

用于 AI 应用的硬件加速器设计师指南
今日头条
描述
作者:Majeed Ahmad,特约作家
硬件加速器——用于执行特定任务(如对对象进行分类)的专用设备——越来越多地嵌入到为各种 AI 应用程序服务的片上系统 (SoC) 中。它们有助于创建紧密集成的定制处理器,提供更低的功耗、更低的延迟、数据重用和数据局部性。
首先,有必要对 AI 算法进行硬件加速。AI 加速器专门设计用于更快地处理 AI 任务;它们以传统处理器不可行的方式执行特定任务。
此外,没有任何一个处理器可以满足 AI 应用程序的多样化需求,在这里,集成到 AI 芯片中的硬件加速器可为特定工作负载提供性能、电源效率和延迟优势。这就是为什么基于 AI 加速器的定制架构开始挑战将 CPU 和 GPU 用于 AI 应用程序的原因。
AI 芯片设计人员必须确定要加速什么、如何加速以及如何将该功能与神经网络互连。以下是定义在不断发展的 AI 工作负载中使用硬件加速器的主要行业趋势的快照。不可避免地,它始于可集成到各种 AI 芯片和卡中的 AI 加速器。
AI 加速器 IP硬件加速器广泛用于 AI 芯片中,用于分割和加速数据密集型任务,例如计算机视觉和深度学习,用于训练和推理应用。这些 AI 内核可加速 Caffe、PyTorch 和 TensorFlow 等 AI 框架上的神经网络。
Gyrfalcon Technology Inc. (GTI) 通过 IP 许可模式设计 AI 芯片并提供用于定制 SoC 设计的 AI 加速器。这家总部位于加利福尼亚州米尔皮塔斯的 AI 新贵 分别为边缘和云应用程序提供 Lightspeeur2801和2803 AI 加速器。
值得注意的是,Gyrfalcon 还围绕这些硬件加速器开发了 AI 芯片,这使得这些 AI 加速器 IP 经过硅验证。该公司用于边缘设计的 2801 AI 芯片每秒每瓦 (TOPS/W) 执行 9.3 tera 运算,而其用于数据中心应用的 2803 AI 芯片可提供 24 TOPS/W。
除了 IP 开发工具和技术文档,Gyrfalcon 还为 AI 设计人员提供 USB 3.0 加密狗,用于模型创建、芯片评估和概念验证设计。被许可方可以在 Windows 和 Linux PC 以及 Raspberry Pi 等硬件开发套件上使用这些加密狗。
硬件架构AI 加速器的基本前提是比以往更快地处理算法,同时尽可能降低功耗。它们在边缘、数据中心或介于两者之间的某个地方执行加速。人工智能加速器可以在 ASIC、GPU、FPGA、DSP 或这些设备的混合版本中执行这些任务。
这不可避免地会导致针对机器学习 (ML)、深度学习、自然语言处理和其他 AI 工作负载进行优化的几种硬件加速器架构。例如,一些 ASIC 设计为在深度神经网络 (DNN) 上运行,而后者又可以在 GPU 或其他 ASIC 上进行训练。
使 AI 加速器架构至关重要的是 AI 任务可以大规模并行。此外,人工智能加速器设计与多核实现交织在一起,这凸显了人工智能加速器架构的重要性。
接下来,人工智能设计通过添加越来越多的加速器来对算法进行越来越精细的分割,以提高神经网络的效率。用例越具体,就越有机会细粒度地使用多种类型的硬件加速器。
在这里,值得一提的是,除了将人工智能加速器整合到定制芯片中外,加速器卡也被用于提高云服务器和本地数据中心的性能并减少延迟。例如,赛灵思公司的Alveo加速器卡与 CPU 相比,可以从根本上加速数据库搜索、视频处理和数据分析(图 1)。

图 1:与高端 GPU 等固定功能加速器相比,Alveo U250 加速器卡将实时推理吞吐量提高了 20 倍,并将低于 2 毫秒的延迟降低了 4 倍以上。(图片:赛灵思公司)
可编程性 AI 设计中发生了很多动态变化,因此,软件算法的变化速度超过了 AI 芯片的设计和制造速度。它强调了在这种情况下往往成为固定功能设备的硬件加速器面临的一个关键挑战。
因此,加速器中必须具有某种可编程性,使设计人员能够适应不断变化的需求。可编程特性带来的设计灵活性还允许设计人员处理各种 AI 工作负载和神经网络拓扑。
英特尔公司通过以大约 20 亿美元的价格收购了一家位于以色列的可编程深度学习加速器开发商,响应了这一对人工智能设计可编程性的呼吁。Habana 用于训练的Gaudi处理器和用于推理的Goya处理器提供了易于编程的开发环境(图 2)。
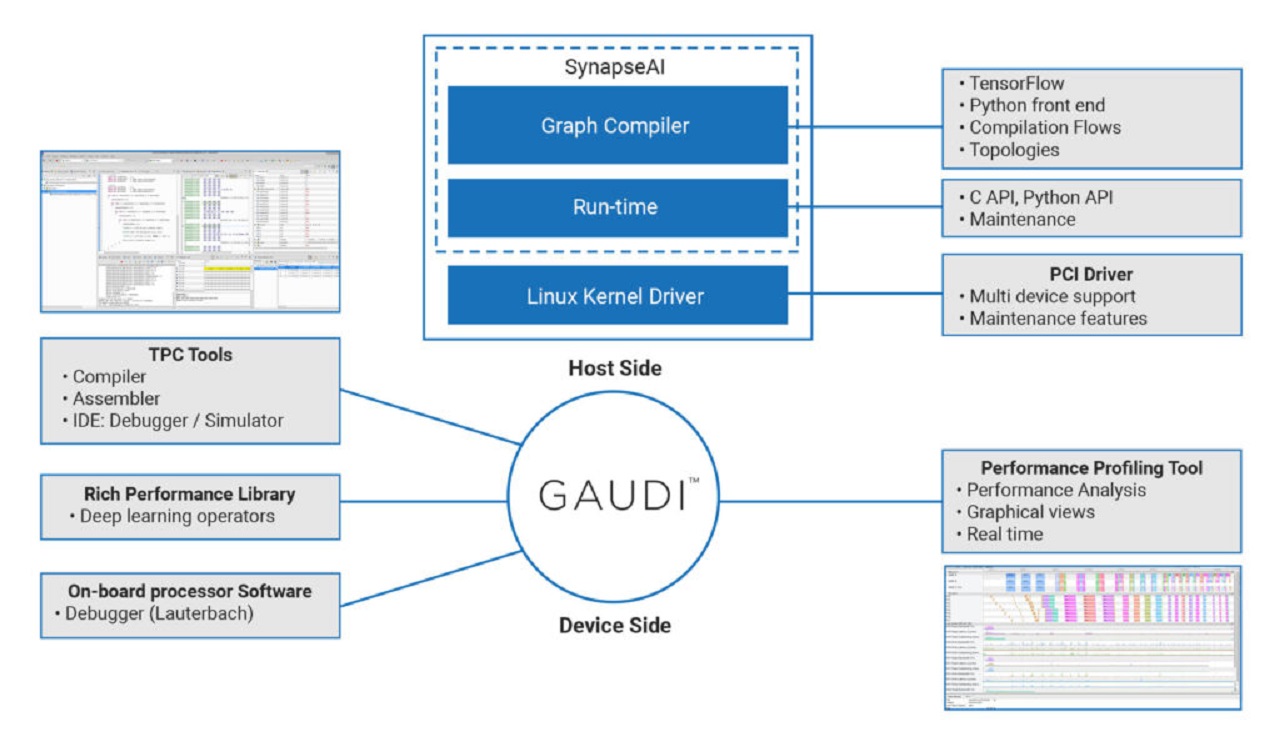
图 2:这就是开发平台和工具如何使用 Gaudi 训练加速器加速 AI 芯片设计。(图片:哈瓦那)
边缘的人工智能现在很明显,人工智能推理的市场比人工智能训练要大得多。这就是为什么业界见证了各种芯片正在针对从训练到推理的各种 AI 工作负载进行优化。
这将微控制器 (MCU) 带入了主要与强大的 SoC 相关联的 AI 设计领域。这些 MCU 正在整合 AI 加速器,为对象检测、面部和手势识别、自然语言处理和预测性维护等应用中资源受限的工业和物联网边缘设备提供服务。
以 Arm 的Ethos U-55microNPU ML 加速器为例,NXP Semiconductors 正在将其集成到其基于 Cortex-M 的微控制器、跨界 MCU 和应用处理器中的实时子系统中。Ethos U-55 加速器与 Cortex-M 内核协同工作以实现小尺寸。其先进的压缩技术可显着节省电力并减少 ML 模型大小,从而能够执行以前仅在较大系统上运行的神经网络。
NXP 的eIQML 开发环境为 AI 设计人员提供了多种开源推理引擎选择。根据具体的应用要求,这些 AI 加速器可以集成到各种计算元素中:CPU、GPU、DSP 和 NPU。
审核编辑 黄昊宇
-
英特尔媒体加速器参考软件Linux版用户指南2023-08-04 736
-
借助硬件加速器开发您的设计2023-01-03 1846
-
问下ARM3的硬件加速器只能用verilog写吗?2022-09-30 5487
-
什么是AI加速器 如何确需要AI加速器2022-02-06 6252
-
OpenHarmony Dev-Board-SIG专场:OpenHarmony 新硬件加速器2021-12-28 2006
-
OpenHarmony 分论坛-华秋电子新硬件加速器2021-10-23 2450
-
H.264解码器中CABAC硬件加速器怎么实现?2021-06-07 1897
-
硬件加速器提升下一代SHARC处理器的性能2021-04-23 1056
-
如何充分利用数字信号处理器上的片内FIR和IIR硬件加速器?2020-12-28 1438
-
毫米波传感器1443硬件加速器的简单介绍2019-05-08 4899
-
无法导入硬件加速器2019-02-27 2067
-
基于Xilinx FPGA的Memcached硬件加速器的介绍2018-11-27 4702
-
Veloce仿真环境下的SoC端到端硬件加速器功能验证2018-03-28 4797
-
利用硬件加速器提高处理器的性能2017-12-04 1978
全部0条评论

快来发表一下你的评论吧 !
