

如何在不增加额外参数量的前提下把模型的表达能力挖掘到极致
电子说
描述
今天跟大家分享一篇来自CMU等机构的论文《Sliced Recursive Transformer》,该论文已被 ECCV 2022 接收。
目前 vision transformer 在不同视觉任务上如分类、检测等都展示出了强大的性能,但是其巨大的参数量和计算量阻碍了该模型进一步在实际场景中的应用。基于这个考虑,本文重点研究了如何在不增加额外参数量的前提下把模型的表达能力挖掘到极致,同时还要保证模型计算量在合理范围内,从而可以在一些存储容量小,计算能力弱的嵌入式设备上部署。
基于这个动机,Zhiqiang Shen、邢波等研究者提出了一个 SReT 模型,通过循环递归结构来强化每个 block 的特征表达能力,同时又提出使用多个局部 group self-attention 来近似 vanilla global self-attention,在显著降低计算量 FLOPs 的同时,模型没有精度的损失。

论文地址:https://arxiv.org/abs/2111.05297
代码和模型:https://github.com/szq0214/SReT
总结而言,本文主要有以下两个创新点:
使用类似 RNN 里面的递归结构(recursive block)来构建 ViT 主体,参数量不涨的前提下提升模型表达能力;
使用 CNN 中 group-conv 类似的 group self-attention 来降低 FLOPs 的同时保持模型的高精度;
此外,本文还有其他一些小的改动:
网络最前面使用三层连续卷积,卷积核为 3x3,结构直接使用了研究者之前 DSOD 里面的 stem 结构;
Knowledge distillation 只使用了单独的 soft label,而不是 DeiT 里面 hard 形式的 label 加 one-hot ground-truth,因为研究者认为 soft label 包含的信息更多,更有利于知识蒸馏;
使用可学习的 residual connection 来提升模型表达能力;
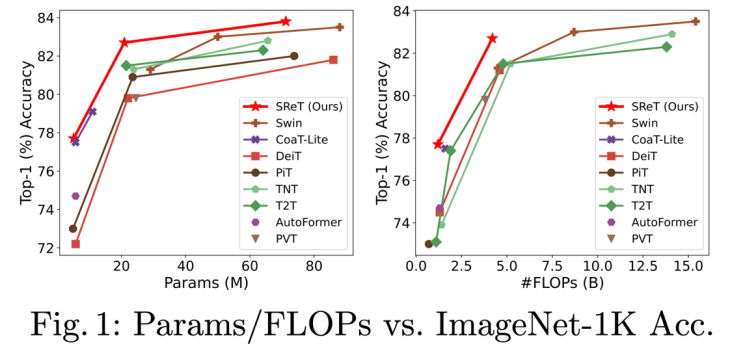
如下图所示,本文所提出的模型在参数量(Params)和计算量(FLOPs)方面相比其他模型都有明显的优势:
下面我们来解读这篇文章: 1.ViT 中的递归模块 递归操作的基本组成模块如下图:
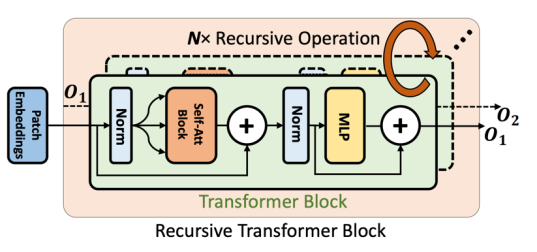
该模块非常简单明了,类似于 RNN 结构,将模块当前 step 的输出作为下个 step 的输入重新输进该模块,从而增强模型特征表达能力。 研究者展示了将该设计直接应用在 DeiT 上的结果,如下所示:
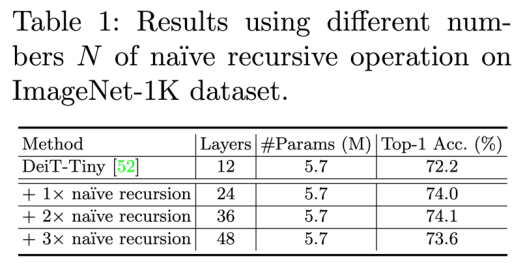
可以看到在加入额外一次简单递归操作之后就可以得到将近 2% 的精度提升。 当然具体到全局网络结构层面还有不同的递归构建方法,如下图:
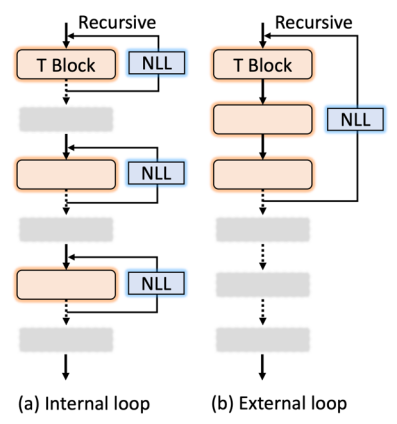
其中 NLL 层(Non-linear Projection Layer)是用来保证每个递归模块输入输出不完全一致。论文提出使用这个模块的主要原因是发现在上述 Table 1 里面更多次数的递归操作并没有进一步提升性能,说明网络可能学到了一个比较简单的状态,而 NLL 层可以强制模型输入输出不一致从而缓解这种情况。同时,研究者从实验结果发现上图 (1) internal loop 相比 external loop 设计拥有更好的 accuracy-FLOPs 结果。 2. 分组的 Group Self-attention 模块 如下图所示,研究者提出了一种分组的 group self-attention 策略来降低模型的 FLOPs,同时保证 self-attention 的全局注意力,从而使得模型没有明显精度损失:
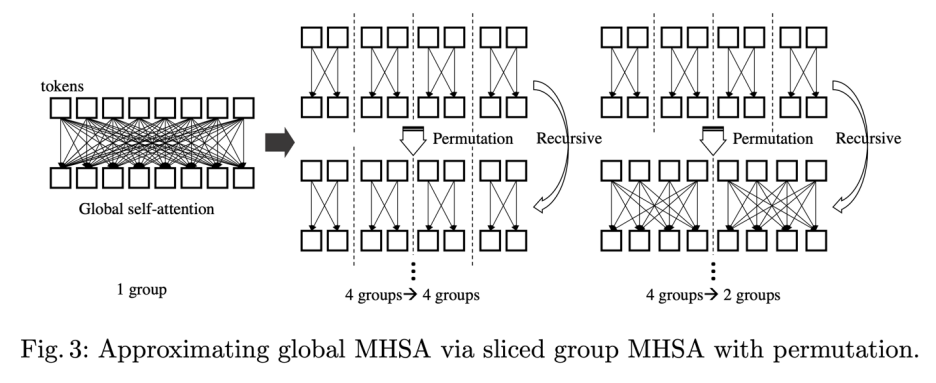
Group Self-attention 模块具体形式如下:
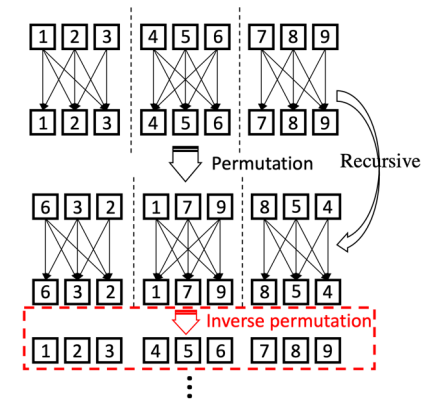
Group self-attention 的缺点是只有局部区域会相互作用,研究者提出通过使用 Permutation 操作来近似全局 self-attention 的机制,同时通过 Inverse Permutation 来复原和保留 tokens 的次序信息,针对这个部分的消融实验如下所示:
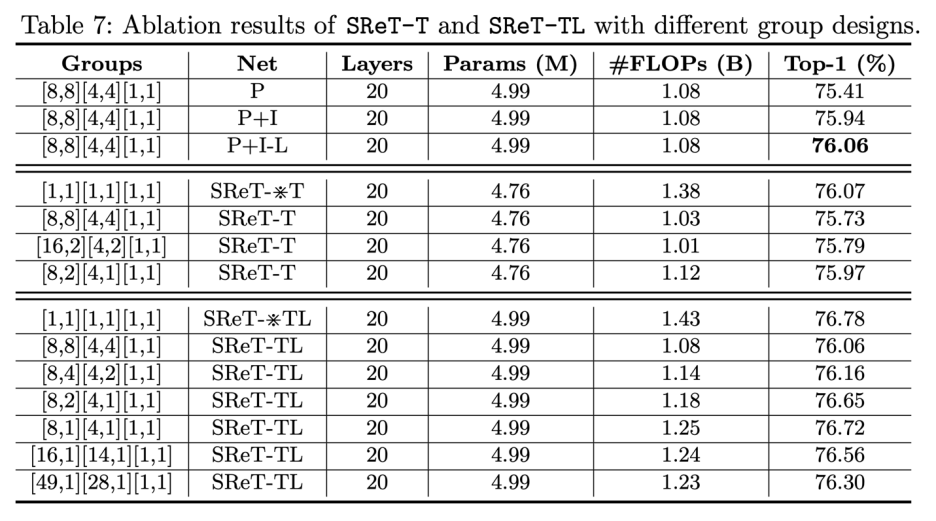
其中 P 表示加入 Permutation,I 表示加入 Inverse Permutation,-L 表示如果 group 数为 1,就不使用 P 和 I(比如模型最后一个 stage)。根据上述表格的结果,研究者最后采用了 [8, 2][4,1][1,1] 这种分组设计。 3. 其他设计 可学习的残差结构 (LRC):
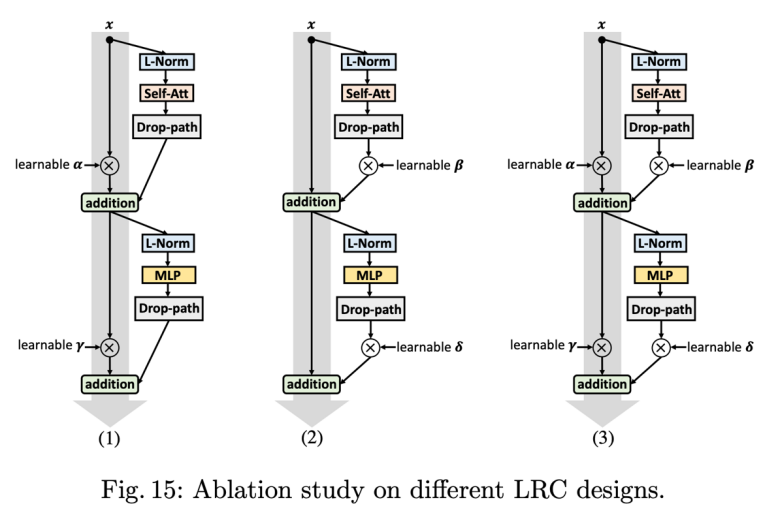
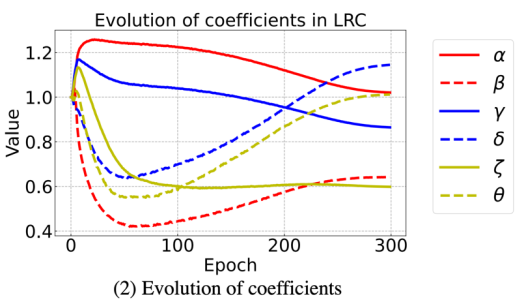
研究者尝试了上图三种结构,图(3)结果最佳。具体而言,研究者在每个模块里面添加了 6 个额外参数(4+2,2 个在 NLL 层),这些参数会跟模型其他参数一起学习,从而使网络拥有更强的表达能力,参数初始化都为 1,在训练过程 6 个参数的数值变化情况如下所示:
Stem 结构组成:
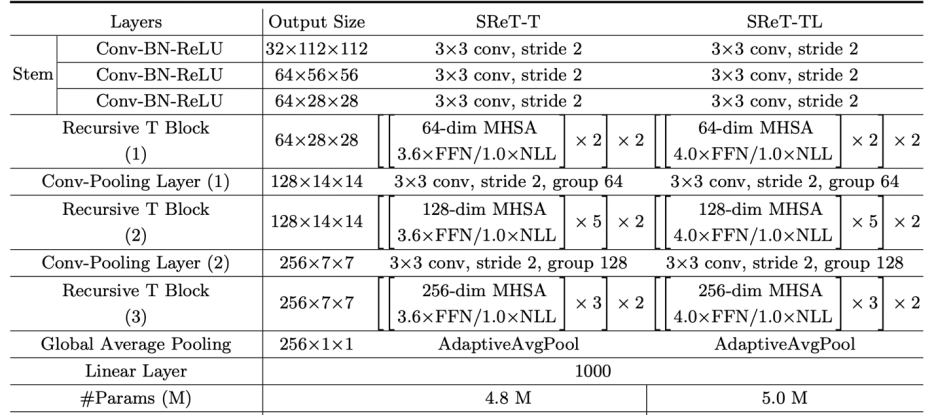
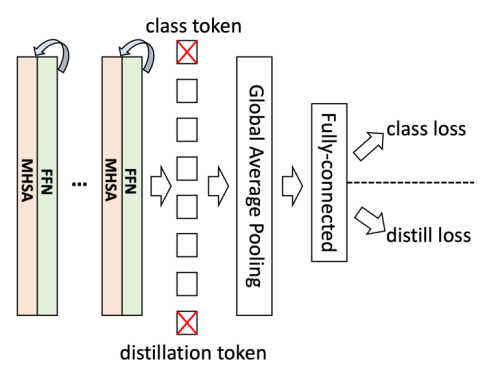
如上表所示,Stem 由三个 3x3 的连续卷积组成,每个卷积 stride 为 2。 整体网络结构: 研究者进一步去掉了 class token 和 distillation token,并且发现精度有少量提升。
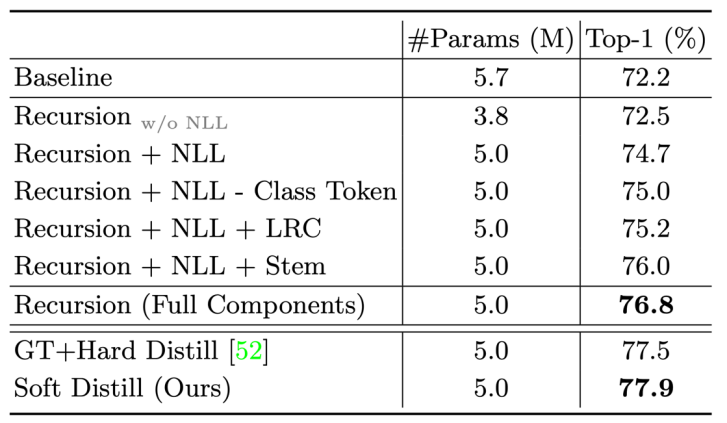
消融实验:
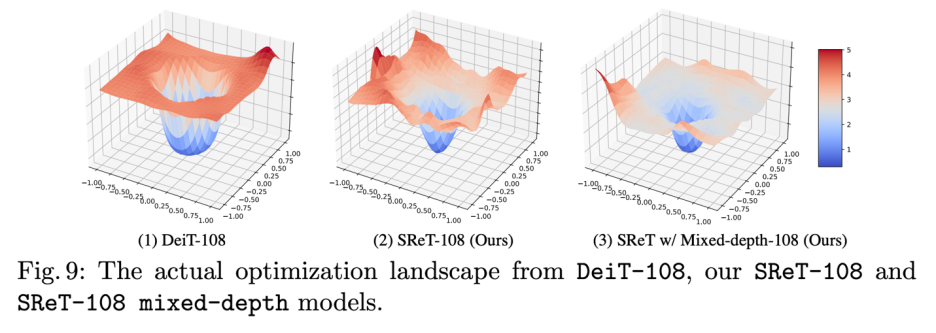
模型混合深度训练: 研究者进一步发现分组递归设计还有一个好处就是:可以支持模型混合深度训练,这种训练方式可以大大降低深度网络结构优化复杂度,研究者展示了 108 层不同模型结构优化过程的 landscape 可视化,如下图所示,可以很明显的看到混合深度结构优化过程困难程度显著低于另外两种结构。
最后,分组 group self-attention 算法 PyTorch 伪代码如下:

审核编辑 :李倩
-
PCB上在不拆掉集成块的前提下怎么能测其好坏?2024-09-02 468
-
在不写程序的前提下,怎么判断ADS1253正常工作了?2025-01-07 393
-
在不影响选择原有器件前提下,在KEIL下增加STC单片机2011-05-10 8744
-
如何简单检测段式LCD的分压方式,在没有LCD资料的前提下...2014-01-14 2491
-
求教大神们,在不退出软件的前提下,怎么实现用户的退出和再登入?2018-05-03 6031
-
请问MIMO为什么能在不增加带宽的前提下成倍的提高信道容量呢?2023-05-16 9094
-
AD7656BSTZ在保证供电和输入模拟信号不超的前提下,什么原因会导致芯片±15V引脚被烧?2023-12-14 660
-
Date功能:ISE中如何在未综合实现的前提下打开ChipScope ?2017-02-10 1839
-
最新可用隔离元件的性能提升如何帮助替代架构在不影响安全性的前提下提升系统性能2017-10-13 8780
-
智慧医疗的真正实现要在万物互联的前提下 数据共享是非常关键的环节2019-04-18 2237
-
如何在避免接触的前提下高效地完成体温检测?2020-08-24 3067
-
如何在多模态的语境中利用Transformer强大的表达能力?2021-03-29 4720
-
不连外网的前提下能否使用数据可视化工具2021-10-09 722
-
如何在保证数据安全的前提下优化通信协议?2025-08-27 1055
-
如何在保证监测效果的前提下降低电能质量在线监测装置的运行和维护成本?2025-09-03 1201
全部0条评论

快来发表一下你的评论吧 !
