

FPGA加速的NVMe存储解决方案
存储技术
描述
介绍
近年来,向基于NAND闪存的存储迁移和非易失性存储器快车®(NVMe™)的引入,为技术公司以不同的方式“做存储”增加了许多机会1。实时数字业务的快速增长和多样化要求这种创新,以便实现新的产品和服务。因此,新的存储产品顺应了更高的带宽、更低的延迟以及减少占地面积和总拥有成本的趋势--这对于依赖大型基础设施的公司来说是至关重要的改进。最近的市场报告2预测,NVMe市场将以约15%的年均增长率增长,到2020年达到570亿美元。NVMe市场继续发展,并在三个领域寻求进一步的技术创新。
1. 存储虚拟化以提高灵活性和安全性
2. 靠近存储数据的局部数据处理
3. 优化基础设施的分类存储3
2018年3月,BittWare发布了250系列FPGA产品,该产品提供了创新的解决方案,以满足存储市场的需求。250系列产品采用Xilinx® UltraScale+™ FPGA和MPSoC,在单芯片中提供ASIC级功能,符合存储行业的技术需求6。通过将NVMe与可重构逻辑FPGA和MPSoC相结合,BittWare提供了一类新的存储产品,在快速发展的市场中具有关键的差异化优势;Xilinx器件的灵活性和可重构性保证了基于20的解决方案可以保持最新的功能,因为NVMe标准随着时间的推移会融入新的功能5。
本应用说明介绍了BittWare支持FPGA和MPSoC的250系列加速器产品如何用于让客户为下一代物联网和云基础设施构建高性能、可扩展的NVMe基础架构。
NVMe路线图
自2011年NVMe诞生以来,NVMe联盟一直非常活跃。事实上,NVMe协议目前正从三个角度发展,分别定义在不同的规范中。除了基本的NVMe规范外,NVMe管理接口(NVMe-MI)详细介绍了如何管理通信和设备(设备发现、监控等),而NVMe over Fabric(NVMe-oF)则推动了如何通过网络与非易失性存储进行通信,以呈现协议的传输不可知性9。
随着时间的推移,随着越来越多来自不同行业的用户开始采用NVMe,新用户对新功能的需求进行了定性,并对规范提出了新的想法。NVMe协议的应用还在不断增加,它正在产生创新。硬件和软件公司正在通过引入新的外形因素、创造新的产品和设备等方式来寻找新的方式进入内存。NVMe生态系统的重点是为用户提供扩展到数据中心或超大规模基础设施的手段,协议规范将继续朝着这个方向发展9。
2019年将发布NVMe基础规范的1.4修订版,这将带来数据延迟、非易失性数据的高性能访问和多个主机之间数据共享的便利性方面的改进。NVMe用户,特别是云提供商期待的功能之一是IO确定性,这将提高IO10并行执行期间的服务质量。通过将后台维护任务的影响限制在最小范围内,并控制嘈杂邻居的影响,IO确定性功能将为用户在访问非易失性数据时提供一致的延迟。另一种方法是之前讨论的开放通道架构11。通过第二种方法,主机接管了部分管理功能,只有数据前往存储硬件。在这种配置中,硬盘与主机的物理接口仅限于高速数据通道,没有边带通道。这个例子显示了NVMe规范中任何变化的影响和相关性,并强调了对灵活的NVMe硬件基础设施的要求。
随着基础、MI和over Fabric规范的新修订版在未来几个月内出台,NVMe用户将受益于一个灵活的基础,它可以适应新的NVMe要求。250系列FPGA和MPSoC产品不仅提供了这种灵活性,而且还解决了当今客户的挑战,为客户带来了直接的竞争优势。
为什么是FPGA?
Bittware的FPGA和MPSoC产品采用了最新的Xilinx UltraScale+技术,并满足了数据中心对NVMe日益关注的需求。三十多年来,FPGA已经为多个行业提供了可编程硬件解决方案,并被广泛用于解决汽车、广播、医疗和军事市场等领域的计算和嵌入式系统问题。同时,近年来,FPGA厂商在集成系统设计中对这一成熟技术进行了最新、最优秀的改进。
Xilinx UltraScale+ FPGA和MPSoC产品采用16nm工艺,通过提供高速结构、嵌入式RAM、时钟和DSP处理来提高系统性能。此外,Xilinx器件还引入了更快的收发器技术(高达32.75Gb/s),以实现更高的吞吐量连接到网络或PCIe结构。凭借其高数量的串行收发器通道,UltraScale+产品可以同时连接到多个PCIe接口,并为主机CPU提供数据卸载接口。在某些情况下,通过用FPGA或MPSoC替换PLX开关,CPU可以卸载部分处理工作,腾出时间进行其他操作。FPGA和MPSoC的可编程逻辑还可以在系统中提供确定性和低延迟的接口,在某些用例中可以获得明显的竞争优势。
最近的FPGA系列现在也在器件结构中加入了嵌入式低功耗微处理器。UltraScale+ MPSoC通过将它们结合到单一封装中,满足了需要软件以及可编程逻辑的应用需求。例如,Xilinx Zynq UltraScale+ ZU19EG具有两个处理单元,一个是四核ARM Cortex-A53,一个是实时双核ARM Cortex-R5,此外还有一个图形处理单元ARM Mali™-400 MP2,满足有混合计算需求的应用。ZU19EG MPSoC器件是一款非常通用的芯片,特别适合NVMe over Fabric或Open Channel的实现,其中可编程逻辑为存储数据提供了低延迟的确定性路径,而ARM内核则可执行复杂的数据包控制操作,或在无CPU的嵌入式系统中取代主机CPU。
在过去的几年里,BittWare一直走在存储行业的前列,并通过开发基于NVMe技术的产品为其创新发展做出了贡献。BittWare认识到,FPGA可以减少I/O瓶颈,并为NVMe固态硬盘提供一条直接的高速确定性路径。早在2015年,BittWare就与Xilinx和IBM合作开发了创新的NoSQL数据库解决方案12。250系列FPGA&MPSoC板建立在这一初始产品的成功基础上,并为服务器存储背板增加了更深更快的板载内存、网络连接、片上系统和布线选项等功能。
250 FPGA & MPSoC产品系列
250 FPGA和MPSoC产品线包括三种FPGA适配器,即250S+、250-U2和250-SoC,可连接到各种行业标准的外形尺寸,如PCIe插槽、OCuLink/Nano-Pitch、SlimSAS、MiniSAS HD、U.2存储背板等。250系列产品可直接安装到现有基础设施的PCIe结构中,以实现对NVMe存储设备的低延迟直接访问。
250S+直连式加速器
该系列的第一个加速器是250S+。这款FPGA加速器采用Xilinx UltraScale+ Kintex 15P FPGA和4个板载四通道1TB M.2 NVMe驱动器(共4TB非易失性闪存),采用符合PCIe标准的8通道半高半长外形。另外,对于只想在系统中引入FPGA计算并且已经有存储设备的客户,M.2板载连接器可以使用Molex低损耗高速布线技术,连接到OCuLink/Nano-Pitch或MiniSAS HD NVMe背板。KU15P FPGA拥有1,143K系统逻辑单元、1,968个DSP Slices和70.6 Mb的嵌入式存储器,是UltraScale+ Kintex FPGA系列中最大的器件,并为实现增值功能提供了大量的可配置资源。板载DDR4内存库允许对更深层次的数据向量进行额外的缓冲。
250S+有两种配置。
最多四个M.2 NMVe固态硬盘通过卡上耦合到Xilinx FPGA。
OCuLink 分离式布线使 250S+ 成为大规模扩展存储阵列的一部分。
这款紧凑的高密度存储节点为主机需要高速读取或写入数据到NVMe驱动器的应用提供了一个一体化的解决方案。板载FPGA设备可以有效地协调和处理数据流,将驱动器呈现为一个或多个命名空间或实现RAID功能。250S+可用作直接连接加速器(DAA)来虚拟化存储,允许NVMe SSD与多个虚拟机共享,在主机CPU和NVMe SSD之间提供一层隔离和安全。FPGA的可编程逻辑还提供了在线打包、压缩或加密数据的选项,对驱动器访问带宽和延迟的影响很小;例如,Xilinx的擦除编码IP引入了可忽略不计的90ns延迟--与基于CPU的实现相比,在原始性能方面远胜一筹。250S+还解决了检查点重启或突发缓冲缓存的用例;为虚拟化和独立的AI和IoT环境提供了一个简单的缓存解决方案。
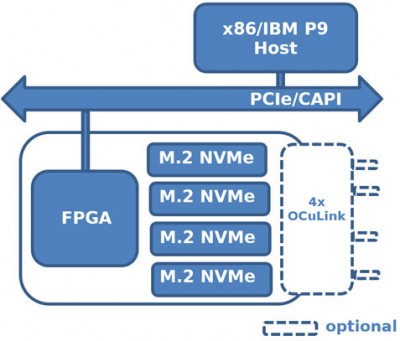
直接附着式加速器(DAA)
虚拟化NVMe存储,并在多个虚拟机之间共享。
隔离NVMe存储,以提高主机CPU和NVMe SSD之间的安全性。
250S+ & 250-SoC
250S-U2代理在线加速器
250系列的第二个成员是250-U2。这款加速器板采用Xilinx UltraScale+ Kintex 15P FPGA(与250S+相同)和一列DDR4内存,采用2.5“U.2驱动形式。与250S+不同的是,250-U2没有任何直接连接到FPGA的板载SSD。这款加速器的新颖设计使其能够在没有专用PCIe插槽的系统中适应现有的U.2存储背板,在现有的标准U.2 NVMe存储旁边提供额外的计算能力。这款250-U2产品承担了代理在线加速器(PIA)的角色。
250-U2可以执行在线压缩、加密和散列,也可以执行更复杂的功能,如擦除编码、重复数据删除、字符串/图像搜索或数据库排序/加入/过滤。根据应用的计算需求,背板群体将显示出不同比例的250-U2板卡用于NVMe驱动器。250-U2与存储一起位于U.2背板中,与其他标准的U.2 NVMe驱动器一样,具有利用NVMe-MI规范的维护选项。由于250-U2处理节点和存储直接连接到主机服务器的PCIe结构,DMA数据流量可以完全绕过CPU和全局内存,利用SPDK等技术优化端到端数据传输。使用RDMA或点对点DMA解决方案,数据直接在NVMe端点之间流动,完全绕过CPU。这些直接进入FPGA和MPSoC可编程逻辑的接口大大降低了访问延迟(Lusinsky,201721)。另外,这种硬件平台的另一个用例是作为卸载计算引擎,将很好地适应FPGAaaS可扩展基础设施。
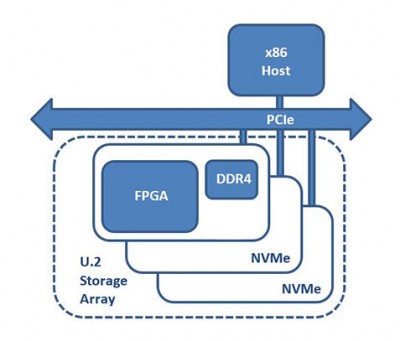
代理在线加速器(PIA)
在本地NVMe存储数据上执行低延迟、高带宽的处理。
多种主机形式 8通道PCIe适配器或2.5”U.2“适配器
250S+ & 250-U2
用于NVMe-over-Fabric的250-SoC。
该系列的第三款加速器250-SoC采用了Xilinx UltraScale+ Zynq 19EG MPSoC,可以通过两个QSFP28端口(支持100GbE的25Gbps线路速率)连接到网络结构,也可以通过一个16线PCIe 3.0主机接口和四个8线OCuLink连接器连接到PCIe结构。ZU19EG是该系列中最大的器件,拥有1,143K系统逻辑单元、1,968个DSP Slices和70.6 Mb的嵌入式存储器。器件封装中的嵌入式ARM处理和图形单元为具有混合处理要求的产品创造了理想的平台。
250-SoC的硬件通用性允许从网络直接访问存储,并支持NVMe-over-Fabric。NVMe-oF是下一代NVMe协议,可通过网络结构分解存储,并远程管理存储;NVMe-oF还提供了比SAS更多的灵活性,可按需设置网络阵列。分散存储或EJBOF(Ethernet Just-a-Bunch-Of-Flash)硬件可降低数据中心的存储成本、占地面积和功耗。
Xilinx Zynq MPSoC芯片为嵌入式系统提供了额外的灵活性。MPSoC板可以独立于主机CPU运行操作系统及其完整的软件栈。凭借其支持多达两个100GbE端口的高带宽网络功能和板载MPSoC,250-SoC无需为NVMe-oF应用同时使用外部网络接口卡(NIC)和外部处理器13。基于FPGA的NVMe-oF基础架构的实现非常简单,而且性能良好,因为数据只需通过硬件路径,从而提供了一个低和可预测的延迟解决方案。
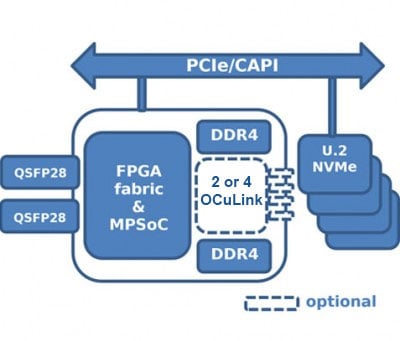
NVMe-over-Fabric (NVMEoF)
在数据中心网络结构上实现NVMe帧的低延迟和高吞吐量。
250-SoC
250-SoC为存储行业提供了一系列灵活的解决方案。250S+和250-SoC针对直接连接加速器的应用案例,满足虚拟化和提高安全性的需求。250-U2和250S+作为代理在线加速器,可以轻松插入到现有的基础设施中,为NVMe存储提供低延迟和高带宽的本地数据计算。最后,250-SoC支持NVMe-over-Fabric,作为一种仅有硬件的创新方法,在支持最新一代NVMe协议的同时,对存储进行分解。随着NVMe市场的不断发展,FPGA和MPSoC解决方案将解决NVMe产品的应用难题。
NVMe应用
NVMe技术给存储带来了颠覆性的创新,并对数据中心基础设施产生了深远的影响。协议的特性使NVMe成为设计涉及存储的新产品或应用时的首选。
数据库加速等企业应用需要低延迟以及高带宽的4K或8K数据写入传输速率,这两个要求完全符合NVMe协议的优势。这些特性使NVMe成为实现重做日志的领头羊,例如,在数据库发生故障时,会存储许多事务记录并用于未来重放的用例。对于这种用例,250S+将高达4TB的NVMe存储直接带到FPGA可重构结构的边缘,在那里,交易记录被高速收集到SSD上,准备重播14。
NVMe还减轻了虚拟化基础架构的挑战,并简化了虚拟机(Virtual Machines)、无状态虚拟机和SRIOV的实施,其中IO是最常见的瓶颈。在无状态虚拟机用例中,IT经理需要锁定企业用户不修改的操作系统镜像。用户只修改自己的数据,操作系统镜像在NVMe存储中保持不变,用户之间的隐私和安全至关重要。对于这样的IT基础架构,NVMe存储是多用户共享的。250S+是实现这一应用的一体化平台。每个1TB的物理硬盘都被FPGA IP分割,因此每个用户都能隔离并安全地访问其操作系统镜像和数据。管理程序管理对硬盘的直接访问,而不需要仿真驱动,这为这种IO绑定的应用提供了更好的性能。
”大数据“市场也为将存储和处理结合起来的智能NVMe产品带来了机会,因为它正在从批处理方法转向实时处理方法。地图缩减问题正朝着实时分析而不是批处理的方向发展,因此,它们需要一种新的存储层,这种存储层的速度要比GFS后端快得多。现在在IT基础设施中看到的存储分层将很少访问和低速的冷存储,分离到非常快的SSD、NVMe或NVM存储器中。在这种用例中,所有的数据都会被记录在GDFS中,但随后会被移动到具有更快内存的计算节点上。实现NVMe-over-Fabric的250-SoC满足了这两个要求,因为它可以访问高速存储和高性能计算能力。
深度学习行业与分析界有类似的需求。深度学习的新一代加速器,即GPGPU、TPU和FPGA;这些设备需要大的内存带宽来匹配芯片的计算能力。训练操作会消耗大量的这种高通量数据,通常是多TB的数据15。最近的研究工作表明,FPGA结构可以加速某些网络类型的训练操作。因此,将存储和计算引擎结合到一个硬件平台上可以减少延迟,随着训练数据集的增加,允许更多的再训练周期16。
在HPC领域,250S+的本地存储和250-SoC的远程版本有一些应用,如检查点/重启、突发缓冲区、分布式文件系统或从调度器缓存作业数据。通过在FPGA结构上靠近存储的地方运行算法,FPGA应用的占用率仍然很低,同时充分利用存储,并将CPU腾出来用于其他处理作业。而不是简单地存储数据或使用主机CPU对内存数据库进行压缩或加密,其中千兆字节的数据保存在易失性存储器中,但需要定期备份到闪存中。基于FPGA的系统可以处理这些数据的快照,以便永久存储到基于NVMe的大型存储阵列中。对于这种类型的操作,MPSoC特别适合对用户数据进行更复杂的操作。
最后,在物联网领域,需要在物联网网关上进行数据过滤和预处理,在物联网网关上进行数据的聚合以及接收到数据后的加密,FPGA通过加密或压缩等位运算实时处理数据流,并使用250S+将数据在板上存储走,或使用有线250S+或250-SoC将数据以输入带宽传递到存储背板。从区块链计算来看,FPGA也是首选平台。区块链技术为物联网网关带来了差异化,提供一种自适应和安全的方法来维护物联网设备的用户隐私偏好17。
BittWare的能力
二十多年来,BittWare帮助行业专家在其基础架构中引入FPGA来设计、开发和优化工作负载。在此期间,BittWare的计算和网络解决方案为各个行业的客户提供了竞争优势,包括HPC、金融、基因组学和嵌入式计算。BittWare结合了硬件、软件和系统设计的专业知识,指导客户在其产品中最大限度地发挥FPGA技术的优势。
在250加速器系列中,BittWare选择了多种Xilinx UltraScale+器件和PCIe外形,为存储基础设施架构师提供完整的解决方案。这些加速器将Xilinx器件的可编程逻辑直接连接到基础架构网络中,并通过上一代100GbE和PCIe 3.0高速接口连接PCIe结构。此外,利用BittWare母公司Molex的能力,250系列提供了连接现有硬件的高灵活性。Molex是超高速低损耗电缆和互连解决方案的行业领导者。
结论
NVMe已经并仍在快速地改变着存储行业。这种全新的高吞吐量存储技术为IT基础设施提供了灵活的存储解决方案。与上一代存储相比,NVMe不仅提供了卓越的数据写入和读取带宽,还充分利用了现有数据中心的PCIe和网络结构。随着NVMe的普及,业界创新者纷纷推出支持NVMe的新产品。所有的基础数据中心设备都在更新,以支持NVMe;NVMe存储背板已经成为新的标准。
基于FPGA的NVMe产品,让计算与存储在硬件层面融合,达到更高的应用性能。通过FPGA,可重构逻辑的处理通过高吞吐量和低延迟的管道直接连接到存储上。由于这些特点,数据可以流经FPGA并进行实时处理。此外,通过使用FPGA处理,CPU核可以自由地执行其他只能在处理器上运行的任务。使用MPSoC,系统可以获得更多的功能,并将高速数据处理和设备上的控制结合起来,有可能自主运行。
BittWare基于FPGA和MPSoC的存储产品旨在满足实际应用的需求,并解决IT基础架构管理人员的挑战。BittWare通过250产品系列提供了一条生产路径。
审核编辑:郭婷
-
Microchip推出Adaptec® SmartRAID 4300 系列加速器 提供安全的可扩展 NVMe® RAID 存储解决方案2025-08-06 19146
-
NVMe over Fabrics 国产 IP:高性能网络存储解决方案2025-12-12 1456
-
机器学习实战:GNN加速器的FPGA解决方案2020-10-20 2007
-
如何用MRAM和NVMe SSD构建未来的云存储的解决方案2021-01-11 1899
-
业内最强的FPGA图像加速解决方案2019-06-18 2056
-
HighPoint NVMe存储解决方案SSD 6540M扩展了其外部NVMe产品线2019-11-21 1617
-
LightOS成为了首款NVMe/TCP群集存储解决方案2019-12-19 5371
-
西部数据新款数据存储解决方案助力企业实现到NVMe的过渡2020-07-07 3755
-
全新NVMe存储解决方案的优势及应用2022-06-02 2986
-
利用BittWare FPGA解决方案构建NVMe Over Fabrics2022-08-02 3436
-
在ZCU102评估套件上实现NVMe SSD接口的解决方案2022-11-28 4102
-
【虹科方案】西部数据超低延迟NVMe存储解决方案2022-05-31 1574
-
FPGA加速视觉搜索引擎解决方案2023-09-13 642
-
NVMe Host Controller IP实现高性能存储解决方案2024-02-21 916
-
HighPoint与 ICY DOCK 达成合作,为专业计算提供高速灵活的 NVMe 存储扩展解决方案2025-11-21 2390
全部0条评论

快来发表一下你的评论吧 !
