

如何基于STM32Cube.AI 从零开始创建AI项目
描述
在之前的文章中,我们介绍了没有AI基础知识的工程师如何使用NanoEdge AI快速训练一个用于风扇异常检测的模型。
该模型根据来自电机控制板的电流信号,检测风扇过滤单元的堵塞百分比。我们知道,当风扇发生堵塞时,电机的电流信号形状会与正常时不同,而传统算法很难有效地处理这种差异。因此,机器学习算法成为解决该问题的明智选择。对于机器学习算法,我们通常使用scikit-learn库来训练模型。今天我们将展示如何自行训练机器学习模型,然后使用STM32Cube.AI 将其部署到同一设备上,以便让大家充分了解两种工具的不同之处。
NanoEdgeAI是一款端到端工具,允许对数据进行一些预处理,并进行训练和算法选择,而STM32Cube.AI 则需要工程师具备一定的AI建模经验,因为STM32Cube.AI 暂不支持模型训练。
硬件和软件准备
用于驱动风扇的P-NUCLEO-IHM03电机控制套件包括一块NUCLEO-G431RB主板、一块电机控制扩展板,以及一台无刷电机。
在软件准备方面,您需要配置anaconda环境,并安装sklearn、pandas、ONNX等必要的库。
让我们回顾一下创建AI项目的一些关键步骤,然后据此逐步演示如何基于STM32Cube.AI 从零开始创建AI项目。
在步骤1中,用户需要收集用于机器学习模型创建的数据。该数据集的一部分(训练数据集)将用于训练模型,另一部分(测试数据集)稍后将用于评估所构建模型的性能。机器学习的数据集中的典型比率为:训练数据集占80%,测试数据集占20%。我们此次试验用的数据集与之前NanoedgeAI训练模型使用的数据是一样的。
在步骤2中,用户需要对数据进行标记;基本上,我们需要告诉机器收集的数据属于哪一类(例如“跑步”、“散步”、“静止”……) 分类指的是根据您认为重要的属性对数据进行分组:这种属性在机器学习领域被称为“类”。
接下来,在步骤3中,用户使用预先准备的数据集训练机器学习模型。该任务也称为“拟合”。训练结果的准确性在很大程度上取决于用于训练的数据的内容和数量。
在步骤4中,用户将训练过的机器学习模型嵌入到系统中。对于在计算机上执行的机器学习,用户可以利用Python库直接执行模型。对于在MCU等器件上运行的机器学习,用户可以在执行之前将该库转换为C代码。
最后在步骤5中,用户验证机器学习模型。如果验证结果与预期的结果不匹配,则用户必须确定上述步骤中需要改进的部分,以及如何改进。比如增加数据,更改模型,调整模型超参数等。
至此,我们已经帮大家重新梳理了一次AI项目的建模过程。接下来我们将按照这样的过程完成我们今天的实验。
首先,导入一些必要的库
为了便于对比,我们使用了之前NanoEdgeAI训练模型中使用的数据集。我们使用pandas从csv文件读取数据,然后用于模型训练。
在训练之前,让我们先来了解一下该数据集。让我们打印出数据集的维度。

可以看到,该数据集一共有119条数据和128个特征,最后一列实际上是我们的数据标签。
接下来,我们将数据集分为训练集和测试集,训练集用于训练模型,测试集用于检验模型的泛化能力。我们将80%的数据用于训练,20%的数据用于测试

一旦数据集准备就绪,我们就可以开始训练模型。

训练完成后,我们可以在测试集上验证模型的性能。我们发现,该模型在测试集上可以达到约83%的准确率。

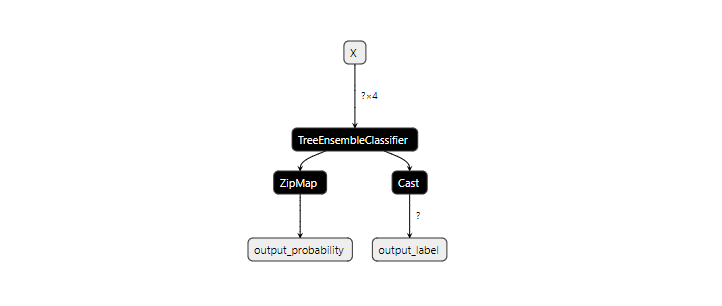
最后,我们保存经过训练的模型,将得到一个ONNX格式的文件random_forest.onnx

我们使用netron查看模型的结构如下
STM32Cube集成使得STM32Cube.AI 用户能够有效地在广泛的STM32微控制器系列产品之间移植模型,并且(在相似型号适用于不同产品的情况下)在STM32产品之间轻松迁移。
该插件扩展了STM32CubeMX功能,可自动转换训练好的AI模型,生成的优化库集成到用户项目中,而不是人工构建代码,并支持将深度学习解决方案嵌入到广泛的STM32微控制器产品组合中,从而为每个产品添加新的智能化功能。
STM32Cube.AI 原生支持各种深度学习框架,如Keras、TensorFlow Lite、ConvNetJs,并支持可导出为ONNX标准格式的所有框架,如PyTorch、Microsoft Cognitive Toolkit、MATLAB等。
此外,STM32Cube.AI 支持来自广泛ML开源库Scikit-Learn的标准机器学习算法,如随机森林、支持向量机(SVM)、K-Means。
现在,我们准备将模型部署到MCU。我们使用STM32Cube.AI 的命令行模式将模型转换为经过优化的C代码。我们运用以下命令执行模型转换。
stm32ai generate -m random_forest.onnx
如果转换成功,我们将看到以下消息。
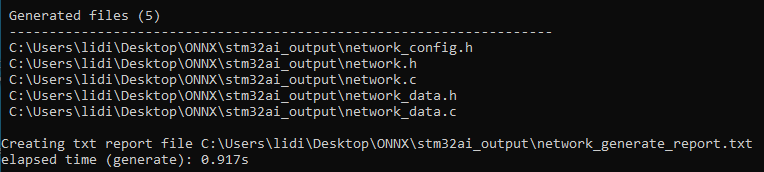
在stm32ai_output文件夹中,我们将看到有以下文件生成。其中,network.c/.h包含关于模型拓扑的一些信息,而network_data.c/.h则记录了关于模型权重的一些信息。

此时,我们准备好将生成的模型集成到stm32项目中。在CLI模式下,我们需要手动添加STM32Cube.AI 的运行环境到项目,所以我们可以调用network.h中的函数来运行模型。
当然,STM32Cube.AI 提供一种更简便的方式来集成AI模型。假设您的项目从一个ioc文件开始,我们可以将AI模型添加到cubeMX的代码生成阶段,然后一起生成代码。
启用cubeMX中的AI功能如下,选择对应的STM32Cube.AI 的版本。
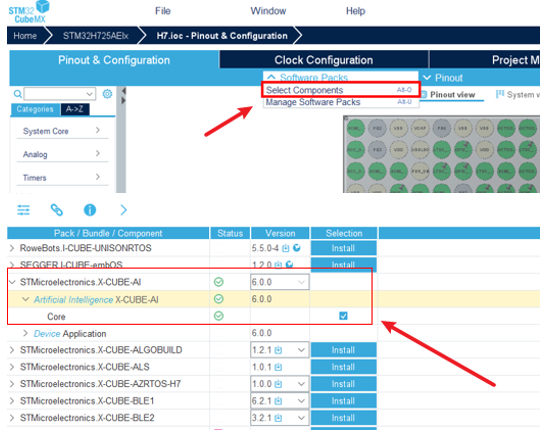
我们可借此将AI模型集成到项目中。
就这样,在我们生成代码后,AI模型转化为优化的C代码,然后与STM32Cube.AI 运行环境的对应版本一起集成到项目中。
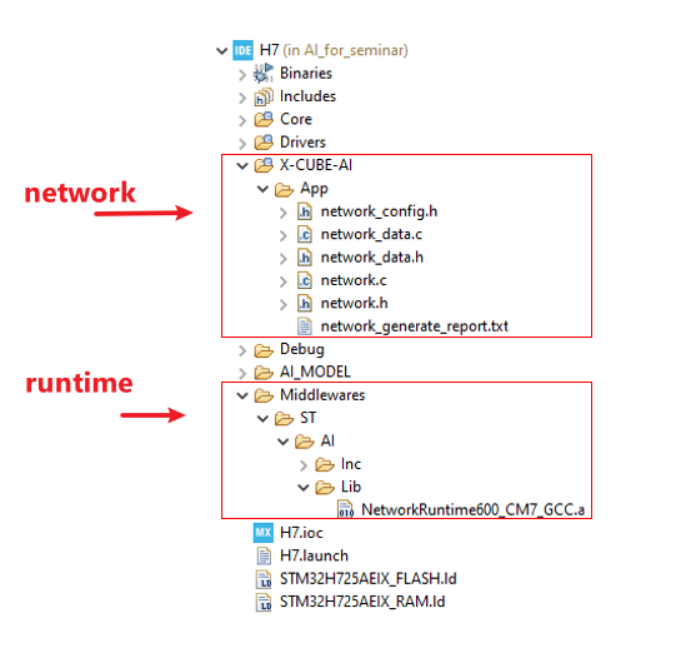
这样,我们就可以调用network.h中的函数将模型运行起来。
最终,我们通过这种方式顺利地将模型集成到了项目中。通过比较这两种不同的方法,我们可以发现STM32Cube.AI 和NanoEdgeAI之间的差异。NanoEdgeAI更简单、高效,而STM32Cube.AI 则更加灵活且可定制。
-
如何在STM32f4系列开发板上部署STM32Cube.AI,2024-11-18 1030
-
用STM32Cube.AI部署ONNX模型实操示例:风扇堵塞检测2023-09-28 3746
-
如何在OpenMV生态系统中集成STM32Cube.AI生成的代码2023-09-20 593
-
ST MCU边缘AI开发者云 - STM32Cube.AI2023-02-02 1304
-
请问STM32WL可以与STM32Cube.AI一起使用吗?2022-12-07 724
-
X-CUBE-AI STM32Cube扩展包精选资料推荐2022-11-29 934
-
意法半导体发布STM32Cube.AI开发工具2022-08-09 2339
-
STM32Cube.AI将神经网络转换为STM32的优化代码2022-05-16 2870
-
STM32Cube.AI工具包使用初探2022-02-22 1203
-
小白初学者从零开始创建stm32工程(包括带着的FreeRTOS实时操作系统快速入门)2021-12-05 1431
-
STM32Cube.AI库的高级特性2021-11-16 4547
-
如何使用stm32cube.ai部署神经网络?2021-10-11 4820
-
Cube ai简介2021-08-03 1796
-
STM32CubeMX在F7子板上从零开始创建TouchGFX UI项目2021-03-23 3072
全部0条评论

快来发表一下你的评论吧 !
