

基于FPGA的CNN加速项目案例解析
可编程逻辑
描述
人工智能(AI)长期以来一直是科幻作家和学者的主题。将人脑的复杂性复制到计算机中的挑战催生了新一代的科学家、数学家和计算机算法开发人员。持续的研究现在已经让位于人工智能的使用,通常被称为深度学习或机器学习,这些应用正越来越成为我们世界的一部分。虽然基本概念已经存在很长时间,但商业现实从未完全实现。近年来,数据的生成速度飞速发展,开发人员不得不长时间思考如何编写算法来从中提取有价值的数据和统计数据。还,另一个关键因素是高度可扩展级别的计算资源的可用性,这是云自愿提供的。例如,您口袋里的智能手机可能会使用 Google 的 Now(“OK Google”)或 Apple 的 Siri 语音命令应用程序,这些应用程序使用深度学习算法(称为(人工)神经网络)的强大功能来实现语音识别和学习能力。然而,除了与手机通话的乐趣和便利之外,还有大量工业、汽车和商业应用程序现在受益于深度学习神经网络的强大功能。称为(人工)神经网络,以实现语音识别和学习能力。然而,除了与手机通话的乐趣和便利之外,还有大量工业、汽车和商业应用程序现在受益于深度学习神经网络的强大功能。称为(人工)神经网络,以实现语音识别和学习能力。然而,除了与手机通话的乐趣和便利之外,还有大量工业、汽车和商业应用程序现在受益于深度学习神经网络的强大功能。
卷积神经网络
在查看其中一些应用程序之前,让我们先研究一下神经网络的工作原理以及它需要哪些资源。当我们一般谈论神经网络时,我们应该更准确地将它们描述为人工神经网络。作为软件算法实现,它们基于人类和动物的生物神经网络——中枢神经系统。多年来,人们构想了几种不同类型的神经网络架构,其中卷积神经网络 (CNN) 得到了最广泛的采用。造成这种情况的主要原因之一是他们的架构方法使它们非常适合使用基于 GPU 和 FPGA 设备的硬件加速器提供的并行化技术。CNN 受欢迎的另一个原因是它们适合处理具有大量空间连续性的数据,其中图像处理应用程序非常适合。空间连续性是指特定位置附近的像素共享相似的强度和颜色属性。CNN 由不同的层构成,每个层都有特定的目的,并且在它们的操作中使用了两个不同的阶段。第一部分是指令或训练阶段,它允许处理算法了解它拥有哪些数据以及每条数据之间的关系或上下文。CNN 是作为结构化和非结构化数据的学习框架创建的,计算机创建的神经元形成连接和中断网络。模式匹配是 CNN 背后的一个关键概念,
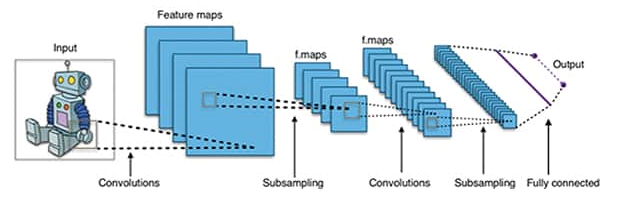
图 1:CNN 的层方法(来源:Wikipedia – credit Aphex34 1)。
更多关于 CNN 工作原理的信息可以在Cadence 1a的一篇论文中找到,以及一个有用的视频1b,该视频录制在最近的 IEEE 协会关于计算新前沿的会议上。当Microsoft 研究团队1c赢得 ImageNet 计算机视觉挑战时,CNN 对图像处理应用程序的有用性的证据获得了进一步的尊重。
CNN 的第二阶段是执行阶段。由不同的层节点组成,关于什么可能的图像可能变得越来越抽象的命题。卷积层从图像源中提取低级特征,以检测图像中的线条或边缘等特征。其他层,称为池化层,用于通过平均或“池化”图像特定区域的共同特征来减少变化。然后可以将其传递给进一步的卷积和池化层。CNN 层的数量与图像识别的准确性相关,尽管这增加了系统性能需求。如果内存带宽可用,这些层可以以并行方式运行,CNN 中计算最密集的部分是卷积层。
开发人员面临的挑战是他们如何提供足够高的计算资源来运行 CNN,以确定在应用程序的时间限制内所需的不同图像分类的数量。例如,工业自动化应用程序可能会使用计算机视觉来识别需要将零件传送到传送带上的下一个阶段。在神经网络识别出零件之前暂停该过程会破坏流程并减慢生产速度。
实现 CNN
加速部分 CNN 正在进行的“强化”学习和执行阶段将显着加速这项主要是数学任务。凭借其高内存带宽和计算能力,GPU 和 FPGA 是这项工作的潜在候选者。具有任何冯诺依曼架构所表现出的缓存瓶颈的传统微处理器可以运行算法,但将层抽象任务移交给硬件加速器。虽然 GPU 和 FPGA 都提供了显着的并行处理能力,但 GPU 固定架构的性质意味着 FPGA 具有灵活且可动态重新配置的架构更适合 CNN 加速任务。使用非常精细的方法,本质上是在硬件中实现 CNN 算法,与 GPU 的软件衍生算法方法相比,FPGA 架构有助于将延迟保持在绝对最小值,并且更具确定性。FPGA 的另一个优点是能够在设备结构中“硬化”功能块,例如 DSP。这种方法进一步加强了网络的确定性。就资源使用而言,FPGA 非常高效,因此每个 CNN 层都可以在 FPGA 结构内构建,并且它自己的内存靠近它。
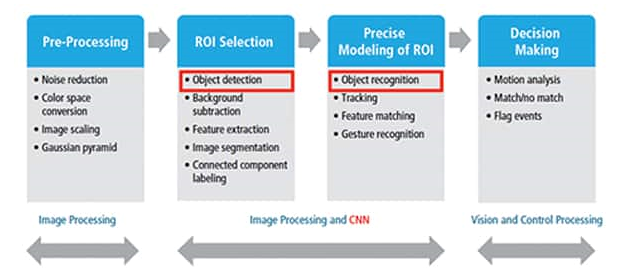
图 2:图像处理 CNN 概述(来源:Cadence 2)。
图 2 突出显示了为工业图像处理应用程序设计的 CNN 的关键组件块,中间的两个块代表 CNN 的核心。
使用 C 语言的OpenCL 2a并行编程扩展来补充基于 FPGA 的 CNN 加速应用程序的开发。适用于卷积神经网络的 FPGA 器件的一个示例是英特尔可编程解决方案集团 (PSG)的Arria 10系列器件,其正式名称为Altera。
为了帮助开发人员开展基于 FPGA 的 CNN 加速项目,英特尔 PSG 提供了 CNN 参考设计。这使用 OpenCL 内核来实现每个 CNN 层。数据使用通道和管道从一层传递到下一层,该功能允许数据在 OpenCL 内核之间传递,而无需消耗外部内存带宽。卷积层是使用 FPGA 中的 DSP 模块和逻辑实现的。硬化块包括浮点功能,可进一步提高设备吞吐量,而不必影响可用内存带宽。
图 3 所示的框图突出显示了可以使用 FPGA 作为加速处理单元的示例图像处理和分类系统。
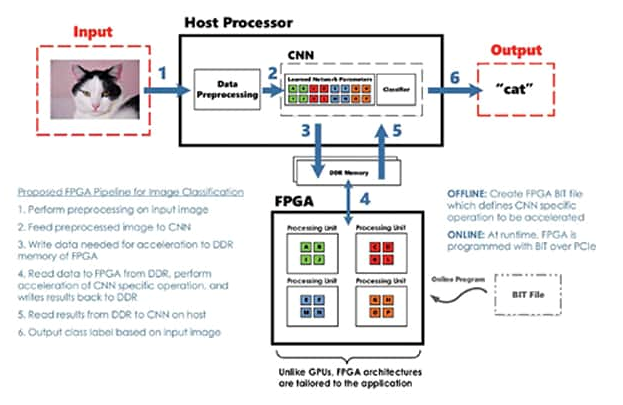
图 3:使用 FPGA 进行加速的图像分类系统框图(来源:FPGA 上的深度学习,过去、现在和未来3)。
英特尔 PSG 还在其网站4上提供了许多有关将 FPGA 卷积神经网络用于工业、医疗和汽车应用的主题的有用文档和视频。为深度学习应用程序选择框架是关键的第一步。为了帮助开发人员,有越来越多的工具,例如OpenANN (openann.github.io),这是一个用于人工神经网络的开源库,以及诸如deeplearning.net和Embedded-vision.com等信息丰富的社区站点。包括对使用 OpenCL 的支持的流行深度学习设计框架包括Caffe(caffe.berkeleyvision.org),基于 C++ 和基于 Lua 的 Torch。DeepCL 是另一个完全支持 OpenCL 的框架,尽管它尚未获得前两者的用户群。
结论
工业市场热衷于利用深度学习神经网络可以为许多制造和自动化控制应用带来的特性。由于德国的工业 4.0 等举措以及更广泛的工业物联网概念,这一重点得到了进一步的推动。与高质量的视觉相机、CPU 和 FPGA 解决方案以及相关控制相结合,卷积神经网络可用于自动执行大量制造过程检查,从而提高产品质量、可靠性和工厂安全性。
凭借其动态可配置的逻辑结构、高内存带宽和功率效率,FPGA 非常适合加速 CNN 的卷积层和池化层。在大量社区驱动的开源框架和并行代码库(如 OpenCL)的支持下,未来在此类应用中使用 FPGA 是安全的。FPGA 提供了一种高度可扩展和灵活的解决方案,可以满足许多工业部门的不同应用需求。
-
【PYNQ-Z2申请】图像目标识别FPGA硬件加速2019-01-09 5301
-
如何移植一个CNN神经网络到FPGA中?2020-11-26 5937
-
基于 FPGA 的目标检测网络加速电路设计2023-06-20 991
-
基于FPGA的通用CNN加速设计2017-10-27 10769
-
优化基于FPGA的深度卷积神经网络的加速器设计2017-11-17 8964
-
简单快捷地用小型Xiliinx FPGA加速卷积神经网络CNN2018-06-29 5525
-
KORTIQ公司推出了一款Xilinx FPGA的CNN加速器IP——AIScale2018-01-09 10819
-
Kortiq小巧高效的CNN加速器,支持所有类型2018-11-23 4030
-
想要实现FPGA的CNN加速 需要考虑以下内容2019-02-14 1665
-
电子学报第七期《一种可配置的CNN协加速器的FPGA实现方法》2021-11-18 1069
-
从C 到 matlab 到 FPGA,如何实现CNN的项目2022-03-15 3436
-
如何采用带专用CNN加速器的AI微控制器实现CNN的硬件转换2023-05-16 2459
-
基于FPGA的深度学习CNN加速器设计方案2023-06-14 3351
-
基于FPGA的CNN加速项目案例解析2023-08-25 1849
-
FPGA加速深度学习模型的案例2024-10-25 2314
全部0条评论

快来发表一下你的评论吧 !
