

利用深度学习在工业图像无监督异常定位方面的最新成果
描述
导读
本文通过全面综述利用深度学习在工业图像无监督异常定位方面的最新成果,帮助该领域的研究人员快速入门。
中科院自动化所、北京工商大学和印度理工学院等单位联合发表最新的工业异常定位(检测)综述。20页综述,共计126篇参考文献! 本综述将工业异常定位方法根据不同的模型/方法进行分类和介绍,最新方法截止至2022年2月!同时,综述还包括了在完整MVTec AD数据集上的性能对比,并给出了多个工业异常定位的未来研究方向!

论文题目:Deep Learning for Unsupervised Anomaly Localization in Industrial Images: A Survey
发表单位:中国科学院自动化所、北京工商大学、印度理工学院
论文地址:https://arxiv.org/abs/2207.10298
1. 概要
目前,基于深度学习的视觉检测在监督学习方法的帮助下取得了很大的成功。然而,在实际工业场景中,缺陷样本的稀缺性、注释成本以及缺陷先验知识的缺乏可能会导致基于监督的方法失效。近5年来,无监督异常定位算法在工业检测任务中得到了更广泛的应用。本文旨在通过全面综述利用深度学习在工业图像无监督异常定位方面的最新成果,帮助该领域的研究人员快速入门。该综述分析了120多份重要文献,涵盖工业异常定位的不同方面,主要涵盖各种概念、挑战、分类、基准数据集以及所提及方法的定量性能比较。在回顾迄今为止的研究成果时,本文对未来的几个研究方向进行了详细的预测和分析。本综述为对工业异常定位感兴趣的研究人员以及希望将其应用于其他领域异常定位的研究人员提供了详细的技术信息。
2. 异常定位的定义
什么是AL?
人类视觉系统具有感知异常的固有能力——人不仅可以区分缺陷图像和非缺陷图像,即使他们以前从未见过任何缺陷样本,而且还可以很容易的指出图像中那些位置存在异常。异常定位(AL,anomaly localization)被引入学术界也是出于同样的目的,即教会机器以无监督的方式“发现”异常区域。在深度学习方法中,“无监督”意味着训练阶段只包含正常图像,没有任何缺陷样本。无监督范式下的AL方法首先避免了收集异常或缺陷样本的困难,这在监督方法中是无法避免的;因为在工业场景中,没有缺陷的正常图像远远多于异常样本。其次,在无监督方法中可以消除监督方法中训练样本的标记成本。最后,无监督方法还避免了标记偏差的影响,这在监督方法中常见。由于训练数据只有正常类,因此可以将其称为“半监督”。然而,为了与大多数现有方法统一,我们在以下内容中删除了术语“无监督”或“半监督”,仅将其称为AL。
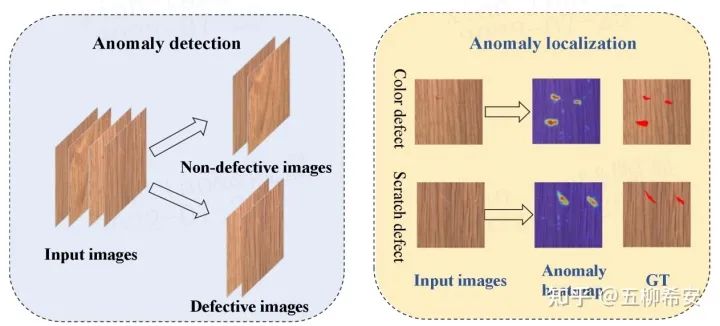
AD和AL的区别:计算机视觉中异常检测AD(anomaly detection)也常常被提及,离群点检测或one class 分类是AD的其他术语。图1展示了AD(anomaly detection)和AL之间的区别。AD是指在图像级别将缺陷图像与大多数非缺陷图像区分开来的任务,只关注图像类别,正常or异常。另一方面,AL也称为异常分割,用于生成像素级异常定位结果,它不仅仅关注图像类别,更关注异常的详细位置。异常热图中的颜色越深,如图1所示,该位置存在异常的可能性越大。
什么是异常?
一般来说,工业领域中的异常通常指缺陷,这里不仅仅包括三伤(划伤、碰伤和压伤等),异色,亮痕等纹理变化的缺陷,而且有更为复杂的,需要进一步逻辑判断的功能缺陷。例如晶体管管脚是否插入到pin中,是否装错,装反或少装。下图第一行展示了MVTec AD数据集上的纹理缺陷,第二行展示了MVTec AD数据集上的功能缺陷。MVTec AD中大部分缺陷类型为纹理缺陷,少部分缺陷为功能缺陷,功能缺陷主要存在晶体管这个数据集中,因此这个数据集是MVTec AD15个数据集中最难检测的。

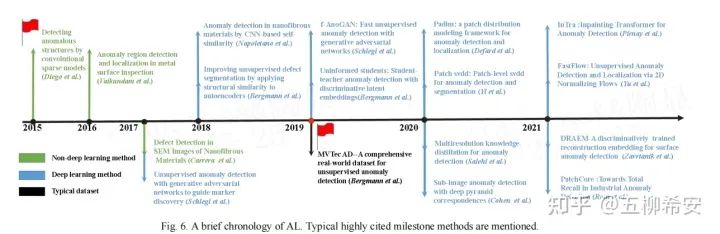
上图追溯了工业图像的AL的历史。大多数基于非深度学习的AL模型依赖于稀疏编码[14,15]和字典学习[16]。自2017年以来,由于深度学习技术在计算机视觉领域的巨大成功,出现了越来越多的深度学习方法[19]。GAN模型[17,22]和AE重建网络[18]首次用于深度AL模型。为了一致地比较AL的影响,MTVec公司提出了一个完整的工业AL数据集,也就是MVTec AD数据集[20]。后来,基于特征嵌入的模型变得更加有效和高效,成为流行的AL架构。知识蒸馏[21,26]和预训练特征比较[23,25,30]是典型模型的示例。然后,将几种基于自监督学习的方法应用于上述任务[24,29]。基于Flow的生成模型[28]和ViT模型[27]作为更好的方法也嵌入到AL网络中。尽管AL研究的历史很短,但它已经发表了数百篇论文,我们综合选择了在著名杂志和会议上发表的有影响力的论文;这项调查侧重于过去五年的主要进展。由于MVTec AD数据集的提出,在过去的两年内,大量方法呈现井喷状态被提出,该数据集的指标也被刷到非常高,这一点可以从paper with code网站 (https://paperswithcode.com/sota/anomaly-detection-on-mvtec-ad)看出。
这篇综述和以往综述有什么区别?
文章中列出了与AD/AL相关的多项综述,涉及早期非深度学习AD方法[6]、基于深度学习的AD方法[5,7-9]、有限的AL模型[10]或仅关注GAN的AD/AL[11]等领域的研究。然而,很少有综述致力于完整和全面的异常定位AL方法。另一方面,大多数现有综述仅仅关注图像级分类的AD方法,该方法很容易忽略工业场景中的细微异常区域。此外,近五年来,所有方法已经从图像级比较(重建或生成)发展到特征级比较,也从简单的缺陷合成代理任务发展到基于对比学习的自监督方法。我们的工作系统全面地回顾了无监督人工智能的最新进展。其中包括对该领域以前从未探索过的许多方面的深入分析和讨论。特别是,我们总结和讨论了解决各种问题和挑战的现有方法,提供了路线图和分类,回顾了现有的数据集和评估指标,对最先进的方法进行了全面的性能比较,并对未来的方向提出了见解。我们希望我们的综述能够提供新的见解和灵感,促进深入了解AL,并鼓励对本文提出的开放主题进行研究。
3. 代表性方法的分类
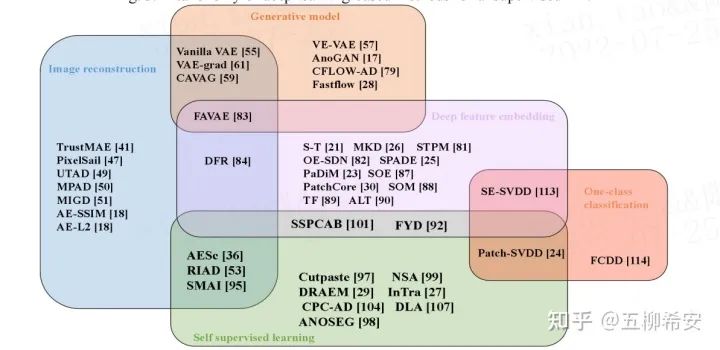
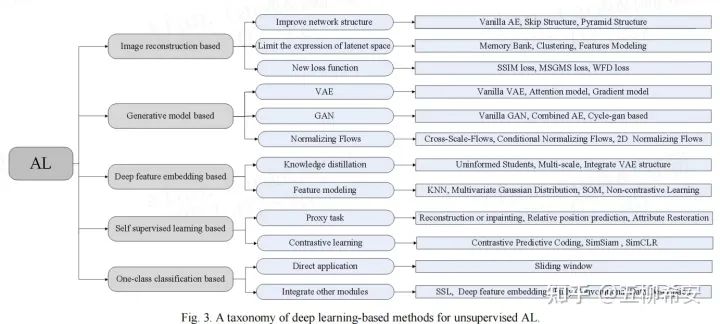
我们将目前的方法分为5大子方法,并对每个子方法进行了详细的介绍和对比分析。在每个小节中,我们对其代表文章进行了进一步细分。然而,有些工作属于不止一个类别。因此,我们利用文章中图4的维恩图划分工作,重叠区域包括方法的交叉部分。
主要包括:
1)基于图像重建的方法:这是最早出现的方法,也非常直观,期待AE自动编码器能够对异常图像重建成正常图像,然后重建图像和正常图像作差,得到定位结果。主要的改进包括网络结构、隐空间和损失函数的改进。该方法的问题在于难以保证异常图像中的异常区域被很好重建为正常,同时图像中的正常区域重建的效果和输入一致,这样两者作差的结果并不能完全代表异常区域。
2)基于生成网络的方法:代表的方法就是VAE、GAN和Normalizing Flow (NF)。VAE中引入了类似CAM这种求梯度方式来判断异常位置的方法。GAN主要是通过多个生成器和判别器的设置,来提升生成或重建的图像效果。然而,GAN和VAE都缺乏对概率分布的精确评估和推理,这往往导致VAE中的模糊结果质量不高,GAN训练也面临着如模式崩溃和后置崩溃等挑战。NF能够较好的解决上述问题,同时NF会和后面的基于特征的方法进行结合,也是目前在MVTec AD上取得效果最好的方法。
3)基于深度特征建模的方法:主要包括知识蒸馏和特征建模两大类。特别是特征建模,可以细分为很多小类,例如:KNN,SOM,高斯建模等,详细的内容可以见文章。
4)基于自监督的方法:主要分为代理任务和对比学习。代理任务包括常见的重建、补全、相对关系预测和属性修护等。
5)基于one-class分类的方法:这个方法主要是异常检测AD采用的,如果将图像划分为滑动窗口,所有的AD方法也适用于AL。此外,它也可以与前面4种方法相结合。
4. 实验评估和对比分析
数据集:准确来说常用于AL定位的数据集有三个:NanoTWICE、MVTec AD和BTAD。这三个数据集也是做AL论文中引用最多的。当然还有一些有监督的分割数据集也会被拿过来做评测,包括KolektorSDD、KolektorSDD2和MT Defect等。
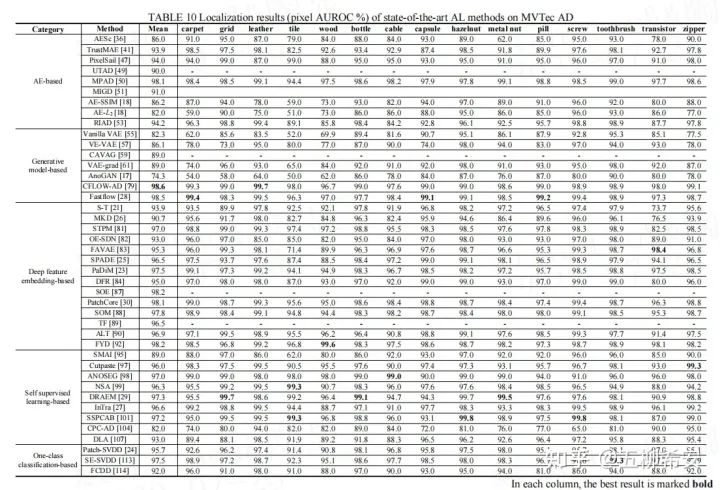

MVTec AD数据集上的性能:文章中表10和11总结了目前AL方法(主要发布于2017至2021)在MVTec AD数据集上的性能。我们观察到,大多数方法在AE的帮助下达到了基线性能。一些尝试致力于设计更强大的模块,如图像修复和GAN生成网络。例如RIAD方法,在MVTec AD数据集上的像素AUROC已达到94.2%[53]。然而,实验结果表明,这些纯基于AE自动编码器的重建或生成方法很难在MVTec AD数据集上表现良好。
相比之下,基于深度特征嵌入的方法很快在AL中展示了它们的优势。过去论文中的结果表明,三种典型的特征比较方法,S-T[21]、SPADE[25]和DFR[84],在MVTec AD数据集上分别实现了93.9%、96.5%和95.0%的像素AUROC。从通用特征建模方法[23]开始,当引入更有效的策略时,基于特征嵌入的方法稳步改进,例如,将特征选择引入半正交嵌入[87]、注意力策略[23,43]、带内存库的KNN[30]、自组织特征[88]和对齐特征[92]。因此,在MVTec AD数据集上,大多数方法产生约93%的像素AUROC和91%的PRO分数。
此外,CFLOW-AD[79]与一种新型的生成网络相结合,性能优于其他最先进的模型,并实现了迄今为止MVTec AD上最好的像素AUROC。另一方面,MPAD[50]结合预先训练的功能,超越了其他最先进的模型,并在MVTec AD上取得了迄今为止最好的PRO分数。在这里,在文章中图13中,我们展示了MVTec AD上四种典型特征嵌入方法的AL结果的可视化,包括STPM[81]、PatchCore[30]、PaDiM[23]和CFLOW-AD[79]。这些结果是使用Intel corporation维护的标准图像库Anomalib[125]获得的。基于自监督学习的方法可以从未标记的图像中学习视觉特征,并作为附加模块嵌入到上述网络结构中。与原始的基于AE自动编码器的方法相比,这种方法,例如ANOSEG[98]、NSA[99]和DRAEM[29]可以获得更好的结果。此外,与图像重建或预训练特征相比,基于对比学习的方法[92107]由于异常区域的判别信息,表现出非常有竞争力的性能。基于One class分类的方法通常耗时且定位结果不准确,尤其是裁剪局部斑块和提取单个局部特征的计算时间。然而,一些方法包括更复杂的特征比较过程,例如,patch-SVDD[24]和SE-SVDD[113]。
总之,基于深度学习的人工智能方法可以通过采用不同的策略在MVTec AD数据集上获得相对满意的结果。特别是,15个数据集中有3个数据集没有被大多数方法克服;这些是瓷砖、木材和晶体管数据集。瓷砖和木材是典型的纹理数据集,包含多尺度和多类型的缺陷,目前主要方法未达到95%的AUROC。晶体管数据集具有包含高级语义信息的缺失缺陷类型,也就是功能异常。在该数据集中,它将所有缺失范围视为ground-truth。因此,目前的主要方法也没有达到理想的性能。
5. 未来的研究方向
功能异常:从上表中提到的优缺点可以看出,许多方法的异常定位效果在某些特定数据集上显著下降。例如,DFR[84]的缺点是晶体管数据集的性能较差(参见文章表6、10)。这是因为文章表10中显示的大多数数据集是纹理缺陷,例如划痕和凹痕,而非功能异常。功能异常违反了基本约束,例如,允许的对象位于无效位置或缺少所需的对象。在工业场景中,这两种类型同等重要。目前,Bergmann等人[126]已经提出了一种联合检测纹理和功能异常的方法。因此,对功能缺陷或异常的研究将是未来的一个重要方向。
发布丰富的AL数据集:与真实行业场景相比,公共异常位置数据集还不够大或丰富。应提供具有变化成像条件(如照明、透视、比例、阴影、模糊等)的更复杂数据集,以更客观地评估AL算法的效果。现有的MVTec AD具有单成像、相对良好的图像质量和某些类别的对齐。一些现有的方法甚至利用这一特性来提高性能。尽管取得了有希望的结果,但这些方法无法适应实际复杂的工业场景。因此,有必要拥有一些现实而丰富的工业数据集。
基于ViT的方法:基于ViT的方法由于其优越的性能,目前在计算机视觉领域占据主导地位。还提出了一些基于ViT的工作[27、124、79]来解决AL问题。ViT在长距离特征建模中具有独特的优势。综合考虑多尺度异常区域是ViT可以改进的方向。此外,AL的最佳框架是基于NF的生成模型。因此,ViT和NF的结合也一直是一个重要的方向。
有意义的模型评估:如文章中图13所示,高像素AUROC值和精细的定位性能之间存在偏差,这可能会导致模型有效性问题。许多方法仍然使用像素AUROC评估指标,但AL的可视化结果表现并不佳,背景存在大量过检,也就是异常被定位出来的效果很粗,缺陷的轮廓并不精细。建议未来的工作在建立模型时考虑精细边界问题,或选择IoU度量进行模型评估。
准确的异常类型:实际工业场景中的异常类型多种多样,不同异常类型的重要性不同。现有的AD/AL方法,仅仅给出缺陷这一单一类别或位置,无法得到详细的缺陷类型,例如划伤、异物、异色等,这个问题挑战了AD或AL的经典范式,需要开发能够区分异常类型的学习方法。已有方法[122]对异常类型进行聚类,并将异常数据分组到语义一致的类别中,但这仅仅是一个开始。
无监督三维异常定位:随着三维传感器的普及,工业场景中越来越多的缺陷检测任务正在从二维场景转移到三维场景。相应地,三维场景中的人工智能也将成为一种发展趋势。最近,MVTec公司在2021年底公开了一个3D AD/AL数据集[123]。因此,我们认为3D AD/AL构成了一个相关的未来方向。
审核编辑 :李倩
-
使用MATLAB进行无监督学习2025-05-16 1747
-
深度学习中的无监督学习方法综述2024-07-09 3265
-
基于transformer和自监督学习的路面异常检测方法分享2023-12-06 3258
-
机器学习技术在图像分类和目标检测上的应用2022-10-20 2892
-
机器学习技术在图像处理中的应用2022-10-18 3424
-
堆叠图像传感器在图像传感器架构演进方面的最新成果2022-07-10 2452
-
基于深度学习的异常检测的研究方法2021-07-12 1762
-
图形处理在多媒体技术应用方面的经验和成果2021-02-01 1359
-
机器学习算法中有监督和无监督学习的区别2020-07-07 6821
-
无监督机器学习如何保护金融2020-05-01 1343
-
如何用Python进行无监督学习2019-01-21 5435
-
利用机器学习来捕捉内部漏洞的工具运用无监督学习方法可发现入侵者2018-11-22 1626
-
英伟达通过利用GAN及无监督学习,实现了场景间的四季转换2018-05-16 2881
-
基于深度学习的多尺幅深度网络监督模型2017-11-28 1307
全部0条评论

快来发表一下你的评论吧 !
