

使用网络实例比较FPGA RTL与HLS C/C++的区别
可编程逻辑
描述
HLS的FPGA开发方法是只抽象出可以在C/C++环境中轻松表达的应用部分。通过使用Vivado(Xilinx)或Intel(Quartus)工具,HLS工具流程基本上可用于任何BittWare板。
要想成功申请HLS,认清自己申请的部分很重要。准则包括:
- 目标用途,一般来说,都是用高级语言开始定义的IP块。数学算法就很好用,或者像我们的RSS块一样,进行一些网络协议处理。
- 另一类用途是定义不清的块,因此可能需要多轮实现。这里最大的好处是允许HLS工具自动将产生的原生FPGA代码进行流水线处理,往往比快速手工编码流水线发出的阶段更少。另外,当需要修改手工编码的流水线时,一个并行路径上的延迟变化会对所有的东西产生连锁反应。 使用HLS工具从头开始第二次自动流水线,可以消除这种头痛的问题。
- 最后,HLS 流程可以更容易地在不同品牌和速度等级的 FPGA 之间移植代码。这是因为 HLS 会自动生成适当数量的流水线阶段--在使用 Verilog 或 VHDL 时需要手动指定。
HLS目前的局限性很明显,它的范围仅限于IP块。应用团队仍然需要为其他组件提供RTL,尽管利用类似于BittWare的SmartNIC Shell这样的RTL部分,用户可以完全在HLS中定义他们独特的应用。还应该注意的是,对于最简单的代码或主要由预优化组件组成的大型设计来说,HLS是一个糟糕的选择。
我们的应用。在FPGA上实现RSS网络化
什么是RSS?RSS是"Receiver Side Scaling"的缩写。它是一种散列算法,用于有效地在多个CPU之间分配网络数据包。RSS是现代以太网卡上的一个功能,一般实现了微软定义的特定Toeplitz哈希。
我们的RSS应用的环境是BittWare的SmartNIC Shell。SmartNIC Shell的设计是为了让用户在构建基于FPGA的网络应用时有一个良好的开端。它为用户提供了一个优化的基于FPGA的100G以太网管道,包括用于主机交互的DPDK。用户只需将其应用作为一个IP块放入即可。
在这种情况下,BittWare也是用户,我们创建了一个RSS的FPGA实现应用。使用传统RTL方法创建RSS的团队和HLS团队都能够使用SmartNIC Shell作为他们的FPGA以太网框架,并专注于RSS应用本身。
BittWare的RSS实施
我们基于FPGA的RSS实现是专门基于DPDK源代码树中的C代码,该代码的测试函数也可以在该树中找到。我们的RSS应用还使用了一个64个entry的indirection表,而不是更常见的128个entry的表。对于这个HLS研究来说,最重要的是我们要把函数移到FPGA中,开始时是用C语言定义的,这符合我们HLS成功的第一标准--用C或C++定义。
使用图元组对数据包进行分组
RSS功能的目标是在CPU之间分配数据包,使相关的数据包流保持在一起。不同的Toeplitz密钥集提供了不同的分配模式。然而,无论密钥集是什么,我们的RSS函数都使用每个数据包的源和目的IP地址以及源和目的端口作为输入。这四个部分组合起来称为4-tuple。
请注意,对于我们的RSS应用,我们假设4-tuple已经被解析并添加到数据包的元数据中。另一个SmartNIC Shell模块处理这个数据包分类功能。我们称该模块为"解析器",并将在另一篇BittWare白皮书中介绍。
我们的RSS实现目前接受96位的分类字段--足以满足IPv4源/目的地和端口的4元组。解析器为数据包中不可用的字段提供零;如果一个数据包不包括任何IP有效载荷,那么整个96位元组字段为零。
许多RSS实现使用5元组而不是4元组。 这样做需要额外的8位来容纳协议号。RSS的HLS用户可以很容易地通过修改源代码来适应这种变化。这种从4-tuple到5-tuple的快速适应能力是HLS成功的第二个标准的例子--对多轮实施的要求。
HLS性能编码
虽然使用HLS提供了一个类似软件的工具流,但开发人员仍然必须学习以硬件为中心的概念,如流水线和迭代间隔,这些概念是他们在为传统处理器编写C代码时可能没有接触过的。
HLS代码主要用于开发嵌入式设计的IP组件,通常是流水线式的。我们的RSS应用也不例外。对于RSS,最低的性能要求是每个512位输入字的处理速度要足够快,以跟上100Gb/s的饱和网络接口。这相当于每一个时钟周期以300MHz的频率处理一个新字。这个频率很有挑战性,因为即使是最快的FPGA,其运行频率也不会超过400MHz。显然,我们必须在每个时钟处理一个新的字。
这里介绍了迭代间隔(II)的概念,它指的是流水线中给定的逻辑完成所需的时钟周期数,对于RSS模块,我们要求每隔一个时钟就有一个结果,II为1。对于RSS模块来说,我们要求每隔一个时钟就有一个结果,II为1,因此,我们需要了解如何编写代码来避免破坏这个要求。
导致高二的原因包括以下几点:
- 当流水线的下一个输出需要流水线中另一个变量的未来结果时,就会引起循环间的依赖,例如递归。简单的递归运算符如累加器是允许的,因为FPGA包含的逻辑可以在一个时钟周期内完成这些计算。然而,更复杂的递归将需要更高的II值。
- RSS设计要求管道的每个阶段在3.3ns内完成。HLS工具将在需要的地方插入注册,以确保每个阶段满足这一时序要求。然而,如果组合逻辑不能被流水线化,就不一定能做到这一点。例如,深度组合逻辑可以是多个嵌套循环的索引计算。
- 如果目标时钟频率过高,而FPGA结构的路由路径实在太长,无法满足时序要求,II就会增加。 解决这个问题的办法是将逻辑分成两条路径,以一半的时钟频率运行。
代码的主体在所需的输入元组字数上循环,创建一个新的哈希值。在这里的例子中,我们使用3个字的输入元组,哈希值为96位。

这段代码实现了RSS计算的核心。它与从DPDK源码中提取的原始代码保持不变。 树。因此,在这个 RSS 模块中,所有的移植工作都是在定义模块的 AXI 接口和添加 Pragma 语句到定语如二。
如果输入长度是一个常数,FPGA可以完全展开两个循环,创建完全流水线的代码。
为了将IP组件集成到智能NIC框架工作中,需要定义接口和控制平面,以及任何读写外部接口的逻辑。智能网卡框架使用AXI接口协议来进行组件之间的通信。

定义AXI接口和添加pragma语句导致代码行数太多,无法在这里用图来显示。完整的源代码文件可以从BittWare获得。
由于Xilinx编译器的常量是按英特尔字节顺序(little-endian),但网络协议使用的是网络字节顺序(big-endian),因此存在一个endianness的挑战,这并不影响性能或资源的使用,但需要在HLS处理之前改变任何输入数据的endianness。这并不影响性能或资源使用,但要求任何输入数据在HLS中处理之前必须改变其字节序。
本地编程与HLS的比较。结果
我们之所以有两个FPGA RSS实现,是因为我们的初始版本是用Verilog编写的。 这是在我们评估的假设下发生的:原生的FPGA编码总是导致最小的资源使用。然而,一位BittWare工程师对这一决定提出了质疑,并在HLS中重新实现了RSS,以测试这一方法。他是对的,BittWare现在已经用HLS代码替换了SmartNIC Shell中的RSS模块和解析器模块。

两种实现之间最大的区别是Verilog/RTL版本使用了FIFO,而HLS C++版本没有。 我们很惊讶地看到,转到HLS后,资源使用量居然下降了--这是我们在所有情况下都无法预料的。
时间上的节省呢?粗略的说,我们看到原生RTL版本的时间线为一个月,而HLS代码在一周内完成。
英特尔HLS与Xilinx HLS的比较
这个例子使用的是Xilinx HLS。然而,使用高级语言的一个关键优势是它们能够在一定程度上抽象出不同技术架构之间的潜在差异。英特尔也有一个等效的编译器,也可以将C++编译成门RTL代码。
为了使用英特尔i++编译器编译相同的代码,需要对数据类型进行一些细微的改变,并对#pragmas进行修改。英特尔和Xilinx之间最大的区别是英特尔使用Avalon流媒体接口,Xilinx使用AXI。这就需要一个简单的shim接口来从一个转换到另一个。
协同模拟
一旦功能上得到验证,调用协同仿真环境进行周期精确的RTL仿真就是一件小事。Vivado-HLS自动生成一个RTL测试平台,该测试平台由原始C++代码生成的向量驱动。 用户唯一需要修改的是处理设计中的任何无限循环或阻塞接口。RSS模块被设计为作为固件流水线的一部分无限期运行。因此,仿真将永远无法完成,协同仿真将挂起。为了避免这种情况,我们将RSS代码的"while(1)"主循环改为一个固定的长度,长度足以消耗掉测试台的所有输入,并且长度足以产生所有需要的输出。
协同仿真使人们对工具正确生成的RTL和模块的时序特性符合原始设计参数有了额外的信心。
协同仿真流程也可作为英特尔HLS工具栈的一部分。
按IP块构建HLS
HLS工具流需要对所使用的接口协议有内置的认识。BittWare的IP块一般使用高级可扩展接口(AXI)进行通信。具体来说,就是用AXI4-Stream来传递数据包数据,用AXI4-Lite作为控制平面。
对于100GbE,BittWare使用一个512位宽、时钟频率为300MHz的AXI4-Stream接口。与每个数据包相关联的元数据在其自身的总线上跟踪,当数据包数据的TLAST信号被确认时,该总线在数据包结束时有效。数据包元数据在区块之间和发布之间不断变化。 它通常包括以下信息:
- 数据包到达的物理以太网连接器的编号。
- MAC识别出的与数据包相关的任何错误。
- 80位IEEE-1588格式的时间戳,有时也有缩短的64位格式。
- 一个"删除"位,表示数据包需要在下一次机会从数据流中删除。
- 一个我们通常称之为"队列"的数字,用来表示数据包的目的地。它是由管道中的一个IP块(甚至可能是这个块)计算出来的。
我们对RSS块的控制平面包括:
- 启用/禁用位
- 托普利兹哈希的20个16位密钥
- 64个条目的间接表
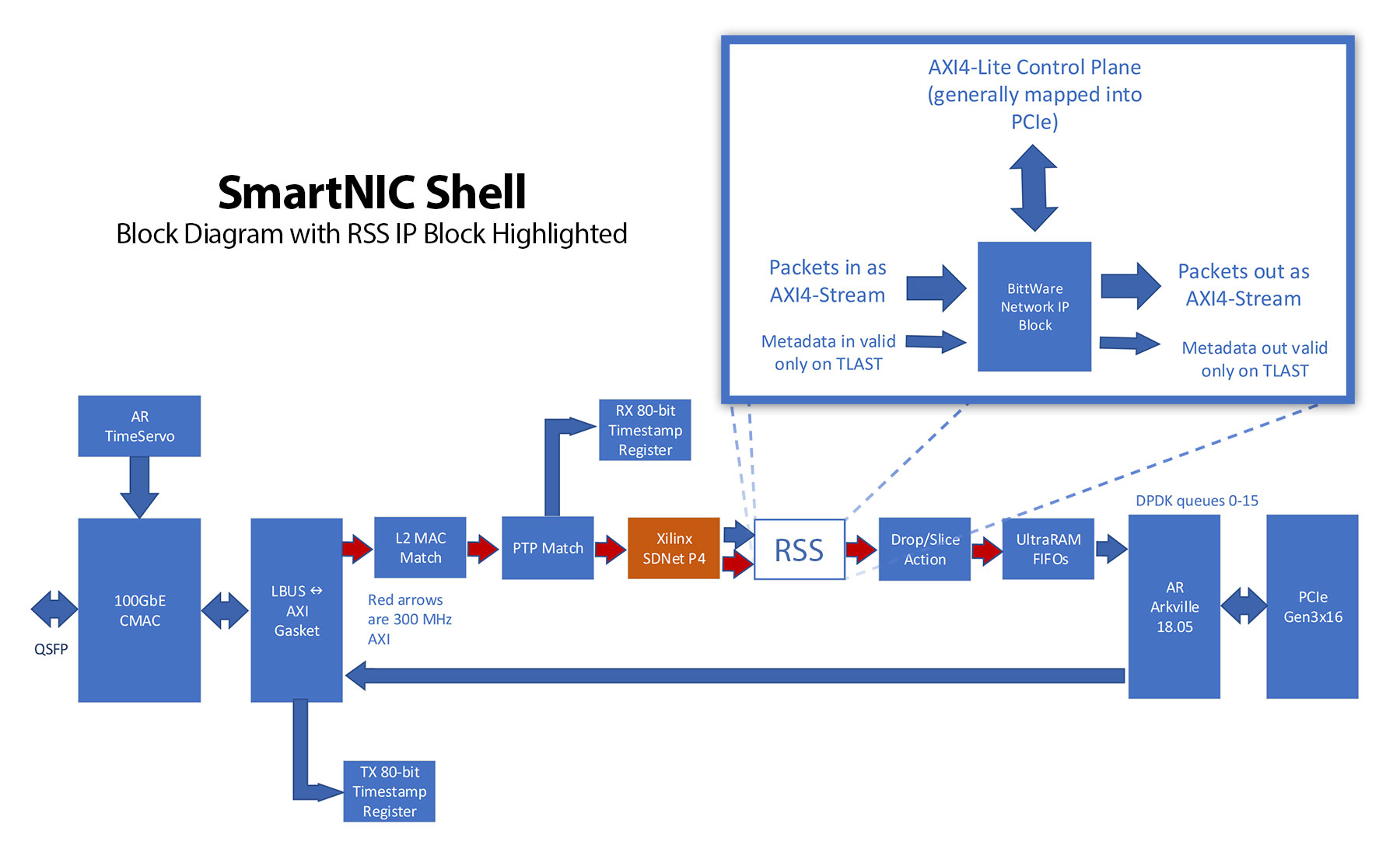
SmartNIC Shell框架的实例实现框图。这里RSS块被替换为HLS实现。
结论
当今的高级FPGA开发工具旨在缩短产品上市时间,减少对硬件工程师的依赖。 然而,认为使用这些工具总是会给应用性能带来妥协--无论是速度还是硅资源,这种假设是错误的。
我们发现使用 HLS 为 BittWare 的 SmartNIC Shell 开发 IP 块,将开发时间从一个月缩短到一周。我们还发现它实际上使用了更少的门来实现。
XUP-P3R板的所有者和SmartNIC Shell的用户可以获得RSS块的源代码。它很好地说明了如何在HLS代码中使用AXI接口。
审核编辑:刘清
-
C语言与C++的区别及联系2025-12-24 236
-
C语言和C++中结构体的区别2024-10-30 1683
-
优化 FPGA HLS 设计2024-08-16 1138
-
介绍一种通过SystemC做RTL/C/C++联合仿真的方法2023-12-13 3968
-
HLS中RTL无法导出IP核是为什么?2023-09-28 867
-
AMD全新Vitis HLS资源现已推出2023-04-23 2043
-
C++中struct和class的区别?2023-03-10 1350
-
FPGA——HLS简介2023-01-15 6972
-
FPGA基础之HLS2022-12-02 7897
-
C语言与C++的区别2022-09-16 1686
-
Vitis HLS工具简介及设计流程2022-05-25 3855
-
如何在不改变RTL代码的情况下,优化FPGA HLS设计2020-12-20 2686
-
【正点原子FPGA连载】第一章HLS简介-领航者ZYNQ之HLS 开发指南2020-10-10 2573
-
一文详解HLS从C/C++到VHDL的转换2018-07-14 8242
全部0条评论

快来发表一下你的评论吧 !
