

用于3D点云形状分析的跨模态知识迁移统一架构的构建
电子说
描述
作者:Qijian Zhang, Junhui Hou, Yue Qian
作为 3D 对象的两种基本表示方式,2D 多视图图像和 3D 点云从视觉外观和几何结构的不同方面反映了形状信息。与基于深度学习的 2D 多视图图像建模不同,2D 多视图已经在各种 3D 形状分析任务中表现出领先的性能,而基于 3D 点云的几何建模仍然存在学习能力不足等问题。在本文中,我们创新性地构建了一个跨模态知识迁移的统一架构,将 2D 图像中具有判别性的视觉描述符蒸馏成为 3D 点云的几何描述符。从技术上讲,在经典的 teacher-student学习范式下,我们提出了多视图 vision-to-geometry 蒸馏,由作为teacher的深度 2D 图像encoder和作为 student的深度 3D 点云encoder组成。为了实现异构特征的对齐,我们进一步提出了可见性感知的特征投影,通过它可以将各点 embeddings 聚合成多视图几何描述符。对 3D 形状分类、部件分割和无监督学习进行了广泛实验,验证了我们方法的优越性。我们将会公开代码和数据。
1 引言
在 3D 数据采集和感知方面的一些最新进展的促进下,基于深度学习的 3D 形状分析在工业界和学术界受到越来越多的关注。根据 3D 形状模型的不同表征方式,主流的学习范式可分为:
基于图像的
基于体素的
基于点的
目前,3D 形状理解没有统一的建模范式,因为每种方法都有不同的优点和局限性。
基于图像的方法 通过多个视点渲染出的多视图 2D 图像的集合,来表示 3D 模型。受益于先进的图像建模架构,以及大规模存在丰富标注的图像数据集,多视图学习在各种形状识别任务中展示了主导性能。然而,形状渲染是基于高质量的人造的多边形网格来实现的,这些网格不能直接从现实世界的传感器或扫描仪中获得,并且不可避免地会丢失内部的几何结构和详细的空间纹理信息。
基于体素的方法 使用体积网格来描述 3D 模型的空间占用,这样标准的 3D 卷积架构可以自然地扩展到用于特征提取,而无需额外去开发特定的学习算子。不幸的是,由于计算复杂度和内存占用的指数增长,这种学习范式更适合处理低分辨率的volumes,并且需要精心配置的、复杂的分层 3D 索引结构,用于处理更密集的体素并获取几何细节信息。
基于点的方法 近年来,基于点的方法逐渐流行,能直接对非结构化 3D 点云进行操作而无需任何进行预处理。作为最直接的几何表征形式,点云是许多 3D 采集设备的原始输出,并能够充分的记录空间信息。然而,与在规则网格上定义的图像和体素不同,点云具有不规则和无序的特点,这给特征提取带来了很大困难。因此,基于点的学习框架仍有很大的性能提升空间。
受基于图像的视觉建模和基于点的几何建模之间互补特性的启发,本文探索了从强大的深度图像encoders中提取的知识迁移到深度点encoders,从而提高下游形状分析任务的性能。在技术上,我们创新性地提出了多视图vision-to-geometry蒸馏(MV-V2GD),这是一种遵循标准的 teacher-student架构设计的统一处理pipeline,用于跨模态的知识迁移。如图1所示,给定一个 3D shape,我们将一组多视图 2D 图像输入到teacher分支的预训练深度 2D 图像encoder中,进而生成多视图的视觉描述符。而在student分支中,我们将3D点云输入一个深度点encoder,进而产生高维的per-point embeddings。在相同的相机位姿下,我们计算特定视图的point-wise可见性。在此基础上,我们生成多视图的几何描述符。通过在多视图视觉和几何描述符之间执行特征对齐,可以引导student模型学习更多有区分性的point-wise特征,进而理解几何形状。为了验证提出的 MV-V2GD 框架的有效性,我们选择了常见的深度点encoder作为 student模型的baseline ,并在三个benchmark任务上进行了实验,包括形状分类、部件分割和无监督学习,我们实现了明显且稳定的性能提升。
总之,本文的主要贡献有三方面:
• 我们提出了一个统一的 MV-V2GD 学习框架,首次尝试从多视图 2D 视觉建模将知识迁移到 3D 几何建模,从而进行 3D 点云的形状分析。
• 为了促进多视图visual-geometric特征对齐,我们特别开发了一种简单而有效的 VAFP 机制,该机制将 per-point embeddings聚合到特定视图的几何描述符中。
• 在大量下游任务和baseline模型中,我们观察到性能的提升很大,这揭示了一种新的用于增强点云网络学习能力的通用范式。
本文的其余部分安排如下。在第2章中,我们讨论了与多视图 3D 形状分析、deep set架构以及 2D-3D 知识迁移等密切相关的研究工作。在第3章中,我们首先在3.1 节总结我们提出的方法的工作机制;在 3.2 节和3.3 节分别介绍了主流的深度 2D 图像和 3D 点encoders的一般形式,且这也基于 3.4节中我们构建的统一的多视图跨模态的特征对齐方案。然后,介绍了一种新颖的 visibility-aware的特征投影机制(VAFP),它可以较好地生成特定视图的 visual-geometric表示对。最后,在3.5节中我们总结了总体的训练目标和策略。在第4章中,我们报告了不同baseline的深度点encoders和benchmark任务的实验结果。最后,我们在第5章中提出了一些批判性的讨论,并在第6章中总结整篇论文。
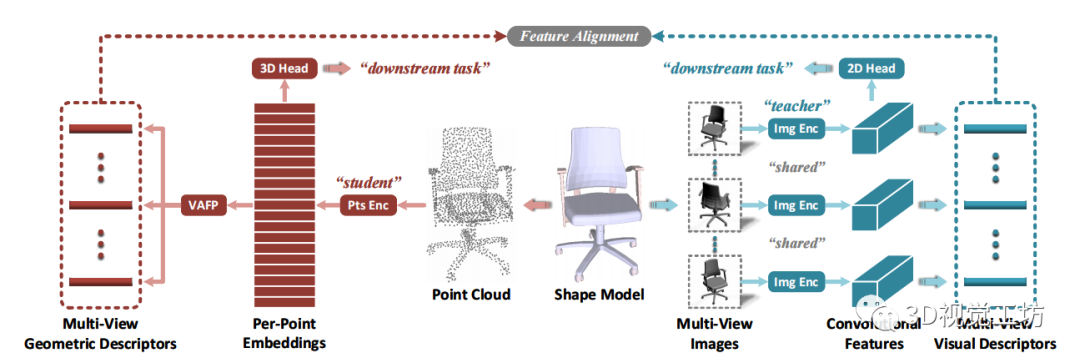
图 1 提出的 MV-V2GD 跨模态知识迁移框架的总体流程图,其中包括:一个预训练的基于图像的teacher分支(右),一个基于点的、通过多视图特征对齐进行蒸馏的student分支(左)。在训练阶段,整个teacher分支是固定的,用于提供discriminative knowledge。而在测试阶段teacher分支被移除,以便我们仅从点云进行推理。
2 相关工作
多视图 3D 形状分析。作为 2D 深度学习的扩展,多视图 3D 形状建模,通常建立在多输入的 2D 卷积神经网络 (CNNs) 的各种变体之上。由 MVCNN 开创,它输入从预定义的相机位姿渲染出的多视图图像,并通过跨视图的max-pooling来生成全局的形状signature。许多后续的工作,致力于设计更高级的视图聚合或选择的策略。GVCNN 构建了一个三级分层的相关建模框架,该框架将多视图描述符自适应地分组到不同的簇中。MHBN 和 RelationNet 进一步利用patch-level的交互来丰富视图间的关系。RotationNet 将视点索引作为可学习的潜在变量,并提出联合估计目标姿态和类别。EMV 提出了一种分组卷积的方法,该方法对旋转组的离散子群进行操作,并提取旋转等变的形状描述符。最近,View-GCN将多视图视为图节点,从而形成相应的视图graph,在该视图graph上应用图卷积来学习多视图关系。MVTN通过引入可微分渲染来自适应地回归得到最佳视点,从而实现端到端训练。
3D 点云的深度学习。由 PointNet 率先采用point-wise多层感知机 (MLP),实现了置换不变的特征提取,并直接在点云上进行 3D 几何建模,这样的深度集architecture迅速流行。PointNet++继承了深度 CNN 的设计范式,引入了局部邻域聚合,并采用渐进式的下采样进行分层提取。在后来的工作中,已经研究了各种各样的高专业化的点卷积算子。通过学习核匹配的自适应权重,进而来模仿标准卷积进行了更复杂的点特征聚合策略,进而增强网络容量。DGCNN 提出了一种基于图的动态特征更新机制,可以捕获全局的上下文信息。探索了基于学习的,而不是启发式的子集选择技术。最近,transformer架构也应用于点云建模。
2D 和 3D 之间的跨模态知识迁移。正如中指出的那样,尽管知识蒸馏研究激增,但由于缺乏配对样本,在具有明显模态差距的跨模态场景上的研究相对较少,而当在 2D域 和 3D 域之间进行时,这项任务变得更具挑战性。xMUDA 提出通过基于pixel-point对应关系来对齐 2D 和 3D 输出,从单视图图像的源域和点云的目标域实现无监督的域自适应。PPKT 构建了一个 3D 预训练pipeline,将对比学习策略应用于正负像素点对,从而利用 2D 预训练知识。在相反的迁移方向上,Pri3D探索了 3D 引导的对比预训练,用于提升 2D 感知方面。除了保持成对的 2D 像素和 3D 点之间的特征一致性外,这项工作还在于学习不变像素描述符,通过从不同视点捕获的图像扫描。在 有更灵活的3Dto-2D的蒸馏框架,通过特定维度的归一化,进而对齐 2D 和 3D CNN 特征的统计分布。特别地是,为了摆脱对 2D 和 3D 模态之间细粒度对应关系的依赖,且这些模态通常获取成本很高,这项工作还探索了一种语义感知的对抗训练方案,用来处理不成对的 2D 图像和 3D 体积网格。通常,由于 2D 和 3D 数据之间的对应信息的可用性,现有工作主要集中在场景级别的理解上。目前,据我们所知,之前没有关于形状分析任务的跨模态知识迁移的研究。
3 提出的方法
3.1 问题概述
我们考虑了两种互补的 3D 形状理解的学习范式,即由2D多视图图像驱动的2D视觉建模和由 3D点云驱动的3D几何建模。如上所述,由于规则的数据结构和强大的学习架构,基于图像的深度模型可以提取 discriminative feature表征,尽管丢失了部分几何信息。相比之下,3D点云虽然保留了完整的3D几何结构,但其结构的不规则性给特征提取带来了很大挑战,因此基于点的深度模型的学习能力相对不足。因此,我们的目标是从深度 2D 图像encoder中提取判别知识,蒸馏到深度 3D 点encoder中。这实际上是一个相当具有挑战性的问题,因为在网络架构和数据模态方面存在显着的域差距。

我们的工作机制与多模态融合本质上不同。在多模态融合中,多模态数据在训练和测试阶段都被作为输入。在功能上,我们强调 MV-V2GD 作为一种通用的学习范式,可以自然地应用于通用深度点的encoders,用于增强网络容量。
3.2 用于 2D 图像建模的Teacher网络
深度卷积架构,已经展示了从 2D 图像中学习discriminative视觉特征的显著能力。在大规模图像数据集上,受益于预训练的成熟的 2D CNN 的backbone网络激增 ,我们可以方便地选择合适且功能强大的现有深度 2D 图像encoder作为我们的 2D teacher模型Mt ,它分别将多视图图像作为输入,并相应地生成高维卷积特征图。形式上,我们可以将teacher模型的一般形式表述为:

3.3 3D 点云建模的Student网络
与成熟的 2D 图像建模相比,3D 点云的深度学习仍然是一个新兴但快速发展的研究领域。受限于大规模形状数据集的稀缺性和 3D 标注的难度,当前的深度set architectures实际上还远远不够深,为了缓解参数过拟合,在应用于下游任务时通常需要从头开始训练。因此,基于点的学习模型,在捕获discriminative几何特征表征方面,表现出学习能力不足。
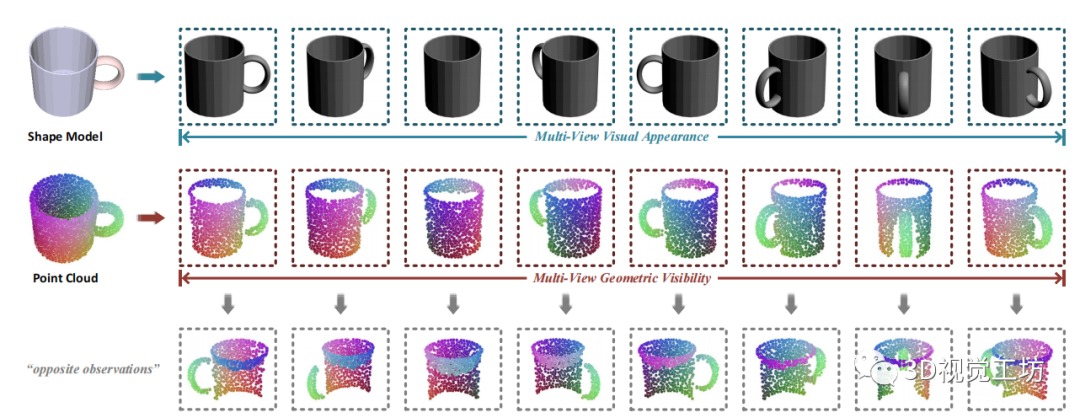
图 2 多视图可见性checking示意图。在预定义的相机位姿下,我们相应地生成了一组多视图图像和部分点云,放置在第一行和第二行。在第三行中,我们还提供了从相反的方位角观察时,可见点的可视化效果。
我们将深度 3D 点encoder Ms视为 3D student模型,也就是被蒸馏的目标。它使用一组不规则的空间点作为输入,并产生高维的point-wise embeddings。不失一般性,我们可以将student模型的形式描述为:
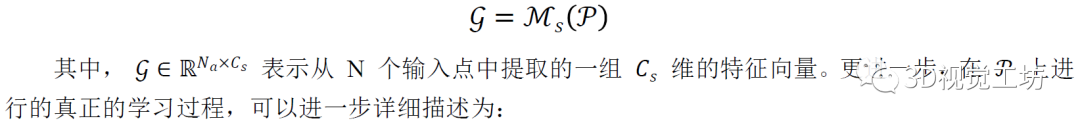

3.4 多视图可见性感知的特征对齐


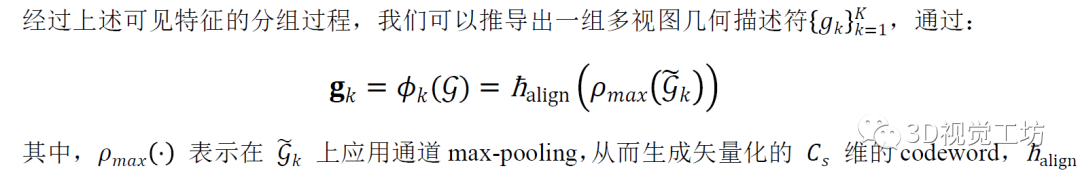
通过单个全连接层 (FC)实现,实现了视觉和几何描述符之间的通道对齐。在4.4节,我们验证了 VAFP 驱动的知识迁移框架,相比于传统蒸馏范式的优越性。
3.5 总体目标

4 实验
我们评估了我们提出的 MV-V2GD 框架在三个应用场景中的有效性,即形状分类(第 4.1 节)、部件分割(第 4.2 节)和reconstruction-driven的无监督学习(第 4.3 节)。在每个小节中,我们介绍了benchmark数据集和数据的准备操作,之后我们提供了teacher和student模型架构的主要实现技术。最后,我们提供了具体的对比实验和性能分析。
4.1 形状分类
数据准备。ModelNet40 是一个常见的 3D 对象数据集,包含 12311 个多边形网格模型,涵盖 40 个人造类别。在官方拆分之后,我们使用 9843 个形状数据集进行训练,其余 2468 个数据集进行测试。

具体来说,我们采用轻量级的 2D CNN backbone(即 MobileNetV2 ),从输入的多视图图像中提取深度卷积特征和矢量化视觉描述符。此外,除了从单个的全局形状signature输出最终的类别分数(logits)外,我们还倾向于单独预测来自所有视图的形状类别,通过添加侧输出的supervisions。
Student网络的架构。我们选择了三种具有代表性的深度点云建模架构,包括 1) PointNet 、2) PointNet++ 和 3) DGCNN 作为目标student点encoder 。此外,我们还尝试了 CurveNet,一种更新的SOTA学习模型。在最初的实现中,分类头由三个全连接层组成,它们将全局形状signature转换为类别 logits。而在我们所有的实验中,我们将 统一简化为单个线性层。请注意,在测试阶段,我们没有采用任何投票技术 ,这些技术变得非常繁琐且不稳定。
定量结果。我们在表 1 中列出了原始模型和蒸馏模型的形状分类准确率。作为早期设计的简单架构的工作,PointNet 官方报告的整体准确率为 89.2%,这被认为远不能令人满意。令人惊讶的是,在 MV-V2GD 的驱动下,该模型的性能甚至比原来的 PointNet++ 还要好,后者涉及更复杂的学习patterns。得益于增强的建模能力,PointNet++ 在蒸馏后进一步达到了极具竞争力的 93.3%。DGCNN 代表了一种常见的强大的graph-style点云建模范式,从 92.9% 提升到 93.7%,性能明显提升 0.8%。即使对于SOTA的 CurveNet,我们的方法仍然获得了令人满意的性能提升,从 93.8% 提高到 94.1%。。
4.2 部件分割
数据准备。ShapeNetPart 是一个流行的 3D 对象的部分分割benchmark数据集,它提供了在 16 个对象类上定义的 50 个不同部件类别的语义标注。官方拆分后,我们有 14007 个形状数据集用于训练,其余 2874 个数据集用于测试。

Teacher分支的架构。与许多已经存在的成熟的多视图学习框架的形状分类或检索相比,基于图像的形状分割方面的研究相对较少。因此,我们设计了一个标准的单图像分割架构作为teacher分支,如图4所示。整体的架构设计遵循经典的encoder-decoder pipeline(例如:U-Net [19]),用来生成全分辨率分割图。在这里,teacher分支单独使用单视图的图像进行预测,而不是同时对同一形状模型的整组多视图图像进行分割。因为我们凭经验发现,这种学习范式计算量大且在训练期间难以收敛。
更具体地说,我们选择 VGG11 作为backbone特征提取器,并移除了最后一个空间max-pooling层,从而扩大了特征图分辨率。为了增强网络容量,我们将 中提出的位置和通道上的attention机制添加到了原始的卷积阶段。然后,通过重建从训练shape渲染得到的视图图像,进而fine-tune整个backbone网络。遵循之前部件分割框架中的常见做法,我们还集成了一个分类向量,该向量将输入图像的对象类别,encode到中间视觉描述符中。
Student分支的架构。我们再次采用 PointNet、PointNet++ 和 DGCNN 作为student的点encodersMs ,并使用他们初始的head网络Hs ,用来预测每个点的语义标签,而无需投票。
定量结果。我们在表 2 中列出了原始模型和蒸馏模型的部件分割精度。从中我们可以观察到,我们的方法始终增强了不同类型的深度set architectures。特别是,PointNet 从 83.7% 提高到 85.9%,在 mIoU 方面具有很大的获益。另外两个更强大的学习框架,即 PointNet++ 和 DGCNN,也从 MV-V2GD 中受益很多,分别有 1.3% 和 1.7% 的明显性能提升。
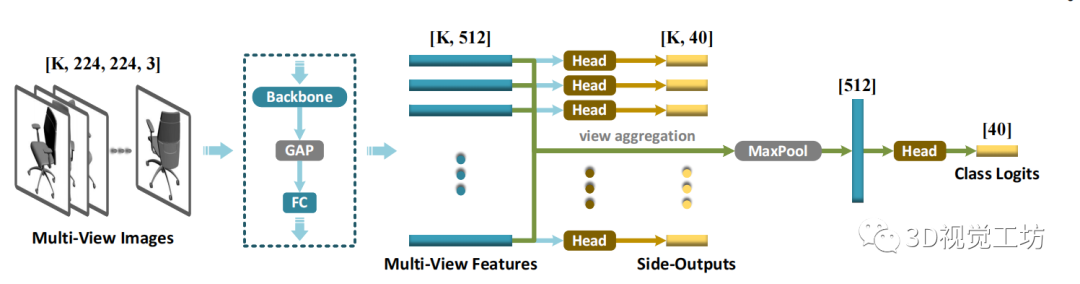
图 3 用于2D多视图图像驱动的形状分类的的Teacher学习分支表 1 ModelNet40 上 3D 形状分类的总体准确率 (%)


图 4 用于 2D 图像驱动的目标部件分割的Teacher学习分支
表 2 ShapeNetPart 上目标部件分割的实例平均mIoU(%)


图 5 用于单视图图像重建的 Teacher 学习分支
表 3 ModelNet40 上的Transfer分类准确率 (%)

4.3 无监督学习
以前的实验已经证明了 MV-V2GD 在有监督学习方面的有效性,这需要特定领域的数据和标注。在本节中,我们探讨了迁移通过无监督特征学习获得的通用 2D 视觉知识,从而促进 3D 几何建模的可能性。
遵循与 中构建的相同开发协议(称为transfer classification),我们首先在源数据集(即 ShapeNetCoreV2)上预训练深度点云 auto-encoder。之后,我们部署预训练的encoder网络,进而从不同的目标数据集(即 ModelNet40 )生成矢量化的形状signatures。最后,在目标数据集上训练线性 SVM 分类器,用来评估形状signatures的判别能力。
数据准备。 ShapeNetCoreV2 [63] 是一个大型 3D 对象数据集,包含 52472 个多边形网格模型,涵盖 55 个对象类别。
对于几何建模,我们应用 PDS,从 ShapeNetCoreV2 数据集和 ModelNet40 数据集中统一采样 2048 个空间点。对于视觉建模,我们采用了与第 4.2 节中描述相同的viewpoint配置,进而在ShapeNetCoreV2 数据集上生成多视图的图像渲染。
Teacher 分支的架构。如图 5所示。我们构建了一个标准卷积的 auto-encoder,用于无监督图像的特征学习。在encode阶段,我们应用了与部件分割实验中采用的相同的backbone网络,将输入的视图图像紧凑地表征为一个矢量化的形状signature。在decode阶段,我们部署了一个全连接层来提升特征维度,以及多阶段的反卷积层来实现全分辨率的图像重建。
Student分支的架构。我们尝试了一个经典的点云驱动的无监督几何特征学习的架构,即 FoldingNet,作为目标student分支。从技术上讲,它将给定的点encodes为一个紧凑的全局codeword向量,从而驱动随后的lattice deformation过程,用来重建输入的点云。
定量结果。我们在表 3 中列出了原始模型和蒸馏模型的transfer classification的准确率,我们可以观察到,FoldingNet 从 88.4% 提高到 89.1%。
此外,在没有特定任务预训练的情况下,我们对迁移从自然图像统计中学习到的常见视觉线索的潜力感兴趣。为此,我们直接部署了在 ImageNet 上预训练的原始 VGG11 的backbone网络,用来提供teacher知识,这也增强了目标student模型,精度提高了 0.4%。
4.4 额外探索
通过设计不同的架构变体,并评估它们在 ModelNet40 上的分类性能,我们进行了额外的探索。
超参数分析。为了全面探索我们的学习框架的特点,我们通过调整两个关键的超参数来修改原始 MV-V2GD 设置:1)视点数量 K ;2)加权因子Wt (等式 6)。

我们尝试将原始点云而不是网格直接渲染到多视图图像中,以训练教师分支,进一步部署为学生分支提供视觉知识。图 6 显示了基于点的渲染的一些典型视觉示例以及它们的网格驱动对应物。显然,这种学习策略对于无法获得高质量的基于网格的几何表示的应用程序更加灵活和实用。如表 6 所示,该变体在所有蒸馏模型上仍然显示出令人满意的性能提升,这证明了我们提出的图像到点知识转移范式的普遍性。
基于点的渲染Pipeline。我们尝试直接使用原始点云而不是网格,将其渲染到多视图图像中,从而训练teacher分支,并进一步为student分支提供视觉知识。图 6 显示了基于点的渲染的一些典型视觉示例,以及它们的mesh-driven对应物。显然,对于无法获得高质量的基于网格的几何表征的应用程序,这种学习策略更加灵活和实用。如表 6 所示,该变体在所有蒸馏模型上仍然显示出令人满意的性能提升,这证明了我们提出的image-to-point知识迁移范式的普遍性。
从头开始训练 Teacher 模型。所提出的跨模态(visual-togeometric)知识迁移框架的主要优点之一是,我们可以方便地利用现成成熟的视觉识别网络,这些网络在大规模带标注的 2D 图像数据集上充分预训练,例如:ImageNet。一个更有趣且有前景的问题是,探索 2D 视觉和 3D 几何建模范式之间的交互机制本身是否有益。事实上,在我们的无监督学习实验中,我们试图通过从头开始训练teacher分支来验证这个问题,这仍然带来了性能提升。在这里,我们进一步进行了实验以在有监督学习场景下加强此类主张。
更具体地说,在这个基于点的渲染实验中,我们保持所有的开发协议不变。除了,我们没有为teacher分支的backbone网络加载 ImageNet 预训练权重。定量结果如表 7 所示,从中我们可以惊奇地观察到,在点云渲染上,完全从头开始训练teacher分支仍然显示出极具竞争力的性能,甚至优于其在 PointNet [11] 上的 ImageNet 预训练和mesh-driven对应物。这种现象有力地证明了,所提出的visual-geometric学习范式的巨大潜力。
表 4 不同的渲染视点数量 (K) 的影响。

表 5 不同加权方案 () 对训练目标的影响


图 6 基于网格和基于点的渲染结果的可视化示例传统蒸馏范式的适应。为了揭示我们方法的必要性和优越性,我们进一步设计了两个baseline知识迁移pipelines,它们直接改编自经典的基于响应的 [53] 和基于特征的 [64] 蒸馏范式。第一个baseline旨在对齐从teacher分支和student分支的最后一层输出的最终类 logits,我们称之为 Lgt-V2GD。第二个baseline称为 Ftr-V2GD,它专注于feature-level的指导,通过对齐矢量化的全局视觉和几何描述符,然后将它们输入到后续的全连接分类器。我们在表 8 中列出了不同baseline框架的性能,并通过结合表 1 中报告的相应实验结果,观察了一致性趋势的几个方面。
首先,我们的实验结果强烈表明,vision-to-geometry知识迁移,提供了一种增强点云学习模型的通用且稳定的方法。即使是最直接的蒸馏框架 (Lgt-V2GD) ,也会在所有实验setups中获得不同程度的性能提升。其次,特征级的teacher指导往往比软目标(即 logits)提供更多信息,因为我们发现 Ftr-V2GD 总是优于 LgtV2GD。第三,在我们提出的 MV-V2GD 处理pipeline下,考虑到所有蒸馏模型的性能显着提升,许多现有点云学习框架的建模能力可能被低估了。
表 6 从原始点云渲染多视图图像的有效性

表 7 ModelNet40 上 3D 形状分类的总体准确率 (%),其中teacher模型是从头开始训练的(即,未加载 ImageNet 预训练的权重)

表 8 logit-driven和feature-driven的蒸馏baselines的比较。

5 讨论在本节中,我们重新强调了我们在设计整体处理流程时的核心动机和原则,以及我们论文带来的新见解,在此基础上,我们简要讨论了未来工作中可能的扩展。
最终,本文重点揭示了将知识从 2D 视觉领域迁移到 3D 几何领域的潜力。因此,我们避免在整个工作流程中设计复杂的学习架构或策略,因为我们相信简洁的技术实现和稳定的性能提升可以有力地证明我们方法的价值。可以预期,更先进的多视图 visual-geometric特征对齐技术,以及蒸馏目标将进一步增强当前的 MV-V2GD 框架。
在实验setups方面,我们注意到现有的多视图学习方法主要针对全局几何建模任务,例如分类和检索。由于特定领域的数据集准备不便,而该工作将应用场景扩展到部件分割和无监督学习,形成了更全面的评估协议。
更重要的是,我们令人鼓舞的结果激励了研究和开发人员,在模型设计之外更加关注数据开发。考虑到大规模丰富标注的 2D 视觉数据的可用性,以及 3D 几何对应物的稀缺性,通过 image-to-point蒸馏来增强点云学习模型,这是一种非常有前景且低成本的方法。
6 结论
在本文中,我们最先尝试并探索了将跨模态知识从多视图 2D 视觉建模迁移到 3D 几何建模,从而促进 3D 点云形状的理解。在技术上,我们研究了一个统一的 MV-V2GD 学习pipeline,适用于常见类型的、基于深度 3D 点云的学习范式,并专门定制了一种新颖的 VAFP 机制来实现多视图图像和点云之间的异构特征对齐。在各种应用上的大量实验,有力地证明了我们方法的优越性、普遍性和稳定性。我们相信,我们的工作将为发展强大的深度set architectures开辟新的可能性,并促使沿着这个有前景的方向进行更多的探索。
审核编辑:郭婷
-
基于深度学习的方法在处理3D点云进行缺陷分类应用2024-02-22 2831
-
《多模态大模型 前沿算法与实战应用 第一季》精品课程简介2026-05-01 220
-
视频课程下载—【完结】多模态与视觉大模型开发实战 - 2026必会2026-07-12 42
-
Powerpc架构与X86架构的区别2021-07-26 2326
-
ARM GIC(八)GICv3架构的变化2022-04-07 5450
-
请问在Keil uVision5下怎么为某一架构重新生成libmicroros.a?2022-04-12 3035
-
面向3D机器视觉应用并采用DLP技术的精确点云生成参考设计2022-09-22 2678
-
IA:利用SoC实现单一架构的广泛灵活性2010-02-02 860
-
3D点云技术介绍及其与VR体验的关系2017-09-15 1644
-
嵌入式应用程序:迁移到Intel x86架构2018-11-07 5327
-
红狮控制Crimson 3.1新增可用于OPC统一架构的增强型功能2019-02-22 4392
-
CANOpen系列教程11_ 深度分析CanFestival_3架构2020-03-06 8995
-
基于图卷积的层级图网络用于基于点云的3D目标检测2021-06-21 7298
-
何为3D点云语义分割2022-07-21 10732
-
浅谈工业4.0的OPC统一架构2022-12-29 1526
全部0条评论

快来发表一下你的评论吧 !
