

MLPerf 扩展 AI 推理基准测试,Nvidia 在所有测试中名列前茅
今日头条
描述
在最新一轮的 MLPerf AI 推理基准测试中,Nvidia 凭借其 AI 计算平台获得了性能记录。MLPerf 是业界独立的基准测试联盟,用于衡量硬件、软件和服务的 AI 性能。对于数据中心和边缘计算系统,英伟达在第二轮 MLPerf 评分中是所有六个应用领域的性能领先者。
MLPerf 联盟发布了 MLPerf Inference v0.7 的结果,这是其机器学习推理性能基准套件的第二轮提交,该套件中的应用程序数量翻了一番。它还引入了新的 MLPerf Mobile 基准。由 Arm、谷歌、英特尔、联发科、高通和三星电子领导的 MLPerf Mobile 工作组选择了四个新的神经网络进行基准测试,并开发了一款智能手机应用程序。
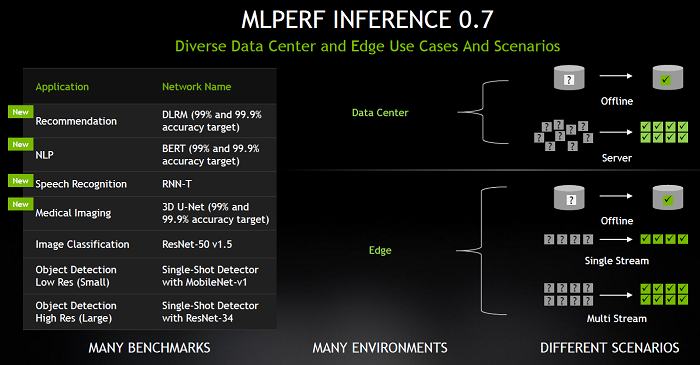
MLPerf 还增加了针对数据中心和边缘系统的额外测试,超越了最初的两个计算机视觉测试,包括 AI 的四个新领域:推荐系统、自然语言理解 (NLP)、语音识别和医学成像,以及图像分类(ResNet-50)和对象检测(低分辨率和高分辨率)。四个新的 AI 推理基准是深度学习推荐模型 (DLRM)、变压器的双向编码器表示 (BERT)、循环神经网络转换器 (RNN-T) 和 3D U-Net。
Nvidia Accelerated Computing 产品管理高级总监 Paresh Kharya 表示,这是第二轮 MLPerf AI 推理测试,出于一些原因,人们热切期待它。该基准已经发展到包含新的应用领域,总体参与人数从上一轮的 12 名(MLPerf 0.5 推理)增加到本轮的 23 名(MLPerf 0.7 推理),Nvidia Ampere 在这些测试中竞争第一次,他补充说。
“四个新的应用领域是推荐系统,其模型由 Facebook 提供,称为 DLRM,由 Google 提供的非常重要的 NLP 模型,称为 RNN-T 的语音识别模型,最后是称为 3D 的新医学成像模型用于在 MRI 扫描中识别肿瘤的 U-Net,”Kharya 说。“改进后的基准代表了现代用例,您可以针对不同的环境和场景运行这些测试。”
资料来源:英伟达(。)
Kharya 解释说,Nvidia 提交了数据中心和边缘应用程序,并且有四种不同的场景强调了这些环境。
“有离线测试,这意味着你的存储中有数据,任务是运行尽可能多的推理,”他说。“然后你有代表不同用户访问数据中心服务器的服务器场景,代表互联网应用程序或从云交付的应用程序,任务是对即将到来的负载进行尽可能多的推断。”
他补充说,还为数据中心和边缘环境提交了单流和多流方案。
分数基于系统。Nvidia 表示,使用 Nvidia A100 GPU的商用系统在所有 AI 推理基准测试得分中排名第一。此外,Nvidia 的 GPU 在提交的内容中占主导地位,Nvidia 和 11 个合作伙伴提交了超过 85% 的系统。合作伙伴包括思科、戴尔和富士通。
Nvidia 表示,五年前,只有少数领先的高科技公司使用 GPU 进行推理,而现在人工智能推理平台可通过各行各业的每个主要云和数据中心基础设施提供商获得。
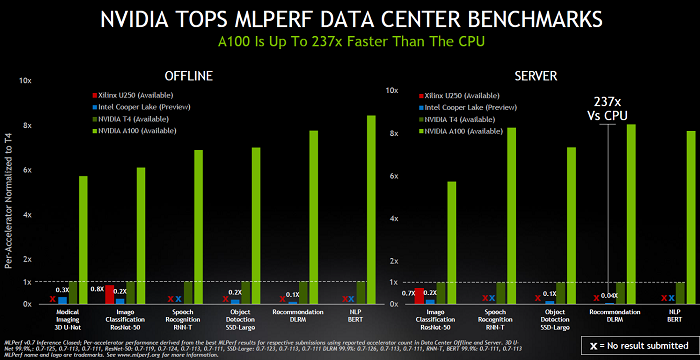
分数Nvidia 及其合作伙伴基于 Nvidia 的加速平台提交了他们的 MLPerf 0.7 结果,其中包括 Nvidia 数据中心 GPU、边缘 AI 加速器和优化软件。Nvidia A100 采用第三代 Tensor Cores 和多实例 GPU 技术,在 ResNet-50 测试中提高了领先优势,在上一轮中以 30 倍击败仅 CPU 的系统,而 6 倍。
对于离线和服务器两种数据中心场景,英伟达在每次测试中都大幅领先于竞争对手。然而,Kharya 指出,没有提交谷歌 TPU,并且许多在推理性能方面提出很多要求的初创公司也没有出现在标准化测试中。
资料来源:英伟达(。)
MLPerf Inference 0.7 基准测试还表明,在新添加的数据中心推理推荐器测试中,A100 的性能优于 CPU 高达 237 倍。Nvidia表示,这意味着单个Nvidia DGX A100 系统可以提供与 1,000 个双插槽 CPU 服务器相同的性能,从而在将 AI 推荐模型从研究到生产过程中为客户提供成本效益。
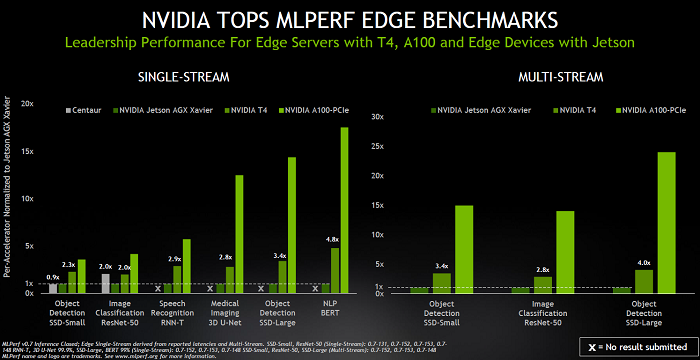
同样,在有单流和多流测试的边缘场景中,Nvidia 提交了其 T4 和 A100 PCIe GPU 以及 Jetson Xavier SoC。基准测试显示,在相同的测试中, Nvidia T4 Tensor Core GPU比 CPU 高出 28 倍,其Nvidia Jetson AGX Xavier是基于 SoC 的边缘设备中的性能领导者。
“Nvidia Jetson Xavier 是一款 30-W SoC 芯片,我们的 GPU 在各自类别的不同测试中都大大优于竞争对手,”Kharya 说。(见下表。)
资料来源:英伟达(。)
Kharya 说,从研究到生产,性能突破对于人工智能的采用至关重要。“人工智能已经取得了人类编写的软件无法取得的成果。人工智能具有很强的可扩展性。更大、更复杂的模型创造出更强大的人工智能和更准确的人工智能,它可以执行许多不同的任务。”

资料来源:英伟达(。)
然而,也存在挑战,他说。“人工智能越准确,训练和推理就越复杂。在过去五年中,模型的复杂性增长了 30,000 倍。当这些精确模型部署在实际应用中时,您需要极高的推理性能才能使这些应用成为可能,因此每天进行的数百万次医学扫描可以实时准确诊断疾病,或数亿次从客户支持到用户搜索和查找信息,对话式 AI 交互的感觉自然而然。
“而且高度相关的内容和产品推荐现在可以个性化并交付给用户,”Kharya 补充道。
英伟达在 CPU 方面的领先地位有所提高,在基本计算机视觉模型 (ResNet-50) 上从大约 6 倍增加到 30 倍,而在本轮新增的高级推荐系统模型上,英伟达 A100 的速度提高了 237 倍Kharya 说,比 Cooper Lake CPU。
他声称,这意味着单个 DGX A100 在推荐系统上提供与 1,000 个 CPU 服务器相同的性能。“MLPerf 的最新结果确实很好地证明了我们如何继续扩大我们的性能领先优势,并最终为我们的客户提供不断增加的价值,并使从研究到生产的全新 AI 应用范围成为可能。”
虽然 GPU 架构是英伟达 AI 平台的基础,但它也需要高度优化的软件堆栈。对于推理,Nvidia 将其分为四个关键步骤:预训练的 AI 模型(可通过 Nvidia 的NGC中心获得 GPU 加速软件)、优化模型的迁移学习工具包、具有 2,000 多项优化的Nvidia TensorRT推理优化器和Nvidia运行模型和应用程序的Triton 推理服务软件。
资料来源:英伟达(。)
该公司还为关键应用领域提供端到端的应用框架。它们包括 CLARA(医疗保健)、DRIVE(自动驾驶汽车)、JARVIS(对话式人工智能)、ISAAC(机器人)、MERLIN(推荐系统)和 METROPOLIS(智能城市)。
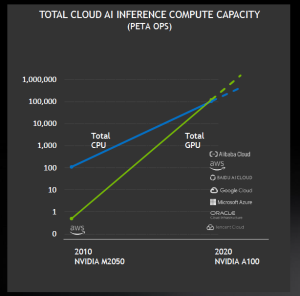
Nvidia 还声称,其 GPU 在公共云中提供的 AI 推理能力比 CPU 更多。据该公司称,英伟达 GPU 上的总云 AI 推理计算能力每两年增长大约 10 倍。应用范围从自主无人机和送货机器人到仓库和光学检测。
审核编辑 黄昊宇”
-
MLCommons推出AI基准测试0.5版2024-12-12 1709
-
浪潮信息AS13000G7荣获MLPerf™ AI存储基准测试五项性能全球第一2024-09-28 957
-
NVIDIA Grace Hopper超级芯片横扫MLPerf推理基准测试2023-09-13 1268
-
NVIDIA Grace Hopper 超级芯片横扫 MLPerf 推理基准测试2023-09-12 1132
-
NVIDIA 在 MLPerf 测试中将推理带到新高度2023-04-08 1208
-
NVIDIA AI平台在MLPerf基准测试实现飞跃2022-07-01 2034
-
如何对推理加速器进行基准测试2022-06-06 2288
-
MLPerf V2.0推理结果放榜,NVIDIA表现抢眼2022-04-15 4707
-
NVIDIA扩大AI推理性能领先优势,首次在Arm服务器上取得佳绩2021-09-23 3050
-
NVIDIA A100 GPU推理性能237倍碾压CPU2020-10-23 5400
-
NVIDIA打破AI推理性能记录2020-10-22 1207
-
NVIDIA在最新AI推理基准测试中大获成功2019-11-29 3664
-
NVIDIA 如何应对会话式AI带来的推理挑战?2019-11-08 6037
-
“企业移动化管理平台”测试认证 中科创达ThunderEMM名列前茅2016-07-20 1618
全部0条评论

快来发表一下你的评论吧 !
