

如何在 MCU 上实现 DS-CNN KWS
控制/MCU
描述
使用一类新兴的高效算法,任何开发人员现在都可以在低功耗、资源受限的系统上部署复杂的关键字识别功能。这个由两部分组成的系列的第一部分展示了如何使用 FPGA 来做到这一点。在第二部分中,我们将展示如何使用 MCU 来做到这一点。
关键字发现 (KWS) 技术已成为可穿戴设备、物联网设备和其他智能产品越来越重要的功能。机器学习方法可以提供卓越的 KWS 准确性,但这些产品的功能和性能限制直到最近限制了大型企业或经验丰富的机器学习专家对机器学习 KWS 解决方案的使用。
然而,开发人员越来越需要在可穿戴设备和其他物联网设备中在能够在这些设备的资源限制内运行的更高效的 KWS 引擎上实现语音激活的 KWS 功能。深度可分离卷积神经网络 (DS-CNN) 架构修改了传统的 CNN 以提供所需的效率。
使用硬件优化的神经网络库,开发人员可以实现需要最少资源的基于 MCU 的 DS-CNN 推理引擎。本文描述了 DS-CNN 架构,并展示了开发人员如何在 MCU 上实现 DS-CNN KWS。
为什么选择 KWS?
消费者对使用“Alexa”、“Hey Siri”或“Ok Google”等短语的智能手机和家用电器上的语音激活功能的接受度已迅速演变为对几乎所有为用户交互而设计的产品的语音服务的广泛需求。在这些服务的基础上,准确的语音识别依赖于各种人工智能方法来识别口语单词,并将单词和词组解释为适合应用程序的命令。
然而,快速准确地完成整个语音命令序列所需的资源开始超过低成本线路供电消费集线器的能力,更不用说电池供电的个人电子产品了。
语音命令管道要求
为了在这些产品上提供语音激活,开发人员将语音命令管道拆分或将语音命令限制为几个非常简单的词,例如“开”和“关”。在资源有限的消费产品上,开发人员使用神经网络推理引擎实现 KWS 功能,该引擎能够为 Alexa、Siri 或 Google 的简单命令或命令激活短语提供所需的高精度、低延迟响应(图 1)。
在这里,设计将输入音频流数字化,提取语音特征,并将这些特征传递给神经网络以识别关键字。
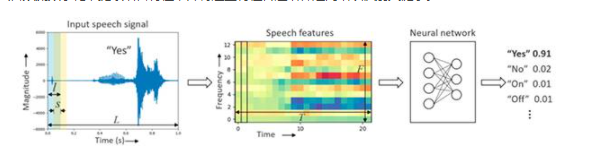
图 1:使用 KWS 进行语音激活使用处理管道从音频输入信号中提取频域特征,并对提取的特征进行分类,以预测输入信号对应于用于训练神经网络的标签之一的概率。(图片来源:Arm®)
通过将幅度调制的音频输入流转换为频谱图中的特征,开发人员可以利用卷积神经网络 (CNN) 模型经过验证的能力,根据神经网络训练期间使用的标签之一对口语进行准确分类。2对于更复杂的语音接口,命令处理管道超出了设备本身。在 KWS 推理引擎检测到激活关键字或短语后,产品将数字化的音频流传递给基于云的服务,能够更有效地处理复杂的语音处理和命令识别操作。
尽管如此,设备资源可用性和推理引擎资源需求之间的冲突仍使开发人员试图将这些方法应用于更小的可穿戴设备和物联网设备设计的尝试。尽管经典的 CNN 相对容易理解且易于训练,但这些模型仍然可能是资源密集型的。随着 CNN 模型在识别图像方面的准确度大幅提高,CNN 的大小和复杂度也显着增加。
结果是非常精确的 CNN 模型,需要数十亿计算密集型通用矩阵乘法 (GEMM) 操作进行训练。一旦经过训练,相应的推理模型可能会占用数百兆内存,并且需要非常大量的 GEMM 操作才能进行单个推理。
对于电池供电的可穿戴设备和物联网设备,有效的 KWS 推理模型必须能够在有限的内存中运行且处理要求低。此外,由于 KWS 推理引擎必须在“始终开启”模式下运行才能执行其功能,因此它必须能够以最低功耗运行。
在越来越有吸引力的可穿戴设备和物联网设备领域,神经网络的潜力与有限资源之间的这种二分法引起了机器学习专家的极大关注。结果是开发了优化基本 CNN 模型的技术,并出现了替代神经网络架构,能够弥合小型资源受限设备的性能要求和资源能力之间的差距。
小尺寸型号
在创建小型模型的技术中,机器学习专家已经应用了网络修剪和参数量化等优化方法来生成 CNN 变体,这些变体能够提供几乎与完整 CNN 一样准确的结果,但只使用了一小部分资源。这些降低精度的神经网络的成功为二值化神经网络 (BNN) 架构铺平了道路,该架构将模型参数从 32 位浮点数,甚至早期 CNN 中的 16 位和 8 位浮点数减少到 1 位价值观。如第 1 部分所述,Lattice Semiconductor机器学习SensAI™平台使用这种高效的 BNN 架构作为 1 毫瓦 (mW) KWS 解决方案的基础,该解决方案在其基于 FPGA 的iCE40 UltraPlus移动开发平台,或 MDP。
除了网络修剪和参数量化等简化技术外,还有其他降低资源需求的方法可以修改 CNN 架构本身的拓扑结构。在这些替代架构中,深度可分离卷积神经网络提供了一种特别有效的方法来创建能够在通用 MCU 上运行的小型、资源高效模型。
在早期工作的基础上,谷歌机器学习专家找到了一种通过关注卷积层本身来提高 CNN 效率的方法。在传统的 CNN 中,每个卷积层过滤输入特征并在一个步骤中将它们组合成一组新的特征(图 2,顶部)。
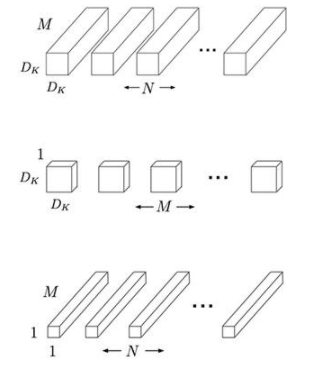
图 2:与全卷积(上)不同,深度可分离卷积首先使用 D K xD K滤波器(中)分别过滤 M 个输入通道中的每一个,并使用逐点 1 x 1 卷积来创建 N 个新特征。(图片来源:谷歌)
新方法将过滤和特征生成分为两个独立的阶段,统称为深度可分离卷积。第一阶段执行深度卷积,该卷积在输入的每个通道上充当空间滤波器(图 2,中间)。因为第一阶段不创建新特征(深度神经网络架构的核心目标),所以第二阶段执行逐点 1 x 1 卷积(图 2,底部),它结合第一阶段的输出以生成新特征。
这种 DS-CNN 架构在用于移动和嵌入式视觉应用的 Google MobileNet 模型中使用,减少了参数和相关操作的数量,从而产生更小的模型,需要显着更少的计算来获得准确的结果。3
与全卷积相比,在 MobileNet 模型中使用深度可分离卷积在行业标准 ImageNet 数据集上仅降低了 1% 的准确度,但使用了不到 12% 的乘加运算和所需的模型参数数量的 14%用于传统 ImageNet CNN 模型中的全卷积。
尽管 DS-CNN 最初是为图像识别而开发的,但这些相同的模型可以通过将音频输入流转换为频谱图来提供一组可用的特征来提供音频识别。实际上,音频前端将音频流转换为 DS-CNN 可以分类的一组特征。对于语音处理,前端产生的特征通常采用梅尔频率倒谱系数(MFCC)的形式,它更接近人类的听觉特征,同时显着降低了传递给 DS-CNN 分类器的特征集的维数。这正是 ARM ML-KWS-for-MCU开源软件存储库中使用的方法。
DS-CNN 实现
ARM KWS 存储库旨在演示在 Arm Cortex ® -M 系列 MCU 上的 KWS 实施,在包括传统 CNN、DS-CNN 等在内的多种架构中提供了大量预训练的 TensorFlow 模型。使用谷歌速度命令数据集4训练,模型将音频输入分类为 12 个可能的类别之一:“是”、“否”、“上”、“下”、“左”、“右”、“开”、“ Off”、“Stop”、“Go”、“silence”(不说话)和“unknown”(代表 Google 数据集中包含的其他词)。
开发人员可以立即使用这些预训练模型来比较这些替代神经网络架构的推理性能并检查它们的内部结构。例如,在 ARM 的预训练 DS-CNN 模型上运行 TensorFlow 的import_pb_to_tensorboard Python 实用程序后,开发人员可以使用 TensorBoard 可视化模型的基于 MobileNet 的架构。
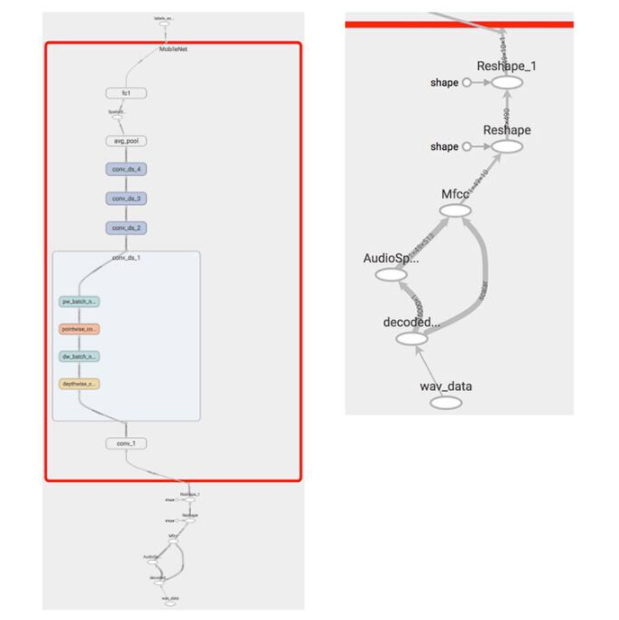
图 3:在 TensorBoard 中显示的 Arm 预训练 KWS 模型将熟悉的 MobileNet DS-CNN 模型(左红色轮廓)与使用梅尔频率倒谱系数 (MFCC) 的频域特征提取阶段(右扩展)相结合. (图片来源:Digi-Key Electronics)
正如在 TensorBoard 中所展示的那样,MobileNet 架构用深度可分离卷积替换了传统 CNN 架构中除第一个完整卷积层之外的所有卷积层。
如前所述,这些阶段中的每一个都包括深度卷积和点卷积阶段,每个阶段都输入一个 batchnorm 内核以对输出结果进行归一化(图 3,左)。DS-CNN 模型使用一个特殊的 TensorFlow 融合 batchnorm 函数,它将多个选项组合到一个内核中。
此外,通过放大音频输入特征提取阶段(图 3,右),开发人员可以检查音频处理序列,包括音频解码、频谱图生成和 MFCC 滤波。MFCC 生成的特征通过一对重塑阶段来创建 MobileNet 分类器所需的张量形状。
可以想象,开发人员可以在基于 MCU 的系统(包括Raspberry Pi )上运行来自 TensorFlow 或其他机器学习框架的训练模型。5使用这种方法,开发人员可以量化经过训练的模型,以生成能够在这些系统上运行的较小版本。但是,如果没有图形处理单元 (GPU) 或其他硬件支持 GEMM 加速,推理延迟可能会令用户对语音激活性能的预期失望。
ARM 通过其对 ARM Cortex 微控制器软件接口标准 (CMSIS) 的神经网络 (NN) 扩展提供了一种替代方法。CMSIS-NN 提供一整套 CNN 功能,充分利用 ARM Cortex-M7 处理器(例如STMicroelectronics 的 STM32F7 MCU 系列中的那些)中内置的 DSP 扩展。除了传统的 CNN 函数外,CMSIS-NN 应用程序编程接口 (API) 还支持深度可分离卷积,其中一对函数对应于 DS-CNN 架构下的深度和逐点 1 x 1 卷积阶段:
ARM_status ARM_depthwise_separable_conv_HWC_q7_nonsquare
ARM_status ARM_convolve_1x1_HWC_q7_fast_nonsquare
该 API 还在专门为方形输入张量设计的版本中提供了这两个函数。
ARM 在示例代码中使用这些函数,该示例代码演示了一个完整的基于 DS-CNN 的 KWS 应用程序,该应用程序在 STMicroelectronics STM32F746G-DISCO开发板上运行,该开发板围绕STM32F746NGH6 MCU 构建。在示例代码的核心,原生 CMSIS-NN C++ 模块实现了 CS-DNN(清单 1)。
void DS_CNN::run_nn(q7_t* in_data, q7_t* out_data)
{
//CONV1 : regular convolution
ARM_convolve_HWC_q7_basic_nonsquare(in_data, CONV1_IN_X, CONV1_IN_Y, 1, conv1_wt, CONV1_OUT_CH, CONV1_KX, CONV1_KY, CONV1_PX, CONV1_PY, CONV1_SX, CONV1_SY, conv1_bias, CONV1_BIAS_LSHIFT, CONV1_OUT_RSHIFT, buffer1, CONV1_OUT_X, CONV1_OUT_Y, (q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer1,CONV1_OUT_X*CONV1_OUT_Y*CONV1_OUT_CH);
// conv2:ds + pw conv // depthwise可分开的cons(批次范围折叠为conv wts/bias) arm_depthwise_separible_conv_hwc_hwc_hwc_hwc_q7_nonsquare(buffer1,conv2_in_in_x,conv2_in_y,conv2_in_y,
conv1_out_conve_c__cond_ss_s_ds_s_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_ds_d, conv2_ds_bias,CONV2_DS_BIAS_LSHIFT,CONV2_DS_OUT_RSHIFT,buffer2,CONV2_OUT_X,CONV2_OUT_Y,(q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer2,CONV2_OUT_X*CONV2_OUT_Y*CONV2_OUT_CH); // 逐点卷积 ARM_convolve_1x1_HWC_q7_fast_nonsquare(buffer2, CONV2_OUT_X, CONV2_OUT_Y, CONV1_OUT_CH, conv2_pw_wt, CONV2_OUT_CH, 1, 1, 0, 0, 1, 1, conv2_pw_bias, CONV2_PW_BIAS_LSHIFT,
CONV2_PW_OUT_RSHIFT, buffer1, CONV2_OUT_X, CONV2_bufferY, (NULL), CONV2_buff_Y, (NULL)_ ARM_relu_q7(buffer1,CONV2_OUT_X*CONV2_OUT_Y*CONV2_OUT_CH);
//CONV3 : DS + PW conv
//Depthwise separable conv (batch norm params folded into conv wts/bias)
ARM_depthwise_separable_conv_HWC_q7_nonsquare(buffer1,CONV3_IN_X,CONV3_IN_Y,CONV2_OUT_CH,conv3_ds_wt,CONV2_OUT_CH,CONV3_DS_KX,CONV3_DS_KY,CONV3_DS_PX,CONV3_DS_PY,CONV3_DS_SX,CONV3_DS_SY,conv3_ds_bias,CONV3_DS_BIAS_LSHIFT,CONV3_DS_OUT_RSHIFT,buffer2,CONV3_OUT_X,CONV3_OUT_Y,(q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer2,CONV3_OUT_X*CONV3_OUT_Y*CONV3_OUT_CH);
//Pointwise conv
ARM_convolve_1x1_HWC_q7_fast_nonsquare(buffer2, CONV3_OUT_X, CONV3_OUT_Y, CONV2_OUT_CH, conv3_pw_wt, CONV3_OUT_CH, 1, 1, 0, 0, 1, 1, conv3_pw_bias, CONV3_PW_BIAS_LSHIFT, CONV3_PW_OUT_RSHIFT, buffer1, CONV3_OUT_X, CONV3_OUT_Y, (q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer1,CONV3_OUT_X*CONV3_OUT_Y*CONV3_OUT_CH);
//CONV4 : DS + PW conv
//Depthwise separable conv (batch norm params folded into conv wts/bias)
ARM_depthwise_separable_conv_HWC_q7_nonsquare(buffer1,CONV4_IN_X,CONV4_IN_Y,CONV3_OUT_CH,conv4_ds_wt,CONV3_OUT_CH,CONV4_DS_KX,CONV4_DS_KY,CONV4_DS_PX,CONV4_DS_PY,CONV4_DS_SX,CONV4_DS_SY,conv4_ds_bias,CONV4_DS_BIAS_LSHIFT,CONV4_DS_OUT_RSHIFT,buffer2,CONV4_OUT_X,CONV4_OUT_Y,(q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer2,CONV4_OUT_X*CONV4_OUT_Y*CONV4_OUT_CH);
//Pointwise conv
ARM_convolve_1x1_HWC_q7_fast_nonsquare(buffer2, CONV4_OUT_X, CONV4_OUT_Y, CONV3_OUT_CH, conv4_pw_wt, CONV4_OUT_CH, 1, 1, 0, 0, 1, 1, conv4_pw_bias, CONV4_PW_BIAS_LSHIFT, CONV4_PW_OUT_RSHIFT, buffer1, CONV4_OUT_X, CONV4_OUT_Y, (q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer1,CONV4_OUT_X*CONV4_OUT_Y*CONV4_OUT_CH);
//CONV5 : DS + PW conv
//Depthwise separable conv (batch norm params folded into conv wts/bias)
ARM_depthwise_separable_conv_HWC_q7_nonsquare(buffer1,CONV5_IN_X,CONV5_IN_Y,CONV4_OUT_CH,conv5_ds_wt,CONV4_OUT_CH,CONV5_DS_KX,CONV5_DS_KY,CONV5_DS_PX,CONV5_DS_PY,CONV5_DS_SX,CONV5_DS_SY,conv5_ds_bias,CONV5_DS_BIAS_LSHIFT,CONV5_DS_OUT_RSHIFT,buffer2,CONV5_OUT_X,CONV5_OUT_Y,(q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer2,CONV5_OUT_X*CONV5_OUT_Y*CONV5_OUT_CH);
//Pointwise conv
ARM_convolve_1x1_HWC_q7_fast_nonsquare(buffer2, CONV5_OUT_X, CONV5_OUT_Y, CONV4_OUT_CH, conv5_pw_wt, CONV5_OUT_CH, 1, 1, 0, 0, 1, 1, conv5_pw_bias, CONV5_PW_BIAS_LSHIFT, CONV5_PW_OUT_RSHIFT, buffer1, CONV5_OUT_X, CONV5_OUT_Y, (q15_t*)col_buffer, NULL);
ARM_relu_q7(buffer1,CONV5_OUT_X*CONV5_OUT_Y*CONV5_OUT_CH);
//Average pool
ARM_avepool_q7_HWC_nonsquare (buffer1,CONV5_OUT_X,CONV5_OUT_Y,CONV5_OUT_CH,CONV5_OUT_X,CONV5_OUT_Y,0,0,1,1,1,1,NULL,buffer2, 2);
ARM_fully_connected_q7(buffer2, final_fc_wt, CONV5_OUT_CH, OUT_DIM, FINAL_FC_BIAS_LSHIFT, FINAL_FC_OUT_RSHIFT, final_fc_bias, out_data, (q15_t*)col_buffer);
}
清单 1:ARM ML-KWS-for-MCU 软件存储库包含一个 C++ DS-CNN 模型,其中一个完整的卷积层后跟几个深度可分离卷积(框),每个都使用深度卷积和 1 x 1 卷积函数(黄色突出显示)在硬件优化的 ARM CMSIS-NN 软件库中支持。(代码来源:ARM)
尽管 C++ DS-CNN 实现与前面展示的 TensorBoard DS-CNN 模型略有不同,但总体方法保持不变。在初始全卷积核之后,一系列深度可分离卷积核输入最终池化层和全连接层,以生成每个输出通道的预测值(对应于用于训练模型的 12 个类标签)。
KWS 应用程序将此模型与代码相结合,以提供对 STM32F746G-DISCO 开发板收集的实时音频流的推断。在这里,主函数初始化推理引擎,启用音频采样,然后进入由单个等待中断 (WFI) 调用组成的无限循环(清单 2)。
char output_class[12][8] = {“Silence”, “Unknown”,“yes”,“no”,“up”,“down”,
“left”,“right”,“on”,“off”,“stop”,“go”};
int main()
{
pc.baud(9600);
kws = new KWS_F746NG(recording_win,averaging_window_len);
init_plot();
kws-》start_kws();
T.start();
while (1) {
/* A dummy loop to wait for the interrupts. Feature extraction and
neural network inference are done in the interrupt service routine. */
__WFI();
}
}
/*
* The audio recording works with two ping-pong buffers.
* The data for each window will be tranfered by the DMA, which sends
* sends an interrupt after the transfer is completed.
*/
// Manages the DMA Transfer complete interrupt.
void BSP_AUDIO_IN_TransferComplete_CallBack(void)
{
ARM_copy_q7((q7_t *)kws-》audio_buffer_in + kws-》audio_block_size*4, (q7_t *)kws-》audio_buffer_out + kws-》audio_block_size*4, kws-》audio_block_size*4);
if(kws-》frame_len != kws-》frame_shift) {
//copy the last (frame_len - frame_shift) audio data to the start
ARM_copy_q7((q7_t *)(kws-》audio_buffer)+2*(kws-》audio_buffer_size-(kws-》frame_len-kws-》frame_shift)), (q7_t *)kws-》audio_buffer, 2*(kws-》frame_len-kws-》frame_shift));
}
// copy the new recording data
for (int i=0;i《kws-》audio_block_size;i++) {
kws-》audio_buffer[kws-》frame_len-kws-》frame_shift+i] = kws-》audio_buffer_in[2*kws-》audio_block_size+i*2];
}
run_kws();
return;
}
// Manages the DMA Half Transfer complete interrupt.
void BSP_AUDIO_IN_HalfTransfer_CallBack(void)
{
ARM_copy_q7((q7_t *)kws-》audio_buffer_in, (q7_t *)kws-》audio_buffer_out, kws-》audio_block_size*4);
if(kws-》frame_len!=kws-》frame_shift) {
//copy the last (frame_len - frame_shift) audio data to the start
ARM_copy_q7((q7_t *)(kws-》audio_buffer)+2*(kws-》audio_buffer_size-(kws-》frame_len-kws-》frame_shift)), (q7_t *)kws-》audio_buffer, 2*(kws-》frame_len-kws-》frame_shift));
}
// copy the new recording data
for (int i=0;i《kws-》audio_block_size;i++) {
kws-》audio_buffer[kws-》frame_len-kws-》frame_shift+i] = kws-》audio_buffer_in[i*2];
}
run_kws();
return;
}
void run_kws()
{
kws-》extract_features(); //extract mfcc features
kws-》classify(); //classify using dnn
kws-》average_predictions();
plot_mfcc();
plot_waveform();
int max_ind = kws-》get_top_class(kws-》averaged_output);
if(kws-》averaged_output[max_ind]》detection_threshold*128/100)
sprintf(lcd_output_string,“%d%% %s”,((int)kws-》averaged_output[max_ind]*100/128),output_class[max_ind]);
lcd.ClearStringLine(8);
lcd.DisplayStringAt(0, LINE(8), (uint8_t *) lcd_output_string, CENTER_MODE);
}
清单 2:在 ARM ML-KWS-for-MCU 软件存储库中,DS-CNN KWS 应用程序的主例程(通过KWS_F746NG)实例化推理引擎,激活 STM32F746G-DISCO 开发板的音频子系统,并进入无限循环,等待中断调用执行推理的完成例程 ( run_kws())。(代码来源:ARM)
包含在此main例程中的回调函数提供完成例程,这些例程缓冲记录的数据并通过调用run_kws(). 该run_kws函数调用对推理引擎实例的调用以提取特征、对结果进行分类并提供预测,以指示记录的音频样本属于如前所述的原始训练中使用的 12 个类之一的概率。
推理引擎本身是通过一系列调用实例化的,从main实例化KWS_F746NG类的调用开始,该类本身是类的子KWS_DS_NN类。后一个类使用父类封装了前面显示的 C++ DS-CNN 模型,该类KWS实现了特定的推理引擎方法:extract_features()、classify()等(清单 3)。
#include “kws.h”
KWS::KWS()
{
}
KWS::~KWS()
{
delete mfcc;
delete mfcc_buffer;
delete output;
delete predictions;
delete averaged_output;
}
void KWS::init_kws()
{
num_mfcc_features = nn-》get_num_mfcc_features();
num_frames = nn-》get_num_frames();
frame_len = nn-》get_frame_len();
frame_shift = nn-》get_frame_shift();
int mfcc_dec_bits = nn-》get_in_dec_bits();
num_out_classes = nn-》get_num_out_classes();
mfcc = new MFCC(num_mfcc_features, frame_len, mfcc_dec_bits);
mfcc_buffer = new q7_t[num_frames*num_mfcc_features];
output = new q7_t[num_out_classes];
averaged_output = new q7_t[num_out_classes];
predictions = new q7_t[sliding_window_len*num_out_classes];
audio_block_size = recording_win*frame_shift;
audio_buffer_size = audio_block_size + frame_len - frame_shift;
}
void KWS::extract_features()
{
if(num_frames》recording_win) {
//move old features left
memmove(mfcc_buffer,mfcc_buffer+(recording_win*num_mfcc_features),(num_frames-recording_win)*num_mfcc_features);
}
//compute features only for the newly recorded audio
int32_t mfcc_buffer_head = (num_frames-recording_win)*num_mfcc_features;
for (uint16_t f = 0; f 《 recording_win; f++) {
mfcc-》mfcc_compute(audio_buffer+(f*frame_shift),&mfcc_buffer[mfcc_buffer_head]);
mfcc_buffer_head += num_mfcc_features;
}
}
void KWS::classify()
{
nn-》run_nn(mfcc_buffer, output);
// Softmax
ARM_softmax_q7(output,num_out_classes,output);
}
int KWS::get_top_class(q7_t* prediction)
{
int max_ind=0;
int max_val=-128;
for(int i=0;i《num_out_classes;i++) {
if(max_val《prediction[i]) {
max_val = prediction[i];
max_ind = i;
}
}
return max_ind;
}
void KWS::average_predictions()
{
//shift right old predictions
ARM_copy_q7((q7_t *)predictions, (q7_t *)(predictions+num_out_classes), (sliding_window_len-1)*num_out_classes);
//add new predictions
ARM_copy_q7((q7_t *)output, (q7_t *)predictions, num_out_classes);
//compute averages
int sum;
for(int j=0;j《num_out_classes;j++) {
sum=0;
for(int i=0;i《sliding_window_len;i++)
sum += predictions[i*num_out_classes+j];
averaged_output[j] = (q7_t)(sum/sliding_window_len);
}
}
清单 3:在 ARM DS-CNN KWS 应用程序中,KWS 模块在基本 DS-CNN 类上添加了执行推理操作所需的方法,包括特征提取、分类和生成由平均窗口平滑的结果。(代码来源:ARM)
所有这些软件复杂性都隐藏在一个简单的使用模型后面,其中主程序通过实例化推理引擎来启动该过程,并在音频输入可用时使用其完成程序执行推理。据 ARM 称,在 STM32F746G-DISCO 开发板上运行的这个示例 CMSIS-NN 实现只需要大约 12 毫秒 (ms) 即可完成一个推理周期,其中包括音频数据缓冲区复制、特征提取和 DS-CNN 模型执行。同样重要的是,完整的 KWS 应用程序只需要大约 70 KB 的内存。
结论
随着 KWS 功能作为一项要求变得越来越重要,资源有限的可穿戴设备和其他物联网设计的开发人员需要占用空间小的推理引擎。ARM CMSIS-NN 旨在利用 ARM Cortex-M7 MCU 中的 DSP 功能,为实现优化的神经网络架构(如 DS-CNN)奠定了基础,能够满足这些要求。
在基于 ARM Cortex-M7 MCU 的开发系统上运行的 KWS 推理引擎可以在资源有限的物联网设备轻松支持的内存占用中实现接近 10 次推理/秒的性能。
-
如何在 S32DS 上实现 CMSIS-DSP ?2026-05-21 379
-
【米尔全志T153开发板评测】kws语音关键字识别测试2026-03-18 2335
-
如何在雅特力AT32 MCU上实现关键词语音识别(KWS)2024-01-06 2620
-
AT32上实现关键词语音识别(KWS)2023-10-26 624
-
如何在AT32 MCU上使用FPU功能2023-10-24 727
-
如何将DS_CNN_S.pb转换为ds_cnn_s.tflite?2023-04-19 597
-
如何在 MCU 上快速部署 TinyML2022-07-19 3107
-
语音识别_ML-KWS-for-MCU_资料大合集2022-02-08 1263
-
如何在嵌入式平台实现CNN2021-12-09 2266
-
语音识别_ML-KWS-for-MCU_资料整理2021-12-05 1037
-
可分离卷积神经网络在 Cortex-M 处理器上实现关键词识别2021-07-26 3843
-
通过FPGA实现深度神经网络的解决方案2019-03-19 13242
-
TF之CNN:CNN实现mnist数据集预测2018-12-19 3139
全部0条评论

快来发表一下你的评论吧 !
