

处理器急于向深度学习和雾计算寻求平衡
今日头条
描述
AMD 与 Intel 竞争的复苏对于寻求低成本、低功耗、高性能处理器的数据中心或工作站设计人员来说是个好消息。然而,这并不能掩盖重点转向专用或异构人工智能处理方法以及开源 RISC-V 架构的吸引力的巨大转变。后者面临着广泛的怀疑。
作为一种新架构,设计人员有必要对 RISC-V 持怀疑态度,因为他们需要谨慎管理风险,确保长期支持和二次采购,并拥有可靠且相对直观的工具工作流程。所有这些都是围绕开源 RISC-V 架构出现的问题,以及包括 ARM、英特尔和 AMD 在内的强大现有企业的现实。客户获胜看起来不太可能。正如一位观察家所说,“这是一个美丽的概念和建筑,但在可预见的未来,大门已经关上了。”
那位观察者是独立顾问和分析师 Loring Wirbel,他补充说,可能是当前使用 Arduino 的爱好者或年轻工程师将 RISC-V 带入主流,但这需要时间。
也就是说,RISC-V IP 的主要支持者 SiFive 正在取得进展。它最近宣布推出其 U54-MC Coreplex IP,这是第一个基于 RISC-V 的 64 位四核实时应用处理器,适用于 Linux(图 1)。Electronic Products 借此机会直接向 SiFive 的产品和业务开发副总裁 Jack Kang 提出了这些问题。
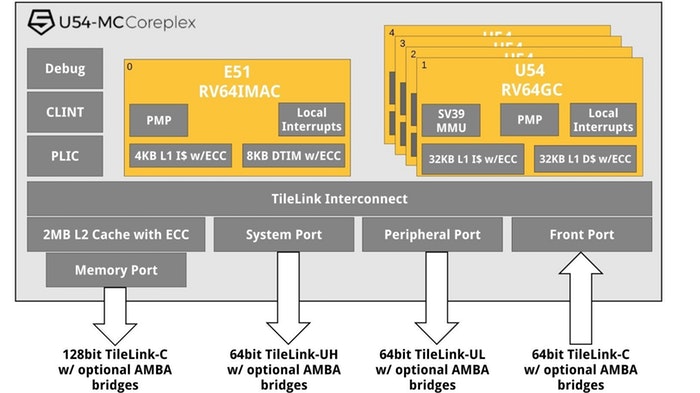
图 1:SiFive 的 U54-MC Coreplex IP 是第一个用于 Linux 的基于 RISC-V 的 64 位四核实时应用处理器。
关于工具支持,Kang 表示已经有很多开源工具可用于 RISC-V。例如,Bintils 和 GCC 是稳定的和主线的,而 LLVM 和 Linux 正在被上游化。“Glibc 和 newlib 已经被上游化,并将在下一个版本中发布,而 GDB 和 OpenOCD 对 RISC-V 的支持也存在,”他说。
SiFive 本身提供 Freedom Studio,这是一个基于 Eclipse 的集成开发环境 (IDE),它将所有这些工具集成到一个易于使用的环境中。
Kang 表示,在商业方面,UltraSoC 和 Segger 等供应商已宣布支持 RISC-V。“其他多家领先的调试和跟踪商业供应商将在 2017 年晚些时候宣布支持。”
面对老牌英特尔和 AMD,Kang 表示,RISC-V 的机会在于新的计算和需求领域,包括边缘计算、物联网和机器学习。
“这些市场没有被半导体行业试图提供的单体公司和单一风格设计很好地服务,”他说。“对于 SiFive 和 RISC-V 生态系统而言,定制芯片和内核的能力是关键优势。” Kang 为 SiFive 技术考虑的应用将需要数千种不同类型的设计。“这根本不是传统供应商有能力提供的。”
至于 RISC-V 需要时间让其用户成熟并从 Arduino 类型的爱好者应用程序迁移,Kang 不屑一顾。“这听起来像是对商业行业在开源软件概念首次出现时游说的批评,”他说。“认为创新只能存在于价值数十亿美元的公司手中是错误的。” 值得注意的是,Microsemi 是 SiFive 与 Arduino 一起宣布的另一个客户。
有足够多的半导体初创公司尝试过但都失败了,这让所有人都看到,与软件公司相比,创办一家硬件公司或构建自己的芯片要困难得多,成本也要高得多。
“SiFive 将通过大幅降低定制硅的门槛来改变这种状况,”Kang 说。“一旦我们这样做了,我们就会看到很多新的想法和创新。”
人工智能和深度学习是新的硬件前沿 SiFive 对物联网、边缘计算和机器学习的重视符合整个行业为从边缘寻找基于物联网的雾计算类型分析的正确处理组合的趋势到云端,以及人工智能 (AI)。虽然 AI 的实际开发很大程度上取决于编程,但执行数据分析和决策的效率和速度在很大程度上取决于底层硬件。
考虑到这一点,每个供应商都在寻找合适的成分来补充他们自己的硅。英特尔已经购买了 Altera 的 FPGA 数据平面处理速度,以补充其 CPU。它还收购了 Nervana 的深度学习计算硬件引擎。Nvidia 已经从一家 GPU 供应商转变为一家人工智能、机器学习和深度学习解决方案提供商。在这样做的同时,它还与其他具有互补芯片的公司合作,以优化效率和速度。
但正确的组合是什么?以色列海法的机器学习软件开发商 Presenso 的首席技术官 Deddy Lavid 试图回答这个问题。他表示,满足深度机器学习需求所需的处理器和处理架构是:
多个并行高速预处理单元(用于数据输入和处理)
几个并行处理单元(用于每个隐藏层神经元的计算)
几个并行的非常大和快速的寄存器(用于快速存储和提取数据)
高速网络带宽
CPU 的耗电量至少要低 10 倍
Lavid 指出,这种特定于 AI 的处理器正在各个公司的密集开发中,Nvidia 以其定制的 GPU 主导了这个市场。
CPU 马力不再是门控因素 为 AI 和深度学习找到正确的处理元素组合的努力是在处理速度和功耗的后马力时代寻找正确的元素组合的更广泛斗争的一个具体例子很重要,但不是决定因素。例如,在数据中心,可扩展性、内存带宽、I/O 和安全性是大数据原始处理与虚拟化混合的主要考虑因素。
当 AMD 与英特尔的战争在今年早些时候重新开始时,这一点得到了强调,AMD 在 6 月宣布了基于 Zen x86 内核的 Epyc 7000 片上系统 (SoC)(图 2)。该 SoC 配备 32 个内核、64 个线程、8 个内存通道,每个插槽高达 2 TB 的内存,以及 128 个 PCIe Gen 3 通道。它还具有硬件嵌入式 x86 安全性。它的推出价格从 400 美元到 4,000 美元不等。
图 2:AMD 用于数据中心的 Epyc SoC 具有多达 28 个 x86 Zen 内核和 128 个 PCIe Gen 3 通道。
为了展示 SoC 的内存控制器性能,AMD 直接将 Epyc 与英特尔的 Broadwell 进行了比较,使用了内存绑定的高性能计算 (HPC) 应用程序。这可作为虚拟现实和 3D 处理等应用程序的代理,在这些应用程序中,数据从主内存来回移动到本地缓存中,然后再次返回到主内存。
AMD 的 Epyc 比 Intel 的 Broadwell 提高了 78%,这并不奇怪,但最重要的一点是有效的:内存带宽可能会扼杀 CPU 的性能。它需要适合应用的比例。这也适用于处理器到处理器的通信,这就是 AMD 用自己的 Infinity 结构替换 PCIe 以实现更快的 GPU 通信的原因。
几周后,当英特尔凭借其 Skylake-SP(可扩展处理器)SoC 超越 AMD 时,Epyc-Broadwell 的比较变得毫无意义。英特尔为其 Broadwell 产品线提供了 65% 的改进,并推出了 50 个版本,价格从 400 美元到 9,000 美元不等。
值得注意的是,Skylake-SP 最高为 28 个内核,而 Epyc 为 32 个,并且只有 48 个 PCIe 3 Gen 通道,而 Epyc 为 128 个通道。然而,除其他因素外,设计人员必须选择哪个具有最适合应用的功能组合以及可用的插槽数量。两者都跨越两个插槽,尽管 Epyc 的 I/O 使其作为单插槽解决方案具有竞争力(与 Broadwell 相比)。
边缘虚拟化和雾计算 随着分布式、雾计算类型的概念在物联网分析中占据主导地位,同样的原则也被应用于虚拟化,将其从数据中心移出并靠近边缘。
这是恩智浦发布具有 16 个 ARM Cortex-A72 内核、100-Gbit/s 以太网和单个 PCIe Gen 4 互连的 LX2160A SoC 背后的部分原因(图 3)。遵循旨在降低延迟、可靠性和整体功耗的雾计算原理,SoC 可用于在传感器和云之间添加一层虚拟化和分析能力,以进行物联网数据分析。
-
NPU与传统处理器的区别是什么2024-11-15 2813
-
深度学习GPU加速效果如何2024-10-17 1293
-
深度学习服务器怎么做 深度学习服务器diy 深度学习服务器主板用什么2023-08-17 1641
-
理解如何处理计算机视觉和深度学习中的图像数据2023-04-26 1411
-
如何使用FPGA加速深度学习计算?2023-03-09 3754
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2156
-
TDA4对深度学习的重要性2022-11-03 1512
-
深度学习算法进行优化的处理器——NPU2022-10-17 3593
-
米尔FZ3深度学习计算卡免费试用2020-10-09 1335
-
TPU/GPU /FPGA谁将能成为智能时代协处理器的领跑者2018-08-31 2168
-
英伟达无人驾驶Xavier处理器帮助应用程序使用深度学习神经网络算法2017-12-19 5073
-
寒武纪科技将发布深度学习专用处理器2017-10-11 1374
-
5分钟搞懂ECE雾计算2017-05-05 3805
-
机智云4.0发布 推下一代IOT雾计算概念2016-09-22 2869
全部0条评论

快来发表一下你的评论吧 !
