

摩尔定律为处理器创新让路
今日头条
描述
作者:Patrick Mannion,特约编辑
随着设计人员将并行数据处理作为人工智能 (AI)、自然语言处理和图像处理的异构架构的核心元素,曾经的协处理器 现在正在变成处理器。
可以肯定的是,英特尔、AMD、Arm 和开源 RISC-V 架构的 CPU 仍将在控制平面处理甚至信号处理功能中发挥作用。然而,重点显然转移到了为快速有效地执行深度神经网络 (DNN) 和卷积神经网络 (CNN) 算法而优化的乘法累加 (MAC) 函数数组。
DNN 主要用于 AI 和自然语言处理。一个简单的例子是亚马逊的 Echo Dot,这是一个看似简单的前端设备,由大规模并行 AI 和自然语言处理农场支持。CNN 越来越多地用于计算机视觉处理,尤其是对来自汽车制造商的高效 CNN 解决方案特别感兴趣,这些解决方案希望进一步增强其高级驾驶辅助系统 (ADAS)。
对于希望利用 DNN 和 CNN 技术的数据中心和基于边缘的系统的设计人员来说,经典架构在 Nvidia 的大型 GPU 和 videantis GmbH 的低功耗 CNN 处理器之后处于次要地位。
例如,Nvidia 最新的 Tesla V100 GPU 加速器使用 Volta GV100 GPU,继续在数据中心树立标准(图 1)。GV100 基于该公司的 Pascal GPU,将 211 亿个晶体管封装在一个尺寸为 815 mm 2的芯片 中,并使用 TSMC 的 12-nm FinFET Nvidia (FFN) 制造工艺。GV100 版本进一步简化了编程和应用程序移植,提高了 GPU 资源利用率。

图 1:Nvidia 的 Tesla V100 加速器基于其 GV100 GPU,它继续为高性能数据中心、人工智能和深度学习系统和应用设定标准。
Volta 迭代具有重新设计的流式多处理器 (SM) 架构,效率比 Pascal 设计高 50%。新的 Tensor Core 专为深度学习而设计,可为训练提供高达 12 倍的峰值 teraflops,为推理提供高达 6 倍的峰值 teraflops。其他功能包括支持 6 个第二代 Nvidia NVLink,总带宽为 300 GB/s,16 GB HBM2 内存,以及针对 Caffe2、MXNet、CNTK 和 TensorFlow 等深度学习框架的优化软件。
TensorFlow 是 Google 的深度学习框架,该公司使用张量处理单元 (TPU) 来支持它(图 2)。谷歌将 TPU ASIC 设计为当前 GPU 和 CPU 架构的替代方案,为谷歌搜索、谷歌图像处理和谷歌翻译等应用程序大规模执行神经网络处理。
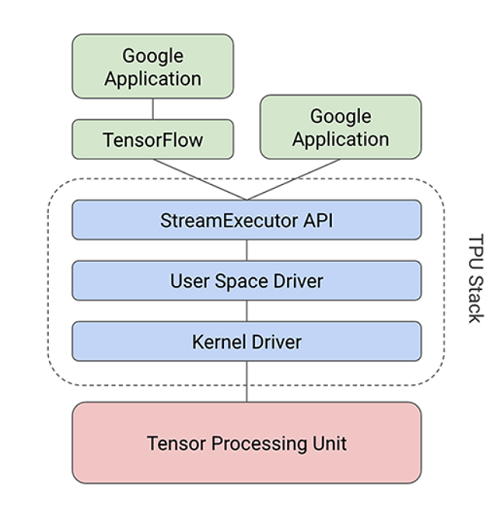
图 2:谷歌的 TPU 旨在为谷歌搜索、谷歌图像处理和谷歌翻译执行大规模的神经网络计算。
TPU 采用 28 纳米工艺实现,运行频率为 700 MHz,功耗为 40 W。由于 Google 需要快速部署它以满足快速达到极限的数据中心的需求,因此它是一款适合的加速卡插入 SATA 插槽。它通过 PCIe Gen3 x16 总线连接到主机。该接口的带宽为 12.5 Gbytes/s。
相对于 CPU 和 GPU,TPU 在性能上是一个飞跃。处理器性能的核心是按脉动阵列排列的乘法器矩阵单元 (MXU)。虽然通用 CPU 是按顺序执行读-操作-写过程,但 MXU 的脉动阵列意味着它可以读取输入值并对其执行多项操作,而无需将其存储到寄存器中。之所以称为收缩期,是因为数据以波的形式流经芯片阵列,就像心脏如何泵血一样。
MXU 方法针对功率和面积效率进行了优化,每个周期可以为 8 位整数执行 65,536 个 MAC。由于它以 700 MHz 运行,这意味着它可以执行 46 x 10 12 MACs/秒。这与 DNN 上下文中的 RISC CPU 相比是有利的,因为它们通常每条指令只能执行一个或两个算术运算。GPU 每秒可以执行数千次。
谷歌的 TPU 和英伟达的 Tesla V100 在替代处理架构方面处于领先地位,AMD 和英特尔正在迎头赶上。也就是说,英特尔收购了 Nervana 和 Altera 等公司尚未充分利用,而微软已经展示了其 Brainwave 软件在 Stratix 10 FPGA 上运行,达到 39.5 teraops/s。它预计在以 500 MHz 运行的生产硅上实现 90 teraop/s。
将 CNN 带到视觉边缘随着新老芯片和软件供应商在数据中心为 DNN 定位而努力,videantis GmbH 宣布了一个直接针对边缘的 CNN 视觉处理器和开发工具链。特别是 v-MP6000UDX 视觉处理架构和 v-CNNDesigner 工具针对智能图像和视频处理(图 3)。

图 3:videantis v-MP6000UDX 与 v-CNNDesigner 工具相结合,加速了网络边缘智能图像传感器的开发。
根据 videantis 营销副总裁 Marco Jacobs 的说法,CPU 和 GPU 本身的效率不足以在边缘进行图像传感和处理,因此它在 2004 年开发了用于低功耗应用的数字信号处理器。6000 系列是其最新的实例,该实例用于 DNN 和 CNN 算法。
与 TPU 不同,它也不用于训练。相反,Jacobs 说,一旦培训完成,设计师可以获取开发的代码,通过 v-CNNDesigner 运行它,并在几分钟内将该代码映射到 v-MP6000UDX 内核。训练是在不同情况和不同背景下识别对象的过程,例如不同的动物、路标、行人和其他对象。该过程是劳动密集型的,可能需要数周时间,并产生数兆字节的最终代码。但是,一旦生成,代码通过 v-CNNDesigner 运行,大大简化了传输和映射过程。Jacobs 表示,v-MP6000UDX 处理器本身的运行速度为 50 teraops/s,其效率取决于工艺节点和其他实施因素。
智能传感设备、ADAS 和智能手机是明显的目标应用,还有无人机、自动驾驶汽车、虚拟和增强现实以及监控。由于神经网络处理的进步,videantis 所做的只是计算机视觉一个非常有趣的时期的开始。“2012 年,CNN 取得了重大突破,”他说,他指的是当年参加 ImageNet 大规模视觉识别挑战赛的 CNN。“现在第二个趋势[数据中心是第一个]是让它们更小、更节能,这样它们就可以在嵌入式设备上运行。”
随着 CNN 的创新每天都在发生,Jacobs 强调 v-MP6000UDX 运行多种算法,使其经得起未来考验。
审核编辑 黄昊宇
-
晶圆和摩尔定律有什么关系?2011-12-01 6084
-
介绍28 nm创新技术,超越摩尔定律2012-08-13 2734
-
摩尔定律也适用于EPON芯片商用之路?2011-09-27 2636
-
半导体行业的里程碑“摩尔定律”竟是这样来的2016-07-14 4364
-
摩尔定律推动了整个半导体行业的变革2019-07-01 4539
-
摩尔定律还能走多远看了就知道2021-02-01 2122
-
摩尔定律在测试领域有哪些应用?2021-04-13 2355
-
请问摩尔定律死不死?2021-06-17 2026
-
摩尔定律,摩尔定律是什么意思2010-02-26 2038
-
摩尔定律_摩尔定律是什么2012-05-21 2891
-
摩尔定律的历程2017-10-24 3403
-
摩尔定律是什么_摩尔定律提出者及含义2018-03-09 33553
-
什么是摩尔定律?2023-08-05 8322
-
摩尔定律为什么会消亡?摩尔定律是如何消亡的?2023-08-14 4693
-
超越摩尔定律,下一代芯片如何创新?2023-11-03 2207
全部0条评论

快来发表一下你的评论吧 !
