

iNeRF对RGB图像进行类别级别的物体姿态估计
电子说
描述
作者:Lin Yen-Chen, Pete Florence, Jonathan T. Barron, Alberto Rodriguez, Phillip Isola, Tsung-Yi Lin
摘要
我们提出了iNeRF,一个通过 “反转 ”神经辐射场(NeRF)来进行无网格姿势估计的框架。NeRFs已经被证明对合成真实世界场景或物体的逼真的新视图非常有效。在这项工作中,我们研究了是否可以通过NeRF来应用无网格、纯RGB的6DoF姿态估计的分析合成法:给定一个图像,找到摄像机相对于三维物体或场景的平移和旋转。我们的方法假定在训练或测试期间没有物体网格模型可用。从最初的姿势估计开始,我们使用梯度下降法来最小化从NeRF渲染的像素和观察到的图像中的像素之间的残差。在我们的实验中,我们首先研究:1)如何在iNeRF的姿势精化过程中对射线进行取样以收集信息梯度;2)不同批次的射线如何影响合成数据集上的iNeRF。然后我们表明,对于来自LLFF数据集的复杂的真实世界场景,iNeRF可以通过估计新的图像的相机姿态和使用这些图像作为NeRF的额外训练数据来改善NeRF。最后,我们展示了iNeRF可以通过反转从单一视图推断出的NeRF模型,对RGB图像进行类别级别的物体姿态估计,包括训练期间未见的物体实例。
主要贡献
总而言之,我们的主要贡献如下。
(i) 我们表明,iNeRF可以使用NeRF模型来估计具有复杂几何形状的场景和物体的6DoF姿态,而不需要使用3D网格模型或深度感应--只使用RGB图像作为输入。
(ii) 我们对射线采样和梯度优化的批量大小进行了深入研究,以确定iNeRF的稳健性和局限性。
(iii) 我们表明,iNeRF可以通过预测更多图像的相机姿态来改善NeRF,这些图像可以被添加到NeRF的训练集中。
(iv) 我们展示了对未见过的物体的类别级姿势估计结果,包括一个真实世界的演示。
主要方法
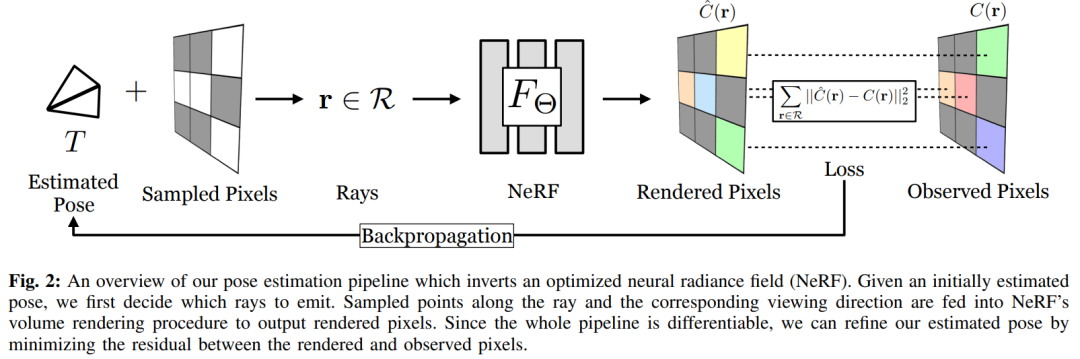
我们现在提出了iNeRF,一个通过 “反转 ”训练过的NeRF来执行6DoF姿态估计的框架。让我们假设一个场景或物体的NeRF的参数化Θ已经被恢复,并且相机的本征是已知的,但是图像观测I的相机位姿T还没有确定。与NeRF不同的是,NeRF使用一组给定的相机位姿和图像观测值来优化Θ,而我们要解决的是在给定权重Θ和图像I的情况下恢复相机姿势T的逆问题。
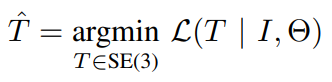
为了解决这个优化问题,我们利用NeRF的能力,在NeRF模型的坐标框架中采取一些估计的相机姿势T∈SE(3),并渲染相应的图像观察。然后,我们可以使用与NeRF相同的光度损失函数L,但我们不是通过反向传播来更新MLP的权重Θ,而是更新姿势T以最小化L。虽然倒置NeRF来进行姿势估计的概念可以简明扼要地说明,但这样的问题是否可以实际解决到一个有用的程度并不明显。损失函数L在SE(3)的6DoF空间上是非凸的,而且全图像的NeRF渲染在计算上很昂贵,特别是在优化程序的循环中使用。
1.基于梯度的SE(3)优化
将Θ定义为经过训练的固定的NeRF的参数,先验Ti是当前优化步骤i的估计相机姿势,I是观察到的图像,L(Ti | I, Θ)是用于训练NeRF中的精细模型的损失。我们采用基于梯度的优化来解决上面方程中定义的先验T。为了确保在基于梯度的优化过程中,估计的姿势先验Ti继续位于SE(3)流形上,我们用指数坐标为先验Ti设置参数。给定一个从相机帧到模型帧的初始姿势估计值先验T0∈SE(3),我们将先验Ti表示为:
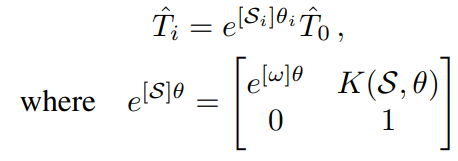
我们通过MLP对损失函数进行迭代,得到梯度∇SθL(e [S]θT0 |I, Θ),用于更新估计的相对变换。我们使用Adam优化器,其学习率为指数衰减。对于每个观察到的图像,我们将Sθ初始化到0附近,其中每个元素都是从零均值正态分布N(0,σ=10-6)中随机抽取的。在实践中,用e[S]θ T0进行参数化,如果利用T0e[S]θ会导致旋转中心在初始估计的中心,而不是在摄像机帧的中心。这就减轻了优化过程中旋转和平移之间的耦合。
2.光线采样
这里讨论了三种采样方法
随机采样:一个直观的策略是在图像平面上随机抽取M个像素点{p i x , piy}M i=0,并计算其对应的射线。事实上,NeRF本身在优化Θ时就使用了这种策略(假设不使用图像批处理)。我们发现,当射线的批处理量b较小时,这种随机采样策略的性能是无效的。大多数随机采样的像素对应于图像中平坦的、无纹理的区域,这些区域在姿势方面提供的信息很少(这与著名的光圈问题一致)。
兴趣特征点采样:我们提出了兴趣点抽样来指导iNeRF的优化,我们首先采用兴趣点检测器来定位观察图像中的一组候选像素位置。然后,我们从检测到的兴趣点中抽出M个点,如果检测到的兴趣点不够多,就回落到随机抽样。虽然这种策略使优化收敛得更快,因为引入了较少的随机性,但我们发现它很容易出现局部最小值,因为它只考虑观察图像上的兴趣点,而不是来自观察图像和渲染图像的兴趣点。然而,获得渲染图像中的兴趣点需要O(HW n)个前向MLP通道,因此在优化中使用的成本过高。
兴趣特征区域采样:为了防止只从兴趣点取样造成的局部最小值,我们建议使用 “兴趣区域 ”取样,这是一种放宽兴趣点取样的策略,从以兴趣点为中心的扩张掩模中取样。在兴趣点检测器对兴趣点进行定位后,我们应用5×5的形态学扩张进行I次迭代以扩大采样区域。在实践中,我们发现当射线的批量大小较小时,这样做可以加快优化速度。请注意,如果I被设置为一个大数字,兴趣区域采样就会退回到随机采样。
3.用iNeRF自我监督学习NeRF
除了使用iNeRF对训练好的NeRF进行姿态估计外,我们还探索使用估计的姿态来反馈到训练NeRF表示中。具体来说,我们首先根据一组已知相机姿势的训练RGB图像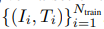 来训练NeRF,产生NeRF参数Θtrain。然后,我们使用iNeRF来接收额外的未知姿势的观察图像{Ii}。Ntest i=1,并求解估计姿势先验Ti。Ntest i=1。鉴于这些估计的姿势,我们可以使用自我监督的姿势标签,将
来训练NeRF,产生NeRF参数Θtrain。然后,我们使用iNeRF来接收额外的未知姿势的观察图像{Ii}。Ntest i=1,并求解估计姿势先验Ti。Ntest i=1。鉴于这些估计的姿势,我们可以使用自我监督的姿势标签,将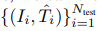 加入训练集。这个过程允许NeRF在半监督的情况下被训练。
加入训练集。这个过程允许NeRF在半监督的情况下被训练。
主要结果


审核编辑:郭婷
-
基于PoseDiffusion相机姿态估计方法2023-07-23 2830
-
纳米位移计真的可以测到纳米级别的物体的位移?2015-07-23 5193
-
源码交流=图像处理 识别圆形物体2020-04-02 24209
-
光照变化情况下的静态头部姿态估计2009-04-22 2362
-
不同类别的电池是如何回收的?2009-11-04 1031
-
基于RGB-D图像物体识别方法2017-12-07 1240
-
基于深度学习的二维人体姿态估计方法2021-03-22 1385
-
基于视点与姿态估计的视频监控行人再识别2021-05-28 1130
-
基于OnePose的无CAD模型的物体姿态估计2022-08-10 2543
-
一种基于去遮挡和移除的3D交互手姿态估计框架2022-09-14 1703
-
无需实例或类级别3D模型的对新颖物体的6D姿态追踪2023-01-12 2719
-
基于飞控的姿态估计算法作用及原理2023-11-13 2573
-
从单张图像中揭示全局几何信息:实现高效视觉定位的新途径2024-01-08 1876
-
基于RV1126开发板的人脸姿态估计算法开发2025-04-14 2424
-
如何在树莓派 AI HAT+上进行YOLO姿态估计?2025-07-20 1400
全部0条评论

快来发表一下你的评论吧 !
