

缓存具体怎么分类呢
今日头条
描述
上次说到缓存的桌面必须要为整个内存的图书馆划定相应的空间存放对应的书本,而不是将这些从内存中取出来的数据随意地摆放在桌面上,经过规划后的缓存能够更快地找到CPU内核需要的数据。
首先,缓存是暂时存储CPU需要经常使用的数据。但CPU在运行过程中,执行的程序指令对于相应数据的指代都是以地址的形式,简而言之,CPU只认地址。那你缓存中暂存的数据你也得同时标明该数据对应的内存地址是多少。这样以后,CPU来找缓存要数据的时候,缓存才能通过对应的地址查找到CPU想要的数据。我们都知道一般的电脑地址是32或64位的,即地址线是32或64位。那好,如果我在一个32位计算机中知道一个32位的地址我就可以取出这个精确到1bit的数据。那么一般我们32位的CPU取一次数据也是32位,那么我们缓存中有必要为每个bit的数据都存一个32位的地址吗?肯定没必要,否则光是32位的地址就占用了整个缓存99%的空间。我们还用图书馆做比喻,上文讨论的问题的实质就是图书馆里的书要有多厚。一本书里就写一个字吗?还是一本书就是一个书架的内容?
如果一本书就一个字,那么还得是32个字作为地址,那还存啥数据,缓存的桌面只够存这些地址了。如果一本书就是一个书架呢?好家伙,原来需要32位的地址现在只要26位了(举例子),因为书少了,地址位数也少了,有效数据的比例增大了!但是能无限增大吗?肯定也不行,太大程序不一定有用到,还挤占别的程序的缓存空间。所以现在一般一本书即一个缓存行的大小是64字节,正好是DDR内存一次读取的数据量,这就很恰好。
中间插一句,缓存对于CPU和程序员是透明的,即CPU和程序员看不到缓存的存在,他们能看到的只有CPU自身的几个寄存器(指令集定义的)和内存,缓存的存储和读取行为是硬件自发的,CPU和程序员无法干涉(不排除一些奇葩硬件,比如某游戏机将缓存放到全局地址空间,可以经过游戏厂商特殊优化加快游戏速度。但这不是一个好办法,特殊优化费程序员,不如改善缓存让硬件更好地自行调度)。
综上,缓存中的空间必须要进行分类规划,不然缓存控制器找起数据来会很累。【假设数据随机摆放,那么需要使用CAM存储器同时对每个数据进行地址匹配,可想而知这需要许多比较器,才可以实现一个周期中完成匹配,并且电路面积和功耗感人(但不是没有这种缓存,存在即合理)。】那么具体怎么分类呢?现在储存在缓存行里的地址一共是26位(32位减去行内偏移6位),那么我们就要在这26位上做分类。
比如,可以和拥有五个窗口的某家KFC一样,尾数为0、1的去一号窗口取餐,2、3、4去二号,以此类推。缓存也是一样,尾数在缓存中体现为Index,缓存就依据此分组,Index的位数就取决于你有几个窗口即缓存容量有多大。那么假设缓存容量是64*64字节即64个缓存行的大小,那么Index就是log2(64)=6位数字。
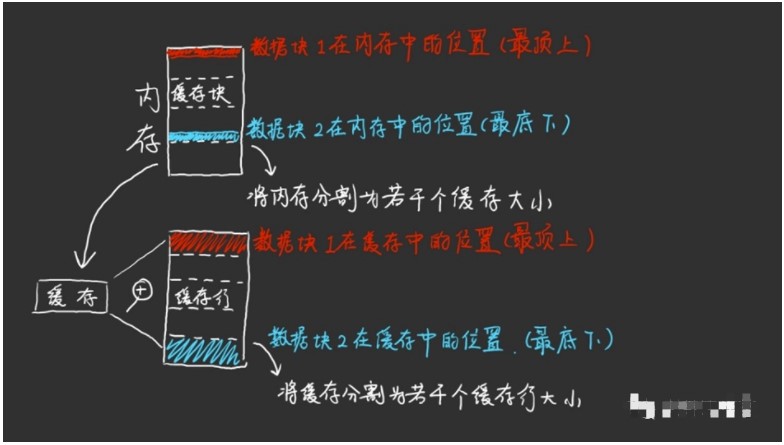
从内存到缓存的分类规则
那么如果CPU现在要某某地址的数据,缓存会将这个地址的Index截取下来在符合该分组的对应缓存行中查找,如果剩下的地址也对应上了,那么就是找到了,否则就往下一级缓存乃至内存中继续查找。这样就不需要非常多的比较器,电路的面积和功耗也就合理多了,缺点就是需要耗费两个时钟周期,先用MUX选取再比较。不过多周期任务可以用流水线来弥补功耗高的缺点。
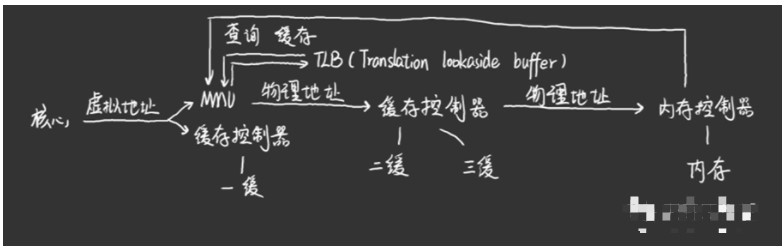
缓存到内存之间的控制关系(部分看不懂没关系)
那如果两个数据块都在同一个位置呢?比如最顶部?那么他们就会互相挤用缓存空间,造成乒乓效应。因此我们需要更高效的解决办法。
审核编辑:刘清
-
labview怎样清空输出板载缓存呢?2012-10-27 6744
-
请问各路大神,labview中这个缓存区的数字是变量,不知道具体个数,怎么才能拆出来所有的数值呢?2020-07-09 1841
-
汽车网络标准的具体分类有哪些?2021-05-18 2503
-
CH9141如何规避不需要的缓存数据?2022-07-28 1045
-
刻录机缓存容量多大才合适呢?2009-12-26 4558
-
Web代理服务器缓存优化2018-03-06 1241
-
渲染中的帧缓存和深度缓存2018-05-14 8627
-
什么是Web缓存,HTTP缓存和浏览器缓存的区别2019-09-13 11798
-
CPU缓存是什么意思_CPU缓存有什么作用2020-05-19 8808
-
缓存的基本原理 缓存的分类2020-06-13 5646
-
适用于命名数据网络的缓存内容分类模型2021-05-12 837
-
聊聊本地缓存和分布式缓存2023-06-11 1399
-
Socket缓存如何影响TCP的性能2023-11-09 1798
-
如何选择合适的本地缓存?2024-01-18 1836
-
HTTP缓存头的使用 本地缓存与远程缓存的区别2024-12-18 1298
全部0条评论

快来发表一下你的评论吧 !
