

利用视觉语言模型对检测器进行预训练
电子说
描述
本文简要介绍了发表于CVPR 2022的论文“Vision-Language Pre-Trainingfor Boosting Scene Text Detector”的相关工作。大规模预训练在视觉任务中有着重要的作用,而视觉语言模型与多模态的特征联合近期也收到了广泛的关注。本文针对场景文本检测的问题,提出了利用视觉语言模型对检测器进行预训练,通过设计Image-text Contrastive Learning、Masked LanguageModeling和Word-in-image Prediction三个预训练任务有效得结合文本、图像两个模态的特征,帮助主干网络提取到更丰富的视觉与语义特征,以此提高文本检测器的性能。该预训练方法可以有效提升各文本检测器在各大公开场景文本数据集上的评估结果。
一、研究背景
预训练通常被用于自然语言处理以及计算机视觉领域,以增强主干网络的特征提取能力,达到加速训练和提高模型泛化性能的目的。该方法亦可以用于场景文本检测当中,如最早的使用ImageNet预训练模型初始化参数,到使用合成数据直接预训练检测器再在真实数据上Finetune,再到通过定义一些预训练任务训练网络参数等。但这些方法都存在一些问题,比如中合成数据与真实数据的Domain Gap导致模型在真实场景下Finetune效果不佳,中没有充分利用视觉与文本之间的联系。基于这些观察,本文提出了一个通过视觉语言模型进行图像、文本两个模态特征对齐的预训练方法VLPT-STD,用于提升场景文本检测器的性能。
二、方法介绍
本文提出了一个全新的用于场景文本检测预训练的框架—VLPT-STD,它基于视觉语言模型设计,可以有效地利用文本、图像两种模态的特征,使得网络提取到更丰富的特征表达。其算法流程如图1所示,主要分为Image Encoder,Text Encoder以及Cross-model Encoder三个部分,并且设计了三个预训练任务让网络学习到跨模态的表达,提高网络的特征提取能力。
2.1 模型结构
Image Encoder用于提取场景文本图片的视觉特征编码,Text Encoder则提取图片中文本内容的编码,最后视觉特征编码和文本内容编码一起输入Cross-model Encoder当中进行多模态特征融合。
Image Encoder 包含了一个ResNet50-FPN的主干网络结构和一个注意力池化层。场景文本图像首先输入到ResNet50-FPN中得到特征,然后通过注意力池化层得到一个图像特征编码序列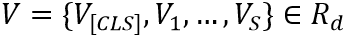 ,
,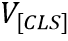 代表[CLS] Token的编码,S代表视觉Token的数量,d是维度。注意力池化层是一层Transformer中的多头注意力模块。
代表[CLS] Token的编码,S代表视觉Token的数量,d是维度。注意力池化层是一层Transformer中的多头注意力模块。
Text Encoder先将输入的文本转化成一个编码序列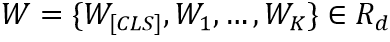 ,K代表序列长度,然后通过三层多头注意力模块得到文本特征编码。
,K代表序列长度,然后通过三层多头注意力模块得到文本特征编码。
Cross-model由四个相同的Transformer Decoder组成,它将视觉编码序列和文本编码序列W结合到了一起,并将其最后的输出用于预测Masked Language Modeling预训练任务。
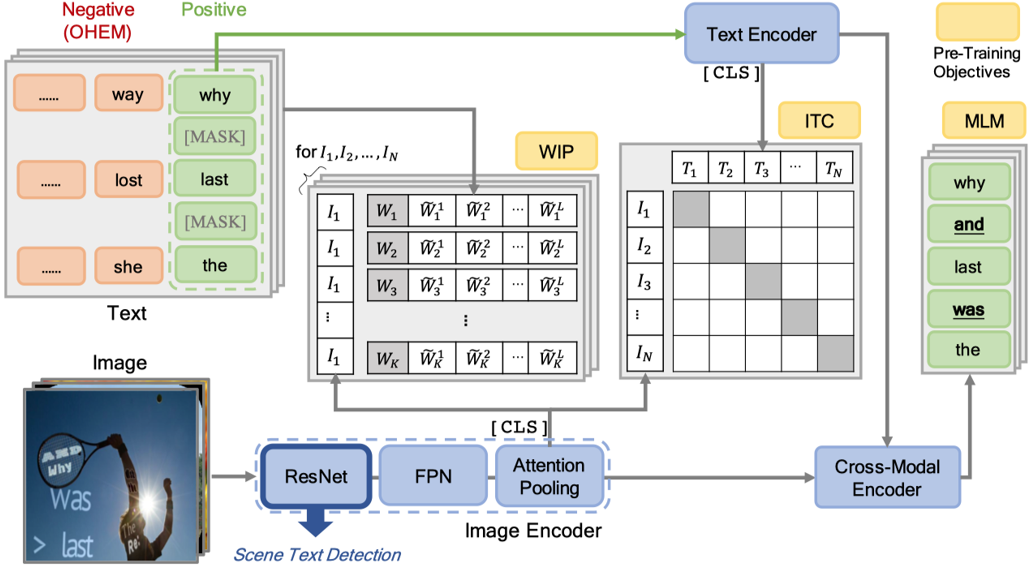
图1 VLPT-STD整体框架
2.2 预训练任务
本文定义了三个预训练任务,包括Image-text Contrastive Learning(ITC)、Word-in-image Prediction(WIP)和Masked Language Modeling(MLM)。
Image-text Contrastive Learning(ITC)的目的是使得文本编码序列的每一项都能在视觉编码序列中找到最相似的编码,也就是让每个单词的文本编码与其对应的文本图片区域视觉特征匹配(例如,“Last”的Text Embedding与图片中“Last”位置的区域特征相似度最高)。
该任务对每个图像编码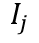 和文本编码
和文本编码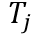 分别运用InfoNCE loss[4]去计算相似度。
分别运用InfoNCE loss[4]去计算相似度。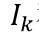 和
和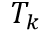 代表一个Batch内所有的图像编码和文本编码,它们分别为Image Encoder得到的和Text Encoder得到的
代表一个Batch内所有的图像编码和文本编码,它们分别为Image Encoder得到的和Text Encoder得到的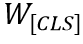 。
。
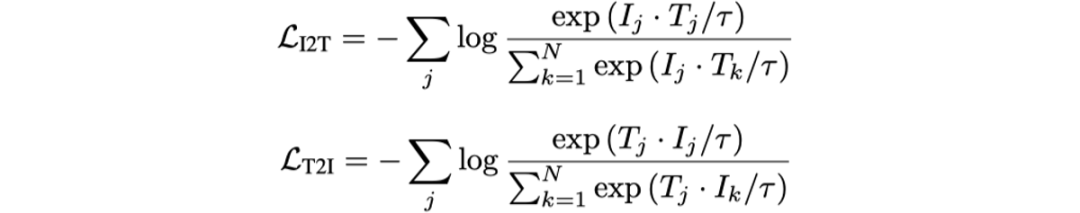
N代表Batch Size。ITC任务最终的损失函数为: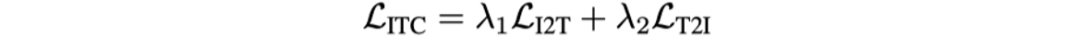
Word-in-Image Prediction(WIP)是通过在图像编码和文本单词编码中应用对比学习去区分出现在图片中的文本(正类)与不存在德文本(负类),从而预测给定的一组单词是否出现在输入图片中。如图1左上角所示,训练时图片中有的单词作为正样本,其编码为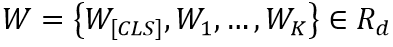 ;负样本则是训练过程中基于文本编码的相似度进行采样得到(如对于正样本“Lost”,负样本可为“Lose”,“Last”等),文中选取的是Top-L(L=63)相似的文本,对于每一个正样本的编码
;负样本则是训练过程中基于文本编码的相似度进行采样得到(如对于正样本“Lost”,负样本可为“Lose”,“Last”等),文中选取的是Top-L(L=63)相似的文本,对于每一个正样本的编码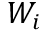 ,其负样本编码为
,其负样本编码为
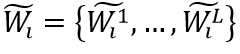
。输入图片为I,WIP的损失函数定义如下:
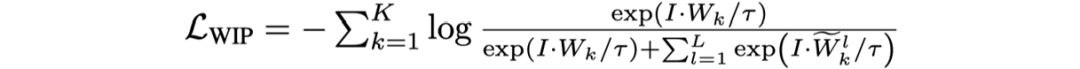
MaskedLanguage Modeling (MLM)类似于BERT,该任务首先随机掩盖文本编码w,然后让网络利用所有的视觉特征编码v和未被掩盖的文本编码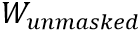 预测缺失的单词文本
预测缺失的单词文本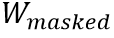 。如图1所示,图片中的文本“And”,“Was”等被掩盖,MLM任务是将它们预测恢复。其损失函数如下所示:
。如图1所示,图片中的文本“And”,“Was”等被掩盖,MLM任务是将它们预测恢复。其损失函数如下所示:
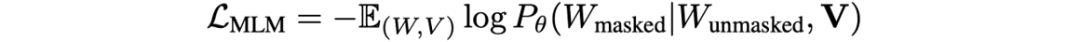
最终的损失函数为:
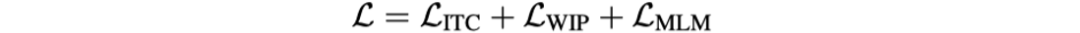
三、实验
3.1 实验细节
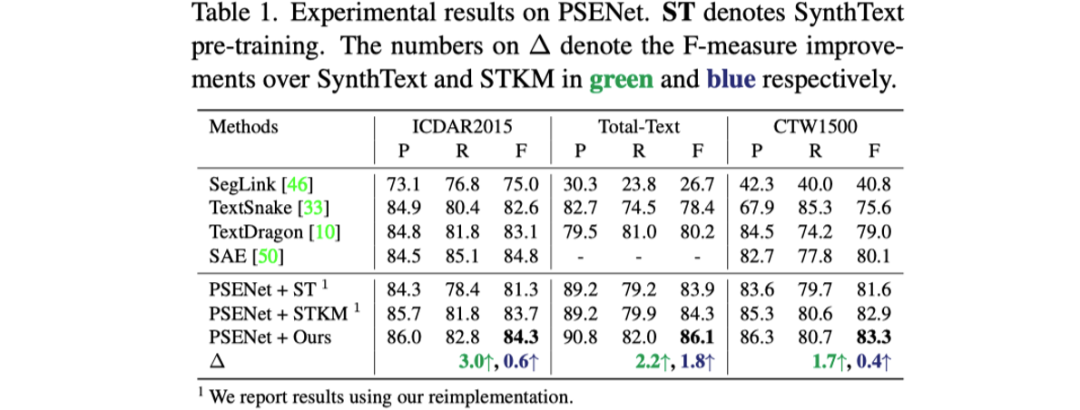
本文提出的VLPT-STD在SynthText [5]上进行预训练,然后将预训练得到的主干网络用于EAST [6],PSENet [7]和DB[2]这三个文本检测器在各个公开的真实场景数据集上进行Finetune。实验使用了八块v100,Batch Size为800。
3.2 与State-of-the-art的方法比较
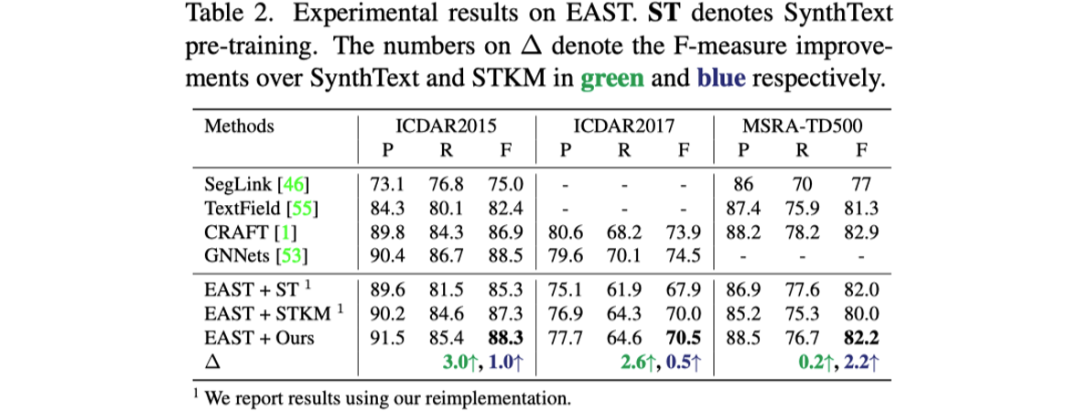
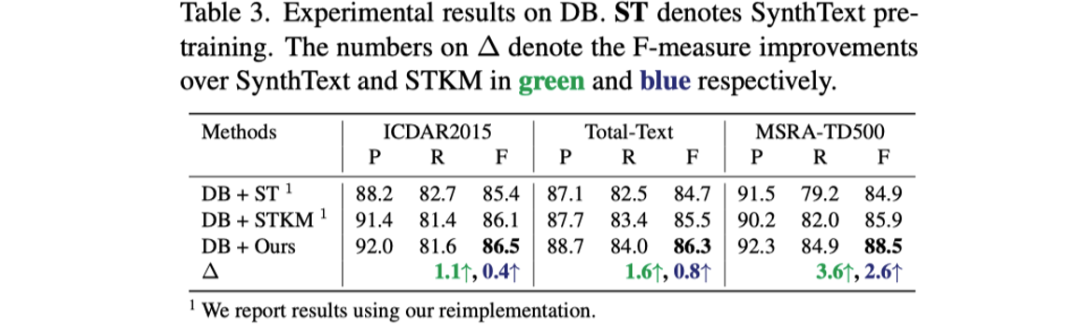
表格1到表格3展示了文章提出的预训练方法与之前预训练方法对于三个不同的文本检测器性能提升的对比。
3.2 消融实验
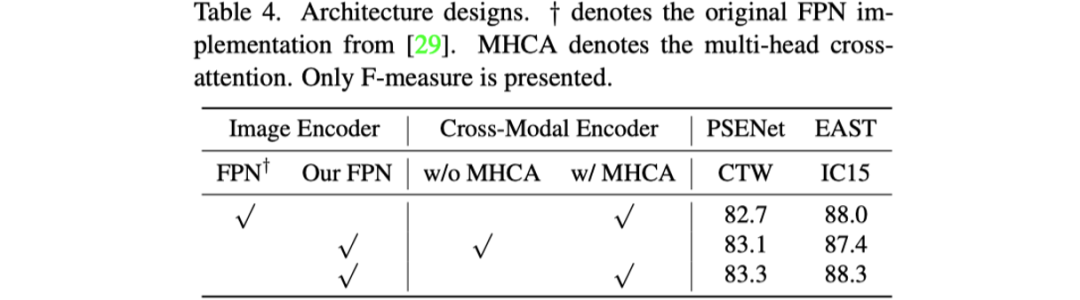
首先是对模型设计的消融实验,如表格4所示。文章探究了Image Encoder中作者改进的FPN结构和Cross-model Encoder中Cross-attention的作用。
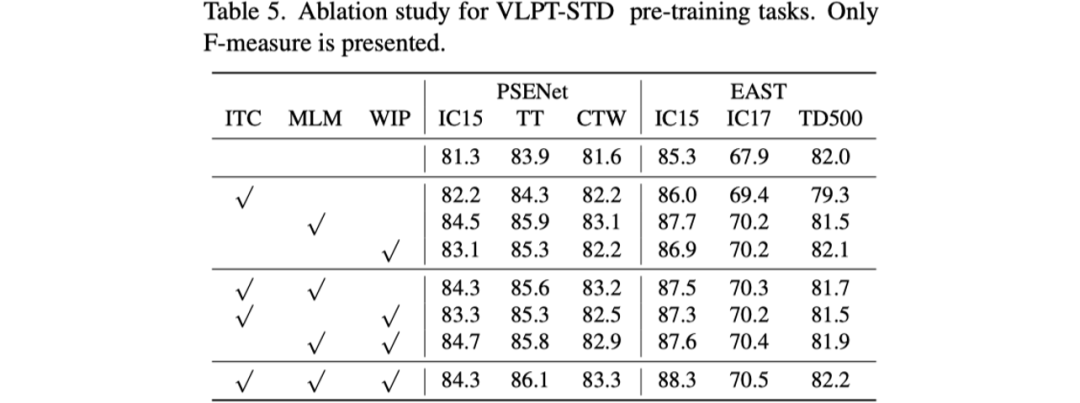
其次是对预训练任务的消融实验,如表格5所示。
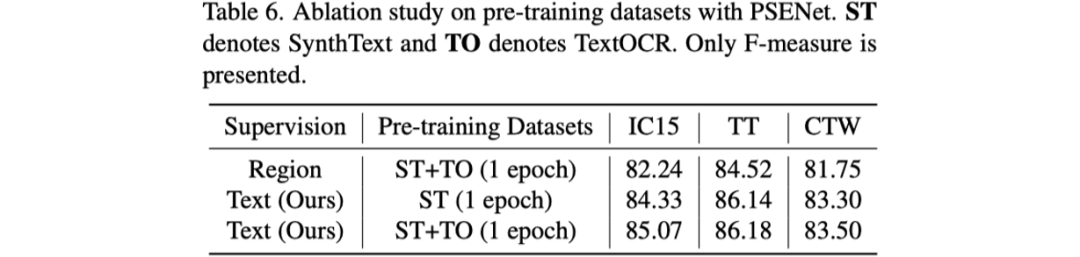
最后是对预训练的数据集进行了探究,作者对比了SynthText和TextOCR [8]两种数据集,结果如表6所示。
3.3 可视化结果
文章首先展示了Cross-model当中Attention Map的可视化结果。可以看到一个文本是与Attention Map中高亮区域是一一匹配的。

然后文章展示了和之前预训练方法STKM [3] 对比的检测结果。

四、总结与讨论
在场景文本检测当中,本文是第一篇用视觉语言模型以及多模态特征融合的思路去设计预训练任务以提升文本检测性能的工作,它设计了三个简单有效的任务,提高了主干网络对文本图像特征的表征能力。如何利用文本和图像两种模态的特征也是未来OCR领域的一个重要方向。
原文作者:Sibo Song, Jianqiang Wan, Zhibo Yang, Jun Tang, Wenqing Cheng, Xiang Bai, Cong Yao
审核编辑:郭婷
-
一文详解知识增强的语言预训练模型2022-04-02 11076
-
【大语言模型:原理与工程实践】大语言模型的基础技术2024-05-05 1384
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1566
-
预训练语言模型设计的理论化认识2020-11-02 4072
-
一种脱离预训练的多尺度目标检测网络模型2021-04-02 1745
-
如何向大规模预训练语言模型中融入知识?2021-06-23 6313
-
基于预训练视觉-语言模型的跨模态Prompt-Tuning2021-10-09 4211
-
Multilingual多语言预训练语言模型的套路2022-05-05 4311
-
一种基于乱序语言模型的预训练模型-PERT2022-05-10 2592
-
CogBERT:脑认知指导的预训练语言模型2022-11-03 1976
-
利用视觉+语言数据增强视觉特征2023-02-13 1851
-
什么是预训练 AI 模型?2023-04-04 2702
-
NLP中的迁移学习:利用预训练模型进行文本分类2023-06-14 881
-
预训练模型的基本原理和应用2024-07-03 6051
-
大语言模型的预训练2024-07-11 1917
全部0条评论

快来发表一下你的评论吧 !
