

FPGA与GPU计算存储加速对比
电子说
描述
硬件制造商正在将加速方法应用于计算存储,这是专门设计用于包含内嵌计算元素的存储。这种方法已经被证明可以为分析和 AI 应用提供优异的性能。使用或者不使用机器学习辅助的分析以及验证,都可以借助计算存储器件进行加速。这些器件提供了一个关键的优势,使得成本高昂的计算被卸载到存储器件上,而不必在服务器 CPU 上完成。与标准的存储/CPU 方法相比,通过计算存储获得的优势包括:
1. 借助应用专用编程定制可编程硬件,获得更高性能
2. 将计算任务从服务器卸载到存储器件,释放 CPU 资源
3. 数据与计算共址,降低数据传输需求
这种新颖的方法前景光明。不过,您应根据具体用例评估这种方法,考量性能、成本、功耗和易用性。性价比和单位功耗性能在选择加速硬件评估时,占据主要比率。在本文中,我们将研讨单位功耗性能。
计算存储功耗比较
在这个场景中,我们将比较以 CSV 数据读取用例为主的三种工具:英伟达 GPUDirect 存储 和RAPIDS存储,以及基于赛灵思技术的三星 SmartSSD 存储。CSV 读取在计算密集型流水线中起着重要的作用(参见图 1)。
在下文中,我们将性能定义成 CSV 的处理速率,或处理“带宽”。我们先快速回顾一下三种系统的运行方式。
英伟达 GPUDirect 存储
端到端满足分析和 AI 需求
将 GPU 用作计算单元,紧贴基于 NVMe 的存储器件布局 (GPUDirect)
使用 CUDA 进行编程 (RAPIDS)
英伟达用其 CSV 数据读取技术衡量相对于标准 SSD 的性能提升。结果如图 1 所示。使用 1 到 8 个加速器时,对应的吞吐量是 4 到 23GB/s。
三星 SmartSSD 驱动器
将赛灵思 FPGA 用作计算单元
与存储逻辑内嵌驻留在同一个内部 PCIe 互联上
通过编程在存储平台上开展运算
赛灵思数据分析解决方案合作伙伴 Bigstream 与三星合作,为 Apache Spark 设计加速器,包括用于 CSV 和 Parquet 处理的 IP。SmartSSD 的测试使用单机模式的 CSV 解析引擎,以便开展比较。结果如图 2 所示,使用 1 到 12 个加速器时,对应的吞吐量是 4 到 23GB/s,同时也给出英伟达的结果(使用 1 到 8 个加速器)。请注意,本讨论中的所有结果都按 x 轴上的加速器数量进行参数化。
这些结果令人振奋,但在选择您的解决方案时,请务必将功耗情况纳入考虑。
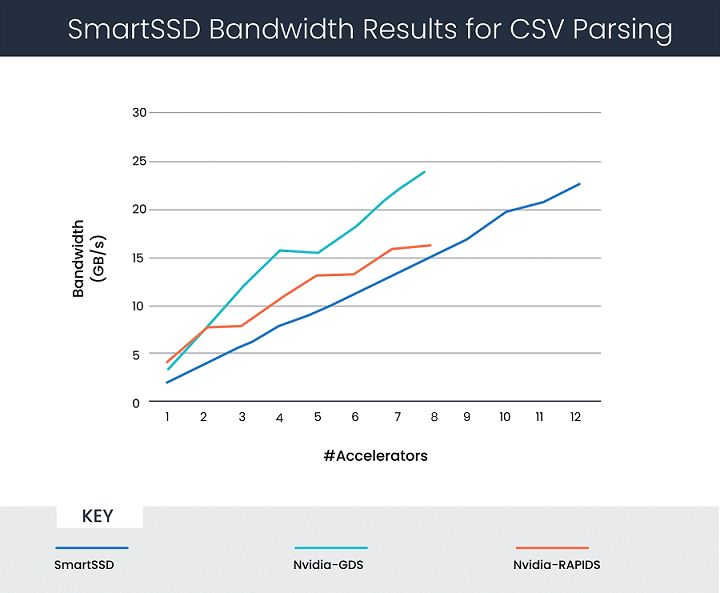
图 2:SmartSSD 驱动器的 CSV 解析性能结果
单位功耗性能比较
图 3 显示了将功耗考虑在内后的分析结果。它们代表单位功耗达到的性能水平,根据上述讨论中引用的相关材料,给出了以下假设:
Tesla V100 GPU:最大功耗 200 瓦
SmartSSD 驱动器 FPGA:最大功耗 30 瓦
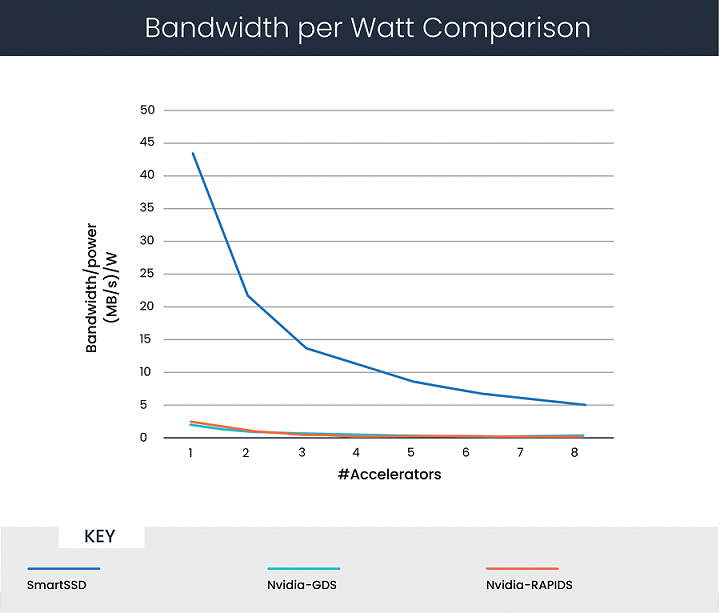
图 3:CSV 解析的每瓦功耗带宽比较
在这个场景下,计算表明,在全部使用 8 个加速器的情况下,SmartSSD 的单位功耗性能比 GPUDirect Storage 高 25 倍。
最终思考
计算存储的优势在于能增强数据分析和 AI 应用的性能。然而,要让这种方法具备可实际部署的能力和实用性,就必须在评估时将功耗纳入考虑。
针对用于 CSV 数据解析的两种不同的计算存储方法,我们已经提出按功耗参数化的吞吐量性能曲线。结果显示,在使用相似数量的加速器进行比较时,SmartSSD 驱动器的单位功耗性能优于 GPUDirect存储方法。
审核编辑:郭婷
-
《CST Studio Suite 2024 GPU加速计算指南》2024-12-16 11949
-
FPGA是如何实现30倍速度的云加速的?都加速了哪些东西?2017-04-15 6556
-
用于加速c代码的PCIe FPGA如何开始2019-01-24 2466
-
GPU加速matlab程序2019-03-30 3140
-
对FPGA与ASIC/GPU NN实现进行定性的比较2023-02-08 2131
-
NoLoad面向Xilinx FPGA的存储和计算加速平台2018-11-26 3954
-
英特尔推出FPGA加速卡D5005助力高性能计算2019-08-06 1992
-
FPGA有什么优势,可以让FPGA替代GPU吗2019-11-01 3420
-
FPGA和GPU计算存储加速有啥不一样2021-08-09 7226
-
FPGA与GPU计算存储单位功耗性能2021-08-13 8510
-
FPGA与GPU计算存储加速对比:单位功耗性能考量因素2021-08-20 4361
-
GPU加速计算平台是什么2024-10-25 1450
-
GPU加速计算平台的优势2025-02-23 1288
-
FPGA和GPU加速的视觉SLAM系统中特征检测器研究2025-10-31 1067
-
基于openEuler平台的CPU、GPU与FPGA异构加速实战2026-04-08 1707
全部0条评论

快来发表一下你的评论吧 !
