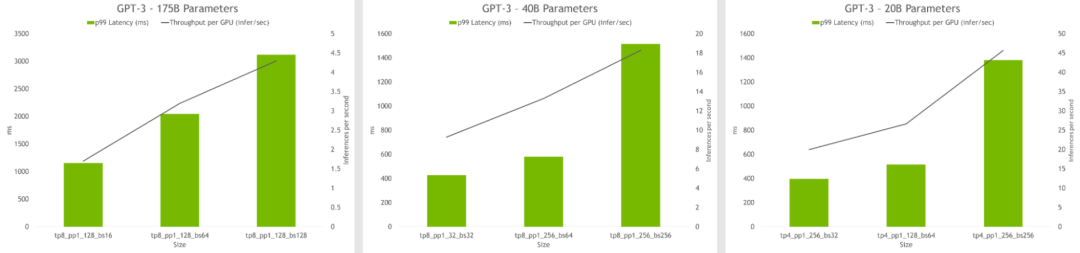
图6. HP 工具的推理结果显示每个 GPU 的吞吐量和不同配置的延迟。最佳配置包括高吞吐量和低延时。
-
超大Transformer语言模型的分布式训练框架2021-10-11 5013
-
探究超大Transformer语言模型的分布式训练框架2021-10-20 4124
-
NVIDIA 借助超大规模 AI 语言模型为全球企业赋能2021-11-10 1292
-
NVIDIA为全球企业开发和部署大型语言模型打开一扇新的大门2021-11-12 2408
-
用Riva和NeMo Megatron构建语音AI2022-03-31 2283
-
NVIDIA发布Riva语音AI和大型LLM软件2022-04-01 12046
-
用NVIDIA NeMo生成高质量的语音识别标签2022-04-27 2620
-
NVIDIA NeMo开源框架概述、优势及功能特性2022-07-19 4492
-
KT利用NVIDIA AI平台训练大型语言模型2022-09-27 2385
-
NVIDIA AI平台为大型语言模型带来巨大收益2022-10-10 1721
-
NVIDIA 人工智能开讲 | 了解 NVIDIA NeMo 框架的多种功能与最新更新2023-02-14 1523
-
基于PyTorch的模型并行分布式训练Megatron解析2023-10-23 5973
-
NVIDIA 为部分大型亚马逊 Titan 基础模型提供训练支持2023-11-29 1590
-
基于NVIDIA Megatron Core的MOE LLM实现和训练优化2024-03-22 2867
-
借助NVIDIA Megatron-Core大模型训练框架提高显存使用效率2025-10-21 1582
全部0条评论

快来发表一下你的评论吧 !
